【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]
文章目录
- 前言
- 一、平均值、方差、协方差
-
- 平均值(mean)np.mean()
- 方差(variance)np.var()
-
- 总体方差 np.var(a, ddof=0)
- 无偏样本方差np.var(a, ddof=1)
- 有偏样本方差
- 标准差(standard deviation)np.std(a, ddof=1)
-
- 默认是有偏估计,所以务必加上ddof=1,以下均使用无偏估计(ddof=1)
- 协方差(covariance)np.cov(x, y,ddof=1)[0][1]
-
- 与自身的协方差 np.cov(x,ddof=1)
- 线性组合的协方差
- 期望值(Expected value) np.average(a, weights=weights)
-
- np.mean()与np.average()的区别
- 协方差矩阵 (covariance matrix)np.cov(x, y,ddof=1)
-
- 交叉协方差矩阵
- 协方差矩阵(自协方差矩阵)
- 协方差矩阵=A^T^A的证明
- 二、奇异值分解、主成分分析法
-
- 奇异值分解(Singular Value Decomposition)np.linalg.svd()
-
- 补充: 奇异值和特征值
- 补充:奇异矩阵和非奇异矩阵(线代基础知识)
- 补充:酉矩阵和正交矩阵
- 从特征值分解到奇异值分解
-
- 求特征值 eig_val, eig_vec = np.linalg.eig(A)
- 求索引值 index =np.argsort(x)
- np.linalg.svd()
- 奇异值的物理意义 (为什么要进行奇异值分解)
- 主成分分析法(Principal components analysis)
-
- 补充:归一化 :(常见)将数据映射到 [0,1] or [-1.1] 的区间之内
- 补充:去中心化:以平均值为中心移动至原点
- 补充:标准化:使得方差为1,均值为0
- 步骤
- np.reshape(-1, 1) #数据化为 -1(自动行)x 1 (列)大小
- PCA(n_components=1) #PCA降维到1维
- 为什么要进行主成分分析
- 模式识别和机器学习
- 三、实战1 ,求取点云的领域曲率
-
- 领域曲率定义
- 代码
- 四、最小二乘法(least square)
-
- 回归(regression)
-
- 回归与分类(classification)的区别与转换
- 补充:聚类(clustering)问题、降维(dimensionality Reduction)问题(机器学习小总结)
- 损失函数(也叫代价函数)(loss function)
-
- 偏差(bias)
- 均方误差函数(Mean Squared Error, MSE)
- 误差(error)(也叫残差)
- 其他损失函数
- 误差平方和(sum of squared errors,SSE)与最小二乘法
- 补充:常见的L1损失函数和L2损失函数
- 如何选取损失函数
- 线性回归 (linear regression)
-
- 一元线性回归
-
- 基于迭代的梯度下降算法
-
- np.random.seed(0) #设置随机种子
- np.linspace(0,10,101)
- np.np.random.normal(loc=0.0, scale=1.0, size=None)
- 代码
- 基于求导的数学方法
-
- 代码
- 上述两个方法的结论
- sklearn库方法(最小二乘法)model = LinearRegression()
- scipy库方法(最小二乘法)leastsq(residual, params0, args=(x, y))
- 上述两者的区别:
- 多元线性回归
-
- 拟合平面
-
- LinearRegression()
- leastsq()
- 非线性回归 leastsq()与curve_fit()
-
- 拟合曲线
-
- leastsq()方法
- curve_fit()方法
- 拟合曲面
-
- leastsq()时,
- curve_fit()时,
- 协方差及其他一些参数
- 五、如何求取点云的缺陷
-
- 缺陷分类
- 高斯曲率、平均曲率
- 公式推导
- 求取高斯曲率和平均曲率的代码实现
前言
记录一下 点云学习遇到的一些数学计算方法。
这里点云的在numpy上的形式如下:每个数组里是x,y,z坐标信息。
import numpy as np
points = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
print(points)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第1张图片](http://img.e-com-net.com/image/info8/5dc46a594af04d38af43e8e11a0cd10b.jpg)
参考链接
Python之Numpy详细教程
形象理解协方差矩阵【看了很多这个是比较正确的理解】
简而言之,numpy返回一个数组对象,与python中的list不同,拥有更多的操作。
比如:列表不能对[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]列表进行 行列切片。
例如:
import numpy as np
li =[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
try :
print(li[:,0])
except Exception as error:
print(error)#报错
shuzu =np.array(li)[:,0] #第一个:表示第一维,第二个0表示第二维的第一个元素 #或者说取第一列
print(shuzu)
print(type(shuzu))
print(list(shuzu))
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第2张图片](http://img.e-com-net.com/image/info8/000c86d22413409ba325723f0d65bdee.jpg)
关于np.array和np.asarray
import numpy as np
points = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
points1 = np.asarray([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
print(points)
print(points1)
返回的数组一致,只是参数上有区别,详情见上面的教程。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第3张图片](http://img.e-com-net.com/image/info8/32adc729d7554b4d82d332e7f9bf0be7.jpg)
一、平均值、方差、协方差
平均值(mean)np.mean()
概念不用多说,这里强调一下写法:
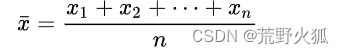
The arithmetic mean of a set of numbers x1, x2, …, xn is typically denoted using an overhead bar, (英文里平均值常写成xbar,bar英文意思是条,带。意思是通常使用个头顶条来表示。)
使用:np.mean() #mean 英译:平均值
import numpy as np
points = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
average_data = np.mean(points, axis=0)##axis=0表示按列求均值
print(average_data)
#[5.5 6.5 7.5]
方差(variance)np.var()
总体方差 np.var(a, ddof=0)
主要看到第一个等号就行,下面推导的是方差也=数平方的均值-数均值的平方
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第4张图片](http://img.e-com-net.com/image/info8/af0b826a257a4a35aef9fb90546b2339.jpg)
这里u=均值。 这u=E(x),后面期望值会讲到。
np.var()
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
variance = np.var(a,axis=1) #axis=1表示按行求方差
print(variance)
#[0.66666667 0.66666667 0.66666667 0.66666667]
无偏样本方差np.var(a, ddof=1)
一般来说,点云中计算从方差都是选取部分点云来算方差,所以基本上用无偏样本方差,其中,对n − 1的使用称为贝塞尔校正,它也用于样本协方差和样本标准差(方差的平方根)。详见Wiki百科。定义如下:
![]()
np.var(a, ddof=1) ddof=0表示总体方差,ddof=1表示为样本方差
import numpy as np
a = ([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
sample_variance = np.var(a, ddof=1, axis=1) #ddof=1表示无偏估计
print(sample_variance)
#[1. 1. 1. 1.]
有偏样本方差
则是除以n,这里n为样本大小。与总体方差计算方式一样。
标准差(standard deviation)np.std(a, ddof=1)
standard deviation,缩写为S.D.或σ1。标准差是一种衡量数据分散程度的统计量,它是方差的平方根。
主要用第一种。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第5张图片](http://img.e-com-net.com/image/info8/8a9f0e12e5df42d58b0ba779d473d48a.jpg)
np.std()
import numpy as np #第一种
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
sample_standard_deviation = np.std(a, ddof=1,axis=1) #ddof=1表示无偏估计
print(sample_standard_deviation)
#[1. 1. 1. 1.]
import numpy as np #第二种
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
sample_standard_deviation = np.std(a, ddof=0,axis=1) #ddof=0表示有偏估计
print(sample_standard_deviation)
#[0.81649658 0.81649658 0.81649658 0.81649658]
可以验证是方差的开根号。
默认是有偏估计,所以务必加上ddof=1,以下均使用无偏估计(ddof=1)
协方差(covariance)np.cov(x, y,ddof=1)[0][1]
方差衡量单个随机变量(如人口中一个人的身高)的变化,而协方差是衡量两个随机变量一起变化的程度(如一个人的身高和人口中一个人的体重)。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第6张图片](http://img.e-com-net.com/image/info8/a59348cf28af4f7cb06d35aa3c0fad91.jpg)
n为样本数量,方差亦可视作随机变量与自身的协方差。

或者 写成如下形式

(图上应为1/n-1)E(x)下面会讲。其中,xi和yi的数量n应相等。
cov为协方差(covariance)的前三个字母缩写。
var为方差(variance)的前三个字母缩写。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第7张图片](http://img.e-com-net.com/image/info8/12d425ed72654683ab4824b3f9d5668e.jpg)
与自身的协方差 np.cov(x,ddof=1)
import numpy as np
x = np.array([1, 2, 3, 4, 5])
covxx = np.cov(x,ddof=1)
varx = np.var(x,ddof=1)
print(covx)
print(varx)
'''
2.5
2.5
'''
线性组合的协方差
np.cov(x, y)返回一个协方差矩阵,类似于输出:下面会讲到
[[cov(x,x)],cov[x,y]
[cov(y,x)],cov(y,y)]
所以np.cov(x, y,ddof=1)[0,1] (或[0][1],或[1,0])是x和y的协方差
import numpy as np
x = np.array([1, 2, 3, 4, 5])
y = np.array([5, 4, 3, 2, 1])
covariance = np.cov(x, y,ddof=1)# np.cov(x, y)返回一个协方差矩阵,[0, 1]表示x和y的协方差
print(covariance)
print(covariance[0,1])
'''
[[ 2.5 -2.5]
[-2.5 2.5]]
-2.5
'''
或者用下面一种形式,默认把每一行当作一个变量。
import numpy as np
x = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
covariance = np.cov(x,ddof=1)
print(covariance)
'''
[[ 1. -1. 3.5 5.5 ]
[-1. 1.33333333 -4.33333333 -7. ]
[ 3.5 -4.33333333 14.33333333 23. ]
[ 5.5 -7. 23. 37. ]]
'''
可以看出是个对称矩阵,因为协方差是交换的,即cov(X,Y) = cov(Y,X)。这个矩阵的每个位置都代表了x中两个随机变量的协方差。
用定义的方式验证一下这个函数,当然是对的。
#验证协方差公式
import numpy as np
x = np.array([1, 2, 3, 4, 5])
y = np.array([5, 4, 3, 2, 1])
print(np.cov(x, y,ddof=0)[0][0]) #ddof=0表示有偏估计
print(np.cov(x, y,ddof=0)[1][1])
print(np.cov(x, y,ddof=0)[0][1])
covx = np.mean((x - x.mean()) ** 2) #np.mean()求均值 /n
covy = np.mean((y - y.mean()) ** 2)
covxy = np.mean((x - x.mean()) * (y - y.mean()))
print(covx)
print(covy)
print(covxy)
'''
2.0
2.0
-2.0
2.0
2.0
-2.0
'''
如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第8张图片](http://img.e-com-net.com/image/info8/b1130a6c0a984bfebb41049d7b9d607d.jpg)
期望值(Expected value) np.average(a, weights=weights)
这里E(X)为期望值:试验中每次可能的结果乘以其结果概率的总和,例如:

由于此时每个点的概率相等,所以也可以写成如上cov(X,Y)形式。
np.average()可以接受一个weights参数,用来计算加权平均值。
import numpy as np
a = np.array([1, 2, 3, 4, 5])
weights = np.array([0.1, 0.2, 0.3, 0.2, 0.2])
weighted_expectation = np.average(a, weights=weights)
print(weighted_expectation)
#3.2
np.mean()与np.average()的区别
import numpy as np
a = np.array([1, 2, 3, 4, 5])
weights = np.array([0.1, 0.2, 0.3, 0.4, 0.5])
mean = np.mean(a)
average = np.average(a, weights=weights)
try :
print(a, weights=weights)
except Exception as error:
print(error)
print("mean:", mean)
print("average:", average)
'''
'weights' is an invalid keyword argument for print()
mean: 3.0
average: 3.6666666666666665
'''
可以看到,当不指定weights参数时,np.mean()和np.average()的结果是一样的,都是3.0。但是当指定了weights参数时,np.average()会根据每个元素的权重来计算加权平均值,结果是3.6666666666666665。np.mean()不支持weights参数,会报错。
协方差矩阵 (covariance matrix)np.cov(x, y,ddof=1)
交叉协方差矩阵
以下为中文wiki百科中协方差的定义
在统计学与概率论中,协方差矩阵(covariance matrix)是一个方阵,代表着任两列随机变量间的协方差,是协方差的直接推广。
因为是方阵,所以下面的m=n。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第9张图片](http://img.e-com-net.com/image/info8/7aec8e4bf5574e2682fc5a074ab0f177.jpg)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第10张图片](http://img.e-com-net.com/image/info8/0740f81619ae4c24bd59f9e0ffb3b673.jpg)
英文的wiki百科中交叉协方差矩阵的定义
交叉协方差矩阵
是一个矩阵,其元素在 i、j 位置是随机向量的第 i 个元素与另一个随机向量的第 j 个元素之间的协方差。
后发现这样来理解np.cov()函数理解不了,故查询了英文的wiki百科中协方差矩阵的定义,发现确实有问题,上述定义在英文wiki百科中定义为交叉协方差矩阵,而协方差矩阵定义如下:
协方差矩阵(自协方差矩阵)
英文的wiki百科中协方差矩阵的定义
在概率论和统计学中,协方差矩阵(covariance matrix),也称为自动协方差矩阵(auto-covariance matrix)、色散矩阵(dispersion matrix)、方差矩阵(variance matrix)或方差-协方差矩阵(variance–covariance matrix)。
是一个平方矩阵,给出给定随机向量的每对元素之间的协方差。任意协方差矩阵都是对称的和半正定的矩阵,且其主对角线包含方差(即每个元素自身的协方差)。不要和交叉协方差矩阵搞混。
直观地说,协方差矩阵将方差的概念推广到多个维度。例如,二维空间中随机点集合的变化不能完全用单个数字来表征,二维空间中随机点的方差也不能用x和y方向包含所有必要的信息;一个2×2矩阵对于充分表征二维变化是必要的。
任何协方差矩阵都是对称的,并且是正半定的,其主对角线包含方差(即每个元素与自身的协方差)。
这里主要按python中的函数来解读了,实际上这样解读更符合直觉上的逻辑。
故可以理解为:
[[cov(x,x)],cov[x,y]
[cov(y,x)],cov(y,y)]
其中covariance_matrix[0,0]和covariance_matrix[1][1]为分别对自身x,和y的协方差。
import numpy as np
x = np.array([1, 2, 3, 4, 5])
y = np.array([5, 4, 3, 2, 1])
covariance_matrix = np.cov(x, y,ddof=1)# np.cov(x, y)返回一个协方差矩阵
print(covariance_matrix)
'''
[[ 2.5 -2.5]
[-2.5 2.5]]
'''
假设为点云数据形式,实际上和上述一样理解,只不过放在一个数组里了。
import numpy as np #第二种
x = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
covariance = np.cov(x,ddof=1)
print(covariance)
'''
[[ 1. -1. 3.5 5.5 ]
[-1. 1.33333333 -4.33333333 -7. ]
[ 3.5 -4.33333333 14.33333333 23. ]
[ 5.5 -7. 23. 37. ]]
'''
可以看出上述协方差矩阵为对称的。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第11张图片](http://img.e-com-net.com/image/info8/6b27169d6ea847e6a64657f5f3f2333b.jpg)
协方差矩阵=ATA的证明
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第12张图片](http://img.e-com-net.com/image/info8/17d7ab906dd449b79a9dc6681cf35574.jpg)
更多可参考
理解和分析协方差矩阵
形象理解协方差矩阵 (有关于是正半定矩阵的证明)
二、奇异值分解、主成分分析法
奇异值分解(Singular Value Decomposition)np.linalg.svd()
这篇大佬讲的很细,可以参考通俗易懂。
SVD分解
这里仅在此基础上做些概念上的补充,简化理解过程,及错误的勘误。
补充: 奇异值和特征值
特征值和特征向量是方阵的概念,它们表示矩阵作用于某些向量时,只会改变向量的长度,不会改变向量的方向。
特征值是这些向量的长度缩放比例,特征向量是这些向量的方向。
特征值和特征向量可以用来分解方阵为对角矩阵和正交矩阵的乘积,这样可以简化矩阵的运算和理解矩阵的性质。
奇异值和奇异向量是任意矩阵的概念,它们表示矩阵作用于某些向量时,会使向量的长度达到最大或最小。
奇异值是这些向量的长度,奇异向量是这些向量的方向。
奇异值和奇异向量可以用来分解任意矩阵为对角矩阵和两个正交矩阵的乘积,这样可以用来降维、压缩、去噪等应用。
简而言之:奇异值是对特征值在矩阵上的推广,将方阵推广到了任意矩阵
奇异值分解能够用于任意mxn矩阵,而特征分解只能适用于特定类型的方阵,故奇异值分解的适用范围更广。
补充:奇异矩阵和非奇异矩阵(线代基础知识)
奇异矩阵和非奇异矩阵是线性代数中的概念,它们都是指方阵,即行数和列数相等的矩阵。
奇异矩阵是指行列式为0的矩阵,也就是说它的秩不是满秩,或者它的特征值有0。
非奇异矩阵是指行列式不为0的矩阵,也就是说它的秩是满秩,或者它的特征值都不为0。
非奇异矩阵也称为可逆矩阵,因为它们都有唯一的逆矩阵。
补充:酉矩阵和正交矩阵
酉矩阵和正交矩阵都是一种特殊的方阵,它们的转置矩阵等于它们的逆矩阵,也就是说它们都满足AT = A-1。
但是,酉矩阵是复数方阵,它的转置矩阵要求是共轭转置,也就是说它满足AH = A-1, 其中AH 表示A的共轭转置。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第13张图片](http://img.e-com-net.com/image/info8/08edd8d4e784483b90ae494b58937fbd.jpg)
正交矩阵是实数方阵,它的转置矩阵不需要是共轭的,也就是说它满足AT = A-1。
简而言之:酉矩阵是正交矩阵的推广,当酉矩阵的元素都是实数时,它就是正交矩阵。满足AT A = AAT =E
从特征值分解到奇异值分解
学过线代的我们都知道,若A~ ^ (^ 为对角矩阵 ) 则P-1AP =^,(P为可逆矩阵)
可以推到A = P ^ P-1, 此时由相似的性质可以得到A的特征值=^的特征值,且一一对应其特征向量的位置。说不太清,下面开始手推。
特征值分解:
定义为:
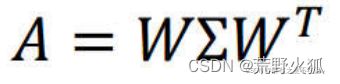
A为方阵(nxn),W为正交矩阵,(正交默认单位化了,即行向量,列向量都是正交的单位向量。),中间Σ为对角矩阵(nxn)(也叫特征值矩阵)。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第14张图片](http://img.e-com-net.com/image/info8/4e4f658699a04bb3b5ad475bd60bf81b.jpg)
最后的^ 里即为A(nxn)的特征值。
奇异值分解:
定义为:

U(m×m酉矩阵),Σ(m×n),除了主对角线上的元素以外全为零,主对角线上的每个元素都称为奇异值,V是一个n×n的酉矩阵。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第15张图片](http://img.e-com-net.com/image/info8/5b1241e943d44d93bdb44dd93347004b.jpg)
SVD分解
求特征值 eig_val, eig_vec = np.linalg.eig(A)
返回第一个值为特征值数组,第二个特征向量矩阵。注意特征值不一定是有序排列,但特征向量返回的默认是单位向量。eig 是特征值(eigenvalue)的缩写
求索引值 index =np.argsort(x)
输出的结果是x数组中的元素从小到大排序后的索引数组值。
[::1]为倒序排列,在列表形式的数据中,也能排列。
import numpy as np
# 定义一个3x2的矩阵A
A = np.array([[0, 1], [1, 1], [1, 0]])
print(A)
# 求AAT的特征值和特征向量
AAT = np.dot(A, A.T)
print(AAT)
eig_val, eig_vec = np.linalg.eig(AAT) #默认返回单位向量
print(eig_val)
print(eig_vec)
# 按特征值的大小降序排列,调整特征向量的顺序
idx = eig_val.argsort()[::-1]
eig_val = eig_val[idx]
eig_vec = eig_vec[:, idx]
U=eig_vec
print(U)
# 求ATA的特征值和特征向量
ATA = np.dot(A.T, A)
print(ATA)
eig_val, eig_vec = np.linalg.eig(ATA)
print(eig_val)
print(eig_vec)
# 按特征值的大小降序排列,调整特征向量的顺序
idx = eig_val.argsort()[::-1]
eig_val = eig_val[idx]
eig_vec = eig_vec[:, idx]
V=eig_vec
print(V)
# 求奇异值,构成Σ
Sigma = np.diag(np.sqrt(eig_val))
print(Sigma) #默认shape是与行列的较小值的方阵
#理应shape与输入矩阵A相同
Sigma = np.append(Sigma, np.zeros((1, A.shape[1])), axis=0)
print(Sigma)
# 验证A=UΣV*
print(np.dot(U, np.dot(Sigma, V.T))) #特征向量不唯一导致的
'''
[[0 1]
[1 1]
[1 0]]
[[1 1 0]
[1 2 1]
[0 1 1]]
[ 3.00000000e+00 1.00000000e+00 -5.13860489e-17]
[[-4.08248290e-01 7.07106781e-01 5.77350269e-01]
[-8.16496581e-01 2.48915666e-16 -5.77350269e-01]
[-4.08248290e-01 -7.07106781e-01 5.77350269e-01]]
[[-4.08248290e-01 7.07106781e-01 5.77350269e-01]
[-8.16496581e-01 2.48915666e-16 -5.77350269e-01]
[-4.08248290e-01 -7.07106781e-01 5.77350269e-01]]
[[2 1]
[1 2]]
[3. 1.]
[[ 0.70710678 -0.70710678]
[ 0.70710678 0.70710678]]
[[ 0.70710678 -0.70710678]
[ 0.70710678 0.70710678]]
[[1.73205081 0. ]
[0. 1. ]]
[[1.73205081 0. ]
[0. 1. ]
[0. 0. ]]
[[-1.00000000e+00 2.22044605e-16]
[-1.00000000e+00 -1.00000000e+00]
[-1.11022302e-16 -1.00000000e+00]]
'''
np.linalg.svd()
import numpy as np
# 定义一个3x2的矩阵A
A = np.array([[0, 1], [1, 1], [1, 0]])
print(A)
# 使用linalg.svd函数进行奇异值分解
U, S, V = np.linalg.svd(A)
# 打印结果
print("U:", U)
print("S:", S)
print("V:", V)
# 使用diag函数构造对角矩阵Σ
Sigma = np.diag(S)
print("Sigma:", Sigma)
'''
[[0 1]
[1 1]
[1 0]]
U: [[-4.08248290e-01 7.07106781e-01 5.77350269e-01]
[-8.16496581e-01 5.55111512e-17 -5.77350269e-01]
[-4.08248290e-01 -7.07106781e-01 5.77350269e-01]]
S: [1.73205081 1. ]
V: [[-0.70710678 -0.70710678]
[-0.70710678 0.70710678]]
Sigma: [[1.73205081 0. ]
[0. 1. ]]
'''
勘误:SVD分解
如上,我们不能得出特征值矩阵等于奇异值矩阵的平方,他们连矩阵的nxm形式都不同,只能说:如果奇异值矩阵Σ的行数与特征值矩阵相等,才能得到如此说法,由它的例子也可以看出,不过由上述手推和怕python返回值上来说,也可以接受这种说法。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第16张图片](http://img.e-com-net.com/image/info8/572ecbaeadce48b18fa82fa64d330c52.jpg)
奇异值的物理意义 (为什么要进行奇异值分解)
奇异值的物理意义
我们为什么要进行奇异值分解,以及为什么选取前几个较大的奇异值可以代表举证的主要信息,而后面的较小的奇异值则可以忽略或近似为零,这样可以实现矩阵的降维、压缩、去噪等目的。
主成分分析法(Principal components analysis)
补充:归一化 :(常见)将数据映射到 [0,1] or [-1.1] 的区间之内
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第17张图片](http://img.e-com-net.com/image/info8/da8c174e18734811b7072ab3af8ae05f.jpg)
由此可见归一化为很多种,常见的是指最小、最大特征缩放。
1、映射到[0,1]范围内:
每一项减去最小值后都除以最大值与最小值之差
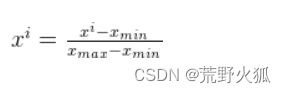
2、映射到[-1,1]范围内:
[0,1]->[0,2]->[-1,1]
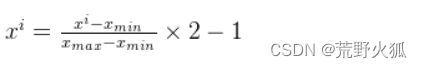
补充:去中心化:以平均值为中心移动至原点
使数据每一项都减去均值:

补充:标准化:使得方差为1,均值为0
去中心化后,除以标准差。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第18张图片](http://img.e-com-net.com/image/info8/5caf94e567e04860afa952cb0710acbe.jpg)
步骤
主要基于维基百科,部分参考:
主成分分析(PCA)原理详解
手撸PCA(Python七行代码实现)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第19张图片](http://img.e-com-net.com/image/info8/2f6805562e8e48ff9bc62245f8529c05.jpg)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第20张图片](http://img.e-com-net.com/image/info8/1b0933a7ad1d44e886863aaaedbe68d1.jpg)
第一个主成分可以等效地定义为使投影数据方差最大化的方向。在以上奇异值分解的基础上,可以理解为最大的特征值所对应的特征向量。
第二主成分可以理解为第二大特征值所对应的特征向量,以此类推。
第一步:
去中心化。
原数据[[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]],求取列方向的均值(求行向量没有意义,行向量为单个点的[x,y,z]数据)。然后将其减掉。
也可以进行标准化,这里仅中心化。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第21张图片](http://img.e-com-net.com/image/info8/82881d2eb2d6423ea8e0fe27c90c40ab.jpg)
通常,为了确保第一主成分描述的是最大方差的方向,我们会使用平均减法(去中心化)进行主成分分析。如果不执行平均减法,第一主成分有可能或多或少的对应于数据的平均值。另外,为了找到近似数据的最小均方误差,我们必须选取一个零均值。
PCA 的结果取决于变量的缩放。这可以通过按标准差缩放每个特征来解决这个问题,从而最终得到具有单位方差的无量纲特征。(也就是说标准化,可以得到位方差的无量纲特征)
在某些应用中,每个协方差矩阵的列向量,也可以缩放为方差等于 1(标准化)。这一步会影响计算出的主成分,但使它们独立于用于测量不同变量的单位。
一般来说,如果数据的各个特征的量纲和尺度相差不大,或者数据的分布比较均匀,那么只需要去中心化就可以了。如果数据的各个特征的量纲和尺度相差很大,或者数据的分布比较偏态,那么最好进行标准化,以提高PCA的效果和稳定性。
第二步:
计算协方差矩阵。
计算XTX 就可以得到协方差矩阵。(参见协方差矩阵=ATA的证明)
Gram matrix
ATA又被称为Gramian矩阵
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第22张图片](http://img.e-com-net.com/image/info8/3a778266433542b38e63e1ed69b4f0a4.jpg)
这里(ATA的一些探讨)
在维基百科中的公式如下:

看到很多的博客上没有除以n-1。
个人看法:至于为什么不除以n-1,在探究特征向量时,n-1不影响结果,在研究贡献率时(每个特征值占所有特征值和),也不影响结果。
当然研究特征值时会有影响,但一般在数值上大多数涉及到百分比率时,变无关紧要了,还有就是ATA也是协方差矩阵。
对是否要/n-1,持保留意见。
第三步:
通过SVD计算协方差矩阵的特征值与特征向量。
第四步:
降序排序
第五步:
求贡献率:每个主成分对整体特征影响了多少百分比。
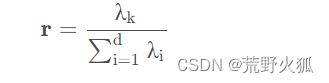
下面仅进行去中心化操作。
import numpy as np
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
#1、去中心化
average = np.mean(A, axis=0)
decentration_matrix = A - average #去中心化
std=np.std(A, axis=0,ddof=1)
#decentration_matrix = decentration_matrix/std #标准化
print(decentration_matrix)
#2、求协方差矩阵
H = np.dot(decentration_matrix.T, decentration_matrix) # 求协方差矩阵
print(H)
#3、求协方差矩阵的特征值和特征向量
eigenvectors, eigenvalues, eigenvectors_T = np.linalg.svd(H)
print(eigenvalues)
#4、降序排列特征值,调整特征向量的顺序
index = eigenvalues.argsort()[::-1] # 从大到小排序 .argsort()是升序排序,[::-1]是将数组反转,实现降序排序
eigenvalues = eigenvalues[index] # 特征值 ## 使用索引来获取排序后的数组
print(eigenvalues)
eigenvectors = eigenvectors[:, index] # 特征向量
print(eigenvectors)
#5、贡献率
contribution_rate = eigenvalues / eigenvalues.sum()
print(contribution_rate)
'''
[[-0.75 -3.5 -3.25]
[ 1.25 -4.5 -5.25]
[ 0.25 2.5 2.75]
[-0.75 5.5 5.75]]
[[ 2.75 -6.5 -7.75]
[-6.5 69. 73.5 ]
[-7.75 73.5 78.75]]
[1.48237664e+02 2.20024983e+00 6.20861128e-02]
[1.48237664e+02 2.20024983e+00 6.20861128e-02]
[[-0.06925606 -0.96162402 0.26548605]
[ 0.68147921 -0.23995698 -0.69138031]
[ 0.72855315 0.13304095 0.67194525]]
[9.84967868e-01 1.46196002e-02 4.12532311e-04]
'''
可以看出,第一,第二主成分对应的贡献率占了99%以上,若继续深究,
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第23张图片](http://img.e-com-net.com/image/info8/f4f15d0b2e194476a41cf41c6d78b81d.jpg)
这里B为去中心化后的矩阵,W为左奇异特征向量。那么第一列的T为第一主成分的投影,如果说只有第一列数据,可以说是三维降维到一维后的数据。
#6、降维后数据
print(eigenvectors[:,0]) #取第一列
new_data = np.dot(decentration_matrix, eigenvectors[:,0])
print(new_data)
print(new_data.reshape(-1, 1)) #-1表示自动计算维度大小,1表示列数为1
'''
[-0.06925606 0.68147921 0.72855315]
[-4.70103291 -6.97813053 3.68990516 7.98925828]
[[-4.70103291]
[-6.97813053]
[ 3.68990516]
[ 7.98925828]]
'''
np.reshape(-1, 1) #数据化为 -1(自动行)x 1 (列)大小
new_data.reshape(4,1) #要是知道行数的话,也可以将上述改为此,意为4行1列,不改变数据,改变形状。
至此发现与用sklearn的PCA,输出的一维降维后的结果一摸一样,至此我们也可以反推出sklearn的PCA也是用的svd分解法,实际上确实如此。
PCA(n_components=1) #PCA降维到1维
##用sklearn的PCA
from sklearn.decomposition import PCA
import numpy as np
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
pca=PCA(n_components=1) #n_components=1表示降维到1维
pca.fit(A) #训练
print(pca.transform(A)) #降维后的数据
'''
[[-4.70103291]
[-6.97813053]
[ 3.68990516]
[ 7.98925828]]
'''
为什么要进行主成分分析
中文翻译后再看这个
理解主成分分析、特征向量和特征值 打的比喻生动形象。
模式识别和机器学习
模式识别主要分为统计模式识别挥舞结构模式识别。
统计模式识别的主要方法有:判别函数法, k近邻分类法,非线性映射法,特征分析法,主因子分析法等。
数字图像的识别问题通常适用于统计模式识别,而结构(句法)模式识别主要用于遥感图像识别、文字识别等。
这里讲的主成分分析法,实际上就是统计模式识别里的主因子分析法。
而模式识别和机器学习又又什么联系和区别呢?
模式识别和机器学习是两个相关但不完全相同的概念。简单地说,模式识别是根据已有的特征,对数据进行分类或识别的过程;机器学习是根据数据本身,自动学习或发现特征和规律的过程。两者的区别和联系可以从以下几个方面来理解:
发展历史:模式识别是人工智能的早期分支,起源于19世纪,主要应用于信号处理、图像分析、语音识别等领域。机器学习是人工智能的核心分支,起源于20世纪,主要应用于数据挖掘、自然语言处理、计算机视觉、生物信息学等领域。
思维方式:模式识别更像是填鸭式教育,人类主动给机器提供特征描述,让机器按照已知的规则进行判断。机器学习更像是读万卷书行万里路,机器自动从海量数据中提取特征,通过某种算法建立模型,进行预测和决策。
技术方法:模式识别主要使用统计模式识别、结构模式识别、模板匹配、聚类分析等方法,侧重于对数据的特征提取和选择,以及对模型的参数估计和优化。机器学习主要使用人工神经网络、支持向量机、决策树、随机森林、深度学习等方法,侧重于对数据的表示和抽象,以及对模型的训练和学习。
总结:模式识别和机器学习是两种基于数据的机器智能方法,它们既有区别又有联系,都为人工智能的发展贡献了重要力量。模式识别更注重对已知特征的利用,机器学习更注重对未知特征的发现。模式识别和机器学习的界限并不严格,有时候也可以互相借鉴和融合,形成新的方法和应用。
三、实战1 ,求取点云的领域曲率
引用论文
李新春,闫振宇,林森,等.基于邻域特征点提取和匹配的点云配准[J].光子学报,2020,49(4):0415001
有的时候也叫表面曲率。
参考Open3D 计算点云的表面曲率
领域曲率定义
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第24张图片](http://img.e-com-net.com/image/info8/3962cbdff55e48c29426202e56c67306.jpg)
得知领域曲率的计算公式如上,根据以上知识,可以得出以下程序:
(其实可以看出这个公式与贡献率的公式只差在分子上,贡献率是分子是最大的特征值,这里是最小的特征值)
代码
import numpy as np
#假设一个点的邻近点集合为:A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
def pca_compute(data, sort=True):
"""
点云的特征值与特征向量
:param data: 点云数据 numpy数组形式为[[x1,y1,z1],[x2,y2,z2],...]
:return: 特征值
"""
average_data = np.mean(data, axis=0) # 求每一列的平均值,即求各个特征的平均值
decentration_matrix = data - average_data # 去中心化矩阵
H = np.dot(decentration_matrix.T, decentration_matrix) # 求协方差矩阵 #协方差是衡量两个变量关系的统计量,协方差为正表示两个变量正相关,为负表示两个变量负相关
eigenvectors, eigenvalues, eigenvectors_T = np.linalg.svd(H) # 求特征值与特征向量 #H = UΣV^T #输出列向量、对角矩阵、行向量
if sort:
sort = eigenvalues.argsort()[::-1] # 从大到小排序 .argsort()是升序排序,[::-1]是将数组反转,实现降序排序
eigenvalues = eigenvalues[sort] # 特征值 ## 使用索引来获取排序后的数组
return eigenvalues
print(pca_compute(A))
w = pca_compute(A)
delt = np.divide(w[2], np.sum(w)) #, out=np.zeros_like(w[2]), where=np.sum(w) != 0)
print(delt)
'''
[1.48237664e+02 2.20024983e+00 6.20861128e-02]
0.00041253231067531844
'''
四、最小二乘法(least square)
本来想速成一下用移动最小二乘法来拟合曲面,发现网上大多没有现成的代码,只好从头学习。
我的学习风格是喜欢从原理上弄懂,觉得这样好理解,不容易忘,然后再从这个点发现和其他知识点的联系或区别,这样比较好加深理解。
回归(regression)
参考
用人话讲明白线性回归LinearRegression
【机器学习小常识】“分类” 与 “回归”的概念及区别详解
回归是一种统计分析方法,它可以用来确定两种或两种以上变量间的相互依赖的定量关系。
回归的目的是找到一个函数或一个模型,使得它能够尽可能地拟合数据,从而进行预测或估计。
回归,简而言之,就是用已知来推未知,更多的可以归结为预测出一个结果,形式上为线(直线,曲线)、面(平面,曲面)或者更多非线性的形式。
在这些预测的结果上,如果我们想要预测下一种情况,那我们可以用现在的已知量(自变量),来得到未知量(因变量)的概率为多少。(具体为:9%)
比方说:我们去爬山,1km时25°,2km时24°,3km时23°,那我们就可以用这些数据来预测,下一次4km时,山上多少°,可以用线性回归来预测,线性相当于直线(y=kx+b)。就像小时候学的一元函数类似。
当然不是很多情况都能用线性回归,比方说:昨天10°,今天13°,预测明天,我们只能拟合出一条曲线,在这条曲线上(横坐标时间,纵坐标温度),我们可以知道明天温度多少。(非线性回归)
回归与分类(classification)的区别与转换
同样的,分类也是用已知的数据来推未知,但分类更像是一个判断题判断,只有对错之分,而回归像个解答题,要你算出值为多少。
就像猫狗识别的二分类问题上,分类是 不是猫就是狗,回归是30%猫,70%是狗。
简而言之,回归定量,分类定性。
当然,我们在此基础上也可以将回归向分类转换,定一个评判标准,设定为50%以上是狗则判断为狗,50%以下则为猫。(事实上分类通常就是在回归的基础上加上一层判断的函数(激活函数)来进行分类,常见一种为sigmoid(英译:S型)。)
我们也可以将分类向回归转换,这篇论文的大概意思是,比方说预测猫狗,我们先判断(分类)这个动物上所拥有的特征,判断出:舌头有倒刺,体型小,尾巴长。然后根据这些特征来判断这个动物是猫的概率,比方说这三个特征都为猫的,那就是100%,如果只有两个是猫的特征,则概率为67%是猫,33%是狗。(这里只是提供一种思路,实际论文里复杂的多)。
补充:聚类(clustering)问题、降维(dimensionality Reduction)问题(机器学习小总结)
机器学习可以分为四大块:
分类(Classification)
回归(Regression)
聚类(Clustering)
降维(Dimensionality Reduction)
降维:用维数更低的子空间来表示原来高维的特征空间 。就是之前讲到主成分分析法(PCA)
分类,回归,聚类问题都是机器学习的常见任务,它们都是通过对数据进行分析和建模,来实现某种目的或预测。但是它们之间也有一些区别和联系,主要体现在以下几个方面:
监督与非监督:分类和回归都是监督学习的方法,它们需要有标注的数据集,即每个样本都有一个已知的目标值或类别。而聚类是非监督学习的方法,它不需要有标注的数据集,而是根据数据的内在特征和相似度,自动地将数据分成不同的类簇。
输出类型:分类的输出是离散的类别,例如判断一个邮件是垃圾邮件还是正常邮件,或者判断一个图片是猫还是狗。回归的输出是连续的数值,例如预测一个房子的价格,或者预测一个学生的成绩。聚类的输出是数据的分组,例如将客户按照购买行为分成不同的市场细分,或者将新闻按照主题分成不同的类别。
模型评估:分类和回归都有明确的评估指标,可以用来衡量模型的性能,例如分类准确率,回归均方误差等。而聚类没有统一的评估指标,因为聚类的结果可能有多种合理的划分方式,而且没有一个标准的真实值可以参考。聚类的评估通常需要结合人工的判断和领域知识,或者使用一些内部的评估指标,例如轮廓系数,戴维森堡丁指数等。
聚类在点云的学习中会经常看到。
损失函数(也叫代价函数)(loss function)
那什么叫好的回归,那肯定要有一个判断标准。这就叫损失函数。
从前面我们学习到了方差,方差是一种衡量数据分散程度的统计量,它是每个数据与平均值的差的平方的平均值。方差越大,说明数据的波动越大,方差越小,说明数据的稳定性越高。
我们希望得到的预测的数据跟以往的数据,相比起来波动较小,那我们联想到最好预测的数据和之前的数据的方差为0。
然而方差为0只是说波动为0,就像射箭打靶,只能说它稳定的打在5环上,或者随便几环上,但不能说明它每次都稳定的打在十环上,于是我们还要引入一个量,这就是偏差。
偏差(bias)
偏差为真实值与预测值的差。
我们肯定也希望偏差为0。
在wiki中定义如下:
![]()
这里θ为真实值,E(T)为预测值。
实际上,大家知道E(X)为期望值,若X数组的每每个数概率相同,则E(X)=X数组的均值。这里可以理解为一个数组T里的值都为预测值,E(T)是这个数组的一个均值,当然也代表这个事件的平均趋势,这里E(T)如果深究的话,可以说是有偏估计(因为/n而不是n-1,上面讲方差提到)。
E(X) 可以简单理解为求X的期望(均值)。
直观可以这么理解:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第25张图片](http://img.e-com-net.com/image/info8/4af88fd3b45744ed92c796aac8c91a2c.jpg)
均方误差函数(Mean Squared Error, MSE)
我们当然希望 偏差和方差均为0,这样的判断标准才能算是好的。
还有一个小细节,这里偏差,会有正有负。假设我们预测会出现不止一个数据。
预测1: 预测100 ,真实 100 -> 偏差 -20
预测2:预测 80,真实100 -> 偏差 20
如果这两个偏差相加,则此时偏差为0了,但实际上并不是如此,于是我们想到偏差加上绝对值,或者平方来处理,我们这里通常取平方来处理。(如果取绝对值就是另外一个损失函数:平均绝对误差( mean absolute error, MAE ))
个人理由:
1、当取绝对值时,偏差相加为40,取平方时,相差为800,相当于把误差放大了很多,这样我们可以更为容易的判断好坏。
2、取平方后与方差的量级相等了,方差中是平方项的均值。
于是我自然想到偏差的平方 和 方差均为0,这样的判断标准才是好的标准。于是我把两个相加等于0。
bias2+var =0
这个等式等价于bias2=0且var =0。
好巧不巧,我们把等式左边进行化简,就得到了我们经常看到的均方误差。这就损失函数的其中一种。
此处化简可以参考wiki或者上述链接。
这就叫(均方误差函数)。

左边是单个预测值,右边是单个真实值。
或者
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第26张图片](http://img.e-com-net.com/image/info8/2aeacd49ef364da094976a08da7d56cf.jpg)
误差(error)(也叫残差)
我们把error 定义为测得的量值减去参考量值。这里测得的量值为真实值,参考的量值为预测值。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第27张图片](http://img.e-com-net.com/image/info8/bd96adb08f9f46deb0a6bbd09aaa8b3b.jpg)
所以由这图可以看出,这个公式为什么叫MSE(Mean Squared Error)。
图片参考
其他损失函数
【深度学习】最全的十九种损失函数汇总
对于回归问题,我们可以使用均方误差( mean squared error, MSE )、均方根误差( root mean squared error, RMSE )、平均绝对误差( mean absolute error, MAE )等代价函数,它们可以衡量预测值和真实值之间的距离,越小越好。如果数据中有异常值或者噪声,我们可以使用平均绝对误差或者 Huber 损失( Huber loss ),它们对异常值不敏感。
对于分类问题,我们可以使用交叉熵( cross entropy )、对数似然( log likelihood )、KL 散度( Kullback-Leibler divergence )等代价函数,它们可以衡量预测值和真实值之间的相似度,越大越好。如果数据中存在类别不平衡,我们可以使用加权交叉熵( weighted cross entropy )、Focal 损失( Focal loss )等代价函数,它们可以增加少数类的权重,减少多数类的权重。
对于聚类问题,我们可以使用误差平方和( sum of squared errors, SSE )、轮廓系数( silhouette coefficient )、戴维森堡丁指数( Davies-Bouldin index )等代价函数,它们可以衡量聚类的紧密度和分离度,越小越好。如果数据中存在噪声或者异常值,我们可以使用鲁棒的代价函数,如 Tukey 双二次损失( Tukey’s biweight loss )等。
这里只是列举常见的,事实上,SSE可以用来解决聚类问题,也可以用来解决回归问题,具体的应用场景和目标函数不同。例如:最小二乘法就是把SSE作为损失函数。
误差平方和(sum of squared errors,SSE)与最小二乘法
实际上,最小二乘法的意思就是使损失函数误差平方和为0,0意为最小,二乘意为平方。
用误差平方和作为损失函数来做回归问题拟合出来的线,就叫做最小二乘回归线。
误差平方和与均方误差的差别就在于,没有除以n(样本数)。
其函数如下:
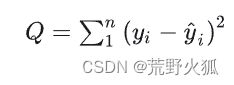
左为真实值,右为预测值。
补充:常见的L1损失函数和L2损失函数
具体范数定义,具体Lp空间定义。(来自wiki百科)
L1和L2的名字来源于数学上的Lp范数的定义,即
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第28张图片](http://img.e-com-net.com/image/info8/05ff37fd6e6b462da4e9d6640c78b6cf.jpg)
那么L1损失函数为∑|y - ŷ|。注意:不要和平均绝对误差( mean absolute error, MAE )搞混,MAE会多一个/n的操作(就是求平均)。

下图为:平均绝对误差函数(MAE)

那么L2损失函数为 :下面的xi替换为|y - ŷ|。注意:不要和RMSE(Root Mean Squard Error)均方根误差函数搞混,同理RMSE在根号下多了个/n的操作。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第29张图片](http://img.e-com-net.com/image/info8/179ec7674bd047fcad9d457c19b71c06.jpg)
下图为:均方根误差函数(RMSE)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第30张图片](http://img.e-com-net.com/image/info8/898ba78f058e4b08bc9e324ab1dbc534.jpg)
如何选取损失函数
这里简单介绍一下MSE、MAE、RMSE的选取:(绝对值、取平方、取平方开根号 的选取)
我们可以通过他们的形式发现,MSE对于异常值是比较敏感的(平方处理)。
所以在处理异常值作为被检测对象时,选取MSE作为损失函数比较好。
同时如果异常值不作为检测对象时,选取MAE作为损失函数比较好。
MSE的优点是梯度随误差减小,导数连续,容易求解,缺点是对异常值比较敏感,容易受到噪声的影响。
MAE的优点是对异常值有较好的鲁棒性,缺点是梯度恒定(一次项求导为常数),导数不连续,不利于优化。
RMSE的优点是与真实值的量纲相同,可以直观地反映误差的大小,缺点是对大的误差更加敏感,会放大误差的影响。(基本和MSE的作用相同)
了解更多可参考:(下面对于L1,L2损失函数不对,参照上面的定义)
机器学习的评价指标(二)-SSE、MSE、RMSE、MAE、R-Squared
线性回归 (linear regression)
如果说是一元线性回归,那么我们的回归模型相当于y=kx+b。
如果是二元线性回归,则回归模型则是y=k1x1+k2x2 +b,以此类推。
如果是一元二次线性回归,则回归模型则是y=k1x2+k2x=b,以此类推。
一元线性回归
此时,y = kx+b 为预测值。为了使损失函数要最小,我们这里有两种方法。
第一种是基于迭代的梯度下降算法。
第二种是基于求导的数学方法。
基于迭代的梯度下降算法
首先看完这个就能通俗易懂了解到梯度下降法。(主要就是下山方法寻找局部最低点,注意下山时梯度方向为-。)
看到代码前一部分就行。
梯度下降算法原理讲解——机器学习
这里也解释了为什么我们会通常看到均方误差函数前面系数会乘以1/2的原因(求导后 后面的平方2可以消掉)
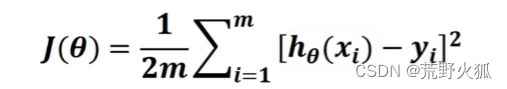
当然我们也可以不用这个形式,照常用之前推出来的形式也可以。
np.random.seed(0) #设置随机种子
np.random.seed(0) # 设置随机种子是一行Python代码,它使用numpy模块中的random子模块来设置随机数生成器的种子为0。
随机数生成器是一种算法,它可以根据一定的规则产生似乎是随机的数列。但是,这些数列实际上是由一个初始值(称为种子)决定的,如果使用相同的种子,那么每次生成的数列也会相同。
设置随机数种子的目的是为了使随机数的结果可复现,也就是说,如果我们想要再次得到相同的随机数,只需要使用相同的种子即可。
numpy模块中的random子模块提供了多种随机数生成函数,例如np.random.rand(),np.random.randn(),np.random.randint()等,它们都会受到np.random.seed()设置的种子的影响。
np.random.seed(0) # 设置随机种子这行代码的作用是将随机数生成器的种子设置为0,这意味着在这行代码之后调用的随机数生成函数都会产生相同的随机数,除非再次改变种子。
import numpy as np
np.random.seed(0) # 设置随机种子
print(np.random.rand(3,2)) #生成3行2列的[0,1) 均匀分布的随机数 均匀分布:每个数出现的概率相同
print(np.random.randn(3,2))#生成3行2列的标准正态分布的随机数 (均值为0,标准差为1) 正态分布:大部分数值都集中在均值附近
print(np.random.randint(1,10,(3,2))) #生成3行2列的[1,10) 均匀分布的随机整数
'''
[[0.5488135 0.71518937]
[0.60276338 0.54488318]
[0.4236548 0.64589411]]
[[ 0.95008842 -0.15135721]
[-0.10321885 0.4105985 ]
[ 0.14404357 1.45427351]]
[[9 2]
[6 9]
[5 4]]
'''
np.linspace(0,10,101)
在生成101个在[0,10]的等距数 (包括0,10)
import numpy as np
print(np.linspace(0, 10, 101)) #在指定的间隔内返回均匀间隔的数字
"""
[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3
1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1
4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5
5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9
7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1 8.2 8.3
8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7
9.8 9.9 10. ]
"""
np.np.random.normal(loc=0.0, scale=1.0, size=None)
np.random.normal是一个Python函数,它属于numpy模块中的random子模块,用来从正态分布(也称为高斯分布)中随机生成指定形状的数组。
正态分布是一种对称概率分布,它的概率密度函数呈钟形曲线,由两个参数决定,分别是均值(μ)和标准差(σ)。 正态分布在自然界和科学研究中经常出现,例如,测量误差、人类身高、智商等都可以近似地用正态分布来描述。
其中,loc参数表示正态分布的均值,缺省值为0.0;scale参数表示正态分布的标准差,缺省值为1.0,必须为非负数;size参数表示输出数组的形状,缺省值为None,表示返回一个标量。
import numpy as np
np.random.seed(0) # 设置随机种子
a = np.random.normal(0, 0.1, (3, 2)) # 生成随机数组
print(a)
'''
[[ 0.17640523 0.04001572]
[ 0.0978738 0.22408932]
[ 0.1867558 -0.09772779]]
'''
代码
这里拟合的函数为y = 2x+3
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟数据,假设真实的w为2,b为3
np.random.seed(0) # 设置随机种子
x = np.linspace(0, 10, 100) # 生成100个在[0,10]的等距数 (包括0,10)
y = 2 * x + 3 + np.random.normal(0, 1, 100) # 生成y值,加入噪声
# 定义一元线性回归模型
def linear_regression(x, w, b):
return w * x + b
# 定义均方误差函数
def mean_squared_error(y_true, y_pred):
return np.mean((y_true - y_pred) ** 2)
# 定义梯度下降算法
def gradient_descent(x, y, w, b, lr, epochs):
# x: 自变量
# y: 目标变量
# w: 斜率的初始值
# b: 截距的初始值
# lr: 学习率
# epochs: 迭代次数
n = len(x) # 样本数量
history_w = [] # 用来记录w的历史值
history_b = [] # 用来记录b的历史值
history_loss = [] # 用来记录损失函数的历史值
for i in range(epochs): # 迭代epochs次
# 计算预测值
y_pred = linear_regression(x, w, b)
# 计算损失值
loss = mean_squared_error(y, y_pred)
# 计算梯度
dw = -2/n * np.sum((y - y_pred) * x)
db = -2/n * np.sum(y - y_pred)
# 更新w和b
w = w - lr * dw
b = b - lr * db
# 记录w,b和损失值
history_w.append(w)
history_b.append(b)
history_loss.append(loss)
# 打印结果
print(f"Epoch {i+1}: w={w:.4f}, b={b:.4f}, loss={loss:.4f}")
return history_w, history_b, history_loss
# 设置超参数
w = 0 # 斜率的初始值
b = 0 # 截距的初始值
lr = 0.02 # 学习率
epochs = 200 # 迭代次数
# 调用梯度下降算法
history_w, history_b, history_loss = gradient_descent(x, y, w, b, lr, epochs)
# 绘制损失函数的变化曲线
plt.plot(range(epochs), history_loss, color="r")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()
# 绘制最终的拟合直线
plt.scatter(x, y, color="b", label="Data")
plt.plot(x, linear_regression(x, history_w[-1], history_b[-1]), color="g", label="Fitted Line")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Linear Regression")
plt.legend()
plt.show()
结果:
迭代两百次后损失为1.0732
拟合函数为y = 2x+2.78 ,能基本拟合成功。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第31张图片](http://img.e-com-net.com/image/info8/529ba18c77ea4d19a1f131eebd01c8da.jpg)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第32张图片](http://img.e-com-net.com/image/info8/f8587bec49c14b6bb43e863505f7ceeb.jpg)
基于求导的数学方法
一样的想法,想求得均方误差函数为最小值,则需要求导求出极小值,求出极小值的方法,大学里都学过,y = kx+b,此时,k,b为未知量,则需要对k和b分别求偏导,令偏导等于0。
在机器学习,通常也写成ŷ = wx+b,斜率w也叫权重(weigh),b为截距。ŷ代表预测值。
MSE:
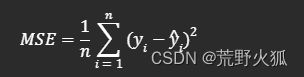
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第33张图片](http://img.e-com-net.com/image/info8/71723ddb268e412d9beb46d660606233.jpg)
代码
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟数据,假设真实的w为2,b为3
np.random.seed(0) # 设置随机种子
x = np.linspace(0, 10, 100) # 生成100个在[0,10]之间的等距数
y = 2 * x + 3 + np.random.normal(0, 1, 100) # 生成y值,加入噪声
# 定义一元线性回归模型
def linear_regression(x, w, b):
return w * x + b
# 定义MSE损失函数
def mean_squared_error(y_true, y_pred):
return np.mean((y_true - y_pred) ** 2)
# 定义基于求导的数学方法
def analytical_solution(x, y):
# x: 自变量
# y: 目标变量
n = len(x) # 样本数量
# 计算w和b的闭式解
w = (n * np.sum(y * x) - np.sum(y) * np.sum(x)) / (n * np.sum(x ** 2) - np.sum(x) ** 2)
b = (np.sum(y) - w * np.sum(x)) / n
# 返回w和b
return w, b
# 调用基于求导的数学方法
w, b = analytical_solution(x, y)
# 计算预测值
y_pred = linear_regression(x, w, b)
# 计算损失值
loss = mean_squared_error(y, y_pred)
# 打印结果
print(f"w={w:.4f}, b={b:.4f}, loss={loss:.4f}")
# 绘制拟合直线
plt.scatter(x, y, color="b", label="Data")
plt.plot(x, y_pred, color="g", label="Fitted Line")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Linear Regression")
plt.legend()
plt.show()
结果:依旧是拟合y=2x+3
w=1.9703, b=3.2085, loss=1.0083
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第34张图片](http://img.e-com-net.com/image/info8/884f61e17e9d4f078a85d767265c2e7e.jpg)
损失率比200次迭代后的梯度下降法还要小一点。
上述两个方法的结论
求导法可以说是比梯度下降法稍好一点,但梯度下降法迭代次数再多下去就不一定了。
改进想法:利用两者
可以先做一次求导法,然后再进行迭代,迭代的学习率可以改的更小一点。
sklearn库方法(最小二乘法)model = LinearRegression()
sklearn: scikit-learn,一个开源的机器学习工具包,它提供了各种分类,回归,聚类,降维,模型选择和预处理等算法,以及一些常用的数据集和评估方法。它建立在 NumPy, SciPy 和 Matplotlib 等数值计算的库之上,可以与 pandas 等数据处理的库协同工作。
pip install scikit-learn
在sklearn库中,也有方便的线性回归库,里面的用的是最小二乘法来拟合(即损失函数是SSE),内部用的是基于求导的数学方法(或者说常见为矩阵微分法)。这里不做详解,具体可见wiki最小二乘法。
步骤如下:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第35张图片](http://img.e-com-net.com/image/info8/179b487fca594c9bbcf5c58bfc2f69ae.jpg)
这里B和θ相当,均为y = k1x1+k2x2+…+b的系数,[k1,k2,k3…,b]
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第36张图片](http://img.e-com-net.com/image/info8/471574a3c9ff45dc93f344646d2d2d1a.jpg)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第37张图片](http://img.e-com-net.com/image/info8/154bacfb828d4eb4a83bb7ab05981a94.jpg)
最后有个前提XTX为可逆才能写成这种。或者说X的行向量不相关才可以这样写,一般而言数据是不相关的,如果相关了,可以采取提前把相关的值删去,再进行拟合或者采取梯度下降法。
#写一个一元线性回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 生成随机数据
np.random.seed(0) # 设置随机种子 #设置随机种子后,每次生成的随机数都是一样的
n = 100 # 数据点个数
x = np.linspace(0, 10, n) # x坐标 #在指定的间隔内返回均匀间隔的数字
y = 2 * x + 3 + np.random.normal(0, 1, size=n) # y坐标
# 使用sklearn的LinearRegression模型进行拟合
model = LinearRegression() #用的是最小二乘法,即最小化误差的平方和(SSE)用的是数学求导法(矩阵微分法)
model.fit(x.reshape(-1, 1), y.reshape(-1, 1)) #model.fit(x, y) #训练 #x.reshape(-1, 1)表示将x转换为一列 相当于转换成矩阵形式
a = model.coef_[0][0] # 拟合得到的参数a #coef_是系数,intercept_是截距
b = model.intercept_[0]# 拟合得到的参数b
print(f"拟合得到的直线为:y = {a:.4f}x + {b:.4f}")
#计算loss
y_pred = a * x + b
loss = np.mean((y_pred - y)**2)
print("loss:", loss)
# 绘制数据点
plt.scatter(x, y, s=10)#s表示点的大小
# 绘制拟合的直线
plt.plot(x, a*x + b, c='r')
plt.show()
结果为:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第38张图片](http://img.e-com-net.com/image/info8/a0c9a2f89b71461289801d217f5a56a8.jpg) 这里在计算loss的时候取了巧,算的是在MSE定义下的loss(实际上SSE下的loss要多乘以n(这里是100)),
这里在计算loss的时候取了巧,算的是在MSE定义下的loss(实际上SSE下的loss要多乘以n(这里是100)),
发现和均方误差函数(MSE)在基于求导的数学方法下得出的结果一致。
可以得出结论:运用MSE和SSE拟合在拟合线性函数时,实际上并无多大差别。(其实在其他函数我也看不出什么差别。。)
scipy库方法(最小二乘法)leastsq(residual, params0, args=(x, y))
scipy: SciPy,是一个开源的科学计算库,它提供了一些数学,统计,优化,信号处理,图像处理,线性代数,稀疏矩阵等方面的功能,以及一些特殊的函数和常量。它也是基于 NumPy 的数组对象进行操作的,可以与 matplotlib 等可视化的库结合使用。
在scipy库中也有最小二乘法的方法。
与上述方法sklearn的区别在于,可以拟合任意形式函数。后续在非线性回归那详细讲述leastsq()函数。这里主要知道下有这个方法。
residual 意为残差。
# 导入库
import numpy as np
from scipy.optimize import leastsq
import matplotlib.pyplot as plt
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 生成随机数据
np.random.seed(0) # 设置随机种子
n = 100 # 数据点个数
x = np.linspace(0, 10, n) # x坐标
y = 2 * x + 3 + np.random.normal(0, 1, size=n) # y坐标
# 定义拟合函数,即要最小化的误差函数
def residual(params, x, y):
k, b = params # 拟合参数
return y - (k * x + b) # 残差
# 初始参数值
params0 = [1, 1]
# 最小二乘法求解
result = leastsq(residual, params0, args=(x, y))
k, b = result[0] # 拟合结果
# 输出结果
print(f"拟合参数: k = {k:.4f}, b = {b:.4f}")
print(f"拟合方程: y = {k:.4f}x + {b:.4f}")
# 绘制散点图
plt.scatter(x, y, c='b', marker='o', label='原始数据') #marker表示点的形状 'o'表示圆形
# 绘制拟合曲线
plt.plot(x, k*x+b, c='r', label='拟合曲线')
# 设置坐标轴标签和图例
plt.xlabel('x')
plt.ylabel('y')
plt.legend() #显示图例 左上角的
# 显示图形
plt.show()
结果为:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第39张图片](http://img.e-com-net.com/image/info8/059fcaac7f9e4e5bbcffe8cd391b03c9.jpg)
可以看出拟合的依旧没有区别,可以证实出里面的原理都是最小二乘法。
当然也很容易看出上述两者的区别
上述两者的区别:
scipy.optimize.leastsq 是一个通用的最小二乘法拟合函数,它可以拟合任意形式的函数,包括线性和非线性的。它的原理是通过最小化误差的平方和来寻找数据的最佳函数匹配。
它的优点是灵活性高,可以处理复杂的函数形式。
缺点是需要自己定义拟合函数和误差函数,以及提供合适的初始值,否则可能导致拟合失败或者结果不准确。
LinearRegression 是 sklearn.linear_model 模块中提供的一个类,它专门用于拟合线性回归模型。它的原理是通过最小二乘法求解线性回归的参数,即使得残差平方和最小的参数。
它的优点是使用方便,只需要传入自变量和因变量的数据,就可以得到拟合结果和相关的统计量。
缺点是只能处理线性的函数形式,不能处理非线性的。
总的来说,scipy.optimize.leastsq 和 LinearRegression 都是基于最小二乘法的拟合方法,但是前者更通用,后者更专业。如果你的数据符合线性关系,可以使用 LinearRegression 来快速得到拟合结果;如果你的数据不符合线性关系,可以使用 scipy.optimize.leastsq 来自定义拟合函数,但是需要注意选择合适的初始值和误差函数。
多元线性回归
若是多元线性回归,实际上y = k1x1+k2x2+…+b,在上文sklearn库方法(最小二乘法)中,其实已经把原理讲清楚了。
这里再补充点平面方程的基础知识,平面方程大多只涉及到三元一次方程。对于线性回归层面来说,就是二元线性回归。
二元线性回归是一种回归分析方法,它用两个自变量(X1和X2)来预测一个因变量(Y)。
相当于y = w1x1+w2x2+b。可以用来拟合出平面。
当然如果用作其他预测需求,二元线性回归的一个例子是,用广告投入(X1)和产品价格(X2)来预测销售量(Y)。
拟合平面
大多数情况下,我们还是不太能断定函数的类型,不知道指定的函数会是什么样,所以下面用的是sklearn库方法。
这里随便自己写的点云的几个点,
LinearRegression()
# 导入库
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 创建数据
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
y = A[:, 0] # 因变量 #A[:,0]表示取所有行的第0列 [[1,3,2,1]]
X = A[:, 1:] # 自变量 #A[:,1:]表示取所有行的第1列及其后面的列 [[2,3],[1,1],[8,9],[11,12]]
# 建立模型
model = LinearRegression() # 创建线性回归模型
model.fit(X, y)
# 绘制散点图
fig = plt.figure() # 创建画布
ax = fig.add_subplot(111, projection='3d') # 创建3D坐标轴 #111表示1行1列第1个子图 #projection='3d'表示3D坐标轴
ax.scatter(X[:, 0], X[:, 1], y, c='b', marker='o') # 绘制散点图 #X[:,0]表示取所有行的第0列 #X[:,1]表示取所有行的第1列 #y表示因变量 #c='b'表示颜色为蓝色 #marker='o'表示散点图的点为圆形
# 绘制拟合线
x1 = np.linspace(X[:, 0].min(), X[:, 0].max(), 10) # 生成x1坐标 #np.linspace()函数用于创建等差数列 #X[:,0].min()表示取所有行的第0列的最小值 #X[:,0].max()表示取所有行的第0列的最大值 #10表示生成10个数
x2 = np.linspace(X[:, 1].min(), X[:, 1].max(), 10)
x1, x2 = np.meshgrid(x1, x2) # 生成网格点坐标矩阵 #np.meshgrid()函数用于生成网格点坐标矩阵 #x1表示x轴坐标矩阵 #x2表示y轴坐标矩阵
#print(model.predict(np.c_[x1.ravel(), x2.ravel()])) 100X1 .reshape(x1.shape) 变为10X10
y_pred = model.predict(np.c_[x1.ravel(), x2.ravel()]).reshape(x1.shape) # 生成拟合平面的z轴坐标 #np.c_[]函数用于按列连接两个矩阵 #x1.ravel()表示将x1转换为一维数组 #x2.ravel()表示将x2转换为一维数组 #np.c_[x1.ravel(), x2.ravel()]表示将x1和x2按列连接 #model.predict()函数用于预测 #np.c_[x1.ravel(), x2.ravel()]表示将x1和x2按列连接 #.reshape(x1.shape)表示将数组转换为x1的形状
ax.plot_surface(x1, x2, y_pred, color='r', alpha=0.5) # 绘制拟合平面 #ax.plot_surface()函数用于绘制三维曲面 #x1表示x轴坐标矩阵 #x2表示y轴坐标矩阵 #y_pred表示z轴坐标矩阵 #color='r'表示颜色为红色 #alpha=0.5表示透明度为0.5
# 设置坐标轴标签
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('Y')
# 显示图形
plt.show()
# 查看结果
print('回归系数:', model.coef_)
print('截距项:', model.intercept_)
print('决定系数:', model.score(X, y))
结果:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第40张图片](http://img.e-com-net.com/image/info8/82a78bb672b747789b07984a5e01b307.jpg)

也就是说拟合的平面为y= 1.83x1-1.81x2+2.98。
决定系数为0.766,这个数介于0-1之间,若是越接近于1,则表示拟合的越好。
这里决定系数的定义为:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第41张图片](http://img.e-com-net.com/image/info8/20c2ee40bd924c54a2c22f1b28a043f2.jpg)
从这个式子可以粗略看出,SSE为0 时,决定系数R2为1,可以说明越接近1,则拟合的越好。
当然上述点看起来拟合的比较好只是巧合,若是随机改一点。就会变成如下情况了。
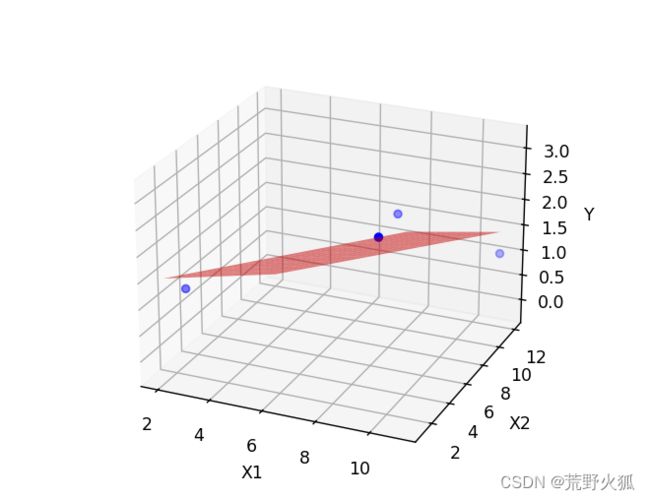
当然我们也可以试试
平面的一般方程y = k1x1+k2x2+b
leastsq()
# 导入库
import numpy as np
from scipy.optimize import leastsq
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 创建数据
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12]])
y = A[:, 0] # 因变量
X = A[:, 1:] # 自变量
# 定义拟合函数,即要最小化的误差函数
def residual(params, X, y):
a, b, c = params # 拟合参数
return y - (a * X[:, 0] + b * X[:, 1] + c) # 残差
# 初始参数值
params0 = [1, 1, 1]
# 最小二乘法求解
result = leastsq(residual, params0, args=(X, y))
a, b, c = result[0] # 拟合结果
# 输出结果
print(f"拟合参数: a = {a:.2f}, b = {b:.2f}, c = {c:.2f}")
print(f"拟合方程: y = {a:.2f}x1 + {b:.2f}x2 + {c:.2f}")
# 绘制散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], y, c='b', marker='o')
# 绘制拟合平面
x1 = np.linspace(X[:, 0].min(), X[:, 0].max(), 10)
x2 = np.linspace(X[:, 1].min(), X[:, 1].max(), 10)
x1, x2 = np.meshgrid(x1, x2)
y_pred = a * x1 + b * x2 + c
ax.plot_surface(x1, x2, y_pred, color='r', alpha=0.5)
# 设置坐标轴标签
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('Y')
# 显示图形
plt.show()
结果:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第42张图片](http://img.e-com-net.com/image/info8/3dd540fb56a04e199aa2ae66a11e9886.jpg)
得出的平面方程与sklearn库方法一致。
非线性回归 leastsq()与curve_fit()
只要不是线性(成比例)关系都可以是非线性回归,注意这里不可以用LinearRegression(),
只能用leastsq() 或者curve_fit(),或者其他一些方法如:least_squares()(求解变量有界)。
当然curve_fit()能拟合非线性,当然也可以拟合线性,不是说只能拟合非线性的意思。
它类似于leastsq() 得事先规定函数,当你这个函数规定为线性时,那就是线性回归了。
首先我们先了解一下leastsq()函数和curve_fit()函数(链接官方文档)。
leastsq(func, x0, args=(), Dfun=None, full_output=0, col_deriv=0, ftol=1.49012e-08, xtol=1.49012e-08, gtol=0.0, maxfev=0, epsfcn=None, factor=100, diag=None)
其中,func 是误差函数,x0 是初始参数的估计值,args 是传递给误差函数的其他参数。(主要了解前三个)其余默认。
Dfun 是雅可比矩阵或其计算方法,full_output 表示是否返回完整的输出,col_deriv 表示是否转置雅可比矩阵,ftol、xtol、gtol 是收敛条件,maxfev 是最大函数调用次数,epsfcn 是数值导数的步长,factor 是初始搜索步长的因子,diag 是对角线缩放矩阵。
注意:leastsq 固定使用 Levenberg-Marquardt 算法。(目标还是使SSE最小,是一种求解非线性最小二乘问题的算法)
关于leastsq()的返回值,第一个元素是回归系数(ndarray数组形式),第二个参数是表示退出原因,根据官网所写,1,2,3,4表示成功拟合了,其他表示不成功。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第43张图片](http://img.e-com-net.com/image/info8/6d3ebeb3572d4388b79a0d1235e7f0d5.jpg)
curve有曲线的意思,fit有适合的意思,意为曲线拟合。
curve_fit(f, xdata, ydata, p0=None, sigma=None, absolute_sigma=False, check_finite=True, bounds=(-inf, inf), method=None, jac=None,** kwargs) # 星和kwargs无空格
其中,f 是拟合的函数模型,xdata 和 ydata 是拟合的数据,p0 是初始参数的估计值。(主要了解前4个和method)
sigma 是数据的标准差,absolute_sigma 表示是否使用绝对标准差,check_finite 表示是否检查数据的有限性,bounds 是参数的边界,method 是优化方法,jac 是雅可比矩阵或其计算方法,kwargs 是其他传递给优化方法的参数。
注意:curve_fit 默认是p0参数全为1,调用Levenberg-Marquardt 算法。method的可选项为:
method='trf’表示使用Trust Region Reflective算法、method='dogbox’表示使用dogleg算法,method='lm’表示使用Levenberg-Marquardt算法,只有这三个。
关于curve_fit的返回值,第一个元素是回归系数(数组形式),第二个参数为协方差矩阵(n*n矩阵)具体第二个参数根据使用算法来确定。(这里不作细节阐述)。
区别:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第44张图片](http://img.e-com-net.com/image/info8/86baa4629dbc46d7bc4f2683b7959d7c.jpg)
拟合曲线
leastsq()方法
# 导入库
import numpy as np
from scipy.optimize import leastsq
import matplotlib.pyplot as plt
# 设置显示中文字体
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 生成随机数据
np.random.seed(0) # 设置随机种子
n = 100 # 数据点个数
x = np.linspace(0, 10, n) # x坐标
y = 2 * np.exp(2 * x) + 3 + np.random.normal(0, 1, size=n) # y坐标
# 定义拟合函数,即要最小化的误差函数
def residual(params, x, y):
a, b, c = params # 拟合参数
return y - (a * np.exp(b * x)+ c) # 残差 真实值-预测值 ##!!!
# 初始参数值
params0 = [1, 1, 1]
# 最小二乘法求解
result = leastsq(residual, params0, args=(x, y))#rgs=(x, y)为传入residual函数的参数
a, b, c = result[0] # 拟合结果
# 输出结果
print("拟合参数:", result[0])
print(f"拟合方程: y = {a:.4f}e^{b:.4f}x + {c:.4f}")
print("退出原因",result[1])
# 绘制散点图
plt.scatter(x, y, c='b', marker='o', label='原始数据') #marker表示点的形状 'o'表示圆形
# 绘制拟合曲线
plt.plot(x, a * np.exp(b * x)+ c, c='r', label='拟合曲线')
# 设置坐标轴标签和图例
plt.xlabel('x')
plt.ylabel('y')
plt.legend() #显示图例 左上角的
# 显示图形
plt.show()
结果:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第45张图片](http://img.e-com-net.com/image/info8/7e121942da414c5f824cb6a5fc74a9a1.jpg)
这里退出原因是2,成功拟合,关于为什么不是1,官网自身的例子是做的线性回归,出来是1。![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第46张图片](http://img.e-com-net.com/image/info8/90ae1230584a4cc59d5fa9c86e7ccc9a.jpg)
我又去上文的【scipy库方法(最小二乘法)leastsq(residual, params0, args=(x, y))】这个例子中打印了下,返回是3。猜测:可能拟合越好的才能是1。
curve_fit()方法
# 导入库
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0) # 设置随机种子
n = 100 # 数据点个数
x = np.linspace(0, 10, n) # x坐标
y = 2 * np.exp(2 * x)+ 3 + np.random.normal(0, 1, size=n) # y坐标
# 定义非线性函数,这里假设是一个指数函数
def func(x, a, b, c):
return a * np.exp(b * x) + c
# 拟合模型,得到回归参数和参数协方差
popt, pcov = curve_fit(func, x, y,p0=[1,1,1],method='lm') # 不加p0=[1,1,1]和method='lm'也可以,默认表示初始参数为1,1,1,method='lm'
#method='lm'表示使用Levenberg-Marquardt算法 #只有这三种
#还有其他的算法 比如method='trf'表示使用Trust Region Reflective算法、method='dogbox'表示使用dogleg算法
# 打印回归参数
print('回归参数:', popt)
# 绘制散点图
plt.scatter(x, y, c='b', marker='o')
# 绘制拟合曲线
y_pred = func(x, *popt) #*popt表示将popt拆分为3个参数 即[1,2,3]拆分为1,2,3
plt.plot(x, y_pred, c='r')
# 设置坐标轴标签
plt.xlabel('X')
plt.ylabel('Y')
# 显示图形
plt.show()
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第47张图片](http://img.e-com-net.com/image/info8/40c592c6b86948829ba29a2d0ae1d684.jpg)
震惊!!!出现了不可思议的一幕,这两个函数返回的竟然不一样,按照官方的说法,此时两者用的算法一样,初始参数一样,数据一样,理论上应该一样才对。
我搜集了下面的博客进行论证,
Python的leastsq()、curve_fit()拟合函数
这个博客得出了两者一致的结果。奇怪的是,我在上文leastsq()方法中,将return改为(a * np.exp(b * x)+ c) -y ,才得出了一致的结论,可官方的定的误差就是真实值-预测值,我应该这样写没错才对,且上面链接的博客也是y-y_pred这样定义。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第48张图片](http://img.e-com-net.com/image/info8/9d149ebccdfc4cc4b084f4d935fa7263.jpg)
于是我从原理上想,SSE,让误差的平方和最小,既然加平方了,那应该谁-谁不重要,在上面链接博客中修改,确实发现结论值没变。在我的代码中,却变了,我改成了返回误差的绝对值abs(y_pred-y),返现值又变了,三个值都不一样。太奇怪了,于是我开始修改函数,改成和我本来的函数参数不一样的函数,发现两者的值变接近了,后来改成与上文链接博客中一样的函数,发现结果竟然一样了。结论:这个应该是库没写好,或者是里面拟合的参数不一样。
有个人和我问了同样的问题,回答很有趣,叫他打电话给这个库,让它改回来。(笑)
这里就不做纠结,但看出leastsq()拟合的稍好些。
拟合曲面
神奇的是,这两个函数在拟合曲面的时候,却像是修好了一样,给出的结论是一致的。
一般的二次曲面方程指这种三元二次方程。(wiki百科)

这里我们要的曲面一般是只有一个面,有z2 时一般会有两个曲面,或者是个闭合的球体。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第49张图片](http://img.e-com-net.com/image/info8/f998f6e57e3b4a05b8d8ad00bb4a9e5b.jpg)
为研究方便,我们一般假设二次曲面为z = ax2 + by2 + cxy + dx + ey + f
leastsq()时,
import numpy as np
from scipy.optimize import leastsq
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 定义二次曲面的函数模型
def func(p, x, y):
a, b, c, d, e, f = p
return a * x ** 2 + b * y ** 2 + c * x * y + d * x + e * y + f
# 定义误差函数
def error(p, x, y, z):
return z - func(p, x, y)
# 数据点
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12],[3,4,5],[7,8,9]])
x = A[:, 0]
y = A[:, 1]
z = A[:, 2]
# 初始参数
p0 = [1, 1, 1, 1, 1, 1]
# 拟合
plsq = leastsq(error, p0, args=(x,y,z))
# 输出结果
print("拟合参数:", plsq[0])
print("退出原因:", plsq[1])
# 绘制散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x, y, z, c='b', marker='o')
# 绘制拟合曲面
x = np.linspace(x.min(), x.max(), 10)
y = np.linspace(y.min(), y.max(), 10)
x, y = np.meshgrid(x, y)
z = func(plsq[0],x,y )
ax.plot_surface(x,y,z, color='r', alpha=0.5)
# 设置坐标轴标签
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
# 显示图形
plt.show()
结果:
z = 0.25x2 -0.083y2 -0.16 xy -0.92x + 2.25y -0.167
退出结果2,表示成功拟合。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第50张图片](http://img.e-com-net.com/image/info8/2504b23b0e9c455bb471c548a3b5faf9.jpg)
注意两点:
1、plsq = leastsq(error, p0, args=(x,y,z)) 后面这里args=(x,y,z)的参数要和定义的误差函数里对应的参数一致,也就是x对应x轴,y对应y轴,z对应z轴,这里z为要拟合的真实值,用x,y的数据来拟合z。
2、绘制拟合曲面时,也要和上面的x,y,z 一一对应。
好,那么我们想用x,z的数据来拟合y,而又不改变args参数和绘制时的参数呢。
我们只需要在数据点选取这,改成该列就行。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第51张图片](http://img.e-com-net.com/image/info8/742143ca490d48ae857f7acf6d1642e9.jpg)
于是拟合的曲面有了如下变化。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第52张图片](http://img.e-com-net.com/image/info8/0aadbc105ee2411da067ba00bdb4aa73.jpg)
当然三个数排列组合A下3上2,有六种,这里就不一一列举了。
同理:
curve_fit()时,
要注意一个点,它只接收xdata,和ydata两种数据,所以不能像leastsq一样直接带入x,y,z,并且接收的xdata数据得是 K*n形式(官网上有讲。)
于是我们可以像下面一样操作。
# 导入库
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 创建数据
A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12],[3,4,5],[7,8,9]])
y = A[:, 2] # 因变量
X = A[:, [0,1]] # 自变量 [[2,3],[1,1],[8,9],[11,12],[4,5],[8,9]] 6*2
# 定义非线性函数,这里假设是一个二次曲面
def func(x, a, b, c, d, e, f):
return a * x[0]**2 + b * x[1]**2 + c * x[0] * x[1] + d * x[0] + e * x[1] + f
# 拟合模型,得到回归参数和参数协方差
popt, pcov = curve_fit(func, xdata=X.T,ydata= y)
#X.T是X的转置 是为了符合func函数的参数形式 (2*6) xdata 可以是多维数组 K*n
#ydata 只能是一维数组 长度为n
# 打印回归参数
print('回归参数:', popt)
print('参数协方差:', pcov)
# 绘制散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], y, c='b', marker='o')
# 绘制拟合曲面
x1 = np.linspace(X[:, 0].min(), X[:, 0].max(), 10)
x2 = np.linspace(X[:, 1].min(), X[:, 1].max(), 10)
x1, x2 = np.meshgrid(x1, x2)
y_pred = func([x1, x2], *popt)
ax.plot_surface(x1, x2, y_pred, color='r', alpha=0.5)
# 设置坐标轴标签
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('Y')
# 显示图形
plt.show()
结果:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第53张图片](http://img.e-com-net.com/image/info8/9f563a1289544f0ab41d0ad40c9aaccd.jpg)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第54张图片](http://img.e-com-net.com/image/info8/4a6936f7090c45c594daafbbd6ba3e87.jpg)
和leastsq()方法一致。只是得出的协方差矩阵里都是无穷,说可能是因为给的数据点不够多导致的。
同理,如何改要拟合的参数,我们想用x,z的数据来拟合y。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第55张图片](http://img.e-com-net.com/image/info8/24d657b90fda4c81ba285884d4cda959.jpg)
结果:(下图表示没有用上面的截图)
和上面leastsq()方法一致。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第56张图片](http://img.e-com-net.com/image/info8/5dc4b54ecdbc48a8b9cbac402eec8ab5.jpg)
调转一个视角看,可以看出拟合的挺好的。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第57张图片](http://img.e-com-net.com/image/info8/870e6e91efd4444caa8c4544ae4375d7.jpg)
协方差及其他一些参数
果然,我加了些数据,协方差就显示出来了。
另外,我还想要其他数据来研究这个拟合的程度好坏。
我可以
leastsq()时
x, ier, cov_x, infodict, mesg = scipy.optimize.leastsq(func, x0, full_output=True)
curve_fit()时
popt, pcov, infodict, errmsg, ier = curve_fit (f, xdata, ydata, full_output = True)
这里我用了curve_fit()的拟合二次曲面来做实验。
与上文的部分修改片段代码(其余不变)
# 导入库
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 创建数据
#A = np.array([[1, 2, 3], [3, 1, 1], [2, 8, 9], [1, 11, 12],[3,4,5],[7,8,9]])
# 生成随机数据
np.random.seed(0) # 设置随机种子
n = 100 # 数据点个数
x = np.linspace(0, 10, n) # x坐标
y = np.random.randint(1, 10, n) # y坐标
z = 2 * y**2 + 3 + np.random.normal(0, 1, size=n) # y坐标
A = np.vstack([x,y,z]).T #按垂直方向(行顺序)堆叠数组构成一个新的数组 成3x100的矩阵 然后转置成100x3的矩阵
y = A[:, 2] # 因变量
X = A[:, [0,1]] # 自变量 [[2,3],[1,1],[8,9],[11,12],[4,5],[8,9]] 6*2
# 定义非线性函数,这里假设是一个二次曲面
def func(x, a, b, c, d, e, f):
return a * x[0]**2 + b * x[1]**2 + c * x[0] * x[1] + d * x[0] + e * x[1] + f
# 拟合模型,得到回归参数和参数协方差
#popt, pcov = curve_fit(func, X.T, y)
popt, pcov, infodict, mesg, ier = curve_fit (func, xdata=X.T,ydata= y, full_output = True)
#X.T是X的转置 是为了符合func函数的参数形式 (2*6) xdata 可以是多维数组 K*n
#ydata 只能是一维数组 长度为n
# 打印回归参数
print('回归参数:', popt)
print('参数协方差:', pcov)
print('infodict:', infodict) #infodict
print('mesg:', mesg)
print('ier:', ier)
结果:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第58张图片](http://img.e-com-net.com/image/info8/d3aa7befb31a44e084e1293f195f0769.jpg)
部分输出:

可以看到信息告诉我们,实际值和预测值的误差平方和最多为0。退出原因为1。
也就是说拟合的SSE为0。拟合的十分完美。
五、如何求取点云的缺陷
缺陷分类
采用对曲面全局曲率分析的办法对其进行缺陷检测,依托高斯曲率和平均曲率正负性质,作为路面缺陷凹凸特征判断依据,进而识别出缺陷形状特征。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第59张图片](http://img.e-com-net.com/image/info8/48a692cfef9641c9929bda82e7078e9f.jpg)
截图来自:基于图像和点云的路面缺陷检测及点云修复技术研究_施洋
高斯曲率、平均曲率
高斯曲率定义(wiki)

平均曲率定义(wiki)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第60张图片](http://img.e-com-net.com/image/info8/74761f76b5804b6dbbe6179841fb69b2.jpg)
第一基本形式定义(wiki)![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第61张图片](http://img.e-com-net.com/image/info8/da01053df1114cb0acf521bffe3d97fb.jpg)
第二基本形式定义(wiki)
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第62张图片](http://img.e-com-net.com/image/info8/f896bc3b51fe4fd585c321d905755392.jpg)
于是我们可以得出:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第63张图片](http://img.e-com-net.com/image/info8/8d71131a657a486b98434c2c85b420d1.jpg)
截图来自:基于图像和点云的路面缺陷检测及点云修复技术研究_施洋
公式推导
首先推导出一般的式子:

![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第64张图片](http://img.e-com-net.com/image/info8/02127585cfb740bbbadfa397359b4b7d.jpg)
这里叉积可以这样求:
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第65张图片](http://img.e-com-net.com/image/info8/d524eebb67ca4559817f7acafa4ee234.jpg)
然后现在只要求导操作就行了,我们这里用中心差分法近似求导,大家都知道求导实际上上是对因变量的变化量在自变量下的变化量的极限。
![【点云、图像】学习中 常见的数学知识及其中的关系与python实战[更新中]_第66张图片](http://img.e-com-net.com/image/info8/7107e326d0834e5c93839cacce8e6115.jpg)
参考
【数值分析】二元函数二阶混合偏导数的近似计算式与误差阶推导
其中混合偏导求法为
![]()
求取高斯曲率和平均曲率的代码实现
这里我们用上文拟合出的曲面函数来实验。
# 导入numpy库
import numpy as np
# 定义曲面函数z = f(x, y)
def f(x, y):
return 0.25*x**2 -0.083*y**2 -0.16* x*y -0.92*x + 2.25*y -0.167
# 定义曲面的梯度函数,即一阶偏导数
def gradient(f, x, y):
# 使用中心差分法近似求导 #参考https://cloud.tencent.com/developer/article/1685164
h = 1e-6 # 差分步长,可以根据精度要求调整
df_dx = (f(x + h, y) - f(x - h, y)) / (2 * h) # 对x求偏导
df_dy = (f(x, y + h) - f(x, y - h)) / (2 * h) # 对y求偏导
return df_dx, df_dy
# 定义曲面的曲率函数,即二阶偏导数
def curvature(f, x, y):
# 使用中心差分法近似求导
h = 1e-6 # 差分步长,可以根据精度要求调整
d2f_dx2 = (f(x + h, y) - 2 * f(x, y) + f(x - h, y)) / (h ** 2) # 对x求二阶偏导
d2f_dy2 = (f(x, y + h) - 2 * f(x, y) + f(x, y - h)) / (h ** 2) # 对y求二阶偏导
d2f_dxdy = (f(x + h, y + h) - f(x + h, y - h) - f(x - h, y + h) + f(x - h, y - h)) / (4 * h ** 2) # 对xy求混合偏导
# 根据公式计算高斯曲率K和平均曲率H
df_dx, df_dy = gradient(f, x, y) # 调用梯度函数求一阶偏导
E = 1 + df_dx ** 2
F = df_dx * df_dy
G = 1 + df_dy ** 2
L = d2f_dx2 / np.sqrt(1 + df_dx ** 2 + df_dy ** 2) #np.sqrt()表示开方
M = d2f_dxdy / np.sqrt(1 + df_dx ** 2 + df_dy ** 2)
N = d2f_dy2 / np.sqrt(1 + df_dx ** 2 + df_dy ** 2)
K = (L * N - M ** 2) / (E * G - F ** 2) # 高斯曲率
H = (E * N + G * L - 2 * F * M) / (2 * (E * G - F ** 2)) # 平均曲率
return K, H
# 测试曲率函数
x = 1 # 某一点的x坐标
y = 2 # 某一点的y坐标
K, H = curvature(f, x, y) # 计算该点的曲率
print(f"高斯曲率为:{K:.6f}")
print(f"平均曲率为:{H:.6f}")
