sheng的学习笔记-网络爬虫scrapy框架
基础知识:
scrapy介绍
何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分,请求、响应、解析、存储,scrapy框架都已经搭建好了。scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架,scrapy使用了一种非阻塞的代码实现并发的
整体架构图

各组件:
数据处理流程
项目示例
环境搭建
下载依赖包
pip install wheel
下载twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
安装twisted:pip install Twisted-17.1.0-cp36m-win_amd64.whl (这个文件的路劲)
pip install pywin32
pip install scrapy
测试:在终端输入scrapy指令,没有报错表示安装成功
在anaconda中,可以直接装scrapy,会自动把依赖的包都装好pyopenssl要改成22.0.0版本,否则调用request的时候报错,anaconda会自动改一下依赖的别的包的版本
创建项目
创建项目叫spider
1、打开pycharm的terminal
2、scrapy startproject spider 创建项目
3、cd spider
4、scrapy genspider douban www.xxx.com 创建爬虫程序
5、需要有main.py里面的输出,则修改settings.py里面的ROBOTSTXT_OBEY = True改为False
6、scrapy crawl main
不需要额外的输出则执行scrapy crawl main --nolog
或者在settings.py里面添加LOG_LEVEL='ERROR',main.py有错误代码会报错(不添加有错误时则不会报错)(常用)
打开spider项目,里面有个spiders文件夹,称为爬虫文件夹,在这里放爬虫业务文件

项目代码
在douban.py里,写爬虫程序
此处是爬虫业务逻辑,爬到网站地址,对于爬虫返回结果的解析,在parse中做
根据应答的数据,解析,可以用xpath或者css解析,找到对应的数据
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponse
from spider.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def start_requests(self):
for page in range(10):
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response: HtmlResponse, **kwargs):
sel = Selector(response)
list_items = sel.css("#content > div > div.article > ol > li")
for list_item in list_items:
movie_item = MovieItem()
movie_item['title'] = list_item.css('span.title::text').extract_first()
movie_item['rank'] = list_item.css('span.rating_num::text').extract_first()
movie_item['subject'] = list_item.css('span.inq::text').extract_first()
yield movie_item
# href_list = sel.css('div.paginator > a::attr(href)')
# for href in href_list:
# url = response.urljoin(href.extract())
其中,将返回的值转化为对象,需要在item.py里改一下代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
#爬虫获取到到数据需要组装成item对象
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
rank = scrapy.Field()
subject = scrapy.Field()
执行爬虫
执行工程:scrapy crawl douban -o douban.csv (运行douban爬虫文件,并将结果生成到douban.csv里面)
如果被识别了是爬虫程序,在setting中设置一下user agent的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36' # User-Agent字符串
保存数据
默认可以支持保存到csv,json
保存到excel
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import openpyxl
#将爬虫返回的数据持久化,先存放到excel
class ExcelPipeline:
# 创建excel工作簿和工作表
def __init__(self):
self.wb = openpyxl.Workbook()
# wb.create_sheet()
self.ws = self.wb.active #激活工作表
self.ws.title = "Top250" #改名字
self.ws.append(('标题','评分','主题'))
def close_spider(self,spider):
self.wb.save('电影数据.xlsx')
# item就是数据
def process_item(self, item, spider):
title = item.get('title','')
rank = item.get('rank', '')
subject = item.get('subject', '')
self.ws.append((title,rank,subject))
return item
在setting.py中改一下配置,找到这个注释,去掉注释
前面是管道名称,如果多个管道,在这里配置多个值,数字小的先执行,数字大的后执行
值要和类名字一致,我改了名字
ITEM_PIPELINES = {
'spider.pipelines.ExcelPipeline': 300,
}

运行命令。 scrapy crawl douban
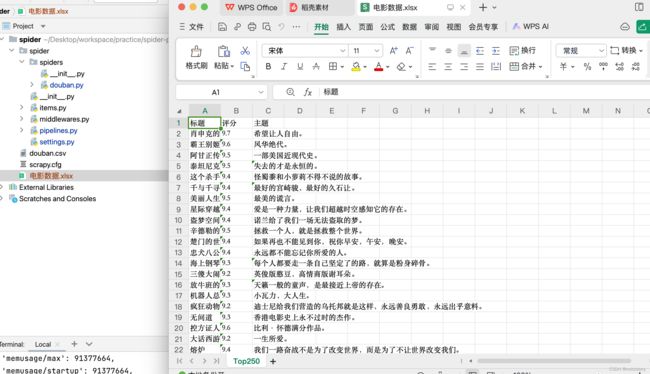
保存到数据库mysql
新增一个mysql的持久化逻辑,init的时候创建连接,process的时候插入,close的时候提交和关闭连接
建表语句
create table tb_top_move(
movie_id INT AUTO_INCREMENT PRIMARY KEY comment '编号',
title varchar(50) not null comment '标题',
rating decimal(3,1) not null comment '评分',
subject varchar(200) not null comment '主题'
) engine=innodb comment='Top电影表'# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import openpyxl
import pymysql
#将爬虫返回的数据持久化,先存放到mysql
class MysqlPipeline:
# 创建excel工作簿和工作表
def __init__(self):
#todo 设置db信息
self.conn = pymysql.connect(host='127.0.0.1',port=,user='',password='',database='',charset='utf8mb4')
self.cursor = self.conn.cursor()
def close_spider(self,spider):
self.conn.commit()
self.conn.close()
# item就是数据
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', 0)
subject = item.get('subject', '')
self.cursor.execute('insert into tb_top_move(title,rating,subject) values (%s,%s,%s)',
(title,rank,subject))
return item
#将爬虫返回的数据持久化,先存放到excel
class ExcelPipeline:
# 创建excel工作簿和工作表
def __init__(self):
self.wb = openpyxl.Workbook()
# wb.create_sheet()
self.ws = self.wb.active #激活工作表
self.ws.title = "Top250" #改名字
self.ws.append(('标题','评分','主题'))
def close_spider(self,spider):
self.wb.save('电影数据.xlsx')
# item就是数据
def process_item(self, item, spider):
title = item.get('title','')
rank = item.get('rank', '')
subject = item.get('subject', '')
self.ws.append((title,rank,subject))
return item
改下setting的配置
ITEM_PIPELINES = {
'spider.pipelines.MysqlPipeline': 200,
'spider.pipelines.ExcelPipeline': 300,
}
如果需要代理,可以用这种方式,在douban的py中修改
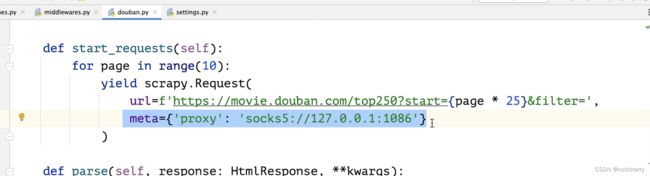
运行爬虫
scrapy crawl douban
多层爬虫
在爬了第一个页面,跟进内容爬第二个页面,比如在第一个汇总页面,想要知道《霸王别姬》中的时长和介绍,要点进去看到第二个页面
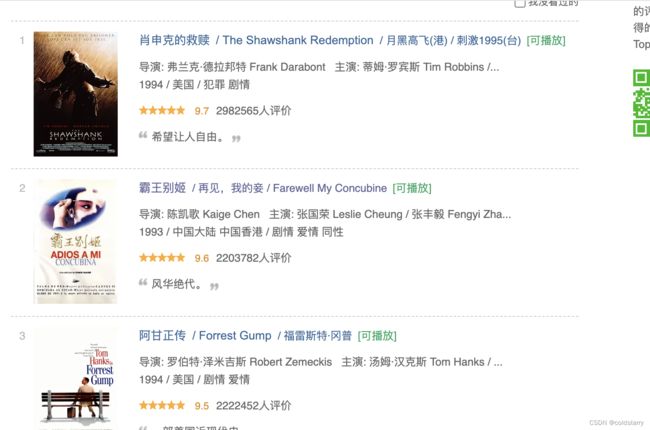
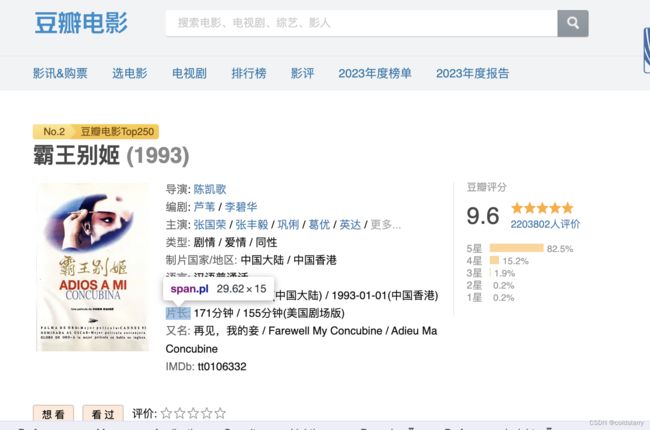
核心是douban.py中,parse函数yield返回的,是一个新的请求,并通过parse_detail作为回调函数进行第二层页面的解析
代码:
douban.py
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponse
from spider.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def start_requests(self):
for page in range(1):
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response: HtmlResponse, **kwargs):
sel = Selector(response)
list_items = sel.css("#content > div > div.article > ol > li")
for list_item in list_items:
detail_url = list_item.css("div.info > div.hd > a::attr(href)").extract_first()
movie_item = MovieItem()
movie_item['title'] = list_item.css('span.title::text').extract_first()
movie_item['rank'] = list_item.css('span.rating_num::text').extract_first()
movie_item['subject'] = list_item.css('span.inq::text').extract_first() or ''
# yield movie_item
yield Request(url=detail_url, callback=self.parse_detail,
cb_kwargs={'item':movie_item}
)
# href_list = sel.css('div.paginator > a::attr(href)')
# for href in href_list:
# url = response.urljoin(href.extract())
def parse_detail(self,response,**kwargs):
movie_item = kwargs['item']
sel = Selector(response)
movie_item['duration']=sel.css('span[property="v:runtime"]::attr(content)').extract()
movie_item['intro']=sel.css('span[property="v:summary"]::text').extract_first() or ''
yield movie_item/items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
#爬虫获取到到数据需要组装成item对象
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
rank = scrapy.Field()
subject = scrapy.Field()
duration = scrapy.Field()
intro = scrapy.Field()
/pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import openpyxl
import pymysql
'''
建表语句
create table tb_top_move(
movie_id INT AUTO_INCREMENT PRIMARY KEY comment '编号',
title varchar(50) not null comment '标题',
rating decimal(3,1) not null comment '评分',
subject varchar(200) not null comment '主题',
duration int comment '时长',
intro varchar(10000) comment '介绍'
) engine=innodb comment='Top电影表'
'''
#将爬虫返回的数据持久化,先存放到excel
class MysqlPipeline:
# 创建excel工作簿和工作表
def __init__(self):
#todo 设置db信息
self.conn = pymysql.connect(host='127.0.0.1',port=3306,
user='lzs_mysql',password='lzs',database='mysql',charset='utf8mb4')
self.cursor = self.conn.cursor()
def close_spider(self,spider):
self.conn.commit()
self.conn.close()
# item就是数据
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', 0)
subject = item.get('subject', '')
duration = item.get('duration', '')
intro = item.get('intro', '')
self.cursor.execute('insert into tb_top_move(title,rating,subject,duration,intro) values (%s,%s,%s,%s,%s)',
(title,rank,subject,duration,intro))
return item
#将爬虫返回的数据持久化,先存放到excel
class ExcelPipeline:
# 创建excel工作簿和工作表
def __init__(self):
self.wb = openpyxl.Workbook()
# wb.create_sheet()
self.ws = self.wb.active #激活工作表
self.ws.title = "Top250" #改名字
self.ws.append(('标题','评分','主题'))
def close_spider(self,spider):
self.wb.save('电影数据.xlsx')
# item就是数据
def process_item(self, item, spider):
title = item.get('title','')
rank = item.get('rank', '')
subject = item.get('subject', '')
self.ws.append((title,rank,subject))
return item
运行爬虫
scrapy crawl douban
中间件
中间件分为蜘蛛中间件和下载中间件
蜘蛛中间件一般不动
如果想要在请求中加上cookie,可以在中间件上的请求加上cookie信息
在middlewares.py类中,加上一个方法,获取cookie信息
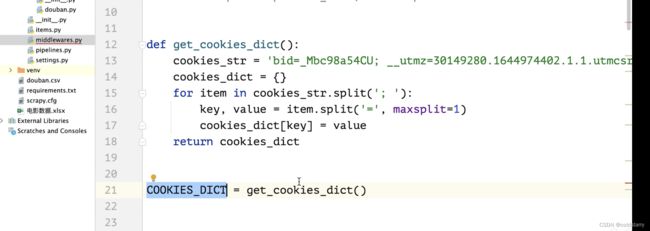
修改middle的类
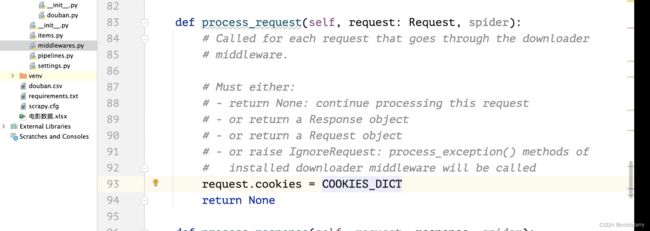
修改配置setting

参考文章:
02.使用Scrapy框架-1-创建项目_哔哩哔哩_bilibili
https://www.cnblogs.com/12345huangchun/p/10501673.html
Scrapy框架(高效爬虫)_scrapy爬虫框架-CSDN博客