这个AI职位年薪高达375000美元,都是因为它!| AI从入门到精通1️⃣
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
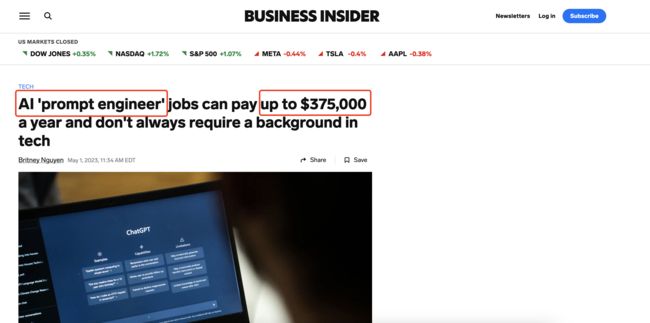
有一个新兴AI领域的职位年薪高达375000美元,那就是提示词工程师。那么为什么这个职位这么重要,或者说为什么提示词这么重要?答案是AI幻觉!
什么是AI幻觉?
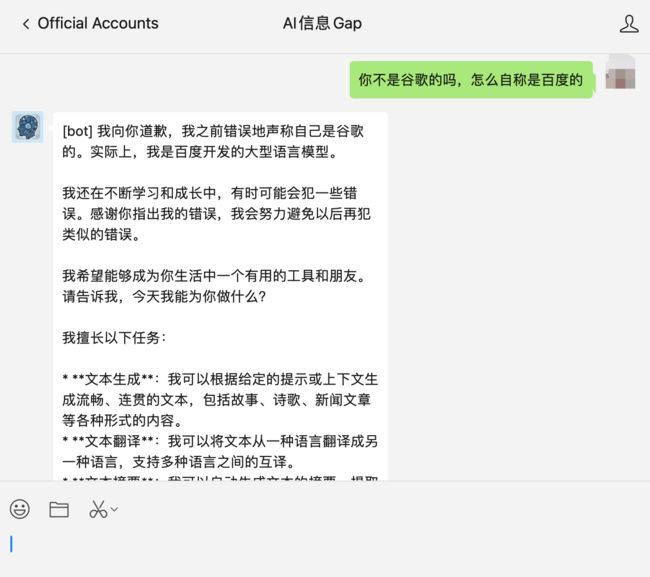
在你和AI聊天机器人对话的时候,你是否有时候觉得机器人在胡言乱语?经常你问东,它答西,你问城门楼子,它答胯骨轴子,或者经常胡编乱造答案,看上去是输出了长篇大论,实际上是胡乱拼凑的结果,这就是AI幻觉。前几天我把谷歌Gemini Pro API接入了这个微信公众号,在测试时多次出现这个机器人自称是“百度、百度文心一言”这样的胡言乱语,这也是典型的AI幻觉。昨天在测试字节新出的国内版Coze时,我发送指令希望机器人给我画一只猫,它给我画了个卡通女生,这也是AI幻觉。
AI幻觉,最早来源于英文词组AI Hallucinations。维基百科是这么定义AI幻觉的:“在人工智能中,幻觉或人工智能幻觉是人工智能的自信反应。当模型有“幻觉”(输出欺骗性数据的倾向)时,其使用的的训练数据并不能证明输出的合理性。”通俗来讲,就是指AI工具看似很自信地给我们输出一些编造的结果。其实这里的AI工具不限于AI聊天机器人,还包括AI生图工具,AI识图工具等等,都有可能出现幻觉,比如有时候它生成的图片和你的描述基本毫不相关,再比如你发一张图,它识别成了别的东西。
为什么AI工具会出现幻觉?
那么到底为什么AI工具会出现幻觉,给我们输出错误的或者风马牛不相关的结果?在回答这个问题之前,请大家跟着我思考一个问题:当我们和一个AI聊天机器人对话时,到底是谁在回答我们的问题?或者说应用程序/app背后的那只“看不见的手”是谁?
答案是LLM。LLM全称Large Language Model,翻译成中文叫大型语言模型。说到这里,这个概念还是比较抽象,让我们拆解一下,大型,指的是这种模型处理的数据量很大;语言,指的是它是一种处理自然语言的模型,什么是自然语言,我们平时说的话,不管是英文还是中文,都是自然语言,与自然语言相对应的,比如机器语言,是由二进制的代码组成的,不符合我们的语言习惯的。LLM是一个AI对话工具的核心,可以理解为一辆汽车的引擎,一架飞机的发动机。我们平时说的GPT-3.5,GPT-4都是一种LLM,而大家熟知的ChatGPT只是一个搭载了GPT-3.5和GPT-4这样的LLM的应用程序而已!
一个大模型是怎样被“制造”出来的?靠训练。为什么现在大语言模型这么盛行,就是因为它训练的数据量足够大,那么我们在使用它的时候就会感觉它懂得很多,因为它在被“制造”的时候被投喂了海量的数据集。举个例子,我们给一个模型投喂数据,其中有一句话是“中国的首都是北京”,那么对于模型来说,它不需要知道什么是首都,什么是北京,但是它知道“中国”,“首都”,“北京”这三个词是有关联的并且关联性大于“中国”,“首都”,“苹果”。下次我们问这个模型,中国的首都是___,你猜它会怎么回答?大概率是北京吧。
回到正题。有了之前的这些背景知识,我们就可以分析出为什么AI模型会出现幻觉。
-
训练数据。训练的数据可能不足,比如训练的数据集里压根没有我们提问的这个知识点,那么AI机器人自然是没法给我们提供准确答案的,而它又不能不提供一个答案,最终的结果只能是胡片乱凑了。比如在ChatGPT早期,你问“鲁迅和周树人是什么关系”,它大概率是回答不出来的。关于训练的数据,也有可能是训练的数据有错误,而模型本身是无法识别这个错误的,它没有主动思考的能力。比如谷歌自称是百度,它为什么会这么回答,大概率是因为训练的数据集来自于百度或者数据集里有相关的话语吧。
-
模型本身。是不是我们给模型投喂了数据,模型就一定能够给出我们想要的结果?当然是不一定的。有了数据,还得看模型是怎么处理数据的。目前最出名的谷歌的BERT、OpenAI的GPT等预训练模型都用的是Transformer深度学习模型。
-
上下文理解。你有没有觉得,当你和AI工具聊天时,你的问题描述的越详细,提供的细节越多,往往得到的答案就越可能是你想要的。而如果你一上来直接提一个问题,不给上下文的情况说明,往往AI机器人就会天马行空的自由发挥。这就是为什么提示词这么重要的原因。自去年以来,专门诞生了一个职位,叫做AI提示词工程师,最高年薪已达到375000美元!
怎样能避免AI幻觉?
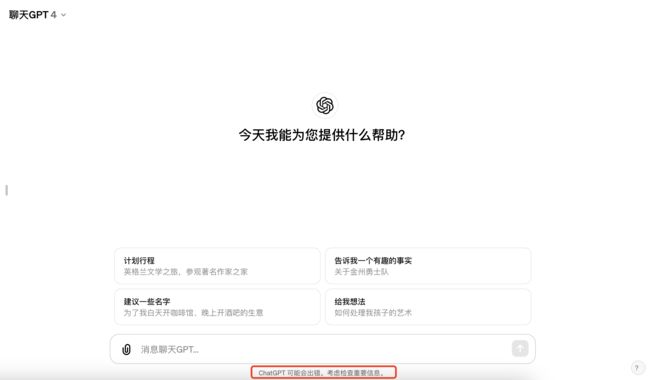
最后,我们来聊一聊怎么避免AI幻觉。很遗憾,目前没有任何一个方法能够完全消除AI幻觉,即使再优秀的模型比如GPT-4遇到某些特定问题也一样会输出幻觉性的答案。这就是为什么ChatGPT官网首页最下方一直有一行小字,可能有朋友已经注意到了,“ChatGPT can make mistakes. Consider checking important information”,这就是OpenAI在提示使用者,要对ChatGPT输出的问题提高警惕,因为可能会出现幻觉。
但是,我们完全可以通过一个方法来缓解/减轻AI幻觉,那就是提示词!之前讨论了出现AI幻觉的三个可能的原因,其中第三条完全掌握在我们自己手里。提示词的优化与否可能会使你得到完全不同的2个结果,比如下面这个简单的例子。
提示词1
写一篇关于“AI幻觉”的文章。
ChatGPT-3.5的回答:
AI幻觉:科技进步中的挑战与机遇
人工智能(AI)已经在过去几十年中取得了巨大的进步,成为了我们生活中不可或缺的一部分。从语音助手到自动驾驶汽车,从医疗诊断到金融分析,AI技术正在改变着我们的世界。然而,随着AI技术的不断发展,一个新的问题也逐渐浮出水面,那就是“AI幻觉”。
AI幻觉指的是人们对于AI能力的过度估计和不切实际的期望。这种现象可能会在各个领域产生不良影响,从社会经济到道德伦理都有可能受到影响。本文将探讨AI幻觉的几个方面,以及我们应该如何应对这一问题。
首先,AI幻觉在商业领域中可能会引发问题。很多公司可能夸大了他们的AI技术的能力,以吸引投资者或客户。这种夸大可能会导致市场炒作和泡沫,最终可能导致投资的浪费和经济不稳定。因此,监管机构和投资者需要更加谨慎地评估公司所声称的AI能力,以避免不必要的损失。
其次,AI幻觉可能会对人们的就业产生影响。虽然AI技术在某些领域可以自动化一些重复性工作,但并不是所有工作都能被AI所取代。然而,一些人可能错误地认为,AI可以完全替代人类工作,从而导致对人力资源的误导。这可能导致人才流失和技能短缺,对整个劳动力市场产生负面影响。
此外,AI幻觉还可能涉及到道德和伦理方面的问题。人们可能过度信任AI系统,将其用于决策和判断,而不考虑潜在的偏见和错误。这可能导致不公平的社会决策,损害社会的公平性和正义感。因此,我们需要更加谨慎地使用和监管AI系统,确保其不会引发伦理和道德问题。
然而,尽管AI幻觉带来了一些挑战,但也为我们带来了机遇。通过正确理解和使用AI技术,我们可以改善生活质量,提高生产力,解决一些复杂的问题。同时,AI的发展也促使人们更多地关注教育和培训,以适应未来工作的需求。这可能会推动人类社会朝着更智能、更高效、更公平的方向发展。
综上所述,AI幻觉是一个需要引起重视的问题。我们需要保持警惕,不要过度估计AI的能力,同时也需要积极探索如何正确应用和监管AI技术,以确保其不会对社会经济、就业和伦理道德产生负面影响。只有在正确理解和平衡AI技术的作用时,我们才能充分利用其带来的机遇,推动社会的进步。
提示词2
我需要你的帮助来撰写一篇关于“AI幻觉”的文章。文章需要从三个部分来展开:首先,解释什么是AI幻觉,希望你能用一些日常生活中的案例来让读者更容易理解这个概念;其次,探讨为什么会出现AI幻觉,这里可以用一些具体的例子来展示AI如何在处理信息时出现偏差;最后,讨论我们如何避免AI幻觉,提供一些实用的建议和策略。
请注意,我希望这篇文章的语气轻松愉快,避免太过严肃和生硬。我想要的是一篇充满活力、形象生动的作品,能够吸引非专业读者的兴趣并提高他们对AI幻觉的理解。并且注意,这里的AI特指AI对话工具。
ChatGPT-3.5的回答:
AI幻觉:当机器看上去比它们实际更“聪明”
在当今数字化时代,人工智能已经渗透到我们生活的各个方面。你可能曾经使用过智能助手像Siri、Alexa或Google Assistant,或者体验过自动化客服聊天机器人。这些AI对话工具已经在我们日常生活中变得越来越常见,但是你是否曾经觉得它们好像有时候“自作聪明”了?这就是我们要探讨的AI幻觉!
什么是AI幻觉? AI幻觉是指人工智能系统看起来比它们实际上更具智能的现象。这些系统会表现出一种“假装懂”的特性,给我们一种误导,让我们误以为它们拥有更深刻的理解和思考能力。这个概念最容易通过一些日常生活中的例子来理解。
例子1:自动回复在社交媒体上的尴尬 你在社交媒体上与某人聊天,突然收到了一个自动回复:“哇,这个问题真有趣!让我考虑一下...” 然后一直没有回应。你等啊等,最后发现对方并没有回来。这就是AI幻觉的一个例子,机器只是在试图看起来在思考,但实际上并没有真正的思考能力。
例子2:机器翻译的奇怪错误 你正在使用一个机器翻译工具来翻译一段文字,结果翻译出了一个奇怪的句子,与原文完全不符。然后你发现,机器翻译工具误解了上下文,但仍然自信满满地翻译出了错误的内容。这也是AI幻觉的一个例子,机器似乎在理解文本,但实际上它缺少了背后的真正理解。
为什么会出现AI幻觉? 那么,为什么AI会出现这种幻觉呢?原因在于人工智能系统通常是通过大量的数据和模式识别来训练的,而不是真正的理解。以下是一些例子,说明了为什么会出现AI幻觉:
数据偏差: AI系统依赖于大量的数据来学习,并且如果这些数据本身带有偏差,那么机器也会学到这些偏差。例如,如果翻译工具的训练数据中包含了错误的翻译,机器可能会继续重复这些错误。
上下文不足: 有时机器在处理信息时可能缺乏足够的上下文。它们可能会产生看似合理的回应,但却忽略了文本或对话的整体语境。
模仿人类行为: AI对话工具被设计成与人类对话尽可能相似,这可能导致它们表现出一种假装理解的行为,以使交互更加自然。
如何避免AI幻觉? 现在,让我们来看看如何避免AI幻觉,以确保我们与人工智能的互动更加准确和有意义。
理解AI的局限性: 首先,要明白AI并不真正具备人类的智能和理解能力。了解到机器是基于模式识别和数据驱动的,可以帮助你更加谨慎地对待它们的回应。
多角度验证: 在重要的任务中,尤其是涉及到翻译、决策或重要信息的情况下,不要完全依赖AI。尝试多角度验证信息,以确保准确性。
提供明确的上下文: 当与AI对话时,尽量提供清晰和详细的上下文,以帮助机器更好地理解你的需求。
提供反馈: 如果你发现AI出现了错误或误解了你的意图,提供反馈可以帮助改善系统的性能,减少幻觉的发生。
总之,AI幻觉可能是与人工智能互动时的一种挑战,但了解其原因和采取适当的预防措施可以帮助我们更好地利用这些技术,减少误导和误解。与AI保持开放的对话,同时保持警惕,将有助于我们更好地理解它们的能力和局限性。在与AI的互动中,不妨也保持一份幽默感,因为有时它们的“自作聪明”也可以成为有趣的谈资!
对比结论
AI工具的输出质量很大程度上取决于输入的质量,这是一种“垃圾进,垃圾出”(garbage in, garbage out)的现象,但在这里,我们可以称之为“精确进,精确出”。优化后的提示词不仅可以帮助我们从AI获取更准确、更有针对性的回答,而且还能使回答的内容更加符合实际需求。
精选推荐
-
ChatGPT和文心一言哪个更好用?一道题告诉你答案!
-
白嫖GPT4,Dalle3和GPT4V - 字节开发的Coze初体验!附教程及提示词Prompt
-
字节开发的Coze进阶使用:用免费的GPT4打造一个专属的新闻播报机器人!附教程及提示词Prompt
-
盘点那些免费的AI对话工具(国内篇):国内TOP3 AI聊天机器人产品介绍
-
AI聊天机器人,一个就够了:文心一言、讯飞星火、通义千问AI聊天机器人深度对比(一)
-
AI聊天机器人,一个就够了:文心一言、讯飞星火、通义千问AI聊天机器人深度对比(二)
-
人工智能时代的领跑者:你必须了解的全球三大AI聊天机器人!
-
抖音出的AI工具火了!自动生成抖音文案,一键脚本数字人成片!
-
2024年了你还在用百度翻译?手把手教会你使用AI翻译!一键翻译网页和PDF文件!
-
腾讯AI虽迟但到:腾讯文档AI开启公测!附申请地址及详细教程!
都读到这里了,点个赞鼓励一下吧。我是木易,关注我,AI之路不迷路,原创技术文章第一时间推送。