政安晨:机器学习快速入门(一){基于Python与Pandas}
对于刚接触ML(机器学习)的小伙伴来说,通过几篇文章能够快速登堂入室是非常及时且有用的,作者政安晨力求让小伙伴们,几篇文章内就可以达到这个目标,咱们开始!

机器学习简介
咱们先看一下Pandas:
Pandas是一个基于Python的开源数据处理库,旨在提供快速、灵活和简单的数据分析工具。它提供了大量的数据结构和函数,可以轻松地处理和操作结构化数据。Pandas的核心数据结构是Series和DataFrame,分别用于存储一维的标签数据和二维的表格数据。它还提供了丰富的数据处理和分析功能,包括数据清洗、筛选、分组、重塑、合并等。Pandas的设计和用法都非常直观,使得用户能够方便地进行数据处理和分析工作。
Python语言我就不多说了,想要Python快速入门的小伙伴,去订阅我的Python语言大讲堂栏目。
里面有几篇示例演绎的Python语言的快速入门。
政安晨的Python语言大讲堂 http://t.csdnimg.cn/ZKv9R
http://t.csdnimg.cn/ZKv9R
好了,接下来:
学习机器学习的核心理念,并构建你的第一个模型。
模型的工作原理
如果你是机器学习的新手,首先要采取的步骤是什么?
我们将先从机器学习模型的工作原理和使用方法的概述开始。
如果您以前进行过统计建模或机器学习,这可能会感觉很基础。不用担心,我们很快就会进入构建强大模型的阶段。
在接下来的情景中,您将在建模过程中构建模型:
您的表亲通过房地产投机赚了数百万元。他因为您对数据科学的兴趣而提出与您成为商业伙伴。他提供资金,您提供预测房屋价值的模型。
您问您的表亲他过去是如何预测房地产价值的,他说那只是凭直觉。但更深入的询问揭示出,他从过去看到的房屋中确定了价格模式,并将这些模式用于预测他正在考虑的新房屋。
机器学习的工作原理与此类似。我们将从一个被称为决策树的模型开始。还有更高级的模型可以提供更准确的预测。但决策树易于理解,它们是数据科学中一些最先进模型的基本构建模块。
为简单起见,我们将从最简单的决策树开始(下图就是简单决策树):
简单决策树
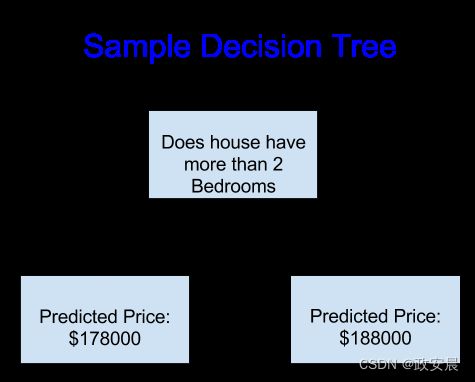
它将房屋分为只有两个类别,对于考虑中的任何房屋,预测价格是同一类别房屋历史平均价格。
我们使用数据来决定如何将房屋分成两组,然后再次使用数据确定每组的预测价格。
从数据中捕捉模式的这个步骤称为拟合或训练模型。
用于拟合模型的数据称为训练数据。
模型的拟合细节(例如如何拆分数据)足够复杂,我们将在后面进行讨论。在模型拟合完成后,您可以将其应用于新数据,以预测额外房屋的价格。
改进决策树
以下两棵决策树中,哪一棵更有可能是通过拟合房地产训练数据得到的结果?

左边的决策树(决策树1)可能更有意义,因为它捕捉到了房屋卧室数量较多的房屋往往以更高的价格出售的现实情况(右边的决策树则没有正确拟合这个情况)。这个模型最大的缺点是它没有捕捉到影响房屋价格的大多数因素,比如浴室数量、地块大小、位置等。
可以通过使用更多“分裂”来捕捉更多的因素。这些被称为“更深”的树。考虑到每个房子的整体面积的决策树可能如下所示:

通过沿着决策树进行追踪,并始终选择与该房屋特征相对应的路径,您可以预测任何房屋的价格。该房屋的预测价格位于树的底部。我们进行预测的底部点被称为叶子节点。
决定叶子节点的分割和数值将取决于数据,所以现在是时候检查一下你将要处理的数据了。
初步数据探索
(加载并理解您的数据)
使用Pandas这样的工具
使用像Pandas这类工具,可以让你面对数据好似庖丁解牛。
您现在需要建立一个Python的虚拟环境,在这个环境里可以通过pip安装Pandas工具包,这个Python虚拟环境可以使用Conda工具建立,因为我的笔记本是Ubuntu系统,所以我选择使用了Miniconda软件来进行Python虚拟环境的构建,并使用Jupyter Notebook来进行程序演练。
(如果您想要参照着某个文档试一试的话,参考我下面这篇博客里开头部分的那些我的其它文章链接:详细讲了如何在windows或者Linux环境下创建与机器学习有关的环境)
跟着演练快速理解TensorFlow(适合新手入门)https://blog.csdn.net/snowdenkeke/article/details/135950931
安装Pandas工具包
现在我打开我的一个虚拟环境,安装好Pandas:
pip install pandas
然后,我在我的虚拟环境中启动Jupyter Notebook:

Jupyter Notebook启动后会打开系统默认浏览器并加载页面:

一切就绪,开始您的第一场数据探索。
任何机器学习项目的第一步是熟悉数据。
您将使用Pandas库来完成这一步。
Pandas是数据科学家用于探索和操作数据的主要工具。
大部分人在代码中将Pandas缩写为pd。我们使用以下命令来完成这一步:
import pandas as pd在Jupyter中像这样输入(那样一行一行的格子成为单元格):

输入后执行,只要没有报错,即表示执行OK,如果该段程序有输出结果,则会在下方打印出来。
打开一个数据文件(.csv)
Pandas库中最重要的部分是DataFrame。DataFrame保存了一种类似于表格的数据类型。这类似于Excel中的工作表或SQL数据库中的表格。
Pandas具有针对此类数据进行操作的强大方法:
以墨尔本,澳大利亚的房价数据为例。在实践练习中,您将使用相同的流程来处理一个新的数据集,其中包含爱荷华州的房价数据。
(这个数据集我已经放到了该文章的资源绑定中,小伙伴们下载后解压使用)
文件路径可以拷贝到Jupyter的工作目录下,类似这样:./melb_data.csv
我们使用以下命令加载和探索数据:
把文件路径像我下面的这段代码这样赋值给变量。
# save filepath to variable for easier access
melbourne_file_path = './melb_data.csv'
# read the data and store data in DataFrame titled melbourne_data
melbourne_data = pd.read_csv(melbourne_file_path)
# print a summary of the data in Melbourne data
melbourne_data.describe()在Jupyter中执行上述代码如下:

解读数据描述
结果显示,每列原始数据集有8个数字。第一个数字是计数,显示有多少行具有非缺失值。
缺失值出现的原因有很多。例如,在调查一个卧室的房子时,可能不会收集到第二个卧室的大小。我们将会回到缺失数据的话题上。
第二个值是平均值。在其下方,标准差(std)是衡量数值分散程度的统计量。
要解释最小值、25%、50%、75%和最大值,可以想象将每一列按照从最小到最大值的顺序排序。第一个(最小)值就是最小值。如果从列表的首位往前推进四分之一的位置,你会找到一个大于25%的值和小于75%的值。那就是25%的值(发音为“25th percentile”)。50th和75th百分位数的定义类似,而最大值则是最大的数。
告一段落
至此,您已经了解了数据分析与机器学习,并熟悉了安装、导入Pandas库,而且还展示出了一段数据文件的描述。你看,并不难吧。