图解 V8 执行 JS 的过程
本文来分享 V8 引擎执行 JavaScript 的过程
1. JS 代码执行过程
在说V8的执行JavaScript代码的机制之前,我们先来看看编译型和解释型语言的区别。
-
编译型语言和解释型语言
我们知道,机器是不能直接理解代码的。所以,在执行程序之前,需要将代码翻译成机器能读懂的机器语言。按语言的执行流程,可以把计算机语言划分为编译型语言和解释型语言:
- 编译型语言: 在代码运行前编译器直接将对应的代码转换成机器码,运行时不需要再重新翻译,直接可以使用编译后的结果;
- 解释型语言: 需要将代码转换成机器码,和编译型语言的区别在于运行时需要转换。解释型语言的执行速度要慢于编译型语言,因为解释型语言每次执行都需要把源码转换一次才能执行。
Java 和 C++ 等语言都是编译型语言,而 JavaScript 是解释性语言,它整体的执行速度会略慢于编译型的语言。V8 是众多浏览器的 JS 引擎中性能表现最好的一个,并且它是 Chrome 的内核,Node.js 也是基于 V8 引擎研发的。
编译型语言和解释器语言代码执行的具体流程如下:
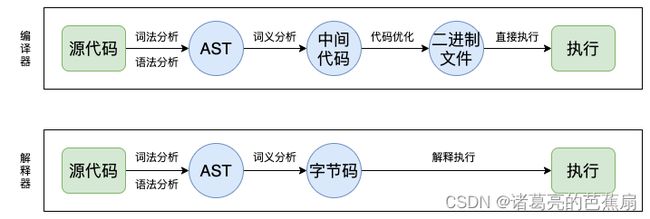
两者的执行流程如下:
- 在编译型语言的编译过程中,编译器首先会依次对源代码进行词法分析、语法分析,生成抽象语法树(AST),然后优化代码,最后再生成处理器能够理解的机器码。如果编译成功,将会生成一个可执行的文件。但如果编译过程发生了语法或者其他的错误,那么编译器就会抛出异常,最后的二进制文件也不会生成成功。
- 在解释型语言的解释过程中,同样解释器也会对源代码进行词法分析、语法分析,并生成抽象语法树(AST),不过它会再基于抽象语法树生成字节码,最后再根据字节码来执行程序、输出结果。
-
V8 执行代码过程
V8 在执行过程用到了解释器和编译器。 其执行过程如下:
- Parse 阶段:V8 引擎将 JS 代码转换成 AST(抽象语法树);
- Ignition 阶段:解释器将 AST 转换为字节码,解析执行字节码也会为下一个阶段优化编译提供需要的信息;
- TurboFan 阶段:编译器利用上个阶段收集的信息,将字节码优化为可以执行的机器码;
- Orinoco 阶段:垃圾回收阶段,将程序中不再使用的内存空间进行回收。
这里前三个步骤是JavaScript的执行过程,最后一步是垃圾回收的过程。下面就先来看看V8 执行 JavaScript的过程。
① 生成抽象语法树
这个过程就是将源代码转换为抽象语法树(AST),并生成执行上下文,执行上下文就是代码在执行过程中的环境信息。
将 JS 代码解析成 AST主要分为两个阶段:
- 词法分析:这个阶段会将源代码拆成最小的、不可再分的词法单元,称为 token。比如代码 var a = 1;通常会被分解成 var 、a、=、1、; 这五个词法单元。代码中的空格在 JavaScript 中是直接忽略的,简单来说就是将 JavaScript 代码解析成一个个令牌(Token)。
- 语法分析:这个过程是将上一步生成的 token 数据,根据语法规则转为 AST。如果源码符合语法规则,这一步就会顺利完成。如果源码存在语法错误,这一步就会终止,并抛出一个语法错误,简单来说就是将令牌组装成一棵抽象的语法树(AST)。
通过词法分析会对代码逐个字符进行解析,生成类似下面结构的令牌(Token),这些令牌类型各不相同,有关键字、标识符、符号、数字等。代码 var a = 1;会转化为下面这样的令牌:
Keyword(var) Identifier(name) Punctuator(=) Number(1)语法分析阶段会用令牌生成一棵抽象语法树,生成树的过程中会去除不必要的符号令牌,然后按照语法规则来生成。下面来看两段代码:
// 第一段代码 var a = 1; // 第二段代码 function sum (a,b) { return a + b; }将这两段代码分别转换成 AST 抽象语法树之后返回的 JSON 如下:
- 第一段代码,编译后的结果:
{ "type": "Program", "start": 0, "end": 10, "body": [ { "type": "VariableDeclaration", "start": 0, "end": 10, "declarations": [ { "type": "VariableDeclarator", "start": 4, "end": 9, "id": { "type": "Identifier", "start": 4, "end": 5, "name": "a" }, "init": { "type": "Literal", "start": 8, "end": 9, "value": 1, "raw": "1" } } ], "kind": "var" } ], "sourceType": "module" }它的结构大致如下:

- 第二段代码,编译出来的结果:
{ "type": "Program", "start": 0, "end": 38, "body": [ { "type": "FunctionDeclaration", "start": 0, "end": 38, "id": { "type": "Identifier", "start": 9, "end": 12, "name": "sum" }, "expression": false, "generator": false, "async": false, "params": [ { "type": "Identifier", "start": 14, "end": 15, "name": "a" }, { "type": "Identifier", "start": 16, "end": 17, "name": "b" } ], "body": { "type": "BlockStatement", "start": 19, "end": 38, "body": [ { "type": "ReturnStatement", "start": 23, "end": 36, "argument": { "type": "BinaryExpression", "start": 30, "end": 35, "left": { "type": "Identifier", "start": 30, "end": 31, "name": "a" }, "operator": "+", "right": { "type": "Identifier", "start": 34, "end": 35, "name": "b" } } } ] } } ], "sourceType": "module" }可以看到,AST 只是源代码语法结构的一种抽象的表示形式,计算机也不会去直接去识别 JS 代码,转换成抽象语法树也只是识别这一过程中的第一步。AST 的结构和代码的结构非常相似,其实也可以把 AST 看成代码的结构化的表示,编译器或者解释器后续的工作都需要依赖于 AST。
AST的应用场景:
AST 是一种很重要的数据结构,很多地方用到了AST。比如在 Babel 中,Babel 是一个代码转码器,可以将 ES6 代码转为 ES5 代码。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。
除了 Babel 之外,ESLint 也使用到了 AST。ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题。
除了上述应用场景,AST 的应用场景还有很多:
- JS 反编译,语法解析;
- 代码高亮;
- 关键字匹配;
- 代码压缩。
② 生成字节码
有了 抽象语法树 AST 和执行上下文后,就轮到解释器就登场了,它会根据 AST 生成字节码,并解释执行字节码。
在 V8 的早期版本中,是通过 AST 直接转换成机器码的。将 AST 直接转换为机器码会存在一些问题:
- 直接转换会带来内存占用过大的问题,因为将抽象语法树全部生成了机器码,而机器码相比字节码占用的内存多了很多;
- 某些 JavaScript 使用场景使用解释器更为合适,解析成字节码,有些代码没必要生成机器码,进而尽可能减少了占用内存过大的问题。
为了解决内存占用问题,就在 V8 引擎中引入了字节码。那什么是字节码呢?为什么引入字节码就能解决内存占用问题呢?
字节码就是介于 AST 和机器码之间的一种代码。 需要将其转换成机器码后才能执行,字节码是对机器码的一个抽象描述,相对于机器码而言,它的代码量更小,从而可以减少内存消耗。解释器除了可以快速生成没有优化的字节码外,还可以执行部分字节码。
③ 生成机器码
生成字节码之后,就进入执行阶段了,实际上,这一步就是将字节码生成机器码。
一般情况下,如果字节码是第一次执行,那么解释器就会逐条解释执行。在执行字节码过程中,如果发现有热代码(重复执行的代码,运行次数超过某个阈值就被标记为热代码),那么后台的编译器就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码即可,这样提升了代码的执行效率。
字节码配合解释器和编译器的技术就是 即时编译(JIT)。在 V8 中就是指解释器在解释执行字节码的同时,收集代码信息,当它发现某一部分代码变热了之后,编译器便闪亮登场,把热点的字节码转换为机器码,并把转换后的机器码保存起来,以备下次使用。
因为 V8 引擎是多线程的,编译器的编译线程和生成字节码不会在同一个线程上,这样可以和解释器相互配合着使用,不受另一方的影响。下面是JIT技术的工作机制:
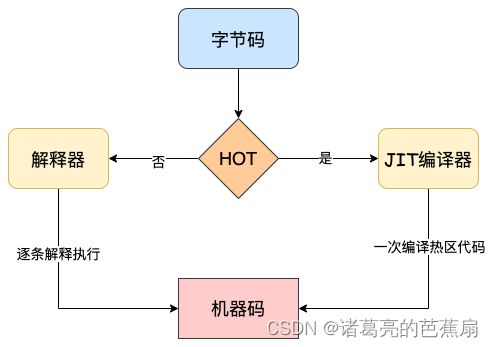
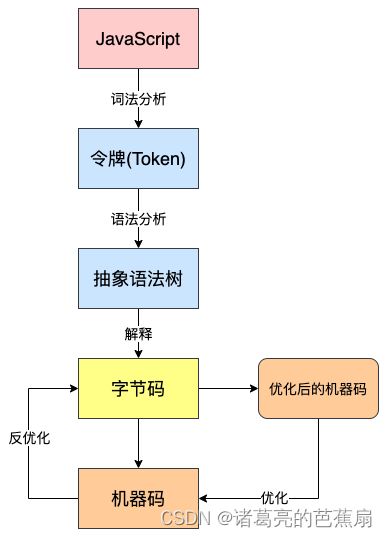
解释器在得到 AST 之后,会按需进行解释和执行。也就是说如果某个函数没有被调用,则不会去解释执行它。在这个过程中解释器会将一些重复可优化的操作收集起来生成分析数据,然后将生成的字节码和分析数据传给编译器,编译器会依据分析数据来生成高度优化的机器码。
优化后的机器码的作用和缓存很类似,当解释器再次遇到相同的内容时,就可以直接执行优化后的机器码。当然优化后的代码有时可能会无法运行(比如函数参数类型改变),那么会再次反优化为字节码交给解释器。
整个过程如下图所示:
-
执行过程优化
如果JavaScript代码在执行前都要完全经过解析才能执行,那可能会面临以下问题:
- 代码执行时间变长:一次性解析所有代码会增加代码的运行时间。
- 消耗更多内存:解析完的 AST 以及根据 AST 编译后的字节码都会存放在内存中,会占用更多内存空间。
- 占用磁盘空间:编译后的代码会缓存在磁盘上,占用磁盘空间。
所以,V8 引擎使用了延迟解析:在解析过程中,对于不是立即执行的函数,只进行预解析;只有当函数调用时,才对函数进行全量解析。
进行预解析时,只验证函数语法是否有效、解析函数声明、确定函数作用域,不生成 AST,而实现预解析的,就是 Pre-Parser 解析器。
以下面代码为例:
function sum(a, b) { return a + b; } const a = 666; const c = 996; sum(1, 1);V8 解析器是从上往下解析代码的,当解析器遇到函数声明 sum 时,发现它不是立即执行,所以会用 Pre-Parser 解析器对其预解析,过程中只会解析函数声明,不会解析函数内部代码,不会为函数内部代码生成 AST。
之后解释器会把 AST 编译为字节码并执行,解释器会按照自上而下的顺序执行代码,先执行 const a = 666; 和 const c = 996; ,然后执行函数调用 sum(1, 1) ,这时 Parser 解析器才会继续解析函数内的代码、生成 AST,再交给解释器编译执行。