什么是数据挖掘
文章目录
- 什么是数据挖掘
-
-
- 1.分类问题
- 2.聚类问题
- 3.回归问题
- 数据挖掘相关的标准库
-
- 数据挖掘
- 模型训练
-
- 分类问题
- 聚类问题
- 回归问题
- 关联问题
- 模型集成
- 模型评估
-
- 评估指标
- 混淆矩阵与标准率指标
- 泛化能力评估
什么是数据挖掘
数据挖掘就是寻找数据中隐含的知识并用于生产产业价值。我们在数据中(尤其在大量的数据中)找到一些价值。
##数挖掘有什么用处?
数据挖掘是一种方法,就用它去解决一些问题,比较常见的问题有
1.分类问题
分类问题就是判断一个事物是否符合相关的标准,如判断一条新闻是社会新闻还是时政新闻,就是对已知类别的数据进行学习,为新的内容注明一个类别。
2.聚类问题
聚类与分类不同,聚类的类别预先是不清楚的。聚类就是要去发现这些类别,适合一些不确定的类别场景。
3.回归问题
简单来说,回归问题可以看作解线性方程,最大的特点就是生成的结果是连续的,而分类和聚类的结果是分散的。
通过使用回归的方法构建一个模型拟合已知的数据,然后测量因变量的结果。
数据挖掘相关的标准库
python的标准库是其核心的扩展,有两个能帮助学习的常用包的方法:
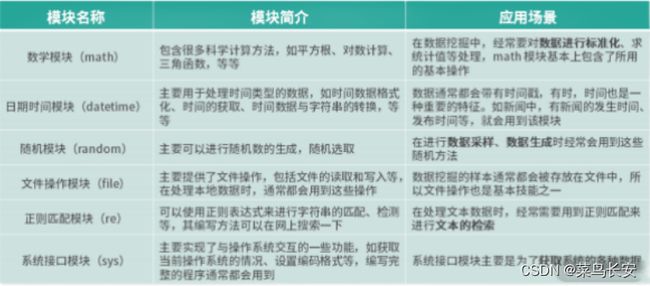
第三方库
- 基础模块
| 名称 | 含义 |
|---|---|
| NumPy | Python 语言扩展程序库,支持大量的维度数组与矩阵运算。 |
| SciPy | 集成了数学、科学和工程的计算包, 它用于有效计算 Numpy 矩阵,使 Numpy 和 Scipy 协同工作。 |
| Matplotlib | 专门用来绘图的工具包,可以使用它来进行数据可视化。 |
| pandas | 数据分析工具包,它基于 NumPy 构建,纳入了大量的库和标准数据模型。 |
-
机器学习
机器学习常用的库也有 4 个,包含了基础数据挖掘、图像处理与自然语言处理常用算法。它们可以支撑 日常工程中的常见算法处理方案
| 名称 | 含义 |
|---|---|
| scikit-learn | 基于 SciPy 进行延伸的机器学习工具包,包含大量的机器学习算法模型,有 6 大基本 功能:分类、回归、聚类、数据降维、模型选择和数据预处理。 |
| OpenCV | 非常庞大的图像处理库,实现了非常多的图像和视频处理方法,如图像视频加载、基 础特征获取、边缘检测等,处理图像通常都需要其支持。 |
| NLTK | 比较传统的自然语言处理模块,自带很多语料,以及全面的传统自然语言处理算法, 比如字符串处理、卡方检验等,非常适合自然语言入门使用。 |
| Gensim | 包含了浅层词嵌入的文本处理模块,以及常用的自然语言处理相关方法,如 TF-IDF、 word2vec 等模型。 |
-
深度学习平台
平台名称 开发平台 优点 TensorFlow 谷歌 相对成熟、应用广泛、服务全面、提供学习视频和其认证计划。 PyTorch Facebook 支持更加快速地构建项目。 PaddlePaddle 百度 中文文档全面,对于汉语的相关模型比较丰富。
数据挖掘
根据前人总结的方法论,我们在开始做数据挖掘的时候需要有一些准备。
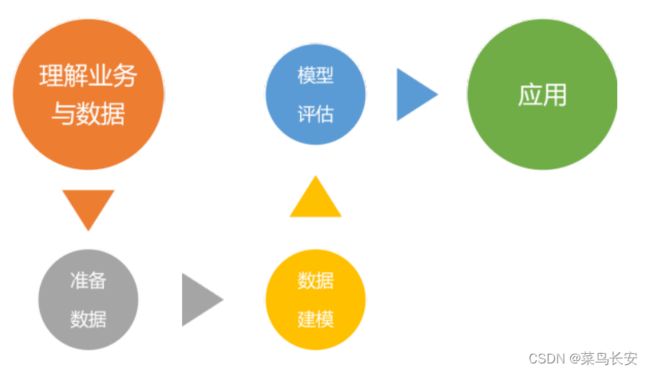
模型训练
对于要解决的问题往往有共同点,针对每一类型的问题,就可以用相对应的算法,比如
分类问题
比如:电影质量是好还是差,风险内容是有风险还是无风险,情感是正向的还是负向的。
分类是有监督的学习过程,分类问题首先要有一批已经有标签结果的数据,经过分类算法的学习,就可以预测新的数据和新的未知数据的分类。如果缺少这些数据信息,就没有办法进行分类,就要考虑使用其他的算法,如聚类算法。或者处理数据,通过人工进行标注。
分类方法中包含3中情况:
- 二分法 :这是最简单的一种,问题答案只有“是”,“否”。在处理用户内容时,首先要做一个较大的判断。eg:判断一群人是否是旅游的
- 多分类 :在二分类的基础上,将标签可选范围扩大。要给一条内容标注它的玩法,那种类就有很多种了,eg:跑步,游泳,登山,骑车等等
- 多标签分类 :在多分类的基础上再升级的方法。对于二分法和多分类,一条内容最后的结果只有一个,标签之间是互斥的关系。但是多标签分类下的一条数据可以被标注上多个标签。eg:一个人可以打篮球,也可以踢足球,还可以跑步。这两者并不冲突
由于分类问题众多,所以用来解决分类问题的算法也非常多,比如:KNN算法,决策树算法,随机森林,SVM等等,都可以解决分类问题。
聚类问题
跟聚类不同,聚类是无监督的,简单来说就是,只知道一些数据,而且需要为这些数据分类,划分的类有多少个不清楚,数量的基数很大。
聚类就是要划分小组,通常小组之间可能有4中情况:
- 互斥:小组和小组之间没有交集,只能存在于一个小组中。划分的方法通常用于互斥的小组,划分的方法就好像在数据之间画几条线,把数据分成几个小组。划分完之后,数据都会有自己的类别。
- 相交:小组和小组之间有交集。可以使用基于密度的聚类,用来解决数据形状不均匀的情况,有些数据集分布并不均匀,而 是呈现不规则的形状,而且组和组之间有一片空白区域,这个时候用划分的方法就很难处理,但是 基于密度的聚类不会受到分布形状的影响,只是根据数据的紧密程度去聚类。
- 层次:一个大组还可以细分成若干个小组,包含的关系。基于层次的聚类,需要使用对数据细分情况,
- 模糊:一个用户并不绝对属于某个小组,只是用概率来表示某个小组的关系。 这种聚类方法首先假设我们的数据符合某种概率分布模型,比如说 高斯分布或者正态分布, 那么对于每一种类别都会有一个分布曲线,然后按照这个概率分布对数 据进行聚类,从而获得模糊聚类的关系。
回归问题
与分类十分相似,都是根据已知的数据去学习,然后为新的数据进行预测,不同的地方是,分类方法输出的结果是离散的,回归的方法输出的结果是连续的

这张图说明不管是线性的还是非线性的数据,都可以使用回归分析。
可以看到,数据散落在坐标系上,通过学习你可以得到一条线,较好地拟合了这些数据。这条线可能不 通过任何一个数据点,而是使得所有数据点到这条线的距离都是最短的,或者说是损失最小的。根据这 条线,如果给出一个新的 x,那么你就能算出对应的 y 是多少。
关联问题
关联问题的方法就是关联分析,这是一种无监督学习,它的目标就是挖掘隐藏在数据中的关联模式并加以利用,分析关联是要在已有的数据中寻找数据的相关关系,所以,关联分析被广泛地用于各种商品销售分析、相关推荐系统分析、用户行为分析等情况。
模型集成
每个问题都可以通过相应的机器学习算法来进行解决。但 是,在实践的时候,很多问题不是靠一个算法、一个模型就能解决的,往往要针对具体的细节使用多个 模型以获得最佳效果,所以就要用到模型集成。
模型集成也叫做集成学习,就是整合多个模型来提升整体的效果。
既然是要合并多个模型,那么很容易想到训练多个并列的模型,或者串行地训练多个模型。
- Bagging(装袋法): 比如多次随机抽样构建训练集,每构建一次,就训练一个模型,最后对多 个模型的结果附加一层决策,使用平均结果作为最终结果。随机森林算法就运用了该方法,

- Boosting(增强法): 这个就是串行的训练,即每次把上一次训练的结果也作为一个特征,不断 地强化学习的效果
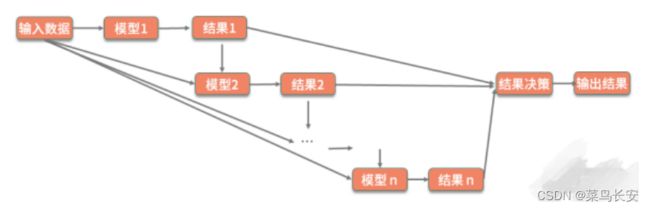
- Stacking(堆叠法): 这个方法比较宽泛,它对前面两种方法进行了扩展,训练的多个模型既可 以进行横向扩展,也可以进行串行增强,最终再使用分类或者回归的方法把前面模型的结果进行整 合。其中的每一个模型可以使用不同的算法,对于结构也没有特定的规则。所以,在使用堆叠法时,就需要你在具体业务场景中不断地去进行尝试和优 化,以达到最佳效果。
模型评估
评估指标
混淆矩阵与标准率指标
标准率相关指标是在模型评估时最受关注的指标,它直接反映了一个模型对于样本数据的学习情况,是一种标准化的检验。
我们把这 1000 张图放进分类器进行分类计算,每张图都会得到一个预测结果,通过对预测结果的统计 可以知道,被模型预测为 “是” 的图片有 770 张,被模型预测为 “否” 的图片有 230 张。这个时候每张图 上会有两个结果:一个人工标注结果、一个模型预测结果。根据这两个数据的统计,可以得到一个混淆 矩阵:
| 样本 1000 份 | 模型预测:是 | 模型预测:否 |
|---|---|---|
| 人工标注:是 | 745(TP) | 55(FN) |
| 人工标注:否 | 25(FP) | 175(TN) |
矩阵中包含以下 4 种数值:
- 真阳性(True Positive,TP):小猪图被判定为小猪图。样本的真实类别是正例,并且模型预测的 结果也是正例(在本案例中此数值为 745)。
- 真阴性(True Negative,TN):不是小猪图被判定为不是小猪图。样本的真实类别是负例,并且 模型将其预测成为负例(在本案例中此数值为 175)。
- 假阳性(False Positive,FP):不是小猪图被判定为小猪图。样本的真实类别是负例,但是模型将 其预测成为正例(在本案例中此数值为 25)。
- 假阴性(False Negative,FN):小猪图被判定为不是小猪图。样本的真实类别是正例,但是模型 将其预测成为负例(在本案例中此数值为 55)。
泛化能力评估
泛化能 力反映的是模型对未知数据的判断能力,因为在数据挖掘中,数据的维度 通常有很多,而且数据也都是非标准值,任意记录之间的数据都会存在着差异,所以泛化能力好的模型 在数据存在着波动的情况下,仍然能够做出正确的判断。
- 过拟合与欠拟合
我们通过两个指标可以评估模型的泛化能力是好还是坏,那就是过拟合(overfitting)和欠拟合 (underfitting)。
过拟合:模型在训练集上表现良好,而在测试集或者验证集上表现不佳。这就是说,模型对样本学习有 些过度了,已经进入了死记硬背的程度,而不是掌握了普适规律,这个时候可以说泛化能力比较差。
欠拟合:在训练集和测试集上的表现都不好。这就是说模型连最基本的内容都没有学到,比如老师教你 1+1=2、1+2=3,考试也考 1+1=2,结果还是做错了。
eg:通常情况下,我们的小猪图都像左侧一样,右侧有两张图,上面一张可以看出仍然是小猪图,但是后背 上的线条有一个缺口,如果此时模型告诉我们,这个后背上有个缺口,这不是小猪图,那么这时就出现 了过拟合(判断条件过于苛刻)。右下侧是一张小羊图,如果模型告诉我们这个也有四条腿,这个是小 猪,那就是欠拟合(特征学习不完全)。
考试也考 1+1=2,结果还是做错了。
eg:通常情况下,我们的小猪图都像左侧一样,右侧有两张图,上面一张可以看出仍然是小猪图,但是后背 上的线条有一个缺口,如果此时模型告诉我们,这个后背上有个缺口,这不是小猪图,那么这时就出现 了过拟合(判断条件过于苛刻)。右下侧是一张小羊图,如果模型告诉我们这个也有四条腿,这个是小 猪,那就是欠拟合(特征学习不完全)。
