golang协程goroutine简介
文章目录
- goroutine
-
- 与thread比较
- M:N模型
- 调度策略
-
- 可运行队列
- 协作式调度
- 系统调用
-
- 同步调用
- 异步调用
- scheduler的陷阱
goroutine是Go语言中的轻量级线程实现,由Go运行时(runtime)管理。
goroutine
Go提供一种机制,可在线程中自己实现调度,上下文切换更轻量(达到线程数少,而并发数并不少的效果)。Goroutine的主要概念:
- G(Goroutine):Go的协程;
- M(Machine):工作线程(由操作系统调度);
- P(Processor):处理器(Go中概念,不指CPU;包含运行go代码的必要资源,有调度goroutine的能力);个数在程序启动时决定,默认为CPU核数(可通过runtime.GOMAXPROCS()设定)。
M必须拥有P才可执行G中的代码,P含有一个包含多个G的队列,P可以调度G交由M执行:
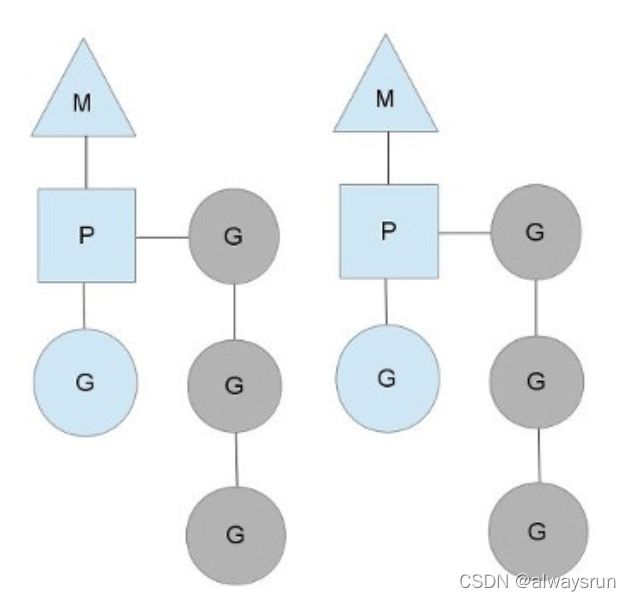
在程序启动时,Go程序就会为main()函数创建一个默认的goroutine;在运行过程中,可随时通过go关键字来创建goroutine;所有 goroutine 会在 main() 函数结束时一同结束。
GPM运行示意图如下所示(详情可见调度策略部分介绍)

与thread比较
goroutine可看作是thread的进一步抽象,它更加轻量,可单独执行;与thread相比:
- 内存占用:goroutine默认栈为2KB(实际运行中,根据需要可自动扩容);而thread至少需要1MB,而且还需要一个’guard page‘区域,以隔离不同thread区域;
- 创建与销毁:goroutine由go runtime管理,其创建是用户级的,消耗小;而thread由操作系统管理,是内核级的,消耗巨大;
- 切换:goroutines 切换只需保存三个寄存器(Program Counter, Stack Pointer and BP),一般200ns即可完成;而thread切换时需要保存各种寄存器,一般需要1000~1500ns。
M:N模型
go runtime负责管理goroutine,Runtime会在程序启动的时候,创建M个线程(CPU执行调度的单位),之后创建的N个goroutine都会依附在这M个线程上执行。
在同一时刻,一个线程上只能跑一个goroutine。当goroutine发生阻塞时,runtime会把当前goroutine调度走,让其他goroutine来执行,不让一个线程闲着。
调度策略
go程序由两层构成:program(用户程序)和runtime(运行时)。Runtime 维护所有的goroutines,并通过 scheduler 来进行调度。

可运行队列
所有可执行go routine都放在队列中:
- 全局队列(GRQ):存储全局可运行的goroutine(从系统调用中恢复的G);
- 本地可运行队列(LRQ):存储本地(分配到P的)可运行的goroutine;
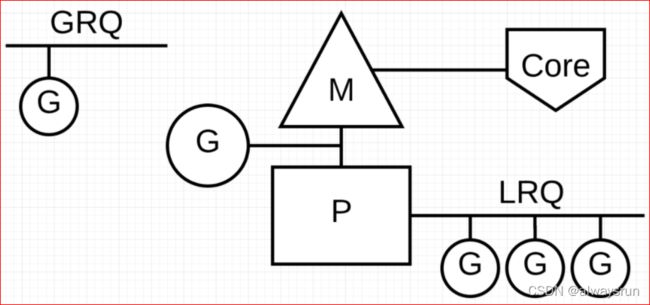
Go scheduler采用队列轮转法: P周期性地将G调度到M中执行(一小段时间),完成后保存上下文然后放入队尾,并重新取出一个G执行;每个P会周期性地查看全局队列中是否有待运行的G并将其调度到M中执行。
工作量窃取:各个P中维护的G队列很可能是不均衡的;空闲的P会查询全局队列,若全局队列也空,则会从其他P中窃取G(一般每次取一半)。
协作式调度
Go scheduler 是 Go runtime 的一部分,运行在用户空间,其采用协作式调度(cooperating)。
Go scheduler的核心思想是:
- 线程重用;
- 限制同时运行(不包含阻塞)的线程数为 N(N 等于 CPU 的核数);
- 线程私有的执行队列:
- 线程阻塞时,可将 runqueues 传递给其他线程。
- 线程空闲时,可从其他线程 stealing goroutine 来运行。
goroutine会在以下时机发生调度:
| 情形 | 说明 |
|---|---|
关键字 go |
go 创建一个新的 goroutine,Go scheduler 会考虑调度 |
| GC | 由于进行 GC 的 goroutine 也需要在 M 上运行,因此肯定会发生调度 |
| 系统调用 | goroutine 进行系统调用时,会阻塞 M,所以它会被调度走,同时一个新的 goroutine 会被调度上来 |
| 内存同步访问 | atomic,mutex,channel 操作等会使 goroutine 阻塞,条件满足后会被重新调度; |
系统调用
系统调用分为同步与异步,对不同的情况go有不同的策略。一般M数量会略大于P的个数(处理G产生系统调用)。
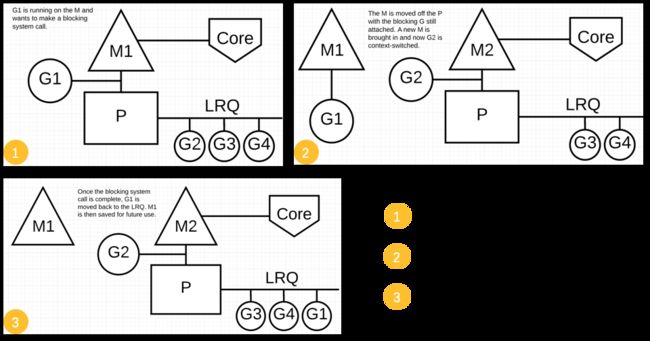
同步调用
对于同步调用:G1即将进入系统调用时,M1将释放P,让某个空闲的M2获取P并继续执行P队列中剩余的G(即M2接替M1的工作);M2可能来源于M的缓存池,也可能是新建的。当G1系统调用完成后,根据M1能否获取到P,将对G1做不同的处理:
- 有空闲的P,则获取一个以继续执行G1;
- 无空闲P,将G1放入全局队列,等待被其他P调度;M1进入缓冲池睡眠。
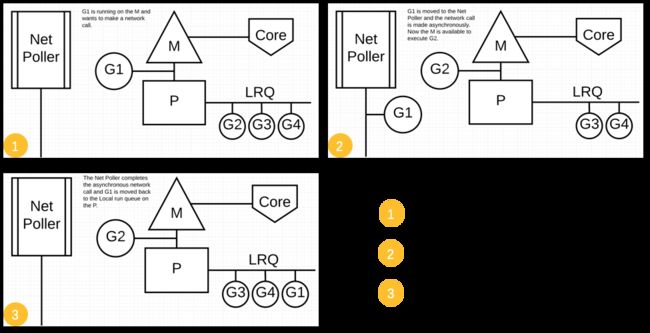
异步调用
对于异步调用:M 不会被阻塞,G 的异步请求会被“代理人” network poller 接手,G 也会被绑定到 network poller,等到系统调用结束,G 才会重新回到 P 上。M 由于没被阻塞,它因此可以继续执行 LRQ 里的其他 G。
scheduler的陷阱
Go scheduler 有一个后台线程在持续监控,一旦发现 goroutine 运行超过 10 ms,会设置 goroutine 的“抢占标志位”,之后调度器会处理。但是设置标志位的时机只有在函数“序言”部分,对于没有函数调用的就没有办法了。
func main() {
var x int
threads := runtime.GOMAXPROCS(0)
for i := 0; i < threads; i++ {
go func() {
for { x++ }
}()
}
time.Sleep(time.Second)
fmt.Println("x =", x)
}
由于goroutine数量与M数量相等,所有goroutine启动后都进入了死循环中,没有调度出的机会;所以主线程一直没有机会执行。
运行结果是:在死循环里出不来,不会输出最后的那条打印语句。
为避免此类问题,需要减少死循环的goroutine数量:
func main() {
var x int
threads := runtime.GOMAXPROCS(0) - 1
for i := 0; i < threads; i++ {
go func() {
for { x++ }
}()
}
time.Sleep(time.Second)
fmt.Println("x =", x)
}
运行结果:x = 0