数据分析案例 - 人力资源数据
目录
1.了解该数据集的基本信息
2.对变量进行描述性统计
3.数据清洗
4.计算数值型变量的相关系数
5.使用交叉表(crosstab)统计不同部门员工的学历构成
6.使用数据透视表(pivot_table)统计不同部门、不同性别员工的流失率:
7.绘制反映不同性别员工占比的饼图(pie chart)
8.绘制不同部门员工人数的柱状图(bar chart)
9.绘制不同性别员工薪酬的箱型图(box plot)
10.绘制员工年龄分布的直方图(histogram)
11.绘制员工年龄和薪酬的散点图(scatter plot)
12. “快乐的员工绩效高?”分析
13. 回归分析检验出差和加班是否会显著降低员工的工作满意度
14. 该企业员根据你所学的管理学知识
15.其它有价值的分析结果
使用Python完成对‘HR-Employee-Attrition.csv’文件进行数据分析,并撰写分析报告。
该文件源自某大型企业人力资源管理系统,各列变量名含义如下:
- Age:年龄
- Sex:性别
- Gender:0-女性,1-男性
- NumCompaniesWorked:工作过的企业数量
- TotalWorkingYears:总工龄
- YearsAtCompany:本企业工龄
- MaritalStatus:婚姻状态
- BusinessTravel:出差,0-不出差,1-偶尔出差,2-经常出差
- OverTime:加班,0-无加班,1-有加班
- Department:部门
- DistanceFromHome:工作地距离家庭地址距离
- Education:教育背景,1-大专以下,2-大专,3-本科,4-硕士,5-博士
- JobSatisfaction:工作满意度(分值越高越满意)
- JobInvolvement:工作投入度(分值越高投入度越高)
- WorkLifeBalance:工作生活平衡(分值越高表示工作生活平衡程度越高)
- PerformanceRating:绩效(分值越高绩效越高)
- MonthlyIncome:月薪
- Attrition:离职,0-未离职,1-已离职
1.了解该数据集的基本信息
import pandas as pd
data = pd.read_csv(r"C:\Users\Terry\Desktop\HR-Employee-Attrition.csv")
data.head()
可以得出该数据共有1472行,18个字段,其中数据类型为浮点型字段1个,整型字段13个,还有3个字段为字符型,数据大小为207.1KB。
2.对变量进行描述性统计
使用data.describe()对各字段的数量、平均数、方差、最大最小值分位数做以上的描述性统计,也可以从下面的分布直方图掌握各字段的数据分布情况。
data.describe()
import matplotlib.pyplot as plt
# matplotlib的中文显示设置
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 显示中文
# matplotlib的负数显示设置
plt.rcParams['axes.unicode_minus'] = False # 显示负数
# 输出高清图像
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
# 绘制各个字段的直方图
data.hist(figsize=(10, 6), bins=10)
plt.tight_layout()
plt.show()


3.数据清洗
3.1判断是否存在重复值,如果存在,删除重复值;
# 重复值 – 处理
# 检查是否存在重复值
duplicates = data.duplicated(keep=False)
# 统计重复值的数量
num_duplicates = duplicates.sum()
# 显示重复值
duplicated_rows = data[duplicates]
print("重复的行:")
# 显示重复值的数量
print("重复值的数量:", num_duplicates)
duplicated_rows
# 删除重复值
print("删除重复值之前的数据数量为:" + str(data.shape[0]))
data = data.drop_duplicates()
print("删除重复值之后的数据数量为:" + str(data.shape[0]))

可以观察到有两组数据重复,应各保留一条,删除重复值如下:

3.2判断是否存在缺失值,如果存在使用均值替换缺失值:
# 缺失值 - 均值填充
# missingno查看数据缺失值
import missingno as msno
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
msno.matrix(data, labels=True)
data.isna().sum()
# 均值填充
# 计算 "MonthlyIncome" 字段的均值
mean_income = data['MonthlyIncome'].mean()
# 使用均值填充缺失值
data['MonthlyIncome'].fillna(mean_income, inplace=True)
data.isna().sum() # 验证数据已经没有缺失值

通过missingno包可视化缺失值,明显发现MonthlyIncome列存在四条缺失值,随后用data.isna().sum()查看缺失的具体情况:发现确实只有MonthlyIncome存在缺失值。
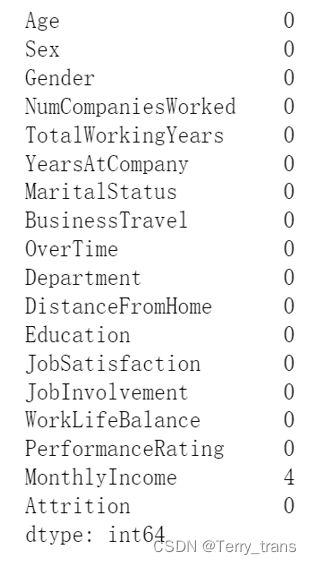
随后用均值填充,填充结果如下:可见已经没有缺失值了

4.计算数值型变量的相关系数
# 相关性系数
# 热力图绘制
# 忽略warnings
def enhanced_corr_heatmap(data):
"""绘制数据皮尔逊相关性系数的热力图(下三角显示)"""
# 导包
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
# matplotlib的图像大小和字体显示设置
plt.figure(figsize=(15, 8)) # 可同比例放大
plt.rcParams['font.sans-serif'] = ['Roboto'] # 美化字体 # Times New Roman Arial Roboto 中文改一下SimHei
plt.rcParams['axes.unicode_minus'] = False # 显示负数
#保留下三角:
data_corr = data.corr()
mask = np.zeros_like(data_corr)
for i in range(1,len(mask)):
for j in range(0,i):
mask[j][i] = True # 上三角就mask[i][j] = True
# 绘图
sns.heatmap(data_corr,annot=True, fmt=".2f",cmap = 'Blues',mask = mask)
plt.show()
# 调用函数绘图
enhanced_corr_heatmap(data)

如图明显看到各个字段的皮尔逊相关性系数,非常直观,其中初步发现,工作满意度和工龄(Pearson:+0.80)、离职和工作地距离家庭住址的距离(Pearson:+0.74)、月工资和工作年限(Pearson:+0.76)、以及工作投入度和绩效(Pearson:+0.86)有着明显的正相关关系。
5.使用交叉表(crosstab)统计不同部门员工的学历构成
# 使用交叉表统计不同部门员工的学历构成
cross_tab = pd.crosstab(data['Department'], data['Education'])
cross_tab

6.使用数据透视表(pivot_table)统计不同部门、不同性别员工的流失率:
# 使用数据透视表统计不同部门、不同性别员工的流失率
pivot_table = pd.pivot_table(data, values='Attrition', index='Department', columns='Gender', aggfunc='mean')
pivot_table

7.绘制反映不同性别员工占比的饼图(pie chart)
# 统计性别员工占比
gender_counts = data['Gender'].value_counts()
# 绘制饼图
plt.pie(gender_counts, labels=gender_counts.index, autopct='%1.1f%%')
plt.title('Gender Distribution')
plt.show()

男性60%,女性40%。
8.绘制不同部门员工人数的柱状图(bar chart)
# 统计不同部门员工人数
department_counts = data['Department'].value_counts()
# 绘制柱状图
plt.bar(department_counts.index, department_counts)
plt.xlabel('Department')
plt.ylabel('Count')
plt.title('Employee Count by Department')
plt.show()

9.绘制不同性别员工薪酬的箱型图(box plot)
# 根据性别分组,获取薪酬数据
male_salaries = data[data['Gender'] == 1]['MonthlyIncome']
female_salaries = data[data['Gender'] == 0]['MonthlyIncome']
# 将薪酬数据放在一个列表中,用于箱型图绘制
data_age = [male_salaries, female_salaries]
# 绘制箱型图
plt.boxplot(data_age, labels=['Male', 'Female'])
plt.xlabel('Gender')
plt.ylabel('Salary')
plt.title('MonthlyIncome Distribution by Gender')
plt.show()

10.绘制员工年龄分布的直方图(histogram)
# 绘制直方图
plt.hist(data['Age'], bins=20)
plt.xlabel('Age')
plt.ylabel('Count')
plt.title('Employee Age Distribution')
plt.show()

11.绘制员工年龄和薪酬的散点图(scatter plot)
# 绘制散点图
plt.scatter(data['Age'], data['MonthlyIncome'])
plt.xlabel('Age')
plt.ylabel('Salary')
plt.title('Employee Age vs MonthlyIncome')
plt.show()

12. “快乐的员工绩效高?”分析
在组织行为学中存在一种说法:“快乐的员工绩效高”,即工作满意度高的员工工作绩效也高,本数据集的分析结果是否支持这一观点?
无论是从相关性系数,还是不同满意度下绩效的平均情况来看,本数据集的分析结果不支持工作满意度高绩效也高这一观点
# 看一下工作满意度和绩效的关系
# 13. JobSatisfaction
# 16. PerformanceRating
import numpy as np
correlation = np.corrcoef(data['JobSatisfaction'], data['PerformanceRating'])[0, 1]
print("Correlation coefficient:", correlation)
grouped_data = data.groupby('JobSatisfaction')['PerformanceRating'].mean()
grouped_data.plot()

13. 回归分析检验出差和加班是否会显著降低员工的工作满意度
工作强度大往往会降低员工的工作满意度,使用回归分析检验出差和加班是否会显著降低员工的工作满意度:
import pandas as pd
import statsmodels.api as sm
# 创建自变量和因变量的数据框
X = data[['BusinessTravel', 'OverTime']]
y = data['JobSatisfaction']
# 将分类变量转换为虚拟变量
X = pd.get_dummies(X, drop_first=True)
# 添加截距项
X = sm.add_constant(X)
# 拟合回归模型
model = sm.OLS(y, X)
results = model.fit()
# 打印回归结果摘要
print(results.summary())

从结果看,出差(BusinessTravel)的P-value为0.000<0.05, 加班(OverTime)的P-value为0.041<0.05 ,说明均会显著降低员工的满意度
14. 该企业员根据你所学的管理学知识
(如,绩效越好的员工薪酬越高、越资深的员工薪酬越高等),并结合数据分析结果,找出该企业员工薪酬的主要影响因素;如果绩效是薪酬的主要影响因素,那么又有什么因素会影响员工的绩效?
data.corr()[['MonthlyIncome']].sort_values(by = "MonthlyIncome", ascending = False)
从相关性系数的角度,可以看到与薪酬最正相关的因素是总工龄TotalWorkingYears,皮尔逊相关性系数达到+0.76,同时这也符合企业的薪酬分配时的基本原则和常识,工龄越久代表着经验越丰富,职位高的概率也比较大,因此薪酬自然较高。
15.其它有价值的分析结果
哪些因素会导致员工离职?
# 分析哪些因素会导致员工离职
data.corr()[['Attrition']].sort_values(by = "Attrition", ascending = False)
# 计算不同Attrition下DistanceFromHome的平均值
# 筛选Attrition和DistanceFromHome两列数据
attrition_distance = data[['Attrition', 'DistanceFromHome']]
# 按照Attrition列分组并计算DistanceFromHome的平均值
mean_distance = attrition_distance.groupby('Attrition').mean()
mean_distance
从相关性系数的角度:工作地距离家庭地址距离和员工离职的相关性达到0.74 说明存在很强的相关性。
