Verilog学习笔记(3)——赋值、时序控制
本章主要讲解Verilog语句中的赋值部分。
Verilog中的赋值包括对线网变量的连续赋值和对寄存器变量的过程赋值。连续赋值用assign语句描述,过程事件用initial和always语句描述,过程赋值包含阻塞赋值和非阻塞赋值两种运算。
时序控制通过时延控制和事件控制两种方式实现。时延控制可以分为常规时延与内嵌时延。事件控制主要分为边沿触发事件控制与电平敏感事件控制。
文章目录
- 3.1 Verilog 连续赋值
-
- assign 语句
- 连续赋值时延
- 全加器
- 3.2 Verilog 过程结构、赋值和时序控制
-
- Verilog 过程结构
-
- initial语句
- always 语句
- Verilog 过程赋值
-
- 阻塞赋值
- 非阻塞赋值
- 使用非阻塞赋值避免竞争冒险
- Verilog 过程时序控制
-
- 时延控制
-
- 常规时延
- 内嵌时延
- 事件控制
-
- 边沿触发事件控制
- 电平敏感事件控制
3.1 Verilog 连续赋值
assign 语句
连续赋值语句是 Verilog 数据流建模的基本语句,用于对 wire 型变量进行赋值。格式如下:
assign LHS_target = RHS_expression ;
LHS(left hand side) 指赋值操作的左侧,RHS(right hand side)指赋值操作的右侧。
assign 为关键词,任何已经声明 wire 变量的连续赋值语句都是以 assign 开头,例如:
wire Cout, A, B ;
assign Cout = A & B ; //实现计算A与B的功能
需要说明的是:
- LHS_target 必须是一个标量或者线型向量,而不能是寄存器类型。
- RHS_expression 的类型没有要求,可以是标量或线型或存器向量,也可以是函数调用。
- 只要 RHS_expression 表达式的操作数有事件发生(值的变化)时,RHS_expression 就会立刻重新计算,同时赋值给 LHS_target。
Verilog 还提供了另一种对 wire 型赋值的简单方法,即在 wire 型变量声明的时候同时对其赋值。wire 型变量只能被赋值一次,因此该种连续赋值方式也只能有一次。例如下面赋值方式和上面的赋值例子的赋值方式,效果都是一致的。
wire A, B ;
wire Cout = A & B ;
连续赋值时延
连续赋值延时语句中的延时,用于控制任意操作数发生变化到语句左端赋予新值之间的时间延时。
时延一般是不可综合的。
寄存器的时延也是可以控制的,这部分在时序控制里加以说明。
连续赋值时延一般可分为普通赋值时延、隐式时延、声明时延。
下面 3 个例子实现的功能是等效的,分别对应 3 种不同连续赋值时延的写法。
//普通时延,A&B计算结果延时10个时间单位赋值给Z
wire Z, A, B ;
assign #10 Z = A & B ;
//隐式时延,声明一个wire型变量时对其进行包含一定时延的连续赋值。
wire A, B;
wire #10 Z = A & B;
//声明时延,声明一个wire型变量是指定一个时延。因此对该变量所有的连续赋值都会被推迟到指定的时间。除非门级建模中,一般不推荐使用此类方法建模。
wire A, B;
wire #10 Z ;
assign Z =A & B
惯性时延
在上述例子中,A 或 B 任意一个变量发生变化,那么在 Z 得到新的值之前,会有 10 个时间单位的时延。如果在这 10 个时间单位内,即在 Z 获取新的值之前,A 或 B 任意一个值又发生了变化,那么计算 Z 的新值时会取 A 或 B 当前的新值。所以称之为惯性时延,即信号脉冲宽度小于时延时,对输出没有影响。
因此仿真时,时延一定要合理设置,防止某些信号不能进行有效的延迟。
对一个有延迟的与门逻辑进行时延仿真。
module time_delay_module(
input ai, bi,
output so_lose, so_get, so_normal);
assign #20 so_lose = ai & bi ;
assign #5 so_get = ai & bi ;
assign so_normal = ai & bi ;
endmodule
testbench 参考如下:
`timescale 1ns/1ns
module test ;
reg ai, bi ;
wire so_lose, so_get, so_normal ;
initial begin
ai = 0 ;
#25 ; ai = 1 ;
#35 ; ai = 0 ; //60ns
#40 ; ai = 1 ; //100ns
#10 ; ai = 0 ; //110ns
end
initial begin
bi = 1 ;
#70 ; bi = 0 ;
#20 ; bi = 1 ;
end
time_delay_module u_wire_delay(
.ai (ai),
.bi (bi),
.so_lose (so_lose),
.so_get (so_get),
.so_normal (so_normal));
initial begin
forever begin
#100;
//$display("---gyc---%d", $time);
if ($time >= 1000) begin
$finish ;
end
end
end
endmodule
仿真结果如下:

信号 so_normal 为正常的与逻辑。
由于所有的时延均大于 5ns,所以信号 so_get 的结果为与操作后再延迟 5ns 的结果。
信号 so_lose 前一段是与操作后再延迟 20ns 的结果。
由于信号 ai 第二个高电平持续时间小于 20ns,so_lose 信号会因惯性时延而漏掉对这个脉冲的延时检测,所以后半段 so_lose 信号仍然为 0。
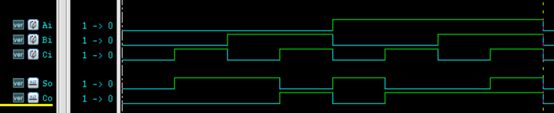
全加器
下面采用数据流描述方式,来设计一个 1bit 全加器。
设 Ai,Bi,Ci 分别为被加数、加数和相邻低位的进位数,So, Co 分别为本位和与向相邻高位的进位数。
真值表如下:
| In | Out | |||
|---|---|---|---|---|
| Ci | Ai | Bi | So | Co |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
全加器的表达式为:
So = Ai ⊕ Bi ⊕ Ci ;
Co = AiBi + Ci(Ai+Bi)
rtl 代码(full_adder1.v)如下:
module full_adder1(
input Ai, Bi, Ci,
output So, Co);
assign So = Ai ^ Bi ^ Ci ;
assign Co = (Ai & Bi) | (Ci & (Ai | Bi));
endmodule
当然,更为贴近加法器的代码描述可以为:
module full_adder1(
input Ai, Bi, Ci
output So, Co);
assign {Co, So} = Ai + Bi + Ci ;
endmodule
testbench(test.sv)参考如下:
`timescale 1ns/1ns
module test ;
reg Ai, Bi, Ci ;
wire So, Co ;
initial begin
{Ai, Bi, Ci} = 3'b0;
forever begin
#10 ;
{Ai, Bi, Ci} = {Ai, Bi, Ci} + 1'b1;
end
end
full_adder1 u_adder(
.Ai (Ai),
.Bi (Bi),
.Ci (Ci),
.So (So),
.Co (Co));
initial begin
forever begin
#100;
//$display("---gyc---%d", $time);
if ($time >= 1000) begin
$finish ;
end
end
end
endmodule
仿真结果如下:
3.2 Verilog 过程结构、赋值和时序控制
Verilog 过程结构
过程结构语句有 2 种,initial 与 always 语句。它们是行为级建模的 2 种基本语句。
一个模块中可以包含多个 initial 和 always 语句,但 2 种语句不能嵌套使用。
这些语句在模块间并行执行,与其在模块的前后顺序没有关系。
但是 initial 语句或 always 语句内部可以理解为是顺序执行的(非阻塞赋值除外)。
每个 initial 语句或 always 语句都会产生一个独立的控制流,执行时间都是从 0 时刻开始。
initial语句
initial 语句从 0 时刻开始执行,只执行一次,多个 initial 块之间是相互独立的。
如果 initial 块内包含多个语句,需要使用关键字 begin 和 end 组成一个块语句。
如果 initial 块内只要一条语句,关键字 begin 和 end 可使用也可不使用。
initial 理论上来讲是不可综合的,多用于初始化、信号检测等。
对上一节代码稍作修改,进行仿真,代码如下。
`timescale 1ns/1ns
module test ;
reg ai, bi ;
initial begin
ai = 0 ;
#25 ; ai = 1 ;
#35 ; ai = 0 ; //absolute 60ns
#40 ; ai = 1 ; //absolute 100ns
#10 ; ai = 0 ; //absolute 110ns
end
initial begin
bi = 1 ;
#70 ; bi = 0 ; //absolute 70ns
#20 ; bi = 1 ; //absolute 90ns
end
//at proper time stop the simulation
initial begin
forever begin
#100;
//$display("---gyc---%d", $time);
if ($time >= 1000) begin
$finish ;
end
end
end
endmodule
仿真结果如下:

可以看出,2 个 initial 进程语句分别给信号 ai,bi 赋值时,相互间并没有影响。
信号 ai,bi 的值按照赋值顺序依次改变,所以 initial 内部语句也可以看做是顺序执行。
always 语句
与 initial 语句相反,always 语句是重复执行的。always 语句块从 0 时刻开始执行其中的行为语句;当执行完最后一条语句后,便再次执行语句块中的第一条语句,如此循环反复。
由于循环执行的特点,always 语句多用于仿真时钟的产生,信号行为的检测等。
下面用 always 产生一个 100MHz 时钟源,并在 110ns 时停止仿真,代码如下:
`timescale 1ns/1ns
module test ;
parameter CLK_FREQ = 100 ; //100MHz
parameter CLK_CYCLE = 1e9 / (CLK_FREQ * 1e6) ; //switch to ns
reg clk ;
initial clk = 1'b0 ; //clk is initialized to "0"
always # (CLK_CYCLE/2) clk = ~clk ; //generating a real clock by reversing
always begin
#10;
if ($time >= 1000) begin
$finish ;
end
end
endmodule
仿真结果如下:
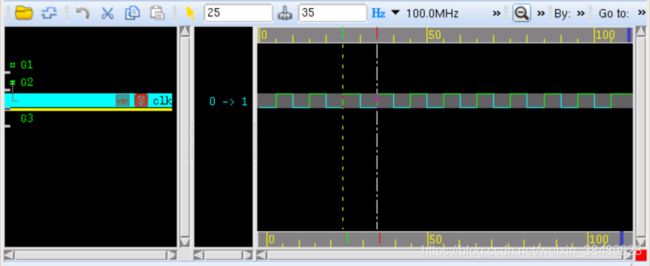
可见,时钟周期是我们想要得到的 100MHz。而且仿真在 110ns 时停止。
Verilog 过程赋值
过程性赋值是在 initial 或 always 语句块里的赋值,赋值对象是寄存器、整数、实数等类型。这些变量在被赋值后,其值将保持不变,直到重新被赋予新值。
连续性赋值总是处于激活状态,任何操作数的改变都会影响表达式的结果;过程赋值只有在语句执行的时候,才会起作用。这是连续性赋值与过程性赋值的区别。
Verilog 过程赋值包括 2 种语句:阻塞赋值与非阻塞赋值。
阻塞赋值
阻塞赋值属于顺序执行,即下一条语句执行前,当前语句一定会执行完毕。
阻塞赋值语句使用等号 = 作为赋值符。
前面的仿真中,initial 里面的赋值语句都是用的阻塞赋值。
非阻塞赋值
非阻塞赋值属于并行执行语句,即下一条语句的执行和当前语句的执行是同时进行的,它不会阻塞位于同一个语句块中后面语句的执行。
非阻塞赋值语句使用小于等于号 <= 作为赋值符。
利用下面代码,对阻塞、非阻塞赋值进行仿真,来说明 2 种过程赋值的区别。
`timescale 1ns/1ns
module test ;
reg [3:0] ai, bi ;
reg [3:0] ai2, bi2 ;
reg [3:0] value_blk ;
reg [3:0] value_non ;
reg [3:0] value_non2 ;
initial begin
ai = 4'd1 ; //(1)
bi = 4'd2 ; //(2)
ai2 = 4'd7 ; //(3)
bi2 = 4'd8 ; //(4)
#20 ; //(5)
//non-block-assigment with block-assignment
ai = 4'd3 ; //(6)
bi = 4'd4 ; //(7)
value_blk = ai + bi ; //(8)
value_non <= ai + bi ; //(9)
//non-block-assigment itself
ai2 <= 4'd5 ; //(10)
bi2 <= 4'd6 ; //(11)
value_non2 <= ai2 + bi2 ; //(12)
end
//stop the simulation
always begin
#10 ;
if ($time >= 1000) $finish ;
end
endmodule
仿真结果如下:
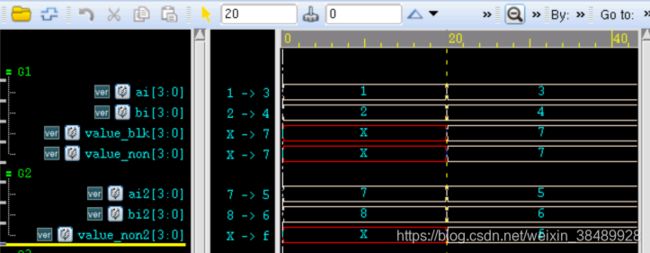
语句(1)-(8)都是阻塞赋值,按照顺序执行。
20ns 之前,信号 ai,bi 值改变。由于过程赋值的特点,value_blk = ai + bi 并没有执行到,所以 20ns 之前,value_blk 值为 X(不确定状态)。
20ns 之后,信号 ai,bi 值再次改变。执行到 value_blk = ai + bi,信号 value_blk 利用信号 ai,bi 的新值得到计算结果 7。
语句(9)-(12)都是非阻塞赋值,并行执行。
首先,(9)-(12)虽然都是并发执行,但是执行顺序也是在(8)之后,所以信号 value_non = ai + bi 计算是也会使用信号 ai,bi 的新值,结果为 7。
其次,(10)-(12)是并发执行,所以 value_non2 = ai2 + bi2 计算时,并不关心信号 ai2,bi2 的最新非阻塞赋值结果。即 value_non2 计算时使用的是信号 ai2,bi2 的旧值,结果为 4’hF。
使用非阻塞赋值避免竞争冒险
上述仿真代码只是为了让读者更好的理解阻塞赋值与非阻塞赋值的区别。实际 Verilog 代码设计时,切记不要在一个过程结构中混合使用阻塞赋值与非阻塞赋值。两种赋值方式混用时,时序不容易控制,很容易得到意外的结果。
更多时候,在设计电路时,always 时序逻辑块中多用非阻塞赋值,always 组合逻辑块中多用阻塞赋值;在仿真电路时,initial 块中一般多用阻塞赋值。
如下所示,为实现在时钟上升沿交换 2 个寄存器值的功能,在 2 个 always 块中使用阻塞赋值。
因为 2 个 always 块中的语句是同时进行的,但是 a=b 与 b=a 是无法判定执行顺序的,这就造成了竞争的局面。
但不管哪个先执行(和编译器等有关系),不考虑 timing 问题时,他们执行顺序总有先后,最后 a 与 b 的值总是相等的。没有达到交换 2 个寄存器值的效果。
always @(posedge clk) begin
a = b ;
end
always @(posedge clk) begin
b = a;
end
但是,如果在 always 块中使用非阻塞赋值,则可以避免上述竞争冒险的情况。
如下所示,2 个 always 块中语句并行执行,赋值操作右端操作数使用的是上一个时钟周期的旧值,此时 a<=b 与 b<=a 就可以相互不干扰的执行,达到交换寄存器值的目的。
always @(posedge clk) begin
a <= b ;
end
always @(posedge clk) begin
b <= a;
end
当然,利用下面代码也可以实现交换寄存器值的功能,但是显然不如在 always 块中直接用非阻塞赋值简单直观。
always @(posedge clk) begin
temp = a ;
a = b ;
b = temp ;
end
Verilog 过程时序控制
Verilog 提供了 2 大类时序控制方法:时延控制和事件控制。
时延控制可以分为常规时延与内嵌时延。事件控制主要分为边沿触发事件控制与电平敏感事件控制。
时延控制
基于时延的时序控制出现在表达式中,它指定了语句从开始执行到执行完毕之间的时间间隔。
时延可以是数字、标识符或者表达式。
根据在表达式中的位置差异,时延控制又可以分为常规时延与内嵌时延。
常规时延
遇到常规延时时,该语句需要等待一定时间,然后将计算结果赋值给目标信号。
格式为:#delay procedural_statement,例如:
reg value_test ;
reg value_general ;
#10 value_general = value_test ;
该时延方式的另一种写法是直接将井号 # 独立成一个时延执行语句,例如:
#10 ;
value_ single = value_test ;
内嵌时延
遇到内嵌延时时,该语句先将计算结果保存,然后等待一定的时间后赋值给目标信号。
内嵌时延控制加在赋值号之后。例如:
reg value_test ;
reg value_embed ;
value_embed = #10 value_test ;
需要说明的是,这 2 种时延控制方式的效果是有所不同的。
当延时语句的赋值符号右端是常量时,2 种时延控制都能达到相同的延时赋值效果。
当延时语句的赋值符号右端是变量时,2 种时延控制可能会产生不同的延时赋值效果。
例如下面仿真代码:
`timescale 1ns/1ns
module test ;
reg value_test ;
reg value_general, value_embed, value_single ;
//signal source
initial begin
value_test = 0 ;
#25 ; value_test = 1 ;
#35 ; value_test = 0 ; //absolute 60ns
#40 ; value_test = 1 ; //absolute 100ns
#10 ; value_test = 0 ; //absolute 110ns
end
//(1)general delay control
initial begin
value_general = 1;
#10 value_general = value_test ; //10ns, value_test=0
#45 value_general = value_test ; //55ns, value_test=1
#30 value_general = value_test ; //85ns, value_test=0
#20 value_general = value_test ; //105ns, value_test=1
end
//(2)embedded delay control
initial begin
value_embed = 1;
value_embed = #10 value_test ; //0ns, value_test=0
value_embed = #45 value_test ; //10ns, value_test=0
value_embed = #30 value_test ; //55ns, value_test=1
value_embed = #20 value_test ; //85ns, value_test=0
end
//(3)single delay control
initial begin
value_single = 1;
#10 ;
value_single = value_test ; //10ns, value_test=0
#45 ;
value_single = value_test ; //55ns, value_test=1
#30 ;
value_single = value_test ; //85ns, value_test=0
#20 ;
value_single = value_test ; //105ns, value_test=1
end
always begin
#10;
if ($time >= 150) begin
$finish ;
end
end
endmodule
仿真结果如下,由图可知:

- 一般延时的两种表达方式执行的结果都是一致的。
- 一般时延赋值方式:遇到延迟语句后先延迟一定的时间,然后将当前操作数赋值给目标信号,并没有"惯性延迟"的特点,不会漏掉相对较窄的脉冲。
- 内嵌时延赋值方式:遇到延迟语句后,先计算出表达式右端的结果,然后再延迟一定的时间,赋值给目标信号。
事件控制
边沿触发事件控制
在 Verilog 中,事件是指某一个 reg 或 wire 型变量发生了值的变化。
事件控制用符号 @ 表示。
语句执行的条件是信号的值发生特定的变化。
关键字 posedge 指信号发生边沿正向跳变,negedge 指信号发生负向边沿跳变,未指明跳变方向时,则 2 种情况的边沿变化都会触发相关事件。例如:
//信号clk只要发生变化,就执行q<=d,双边沿D触发器模型
always @(clk) q <= d ;
//在信号clk上升沿时刻,执行q<=d,正边沿D触发器模型
always @(posedge clk) q <= d ;
//在信号clk下降沿时刻,执行q<=d,负边沿D触发器模型
always @(negedge clk) q <= d ;
//立刻计算d的值,并在clk上升沿时刻赋值给q,不推荐这种写法
q = @(posedge clk) d ;
当多个信号或事件中任意一个发生变化都能够触发语句的执行时,Verilog 中使用"或"表达式来描述这种情况,用关键字 or 连接多个事件或信号。这些事件或信号组成的列表称为"敏感列表"。当然,or 也可以用逗号 , 来代替。例如:
//带有低有效复位端的D触发器模型
always @(posedge clk or negedge rstn) begin
//always @(posedge clk , negedge rstn) begin
//也可以使用逗号陈列多个事件触发
if(! rstn)begin
q <= 1'b ;
end
else begin
q <= d ;
end
end
当组合逻辑输入变量很多时,那么编写敏感列表会很繁琐。此时,更为简洁的写法是 @* 或 @(*),表示对语句块中的所有输入变量的变化都是敏感的。例如:
always @(*) begin
//always @(a, b, c, d, e, f, g, h, i, j, k, l, m) begin
//两种写法等价
assign s = a? b+c : d ? e+f : g ? h+i : j ? k+l : m ;
end
电平敏感事件控制
前面所讨论的事件控制都是需要等待信号值的变化或事件的触发,使用 @+敏感列表 的方式来表示的。
Verilog 中还支持使用电平作为敏感信号来控制时序,即后面语句的执行需要等待某个条件为真。Verilog 中使用关键字 wait 来表示这种电平敏感情况。例如:
initial begin
wait (start_enable) ; //等待 start 信号
forever begin
//start信号使能后,在clk_samp上升沿,对数据进行整合
@(posedge clk_samp) ;
data_buf = {data_if[0], data_if[1]} ;
end
end