【优先级队列(大顶堆 小顶堆)】【遍历哈希表键值对】Leetcode 347 前K个高频元素
【优先级队列(大顶堆 小顶堆)】【排序】Leetcode 347 前K个高频元素
-
- 1.不同排序法归纳
- 2.大顶堆和小顶堆
- 3.PriorityQueue操作
- 4.PriorityQueue的升序(默认)与降序
- 5.问题解决:找前K个最大的元素 :踢走最小的(堆顶的),加入比堆顶大的,最终就是最大的K个
- 6.问题解决:找前K个最小的元素 :维护一个小顶堆,最后从堆顶依次弹出K个,最终就是最小的K个
- 题目347解法
---------------题目链接 Leetcode 347 前K个高频元素-------------------
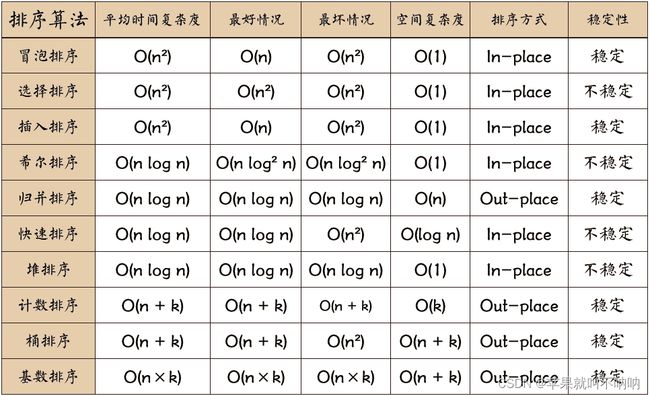
1.不同排序法归纳
2.大顶堆和小顶堆
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。
大顶堆和小顶堆——非常适合在数据集中进行求前k个高频或低频结果的操作。如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
| 队头 | 种类 |
|---|---|
| 最大 | 大顶堆( PriorityQueue从大到小排就是大顶堆) |
| 最小 | 小顶堆( PriorityQueue从小到大排就是小顶堆【默认】) |
3.PriorityQueue操作
- 创建优先级队列【默认创建小顶堆】:
PriorityQueuepriorityQueue = new PriorityQueue<>(); - 使用自定义比较器创建优先队列【创建大顶堆】:
PriorityQueuecustomPriorityQueue = new PriorityQueue<>(Collections.reverseOrder()); - 插入元素: 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
priorityQueue.add(5); - 插入元素: 添加一个元素并返回true ,如果队列已满,则返回false
priorityQueue.offer(5); - 获取队头元素:
Integer head = priorityQueue.peek(); - 弹出队头元素:
Integer removedElement = priorityQueue.poll(); - 删除指定元素
priorityQueue.remove(5); - 获取队列大小:
int size = priorityQueue.size(); - 遍历队列元素:
for (Integer element : priorityQueue) { System.out.println(element); } - 清空队列:
priorityQueue.clear();
4.PriorityQueue的升序(默认)与降序
priority_queue(优先级队列),从小到大排就是小顶堆,从大到小排就是大顶堆。
默认情况下,PriorityQueue的队列是小顶堆(即从小到大【升序】),如果需要大顶堆需要用户提供比较器
// 用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
}
public class TestPriorityQueue {
public static void main(String[] args) {
PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp()); //自定义类的优先队列需要重写比较类作为传入参数
p.offer(4);
p.offer(3);
p.offer(2);
p.offer(1);
p.offer(5);
System.out.println(p.peek());
}
}
简化写法:
PriorityQueue<int[]> my = new PriorityQueue<>((o1,o2) -> o1[1] - o2[1])
向优先级队列中传入int[]数组,排序方式根据数组的索引为[1]的元素按照升序排列
默认情况下:Java实现Comparator排序是升序,根据参数,返回值来判断是否交换
✋可参考下面的链接查看Java实现Comparator排序的方式:
Java中Comparator的升序降序使用博客
Java comparator 升序、降序、倒序从源码角度理解

5.问题解决:找前K个最大的元素 :踢走最小的(堆顶的),加入比堆顶大的,最终就是最大的K个
- 将数组中前K个元素建立一个小根堆( PriorityQueue从小到大排就是小顶堆【默认】)
- 然后用数组中剩下的元素和堆顶元素进行比较。
此时如果比堆顶元素大(说明当前堆中的K个元素一定不是最大的K个),就踢走堆顶的最小的,加入新元素,更新堆顶元素的值,最后比较完数组中剩下的元素,此时堆中就是前K个最大的元素。
6.问题解决:找前K个最小的元素 :维护一个小顶堆,最后从堆顶依次弹出K个,最终就是最小的K个
- 将数组中全部元素建立一个小根堆 (PriorityQueue从小到大排就是小顶堆【默认】)
- 弹出K个元素放进结果数组即可。
题目347解法

时间复杂度O(NlogK)
空间复杂度O(N)
1 使用hashMap存储key和value,key是元素,value是元素出现次数:
HashMap
for(int num:nums){myhashmap.put(num, getOrDefault(num, 0)+1);}
2 初始化优先级队列
在优先队列中存储int[ ],int[ ] 的第一个元素代表数组的值,第二个元素代表了该值出现的次数。
自定义比较器按照出现次数,从队头到队尾的顺序是从小到大排(升序),出现次数最低的在队头(相当于小顶堆)
⭐️⭐️ ⭐️可以记住(o1,o2) -> o1-o2 代表从队顶开始升序排序⭐️⭐️⭐️
⭐️⭐️ ⭐️可以记住(o1,o2) -> o1-o2 代表从队顶开始升序排序⭐️⭐️⭐️
⭐️⭐️ ⭐️可以记住(o1,o2) -> o1-o2 代表从队顶开始升序排序⭐️⭐️⭐️


PriorityQueue
自定义比较器:
(pair1, pair2) -> pair1[1] - pair2[1]
pair1和pair2都是整型数组int[ ],pair1[1] - pair2[1]表示比较的是两个整形数组中的第二个元素,且表示升序排序
*Comparator接口说明:
返回负数,形参中第一个参数排在前面(队头);返回正数,形参中第二个参数排在前面(队头)
⭐️⭐️ ⭐️可以记住(o1,o2) -> o1-o2 代表从队顶开始升序排序⭐️⭐️⭐️

3 使用map.entrySet() 获取key-value的set集合
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
// 循环体
}
map.entrySet(): 是 Map 接口中的一个方法,它返回一个键值对Set。map 是一个实现了 Map 接口的对象,比如 HashMap 或 TreeMap。调用 entrySet() 方法会返回一个包含 Map.Entry 对象的集合。每个 Map.Entry 对象代表了 Map 中的一个键值对。
Map.Entry接口:Map.Entry 是 Java 中的一个接口,用于表示映射(Map)中的一个键值对。在 Java 中,Map 存储的是键值对的集合,而 Map.Entry 就是这个键值对的表示。Map.Entry 接口定义了一些方法,允许你访问键和值。
Map.Entry: 这是增强的 for 循环的声明部分。在每次迭代中,entry 变量会被赋值为 map.entrySet() 中的一个元素,即一个键值对。
for (Map.Entry: 这是增强的 for 循环的语法,用于遍历 map.entrySet() 返回的集合中的每个元素。在循环体中,你可以使用 entry 变量来访问键和值。
举例来说,如果 map 是一个 HashMap,它包含整数键key和整数值value的映射,那么在这个循环中,**entry.getKey()**就是当前键值对的key,**entry.getValue()** 就是当前键值对的value。这种语法的好处是,它简化了遍历 Map 的过程,使得代码更加简洁,不需要显式地使用迭代器。
具体代码实现:
【程序采用判断进行,当优先队列大小小于K的时候将键值对无脑加入,大于的时候进行判断】
(判断如果当前要添加的 myentry.getValue() 大于队列顶部元素 mypriorityqueue.peek()[1] 那就弹出队列元素,添加当前的键值对入队)
class Solution {
public int[] topKFrequent(int[] nums, int k) {
// 初始化hashmap:用于整理统计数据和重复的元素 key:元素 value:元素出现的次数
HashMap<Integer,Integer> myhashmap = new HashMap<>();
// 增强for循环 将nums中数据遍历汇总到hashmap中
for(int num:nums){
myhashmap.put(num, myhashmap.getOrDefault(num,0)+1);
}
// 首先用优先级队列维护一个小顶堆 如果新元素大于堆顶元素就弹出堆顶,加入新元素
PriorityQueue<int[]> mypriorityqueue = new PriorityQueue<>((o1, o2)->o1[1]-o2[1]);
// 答案数组result[]
int[] result = new int[k];
// 遍历hashmap的键值对
for(Map.Entry<Integer,Integer> myentry : myhashmap.entrySet()){
// 维护一个大小为k的小顶堆,如果优先级队列中小于K个元素,那么就无脑加入就行 等于k就需要判断了
if(mypriorityqueue.size() < k){
mypriorityqueue.add(new int[]{myentry.getKey(),myentry.getValue()});
}
// 如果超过k那就要比一下是不是比堆顶元素大,如果大那么就弹出队列元素(即为目前队列中最小的)
else{
if(myentry.getValue() > mypriorityqueue.peek()[1]){
mypriorityqueue.poll();
mypriorityqueue.add(new int[]{myentry.getKey(),myentry.getValue()});
}
}
}
for(int i = k-1; i>=0; i--){
result[i] = mypriorityqueue.poll()[0];
}
return result;
}
}
革新1:for (var x : map.entrySet()) :
在这个上下文中,var 是 Java 10 引入的局部变量类型推断的关键字。它可以在声明变量时根据赋值语句的类型自动推断变量的类型。在这里,var 被用于迭代 map.entrySet(),其中map.entrySet()返回的是一个Set类型。
var x 实际上是推断为 Map.Entry 类型,这使得 x.getKey() 和 x.getValue() 方法能够被正确调用
注意,使用 var 的情况下,编译器会根据上下文推断变量的实际类型,因此程序员无需手动指定类型。这在简化代码并提高可读性方面有一些好处,但有时也可能导致可读性下降,特别是在复杂的代码中。
革新2:
Queue使用时要尽量避免Collection的add()和remove()方法,add()和remove()方法在失败的时候会抛出异常。
使用offer()来加入元素,使用poll()来获取并移出元素。
【程序采用先添加进优先队列,判断队列中超过k后再弹出】
class Solution {
public int[] topKFrequent(int[] nums, int k) {
// 初始化hashmap:用于整理统计数据和重复的元素 key:元素 value:元素出现的次数
HashMap<Integer,Integer> myhashmap = new HashMap<>();
// 增强for循环 将nums中数据遍历汇总到hashmap中
for(int num:nums){
myhashmap.put(num, myhashmap.getOrDefault(num,0)+1);
}
// 首先用优先级队列维护一个小顶堆 如果新元素大于堆顶元素就弹出堆顶,加入新元素
PriorityQueue<int[]> mypriorityqueue = new PriorityQueue<>((o1, o2)->o1[1]-o2[1]);
// 答案数组result[]
int[] result = new int[k];
// 遍历hashmap的键值对
for(var x : myhashmap.entrySet()){
// 利用var局部变量类型推断的关键字,获取map.entrySet()返回的Map.Entry