CV | SAM在医学影像上的模型调研【20240207更新版】
本文主要是SAM(Segment Anything)在医学影像上的数据集,模型及评估方法调研【持续更新】~
1.开源数据集
可参考这篇【数据集 | 基于计算机视觉的医学影像处理数据集_CSDN博客】
2.算法模型
2023.04_SAM
论文:2018.08.05v_Segment Anything
论文地址:2304.02643.pdf (arxiv.org)
代码地址:facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. (github.com)
基础模型,详情请参考【CV | Segment Anything论文详解及代码实现】
2023.04.02v1_SAM-Adapter
论文:SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More
论文地址:2304.09148.pdf (arxiv.org)
两个 MLP 和一个激活函数组成的Adapter。解码器中不输入任何提示。

2023.04_Medical-SAM-Adapter
Adapting Segment Anything Model for Medical Image Segmentation
论文地址:2304.12620.pdf (arxiv.org)
论文代码:KidsWithTokens/Medical-SAM-Adapter: Adapting Segment Anything Model for Medical Image Segmentation (github.com)
对医疗图像分割任务的 SAM 架构进行微调,插入 Adapter 模块。
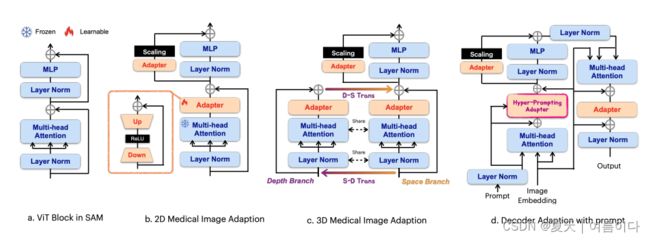
2023.06.01_DeSAM
论文:DeSAM: Decoupling Segment Anything Model for Generalizable Medical Image Segmentation
论文地址:2306.00499.pdf (arxiv.org)
- 修改 SAM 的mask decoder,以解耦mask生成和提示嵌入,同时利用预先训练的权重
- 提示相关的 IoU 模块(PRIM),包括一个交叉注意变压器层和一个 IoU 预测头,丢弃掩码预测头,从交叉注意变压器层提取掩码嵌入
- 提示不变掩码模块(PIMM),CNN结果输出mask

2023.07.17_MedSAM
论文:Segment Anything in Medical Images
论文地址:2304.12306.pdf (arxiv.org)
MedSAM 的目标是创建一种用于细分各种医疗图像的通用工具。为了使 SAM 适应医学图像分割,需要选择适当的用户 Prompt 和网络组件进行微调。SAM 的网络架构包含三个主要组件:图像编码器、提示编码器和掩码解码器。
MedSAM 选择微调掩码解码器组件。图像编码器基于 VIT,它在 SAM 中具有最大的计算开销。为了最大限度地降低计算成本,冻结了图像编码器。提示编码器对边界框的位置信息进行编码,可以从 SAM 中预先训练的边界框编码器中重复使用,因此也会冻结该组件。其余需要微调的部分是掩码解码器。
此外,预先计算了所有训练图像的图像嵌入,以避免重复计算每个提示的图像嵌入,这显著提高了训练效率。掩码解码器只需要生成一个掩码而不是三个掩码,因为在大多数情况下,边界框提示符可以清楚地指定预期的分割目标。
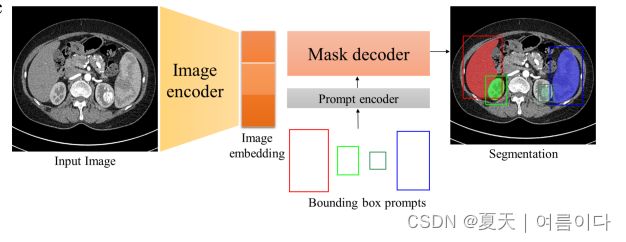
大规模医学图像分割数据集。使用基于边界框的提示。
2023.08_Polyp-SAM++
论文:Polyp-SAM++: Can A Text Guided SAM Perform Better for Polyp Segmentation?
论文地址:
补充文本提示,使用grounded-DINO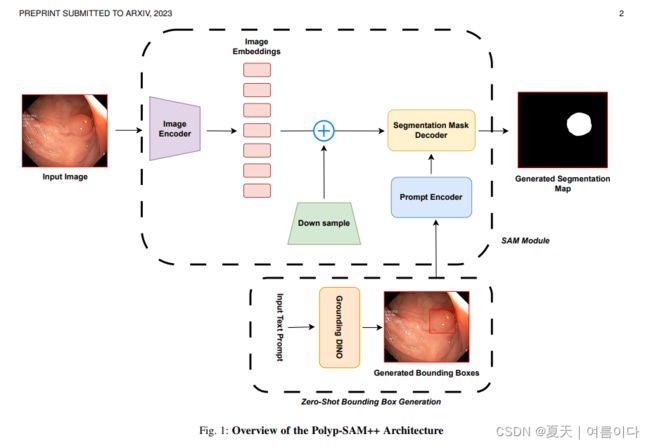
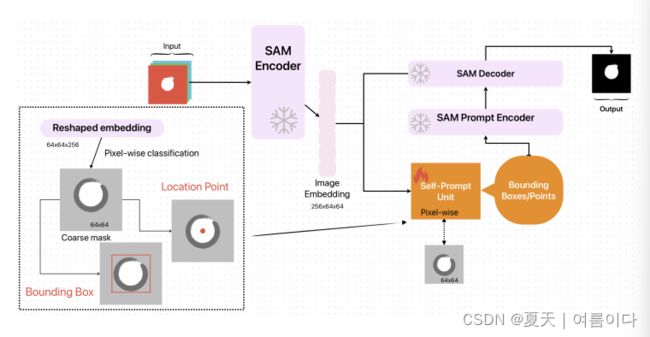
2023.08.15_Self-Prompting Large Vision Models for Few-Shot Medical Image Segmentation
论文地址:2308.07624v1.pdf (arxiv.org)
利用简单的像素分类器自提示 SAM 模型,采取图像嵌入提供边界框和点
2023.08.17_SurgicalSAM
论文:SurgicalSAM: Efficient Class Promptable Surgical Instrument Segmentation
论文地址:2308.08746.pdf (arxiv.org)
- 提出了一个轻量级的基于原型的类提示编码器,直接生成提示嵌入类原型,并消除了显式提示的使用
- 进一步提出了对比原型学习,利用对比损失来获得有区别的学习类原型

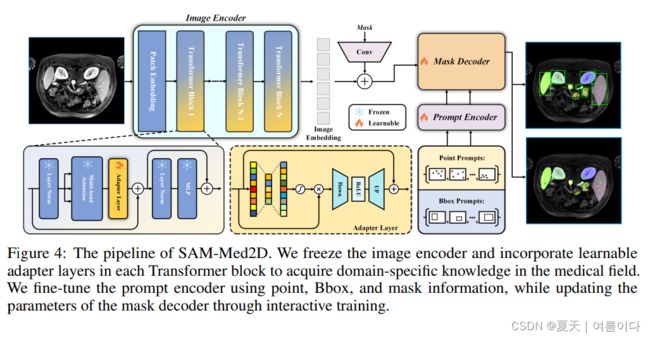
2023.08.31_SAM-Med2d
论文:SAM-Med2D
论文地址:2308.16184.pdf (arxiv.org)
论文代码:OpenGVLab/SAM-Med2D: Official implementation of SAM-Med2D (github.com)
对于 2D 数据集,仅检查像素值是否在 [0, 255] 范围内,并将所有处理后的图像以 PNG 格式保存以保持数据加载的一致性;
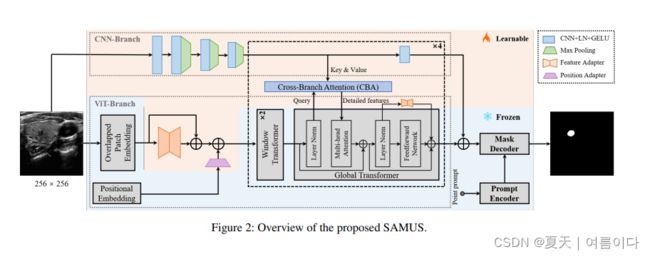
2023.09_SAMUS
论文:SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
论文地址:2309.06824.pdf (arxiv.org)
论文代码:xianlin7/SAMUS (github.com)
- 在 SAM 的基础上,引入了一个并行的 CNN 分支
- 提出位置Adapter和特征Adapter,以适应 SAM 从自然到医学领域
2023.10.03_ Multi-Prompt Fine-Tuning of Foundation Models for Enhanced Medical Image Segmentation
论文:Multi-Prompt Fine-Tuning of Foundation Models for Enhanced Medical Image Segmentation
论文地址:2310.02381.pdf (arxiv.org)

2023.10.29v2_SAM-Med3d
论文:SAM-Med3D
论文地址:2310.15161.pdf (arxiv.org)
论文代码:uni-medical/SAM-Med3D: SAM-Med3D: An Efficient General-purpose Promptable Segmentation Model for 3D Volumetric Medical Image (github.com)
对于 3D 数据集,作者们将每个体积的强度值标准化到 [0, 255] 范围,并沿着 x、y、z 轴提取所有切片图像及其对应的掩码;

2023.11.13v2_MediViSTA-SAM
论文:MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation
论文地址:MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation (arxiv.org)
- 介绍了第一项关于在视频分割上调整SAM的研究,称为MediViSTA-SAM,这是一种专为医学视频分割而设计的新方法。
- 给定视频数据,MediViSTA 时空适配器通过跨帧注意力机制捕获长距离和短距离时间注意力,有效地约束了其将前一帧视频作为参考,同时也有效地考虑了空间信息。
- 通过使用 U 形编码器和改进的掩码解码器来处理不同大小的物体,从而实现了多尺度融合。

3.评估方法
dice 和 iou 都是衡量两个集合之间相似性的度量
3.1.IOU
IoU(Intersection-over-Union)即是预测样本和实际样本的交并比,表达式如下:


# Iou
def Iou(pred,true):
intersection = pred * true # 计算交集 pred ∩ true
temp = pred + true # pred + true
union = temp - intersection # 计算并集:A ∪ B = A + B - A ∩ B
smooth = 1e-8 # 防止分母为 0
iou_score = intersection.sum() / (union.sum() + smooth)
return iou_score- intersection 为两个区域的交集,即两个区域的乘积
- temp 为两个区域的和,(注:这里不是并集,因为没有减去相交的部分)
- union 为两个区域的并集
MIoU
Mean IoU是在所有类别的IoU上取平均值。

3.2.DICE
对于分割过程中的评价标准主要采用Dice相似系数(Dice Similariy Coefficient,DSC),Dice系数是一种集合相似度度量指标,通常用于计算两个样本的相似度,值的范围 0−1 ,分割结果最好时值为 1 ,最差时值为 0
# Dice
def Dice(pred,true):
intersection = pred * true # 计算交集 pred ∩ true
temp = pred + true # pred + true
smooth = 1e-8 # 防止分母为 0
dice_score = 2*intersection.sum() / (temp.sum() + smooth)
return dice_score相关论文
When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation 【paper】
Q&A
【Q&A1】ct和x-ray的区别是什么?
CT(Computed Tomography)扫描和X射线(X-ray)是医学影像学中常用的两种成像技术,它们有一些区别,主要涉及到成像原理和应用领域:
成像原理:
- X射线: X射线是一种电磁辐射,通过人体组织时,不同组织对X射线的吸收程度不同,从而形成影像。X射线成像主要是通过检测射线通过组织的衰减程度来生成影像。
- CT扫描: CT扫描则是利用X射线进行成像,但其采用了旋转式的探测器和计算机算法,能够获取多个方向上的断层图像,进而重建出三维的图像。
图像分辨率:
- X射线: X射线成像一般为二维影像,提供了对骨骼和某些软组织的清晰图像。
- CT扫描: CT扫描提供了更高的图像分辨率,并能够生成多层次、三维的图像,对于观察细微结构和检测病变更为有效。
应用领域:
- X射线: X射线主要用于检查骨折、关节问题以及胸部、腹部等一些基本解剖结构的影像。
- CT扫描: CT扫描在更广泛的情况下使用,可用于头部、胸部、腹部、骨盆等多个部位的成像,对于肿瘤、感染、血管疾病等的诊断具有高度准确性。
辐射剂量:
- X射线: 一般来说,X射线的辐射剂量相对较低。
- CT扫描: 由于CT扫描需要多个X射线投影,因此相对于普通X射线,CT扫描的辐射剂量较高,需要在医学必要性和辐射风险之间进行权衡。
总体而言,X射线成像在一些基础的骨骼检查中仍然是常用的,而CT扫描则提供了更为细致和全面的图像,适用于更广泛的医学应用。在实际应用中,医生会根据具体情况选择合适的成像技术。
参考文献
【1】YichiZhang98/SAM4MIS: Segment Anything Model for Medical Image Segmentation: paper list and open-source project summary (github.com)
【2】23年9月始阅读过的SAM相关文章总结[2024/2/2] - 知乎 (zhihu.com)
【3】【理论+实践】史上最全-论文中常用的图像分割评价指标-附完整代码 - 知乎 (zhihu.com)
【4】分割常用评价指标Dice、Hausdorff_95、IOU、PPV等(打马) - 知乎 (zhihu.com)