过年送你三句话!部门大战积雪!飞机延误,掌声响起?——早读
你到家了吗?
-
- 引言
- 代码
- 第一篇 也评 以雪为令,多滴部门全力以赴迎战寒潮
- 第二篇 人民日报 飞机延误20分钟,但他走进机舱时,掌声响起!
- 第三篇 人民日报 【夜读】快过年了,这三句话送给你
- 第四篇(跳)人民日报 来啦 新闻早班车
-
-
-
- 要闻
- 社会
- 政策
-
-
- 结尾
引言
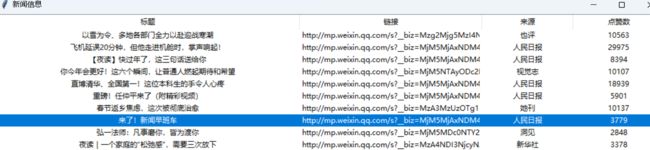
放假第一天
你看看 这个新闻早班车的排名这么靠后
全国人民都慢慢进入放假的节奏啦

代码
alike
解释:指在某些方面相像或相似,不一定要完全一样,但有共同之处。
记忆方法:通过词根 “like” (像)和前缀 “a-” 表示加强语气,记住 “alike” 就是“非常像”的意思。
# -*- coding: utf-8 -*-
# @Time : 2024/1/25 11:11
# @File : everyDayRequestwx.py
# @Software: vscode
# @author : Zercher
# @Desc : 爬取微信文章热榜前10 网址:https://www.gsdata.cn/rank/wxarc
import requests
from bs4 import BeautifulSoup
import pandas as pd
import tkinter as tk
from tkinter import ttk
import webbrowser
url = 'https://www.gsdata.cn/rank/wxarc'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
r = requests.get(url, headers=headers)
# print(r.text)
# print(r.status_code)
soup = BeautifulSoup(r.text, 'html.parser')
articleTitles = []
articleLinks = []
articlePublishs = []
articleLikes = []
for i in range(1, 11):
r = soup.find_all('tr')[i].find_all('td')
articleTitle = r[0].get_text().strip() # 去除首尾空格
articleLink = r[0].a['href']
articlePublish = r[1].get_text()
articleTitles.append(articleTitle)
articleLinks.append(articleLink)
articlePublishs.append(articlePublish)
articleLikes.append(r[4].get_text())
# 创建DataFrame
data = {
'标题': [articleTitle.strip() for articleTitle in articleTitles], # 去除首尾空格和换行符
'链接': articleLinks,
'来源': articlePublishs,
'点赞数': articleLikes
}
df = pd.DataFrame(data)
# 打印标题和来源
print(articleTitles)
print(articlePublishs)
# 保存为CSV文件
df.to_csv('news_data.csv', index=False, encoding='utf_8_sig')
print('爬取完成!')
# 创建主窗口
root = tk.Tk()
root.title("新闻信息")
# 创建Treeview控件,并设置其头部列名
treeview = ttk.Treeview(root, columns=("标题", "链接", "来源", '点赞数'), show="headings")
treeview.column("标题", width=500, anchor=tk.CENTER)
treeview.column("链接", width=300, anchor=tk.CENTER)
treeview.column("来源", width=150, anchor=tk.CENTER)
treeview.column("点赞数", width=150, anchor=tk.CENTER)
treeview.heading("标题", text="标题")
treeview.heading("链接", text="链接")
treeview.heading("来源", text="来源")
treeview.heading("点赞数", text="点赞数")
def open_url(event):
item = treeview.selection()[0] # 获取选中的行
url = treeview.item(item, "values")[1] # 获取该行的链接值
# 指定Edge浏览器打开链接
webbrowser.register('edge', None, webbrowser.BackgroundBrowser(r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'))
webbrowser.get('edge').open(url)
treeview.bind('' , open_url) # 绑定鼠标左键释放事件
# 将数据插入到Treeview中并绑定点击事件
for i, (_title, _link, _publish, _Like) in enumerate(zip(articleTitles, articleLinks, articlePublishs, articleLikes)):
item_id = treeview.insert("", tk.END, values=(_title, _link, _publish, _Like))
# 显示Treeview
treeview.pack(fill=tk.BOTH, expand=True)
# 运行主循环
root.mainloop()
第一篇 也评 以雪为令,多滴部门全力以赴迎战寒潮
这个也评现在能顶上人民日报的位置
属实不易
先看看他的背景
个人主体 地区显示 河南
很难想象
简介
纵观天下时事,站在独立视角,也予洞察评析,为您精彩呈现。
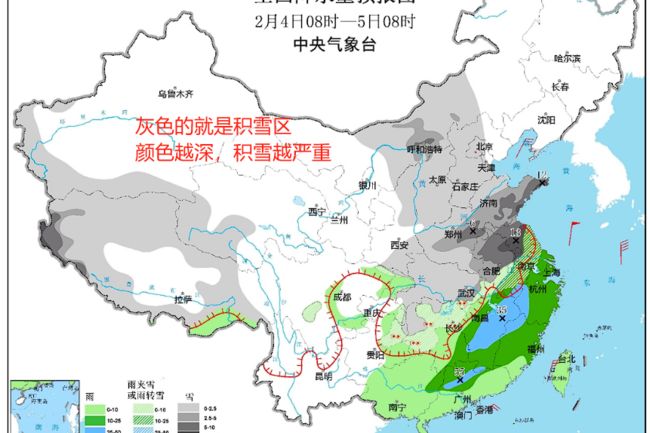
基本上看是中国的东北部积雪严重,且十分偏中腹,恰好是人流密集的地方
其中就包括河南
文章大体罗列了一些事实
确实够独立
后面持续关注这个号看看,数据真的挺多面的。
附议文章:
新春佳节将至,在回家过年的路上,也请各位及时关注天气预警,做好防寒保暖措施,一路安全,一路美景,一路风歌,一路春风。
慢 堵 停 就当做沿途欣赏风景吧!
第二篇 人民日报 飞机延误20分钟,但他走进机舱时,掌声响起!
文章内容三句话:
- 2月3日,在兰州机场一架飞往上海的航班前,一名年轻女孩在摆渡车上突发心脏骤停晕倒。
- 上海交通大学医学院附属瑞金医院心脏外科医生李海清立即施救,持续心脏按压两分钟后成功使女孩恢复心跳和意识。
- 救援过程中,飞机延迟起飞,李海清医生受到乘客赞扬,并借此机会呼吁大众学习心脏骤停急救技能。
这个20分钟延误是情有可原,没人会苛责;
这个20分钟延误是救人性命,大家会故障;
这时候的这篇文章,是不是正好能够跟南航的延误,道歉形成鲜明对比呢?
望大家乘坐飞机时,也应该仔细斟酌,特别是这种容易发生突发状况的时间点,宁愿贵一点,也好安全到家!

第三篇 人民日报 【夜读】快过年了,这三句话送给你
昨天三句今天又三句
不知道我的压力好大的噻
每天端正一个缺点就够难的
现在还要每天三个。。。
- 爱惜自己的身体,人生道路才会走得更顺畅
- 家是一生所爱,是永远的港湾
- 现在自律努力,未来才会闪闪发光
不用说,这个编辑在让人变得更好的道路上已经编不下去了
重复了,今天居然还有自律
善良、能扛事、真诚、自律、专注,欣赏,今天是 优秀,靠谱,懂得(别人?自己),今天 注意身体、顾家、自律
注意身体 也是一定程度的自律
遂
后面不再整理这个夜读的关键词
没什么意思 不是一条严谨的线
摘摘里面那优美(鸡汤)的句子吧
一个好的身体是我们做事的前提,也是我们最大的底气。千万不要等到身体拉响警报,才追悔莫及。
过年回家,不要嗨过头啦,否则小心年后综合征!

第四篇(跳)人民日报 来啦 新闻早班车
要闻
- 中央财政紧急下达1.41亿元,支持低温雨雪冰冻灾害地区公路应急抢通。(大概率会拿来填补地方上CZ的kongQue,以前我们潮汕地区总是发大水,拨了很多米,最后水更大了,说起这个物资,其中更是发生很多事,有机会后面再聊)
- 文旅部表示,各地在春节期间将发放超6亿元的文旅消费惠民补贴。(旅游,旅游,要是我现在还有玩G,那么我就在这里打打野)
- 6日,海关总署发布横琴粤澳深度合作区进口货物免税管理新规。(最近的苹果的Vision Pro从这里过是不是免税,又省了一笔钱,不过买这个的会在意这点税吗?昨天去看租房,G中介说别人的管理费都是200元,我的才100多,很便宜啦,他也不看看被人租的都是一个月3k-4K的房子。。。)
社会
-
文旅部发布公告,北京(通州)大运河文化旅游景区等21家旅游景区被正式确定为国家5A级旅游景区。(定吧,全都是5A)
-
国家电影局推出优惠观影活动,11家金融机构将在春节期间投入超3000万元的数字人民币观影消费补贴。(不是9.9,再送一桶爆米花,我不去哈)
-
安徽阜阳护士胡礼秀返乡途中偶遇车祸,一男子脉搏渐弱失去意识,胡礼秀立即上前施救,直到救护车赶来。(医生护士真是好职业,功德+++)

政策
- 北京发文,在京具备购房资格的四类家庭,可以在通州区购买一套商品住房。(我知道这一条跟我没关系,因为我不是缺少资格,我是缺少买房子的米)
- 河南明确,今年6月底前,各地完成辖区内农村留守儿童和困境儿童全面摸底排查。(支持,祖国的未来就应该多顾及!这些的地方的留守儿童也确实多)
- 海南发布公告,今天起,海口等11市县首套住房购房商贷最低首付款比例调整为20%。(要我说,现在呀,没钱的不烦恼,烦恼的是有钱的,这些个文书,宣传呀,都在让他们把口袋的米拿出来,割一割,有钱的还在思考,如何被割会好点;像我这种,割过之后,剩下死心也安心了)

结尾
今天是我假期第一天
还在考虑回不回家
回家可能就不自律做不到每天更新
不回家 心有点难受
还在过父母那关
望我能坚持努力

引用科比·布莱恩特的一句话吧
总有那么一天,你的负担将变成礼物,你受的苦将照亮你的路。
共勉!
那么
