基于LSTM模型的时间序列预测(车厢重量预测),Python中Keras库实现LSTM,实现预测未来未知数据,包括参数详解、模型搭建,预测数据
简介
LSTM是一种常用的循环神经网络,其全称为“长短期记忆网络”(Long Short-Term Memory Network)。相较于传统的循环神经网络,LSTM具有更好的长期记忆能力和更强的时间序列建模能力,因此在各种自然语言处理、语音识别、时间序列预测等任务中广泛应用。
问题
场景:对一节火车进行装载货物,火车轨道上有仪表称,我们希望利用LSTM模型对装车数据进行训练、预测,已经收集到12小时内的仪表重量的时序数据,通过训练模型从而预测未来时间段内的仪表数据,方便进行装车重量调控。
思路
首先训练模型预测未来时间段内数据的能力,训练完后,我们使用收集的数据预测第13h的数据,预测后,我们将13h的数据看做真实数据,放入历史数据中,再用它预测第14h的数据,依次类推,最终预测完未来的数据。
代码
导入模块
import math
import torch
import keras
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import read_csv,Series
from keras.models import Sequential
from keras.layers import LSTM,Dense,Dropout,Activation
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
读入数据
# 定义随机种子,以便重现结果
np.random.seed(7)
# 加载数据
dataframe = read_csv('装车训练数据.csv',encoding='gbk',usecols=[0],engine='python')
print(dataframe)
data = dataframe.values
data = data.astype('float32')
dataframe = read_csv('文件名',usecols=[0],encoding='gbk', engine='python')、
usecols=[0]:读入文件的第一列数据(该文件第一列数据为仪表重量,针对仪表重量的时间序列预测)
encoding='gbk':编码方式为gbk,如果乱码报错可更改编码方式:encoding='utf-8'

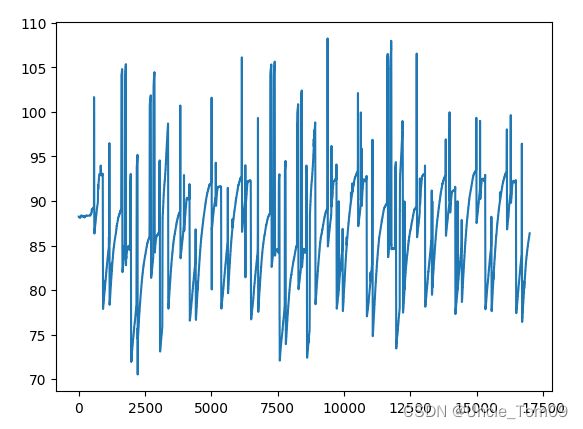
数据归一化,分割训练集和测试集
数据缩放到0~1的范围,加快收敛,满足LSTM细胞门的输入范围
train_size是训练集和测试集的分割点,此处将数据集分为80%的训练集和20%的测试集
如要更改训练集和测试集的比例,例如将数据集分为60%的训练集和40%的测试集
更改:train_size = int(len(data) * 0.6)
# # 缩放数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
# 分割数据作为训练集和测试集
train_size = int(len(data) * 0.8)
test_size = len(data) - train_size
train, test = data[0:train_size, :], data[train_size:len(data), :]
设置数据预测步长,转为监督学习格式
features为数据的特征,此处设置为100,也就是将100个数据为一个序列
# 预测数据步长为100,100个数据为一组预测1个数据,100->1 步长需要和保存模型时的一致 步长越小对现有数据集的拟合越好,对未来值的预测越差
look_back = 100
def create_dataset(data, look_back=1):
dataX, dataY = [], []
for i in range(len(data) - look_back - 1):
a = data[i:(i + look_back), 0]
dataX.append(a)
dataY.append(data[i + look_back, 0])
return np.array(dataX), np.array(dataY)
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# 重构输入数据格式 [samples, time steps, features] = [样本数,1,100]
# 输入必须是三维 包括样本(数据的行) 时间步 特征(数据的行)
#samples 输入LSTM的样本的数量 timesteps 窗口大小,即截取的样本长度(拿多长的样本进行预测) features 样本的维度
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
print(trainX)
print(trainX.shape)
print(trainY)
print(trainY.shape)trainX:

trainY:
![]()
trainX与trainY形成100->1的监督学习格式,trainX的每一条序列有100个数据,对应trainY的1个数据
重构输入数据格式 [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
samples:输入LSTM的样本的数量
timesteps:窗口大小,设置为1,即每次处理一条序列
features:样本的维度,即每条序列中包含多少数据
搭建LSTM模型
1.定义网络
model = Sequential()
model.add(LSTM(units, input_shape=(1, features),return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1))
神经网络在Keras中定义为层序列,这些层的容器是Sequential类。
第一步是创建Sequential类的实例。然后,创建层并按照它们应连接的顺序添加它们。
由存储器单元组成的LSTM复现层称为LSTM()。通常跟随LSTM层并用于输出预测的完全连接层称为Dense()。
units:神经元的数量 ,在第一层LSTM网络中设置为256,第二层中设置为128,
神经元的数量增加,模型计算量也会增加,耗时更久,模型会更准确一些
input_shape = (TIME_STEPS,INPUT_SIZE))
TIME_STEPS:每个输入的样本序列长度,INPUT_SIZE:每个序列里面具有多少个数据。
Dropout为随机丢弃一些神经元,防止过拟合
2、编译网络
model.compile(loss='mean_squared_error', optimizer=keras.optimizers.SGD(lr=0.001))
loss函数:均值误差 mean_squared_error
optimize优化器选择随机梯度下降(sgd,学习率lr=0.001
常用优化算法:sgd、 Adam、RMSprop等优化算法
模型的结构 model.summary()
3.适合网络
history = model.fit(trainX, trainY, epochs=25, batch_size=1, verbose=1,validation_data=(testX, testY))
将trainX,trainY送入模型学习
epochs:训练轮数
batch_size:批大小
verbose:日志信息
validation_data:对测试集进行评估的函数
4.评估网络
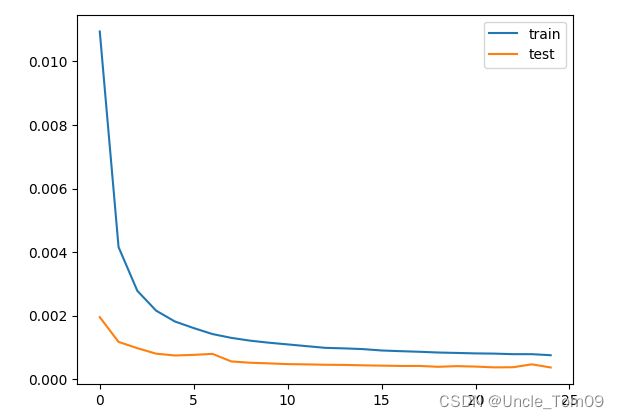
绘制训练集和测试集的损失函数
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
保存训练模型,生成lstm.pt权重文件
torch.save(model, 'lstm.pt')
后续可以直接读取权重文件
model = torch.load('lstm.pt')
5.网络预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
使用model.predict()进行预测
train=True
if train:
# 构建 LSTM
# 1.定义网络
model = Sequential() # 创建层序列 Sequential类
model.add(LSTM(256, input_shape=(1, look_back),
return_sequences=True)) # units 神经元的数量 input_shape = (TIME_STEPS,INPUT_SIZE)),第一个代表每个输入的样本序列长度,第二个元素代表
# 每个序列里面的1个元素具有多少个输入数据。
model.add(Dropout(0.2)) # Dropout把上一层神经元进行随机丢弃,减少过拟合
model.add(LSTM(128, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1)) # 全连接层 用于输出预测
# model.add(Activation("tanh"))
# 2.编译网络
model.compile(loss='mean_squared_error',optimizer=keras.optimizers.SGD(lr=0.001)) # 编译网络 优化算法 sgd--随机梯度下降 Adam RMSprop等优化算法
print(model.summary())
# 3.适合网络
history = model.fit(trainX, trainY, epochs=25, batch_size=1, verbose=1,
validation_data=(testX, testY), ) # verbose是日志显示,有三个参数可选择,分别为0,1和2。
# 4.评估网络
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
# loss,accuracy=model.evaluate(trainX,trainY)
torch.save(model, 'Tang-model.pt') # 16
else:
# #加载模型
model = torch.load('Tang-model.pt')模型结构:

训练过程:

训练集和测试集预测
#5.预测
# 对训练数据的Y进行预测
trainPredict = model.predict(trainX)
# 对测试数据的Y进行预测
testPredict = model.predict(testX)
# 对数据进行逆缩放
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY]) 
模型评估指标
# 计算RMSE误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# 计算均方误差(MSE)
mse = mean_squared_error(testY[0], testPredict[:,0])
# 计算R平方值(R^2)
r2 = r2_score(testY[0], testPredict[:,0])
# 计算平均绝对误差(MAE)
mae = mean_absolute_error(testY[0], testPredict[:,0])
# 计算平均绝对百分比误差(MAPE)
mape = np.mean(np.abs((testY[0] - testPredict[:,0]) / testY[0])) * 100
#对称平均绝对百分比误差(SMAPE)
smape=2.0 * np.mean(np.abs(testPredict[:,0] - testY[0]) / (np.abs(testPredict[:,0]) + np.abs(testY[0]))) * 100
# 模型评估性能指标
print(f"均方误差 (MSE): {mse:.2f}")
print(f"R平方值 (R-Square): {r2:.2f}")
print(f"平均绝对误差 (MAE): {mae:.2f}")
print(f"平均绝对百分比误差 (MAPE): {mape:.2f}%")
print(f"对称平均绝对百分比误差 (SMAPE): {smape:.2f}%")
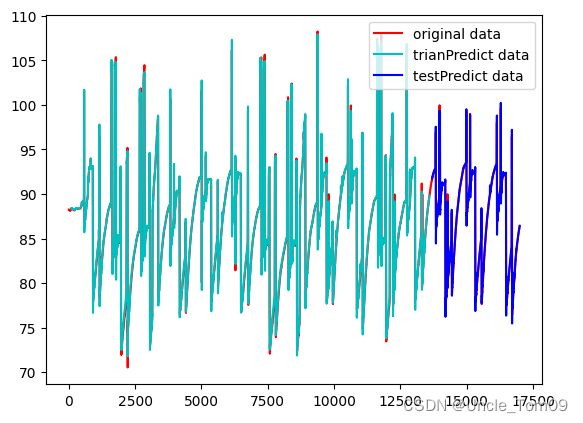
绘制图像
# 构造一个和dataset格式相同的数组 dataset为总数据集
trainPredictPlot = np.empty_like(data)
# 用nan填充数组
trainPredictPlot[:, :] = np.nan
# 将训练集预测的Y添加进数组
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# 构造一个和dataset格式相同的数组 把预测的测试数据放进去
testPredictPlot = np.empty_like(data)
testPredictPlot[:, :] = np.nan
# 将测试集预测的Y添加进数组
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(data)-1, :] = testPredict
# 画图
plt.plot(scaler.inverse_transform(data),color='r',label='original data')
plt.plot(trainPredictPlot,color='g',label='trianPredict data')
plt.plot(testPredictPlot,color='b',label='testPredict data')
plt.legend()
plt.show()
对未来时间预测
利用测试集最后一个步长的数据进行预测,预测后得到的第一个预测值和之前的数据输入到模型中再预测,以此类推。
未来数据的预测基于测试集的最后一个序列(也就是features,前面设置为100),利用这100个数据预测出1个数据
然后再利用序列的第2~100个数据以及预测出的这个数据,形成一个序列,再预测出第2个数据,以此类推
这种预测是基于预测数据的预测,也就是说用最后100个数据预测位置的100个数据可能相对准确一些,如果用最后100个数据预测未知的500个数据,可能就不准确了
# 加载训练模型
model = torch.load('Tang-model.pt')
#读入测试集预测的后三个数据
n=look_back
testpredict=testPredictPlot[-n-1:-1]
a=[]
for i in range(len(testpredict)):
a.append(testpredict[i][0])
print(a)
#预测后100数据
def Perdict(a,n):
Input=a[-n:]
Input = np.array(Input)
Input = Input.astype('float32')
Input = scaler.fit_transform(Input.reshape(-1, 1))
Input = Input.reshape(-1, 1)
Input = np.reshape(list(Input[-n:]), (1, Input.shape[1], len(Input)))
featruePredict = model.predict(Input)
# #将标准化数据逆缩放
featruePredict = scaler.inverse_transform(featruePredict)
print(featruePredict[0][0])
return featruePredict[0][0]
for i in range(len(testpredict)):
t=Perdict(a,n)
a.append(t)
print("预测结果为:",a)
plt.plot(a)
plt.ticklabel_format(style='plain')
plt.show() 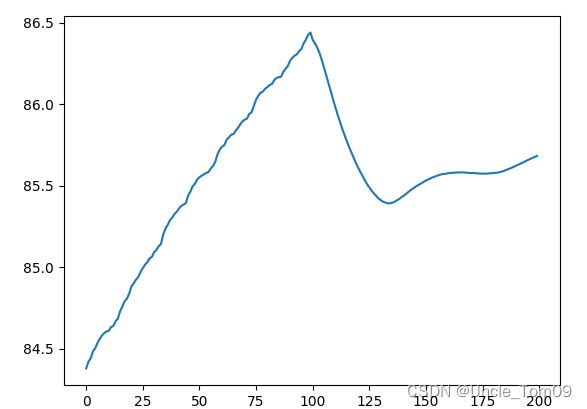
完整代码
import math
import torch
import keras
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import read_csv,Series
from keras.models import Sequential
from keras.layers import LSTM,Dense,Dropout,Activation
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
# 定义随机种子,以便重现结果
np.random.seed(7)
# 加载数据
dataframe = read_csv('装车训练数据.csv',encoding='gbk',usecols=[0],engine='python')
print(dataframe)
data = dataframe.values
data = data.astype('float32')
# # 缩放数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
# 分割数据作为训练集和测试集
train_size = int(len(data) * 0.8)
test_size = len(data) - train_size
train, test = data[0:train_size, :], data[train_size:len(data), :]
# 预测数据步长为100,100个数据为一组预测1个数据,100->1 步长需要和保存模型时的一致 步长越小对现有数据集的拟合越好,对未来值的预测越差
look_back = 100
def create_dataset(data, look_back=1):
dataX, dataY = [], []
for i in range(len(data) - look_back - 1):
a = data[i:(i + look_back), 0]
dataX.append(a)
dataY.append(data[i + look_back, 0])
return np.array(dataX), np.array(dataY)
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# 重构输入数据格式 [samples, time steps, features] = [样本数,1,100]
# 输入必须是三维 包括样本(数据的行) 时间步 特征(数据的行)
#samples 输入LSTM的样本的数量 timesteps 窗口大小,即截取的样本长度(拿多长的样本进行预测) features 样本的维度
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
print(testX.shape)
train=True
if train:
# 构建 LSTM
# 1.定义网络
model = Sequential() # 创建层序列 Sequential类
model.add(LSTM(256, input_shape=(1, look_back),
return_sequences=True)) # units 神经元的数量 input_shape = (TIME_STEPS,INPUT_SIZE)),第一个代表每个输入的样本序列长度,第二个元素代表
# 每个序列里面的1个元素具有多少个输入数据。
model.add(Dropout(0.2)) # Dropout把上一层神经元进行随机丢弃,减少过拟合
model.add(LSTM(128, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1)) # 全连接层 用于输出预测
# model.add(Activation("tanh"))
# 2.编译网络
model.compile(loss='mean_squared_error',optimizer=keras.optimizers.SGD(lr=0.001)) # 编译网络 优化算法 sgd--随机梯度下降 Adam RMSprop等优化算法
print(model.summary())
# 3.适合网络
history = model.fit(trainX, trainY, epochs=25, batch_size=1, verbose=1,
validation_data=(testX, testY), ) # verbose是日志显示,有三个参数可选择,分别为0,1和2。
# 4.评估网络
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
# loss,accuracy=model.evaluate(trainX,trainY)
torch.save(model, 'Tang-model.pt') # 16
else:
# #加载模型
model = torch.load('Tang-model.pt')
#5.预测
# 对训练数据的Y进行预测
trainPredict = model.predict(trainX)
print(trainPredict.shape)
# 对测试数据的Y进行预测
testPredict = model.predict(testX)
# 对数据进行逆缩放
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算RMSE误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# 计算均方误差(MSE)
mse = mean_squared_error(testY[0], testPredict[:,0])
# 计算R平方值(R^2)
r2 = r2_score(testY[0], testPredict[:,0])
# 计算平均绝对误差(MAE)
mae = mean_absolute_error(testY[0], testPredict[:,0])
# 计算平均绝对百分比误差(MAPE)
mape = np.mean(np.abs((testY[0] - testPredict[:,0]) / testY[0])) * 100
#对称平均绝对百分比误差(SMAPE)
smape=2.0 * np.mean(np.abs(testPredict[:,0] - testY[0]) / (np.abs(testPredict[:,0]) + np.abs(testY[0]))) * 100
# 模型评估性能指标
print(f"均方误差 (MSE): {mse:.2f}")
print(f"R平方值 (R-Square): {r2:.2f}")
print(f"平均绝对误差 (MAE): {mae:.2f}")
print(f"平均绝对百分比误差 (MAPE): {mape:.2f}%")
print(f"对称平均绝对百分比误差 (SMAPE): {smape:.2f}%")
# 构造一个和dataset格式相同的数组 dataset为总数据集
trainPredictPlot = np.empty_like(data)
# 用nan填充数组
trainPredictPlot[:, :] = np.nan
# 将训练集预测的Y添加进数组
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# 构造一个和dataset格式相同的数组 把预测的测试数据放进去
testPredictPlot = np.empty_like(data)
testPredictPlot[:, :] = np.nan
# 将测试集预测的Y添加进数组
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(data)-1, :] = testPredict
# 画图
plt.plot(scaler.inverse_transform(data),color='r',label='original data')
plt.plot(trainPredictPlot,color='g',label='trianPredict data')
plt.plot(testPredictPlot,color='b',label='testPredict data')
plt.legend()
plt.show()
# 加载训练模型
model = torch.load('Tang-model.pt')
#读入测试集预测的后三个数据
n=look_back
testpredict=testPredictPlot[-n-1:-1]
a=[]
for i in range(len(testpredict)):
a.append(testpredict[i][0])
print(a)
#预测后100数据
def Perdict(a,n):
Input=a[-n:]
Input = np.array(Input)
Input = Input.astype('float32')
Input = scaler.fit_transform(Input.reshape(-1, 1))
Input = Input.reshape(-1, 1)
Input = np.reshape(list(Input[-n:]), (1, Input.shape[1], len(Input)))
featruePredict = model.predict(Input)
# #将标准化数据逆缩放
featruePredict = scaler.inverse_transform(featruePredict)
print(featruePredict[0][0])
return featruePredict[0][0]
for i in range(len(testpredict)):
t=Perdict(a,n)
a.append(t)
print("预测结果为:",a)
plt.plot(a)
plt.ticklabel_format(style='plain')
plt.show()
如需数据集:请关注并私信Up 邮箱,看到会及时发送