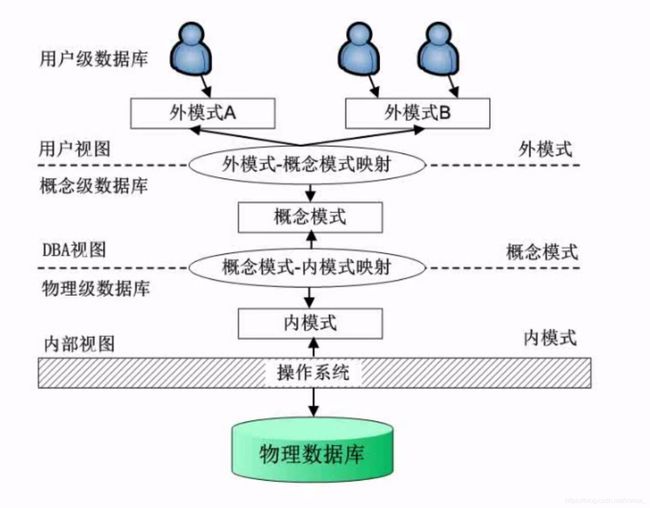
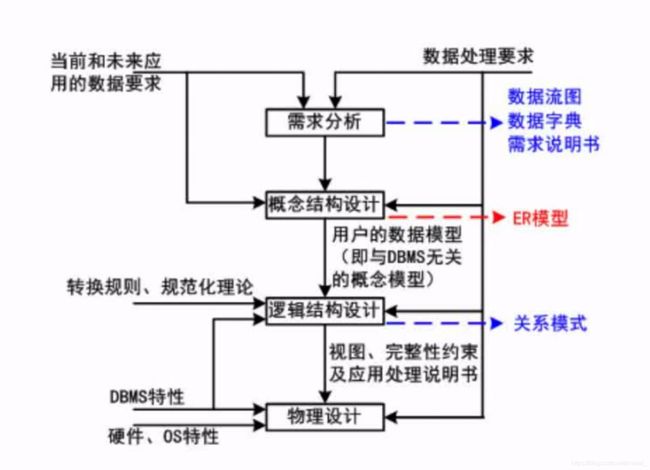
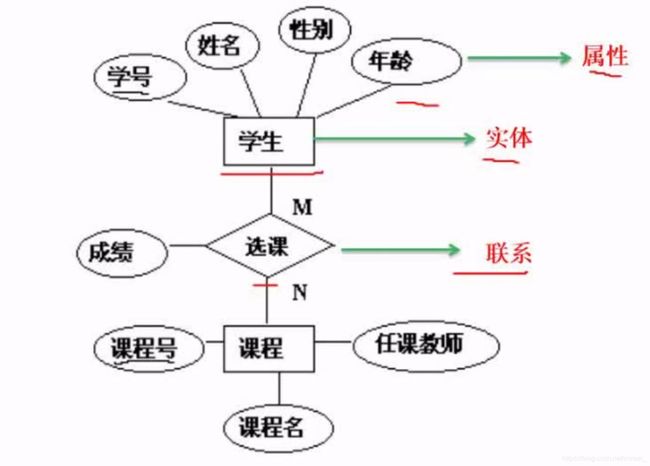
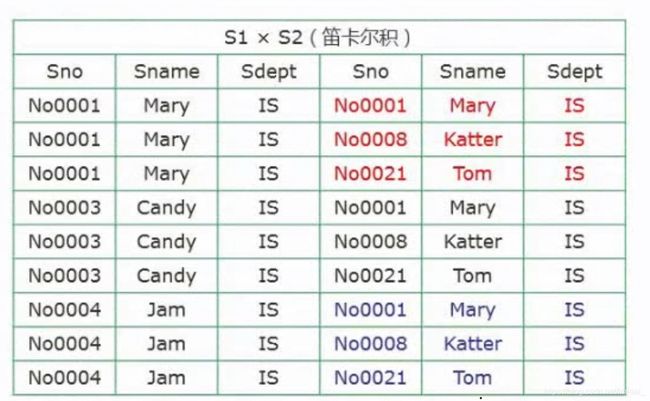
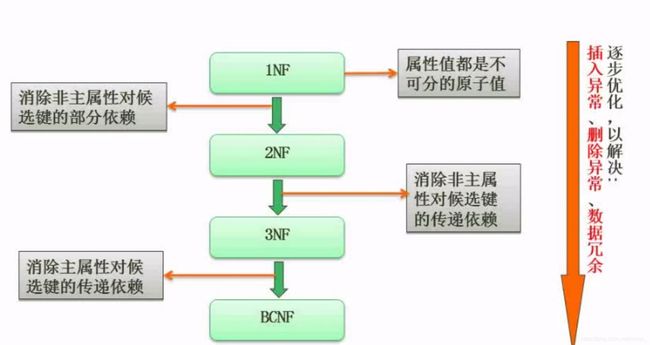
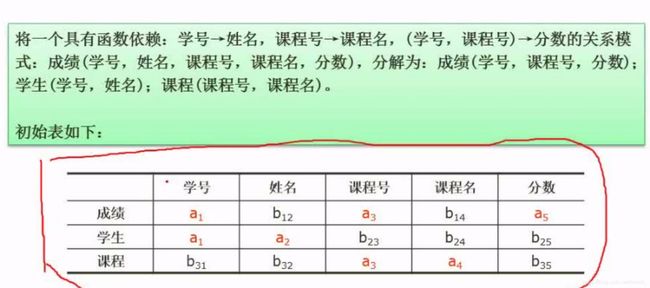
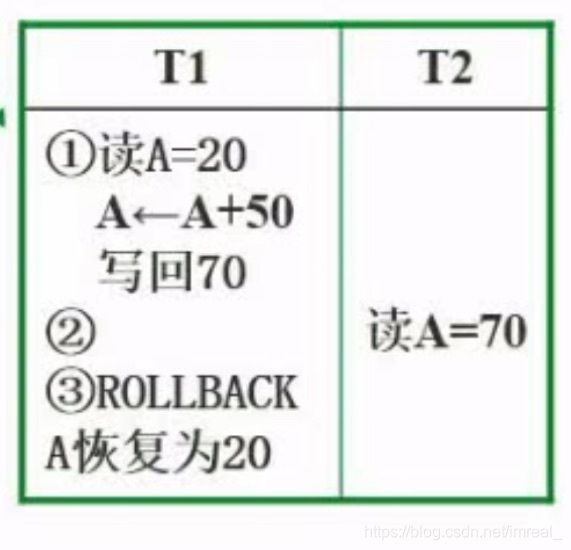
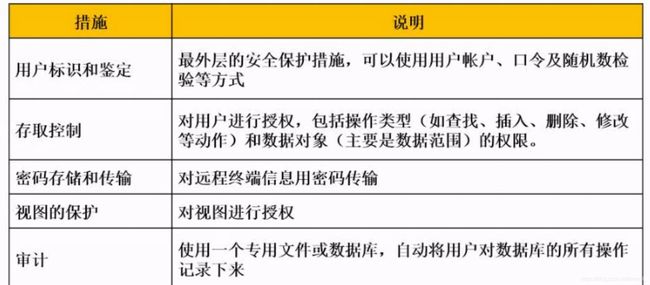
- 使用Python Selenium抓取表单数据:从数据提取到自动化处理的完整指南
Python爬虫项目
2025年爬虫实战项目pythonselenium自动化爬虫开发语言phpmicrosoft
目录:前言爬虫基础知识什么是爬虫爬虫的工作原理Selenium简介什么是SeleniumSelenium的工作原理表单数据抓取概述什么是表单数据常见的表单类型表单抓取的实际应用场景爬虫技术栈requestsvsSeleniumSelenium的安装与配置使用Selenium抓取表单数据的步骤启动浏览器并访问目标页面查找表单元素提交表单并抓取返回的数据数据存储与处理存储抓取的数据:CSV、数据库等数
- 计算机毕业设计ssm基于Web的医院陪诊系统的设计与实现go8299(附源码)新手必备
一念 计算机毕设源码程序
课程设计前端
本项目包含程序+源码+数据库+LW+调试部署环境,文末可获取一份本项目的java源码和数据库参考。系统的选题背景和意义选题背景:随着社会的发展和人们生活水平的提高,医疗服务的需求也越来越多样化。在传统的医院就诊过程中,患者通常需要自行前往医院,并且由于医生工作繁忙,陪诊时间有限,导致患者在就诊过程中感到孤独和不安。而基于Web的医院陪诊系统的设计与实现,可以为患者提供更加便捷和贴心的就医体验。意义
- Spring Boot 整合 MySQL 和 Druid 连接池
疯狂的键盘侠
springbootmysqlspringbootmysqldruid
SpringBoot整合MySQL和Druid连接池一、引言在JavaWeb开发中,SpringBoot凭借其简洁的配置和强大的功能成为主流框架,而MySQL作为常用的关系型数据库,与SpringBoot的结合十分紧密。Druid是阿里巴巴开源的一款高性能数据库连接池,它提供了丰富的监控和扩展功能,能有效提升应用程序与数据库交互的性能和稳定性。本文将详细介绍如何在SpringBoot2和Sprin
- DataGrip的数据库驱动的离线安装
一口酥Hac
数据库数据库
文章目录概要离线安装数据库驱动本地云桌面注意概要在某些工作环境中,由于网络访问受限,可能无法自动下载所需的数据库驱动。离线安装数据库驱动本地本地的DataGrip打开File->DataSources:云桌面云桌面的DataGrip打开File->DataSources:注意请确保下载的驱动版本与您所使用的数据库版本完全兼容,以避免出现连接或功能异常。
- Oracle PL/SQL 编程入门:第八章 异常
caifox菜狐狸
OraclePL/SQL编程入门oraclesql数据库异常异常范围自定义异常Exceptions
欢迎来到OraclePL/SQL编程入门的第八章!在这一章中,我们将深入探讨PL/SQL中的异常处理机制。通过学习如何定义和使用自定义异常、内置异常以及异常链,你将能够编写更加健壮和可靠的程序。此外,我们还会介绍一些注意事项,并通过实际例子展示它们的用法。准备好迎接新的挑战了吗?让我们开始吧!第一节:异常范围异常处理是编程中的重要组成部分,它允许你在运行时捕获并处理错误,从而避免程序崩溃。PL/S
- 知识图谱自动构建工具有哪些
Nate Hillick
知识图谱neo4j人工智能
知识图谱的自动构建工具有很多,常见的包括:Neo4j:基于图数据库的知识图谱构建工具Protégé:开源的知识图谱开发平台GoogleKnowledgeGraph:Google搜索引擎的知识图谱构建工具TopBraidComposer:基于SemanticWeb技术的知识图谱构建工具AllegroGraph:高性能图数据库,可用于构建知识图谱这仅仅是其中一部分工具,在市场上还有更多类似的工具。
- 【性能调优】高性能实践
Forest 森林
性能调优性能优化
缓存思想性能优化,缓存为王,所以开始先介绍一下缓存。缓存在我们的架构设计中无处不在,常规请求是浏览器发起请求,请求服务端服务,服务端服务再查询数据库中的数据,每次读取数据都至少需要两次网络I/O,性能会差一些,我们可以在整个流程中增加缓存来提升性能。异步化处理例如Redis的bgsave,bgrewriteof就是分别用来异步保存RDB跟AOF文件的命令,bgsave执行后会立刻返回成功,主线程f
- 高效向量搜索RAG解决方案(Canopy)
deepdata_cn
RAGRAG
Canopy利用Pinecone在高效向量搜索方面的专业知识,提供强大且可扩展的RAG(Retrieval-AugmentedGeneration)解决方案。包括与Pinecone向量数据库的紧密集成,支持流处理和实时更新,先进的查询处理和重新排序功能,以及管理知识库和版本控制的工具。一、基本原理1.向量嵌入:Canopy首先会将文本数据转换为向量表示,通常使用预训练的语言模型等技术,将文本映射到
- MyBatis-Plus 逆向工程原理及使用指南
吴冰_hogan
mybatisoracletomcat
概述MyBatis-Plus(简称MP)是MyBatis的增强工具,它简化了开发人员对数据库的操作,并提供了代码生成器、分页插件等功能。其中的代码生成器(即逆向工程),能够根据数据库中的表结构自动生成实体类(Entity)、Mapper接口、Service层及Controller层的基础代码,从而极大地减少了开发初期的手动编码工作量。逆向工程原理数据库元数据读取:MyBatis-Plus使用JDB
- mysql冷热备份方案_MySQL双机热备份实施方案
析木分野
mysql冷热备份方案
MySQL双机热备份实施方案1、MySQL数据库没有增量备份的机制,当数据量太大的时候备份是一个很大的问题。还好MySQL数据库提供了一种主从备份的机制,其实就是把主数据库的所有的数据同时写到备份数据库中。实现MySQL数据库的热备份。2、要想实现双机的热备首先要了解主从数据库服务器的版本的需求。要实现热备MySQL的版本都要高于3.2,还有一个基本的原则就是作为从数据库的数据库版本可以高于主服务
- 热备份和冷备份
K. Bob
MySQL
目录冷备份热备份双机热备的实现模式冷备份 冷备份发生在数据库已经正常关闭的情况下,当正常关闭时会提供一个完整的数据库。冷备份是将关键性文件拷贝到另外位置的一种说法。对于备份数据库信息而言,冷备份是最快和最安全的方法。冷备份的优点:1.是非常快速的备份方法(只需拷贝文件)2.容易归档(简单拷贝即可)3.容易恢复到某个时间点上(只需将文件再拷贝回去)4.能与归档方法相结合,作数据库“最新状态”的恢复
- Java学习day002 Java程序设计环境(下载安装JDK、使用命令行工具、使用集成开发环境、运行图形化应用程序)
Z zehao
Java基础学习java后端
使用的教材是java核心技术卷1,我将跟着这本书的章节同时配合视频资源来进行学习基础java知识。day002Java程序设计环境(下载安装JDK、使用命令行工具、使用集成开发环境、运行图形化应用程序)第一部分安装java开发工具包下载JDK要想下载Java开发工具包,可以访问Oracle网站:www.oracle.com/technetwork/java/javase/downloads,在得到
- 【面试题】构建高并发、高可用服务架构:技术选型与设计
言之。
redispython面试架构
监控系统消息队列缓存层数据存储层应用层Web层负载均衡与流量分配GrafanaPrometheusAlertmanager消息队列Kafka/RabbitMQ集群/镜像队列缓存层Redis/Memcached数据库MySQL/PostgreSQL主从复制/主主复制应用服务器SpringBoot/Node.js应用服务器SpringBoot/Node.js应用服务器SpringBoot/Node.j
- 基于Python的多元医疗知识图谱构建与应用研究(下)
Allen_LVyingbo
医疗高效编程研发pythonpython知识图谱健康医疗
五、基于医疗知识图谱的医疗知识图谱程序构建5.1数据层构建5.1.1数据源选择与获取在构建基于医疗知识图谱的医疗知识图谱数据层时,数据源的选择与获取至关重要。数据源的质量和丰富度直接决定了知识图谱的可靠性和实用性。医学文献是重要的数据源之一,包括学术期刊论文、医学研究报告等。这些文献包含了大量经过科学验证的医学知识,如疾病的发病机制、诊断标准、治疗方法等。可以通过专业的医学文献数据库,如PubMe
- 使用 @NoRepositoryBean 简化数据库访问
java后端
在SpringDataJPA应用程序中管理跨多个存储库接口的数据库访问逻辑可能会变得乏味且容易出错。开发人员经常发现自己为常见查询和方法重复代码,从而导致维护挑战和代码冗余。幸运的是,SpringDataJPA为这个问题提供了一个强大的解决方案:@NoRepositoryBean注解。在本文中,我们将探讨@NoRepositoryBean如何允许我们在超级接口中定义通用查询和方法,然后可以由所有基
- 将jar包导入maven
null or notnull
pycharmidepython
1.将jar包放repository2.执行命令:mvninstall:install-file-DgroupId=com.oracle-DartifactId=ojdbc7-Dversion=12.1.0.2-Dpackaging=jar-Dfile=D:\dev\utils\idea\repository\ojdbc7.jar-Dfile:指定要安装的JAR文件的路径。-DgroupId:指定
- Go语言web快速开发框架Gin如何进行数据的增删查改呢?
网友阿贵
Go语言golanggin后端intellij-ideavscode
在Go语言中使用Gin框架进行Web开发时,你可以轻松地结合database/sql接口和具体的数据库驱动(如MySQL的go-sql-driver/mysql)来执行数据的增删查改(CRUD)操作。下面通过几个简单的例子展示如何使用Gin和MySQL进行基本的数据操作。1.安装依赖确保你已经安装了必要的依赖:goget-ugithub.com/gin-gonic/gingoget-ugithub
- C#开发人员学习书籍推荐
Lu01
.net学习python
作为一名C#开发人员,持续学习和提升自己的技术水平是至关重要的。如今,技术不断更新换代,新的开发框架、语言和工具层出不穷。对于刚入行的开发者或希望深入某一领域的工程师来说,选对书籍是学习的捷径之一。本篇文章将推荐一些经典的书籍,涵盖了C#、数据库、前端开发等多个领域,帮助你在开发的道路上不断进步。1.学习SQL基础推荐书籍:《SQL必知必会(第5版)》作者:[美]本·福达(BenForta)译者:
- mysql开放远程连接
大叔是90后大叔
Mysql服务器mysql数据库
mysql开放远程连接mysql开放远程连接方法一:方法二(推荐):mysql开放远程连接新安装的mysql只可以本机连接,但是远程连接就会报notallowedtoconnecttothisMySQLserver例如:按如下步骤进行操作方法一:更改mysql数据库user表的host列,把localhost改为%[root@localhost~]#mysql-uroot-p123***mysql
- 1Panel服务器运维管理面板
安星辰
综合web运维服务器
1Panel是一个现代化、开源的Linux服务器运维管理面板,类似于宝塔1产品优势¶快速建站:深度集成Wordpress和Halo,域名绑定、SSL证书配置等一键搞定;高效管理:通过Web端轻松管理Linux服务器,包括应用管理、主机监控、文件管理、数据库管理、容器管理等;安全可靠:最小漏洞暴露面,提供防火墙和安全审计等功能;一键备份:支持一键备份和恢复,备份数据云端存储,永不丢失。在线安装:1环
- AI Agent(智能体)技术白皮书(Google,2024)
花生糖@
AIGC学习资料库人工智能AIAgent智能体AI实战
1引言1.1人类的先验知识与工具的使用人类很很好地处理复杂和微妙的模式识别任务。能做到这一点是因为,我们会通过书籍、搜索或计算器之类的工具来补充我们头脑中的先验知识,然后才会给出一个结论(例如,“图片中描述的是XX”)。1.2人类的模仿者与以上类似,我们可以对生成式AI模型进行训练,让它们能使用工具来在现实世界中获取实时信息或给出行动建议。例如,利用数据库查询工具获取客户的购物历史,然后给出购物建
- JavaWeb——MySQL-多表设计(3/5):(一对一关系,多对多关系,小结)
qiyi.sky
JavaWebmysql数据库笔记学习java
目录一对一关系剖析一对一关系场景与特点数据库实现方式图形化工具演示与验证多对多关系解析多对多关系实例与困境中间表解决方案工具演示与理解深化多表关系核心要点回顾一对一关系剖析一对一关系场景与特点以用户与身份证为例,呈现一对一典型场景。在业务系统中,为优化数据操作效率,常拆分含多种信息的大表。如用户表含基本与身份信息,若基本信息查询频繁、身份信息查询低频,可拆为用户基本信息表(含用户ID、姓名、性别等
- centos安装1Panel管理面板
l1677516854
系统搭建centoslinux运维
简介1Panel是一个现代化、开源的Linux服务器运维管理面板。高效管理:用户可以通过Web图形界面轻松管理Linux服务器,实现主机监控、文件管理、数据库管理、容器管理等功能;快速建站:深度集成开源建站软件WordPress和Halo,域名绑定、SSL证书配置等操作一键搞定;应用商店:精选上架各类高质量的开源工具和应用软件,协助用户轻松安装并升级;安全可靠:基于容器管理并部署应用,实现最小的漏
- K8S中数据存储之配置存储
元气满满的热码式
kubernetes容器云原生
配置存储在Kubernetes中,ConfigMap和Secret是两种核心资源,用于存储和管理应用程序的配置数据和敏感信息。理解它们的功能和最佳实践对于提高Kubernetes应用程序的安全性和配置管理的效率至关重要。ConfigMapConfigMap是一种API对象,允许你存储非敏感配置数据,如环境变量、数据库URL等。它以键值对的形式存储数据,便于应用程序访问必要的配置。ConfigMap
- Redis的优缺点
zhanghaiyang0011
redisredis
优点:速度快,完全基于内存,使用C语言实现丰富的数据类型,Redis有8种数据类型,当然常用的主要是String、Hash、List、Set、SortSet这5种类型支持事务,Redis的所有操作都是原子性的支持主从复制可以进行读写分离缺点:由于Redis是内存数据库,短时间内大量增加数据,可能导致内存不够用数据库容量受到物理内存的限制,不能用作海量数据的高性能读写Redis较难支持在线扩容red
- Redis的单线程架构
ら.二十一
Redis
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务。这里通过多个客户端命令调用的例子说明Redis单线程命令处理机制,接着分析Redis单线程模型为什么性能如此之高,最终给出为什么理解单线程模型是使用和运维Redis的关键。开启三个redis-cli客户端同时执行命令客户端1设置一个字符串键值对:127.0.0.1:6379>sethelloworld客户端2对counte
- (2025 年最新)MacOS Redis Desktop Manager中文版下载,附详细图文
itbysj
macosredis数据库RedisDesktop
MacOSRedisDesktopManager中文版下载大家好,今天给大家带来一款非常实用的Redis可视化工具——RedisDesktopManager(简称RDM)。相信很多开发者都用过Redis数据库,但如果你想要更高效、更方便地管理Redis数据,RDM无疑是个不错的选择!特别是Mac版本,不仅界面简洁,功能也非常强大,支持多种高效连接方式,简直是Redis用户的必备神器!什么是Redi
- Java 个版本解决控制台中文乱码
杨过姑父
java开发语言
我新建了一个SpingBoot3.3.0的项目,SDK设置为OracleOpenJDK21.0.2,并在main方法中写了一个简单的System.out.println(“你好,世界”),运行后得到一串乱码。按照JDK8的经验,我检查了IDEA的相关配置:1.File->Settings有关encoding的选项已经是UTF-82.Help->EditCustomVMOptions中已经添加了-D
- JAVA 安装教程
连云港大帅哥
java基础javajdk安装配置环境变量
下载官网地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html,选择1.8版本jdk进行下载安装JDK直接运行exe可执行程序,默认安装即可;备注:路径可以自己定义,不建议路径包含中文名、特殊符号、空格。配置环境变量1)新建变量名:JAVA_HOME,变量值:D:\Java8(JDK安装路径);2)打开PATH,添
- 使用 EFCore 去连接 mysql 数据库的时候提示下面的报错信息
黄同学real
C#后端开发.net数据库mysql.netcorec#.net
使用EFCore去连接mysql数据库的时候,提示下面的报错信息:“Anexceptionhasbeenraisedthatislikelyduetoatransientfailure.Considerenablingtransienterrorresiliencybyadding‘EnableRetryOnFailure()’tothe‘UseMySql’call.”的解决方案。解决方案:这一般
- ztree设置禁用节点
3213213333332132
JavaScriptztreejsonsetDisabledNodeAjax
ztree设置禁用节点的时候注意,当使用ajax后台请求数据,必须要设置为同步获取数据,否者会获取不到节点对象,导致设置禁用没有效果。
$(function(){
showTree();
setDisabledNode();
});
- JVM patch by Taobao
bookjovi
javaHotSpot
在网上无意中看到淘宝提交的hotspot patch,共四个,有意思,记录一下。
7050685:jsdbproc64.sh has a typo in the package name
7058036:FieldsAllocationStyle=2 does not work in 32-bit VM
7060619:C1 should respect inline and
- 将session存储到数据库中
dcj3sjt126com
sqlPHPsession
CREATE TABLE sessions (
id CHAR(32) NOT NULL,
data TEXT,
last_accessed TIMESTAMP NOT NULL,
PRIMARY KEY (id)
);
<?php
/**
* Created by PhpStorm.
* User: michaeldu
* Date
- Vector
171815164
vector
public Vector<CartProduct> delCart(Vector<CartProduct> cart, String id) {
for (int i = 0; i < cart.size(); i++) {
if (cart.get(i).getId().equals(id)) {
cart.remove(i);
- 各连接池配置参数比较
g21121
连接池
排版真心费劲,大家凑合看下吧,见谅~
Druid
DBCP
C3P0
Proxool
数据库用户名称 Username Username User
数据库密码 Password Password Password
驱动名
- [简单]mybatis insert语句添加动态字段
53873039oycg
mybatis
mysql数据库,id自增,配置如下:
<insert id="saveTestTb" useGeneratedKeys="true" keyProperty="id"
parameterType=&
- struts2拦截器配置
云端月影
struts2拦截器
struts2拦截器interceptor的三种配置方法
方法1. 普通配置法
<struts>
<package name="struts2" extends="struts-default">
&
- IE中页面不居中,火狐谷歌等正常
aijuans
IE中页面不居中
问题是首页在火狐、谷歌、所有IE中正常显示,列表页的页面在火狐谷歌中正常,在IE6、7、8中都不中,觉得可能那个地方设置的让IE系列都不认识,仔细查看后发现,列表页中没写HTML模板部分没有添加DTD定义,就是<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3
- String,int,Integer,char 几个类型常见转换
antonyup_2006
htmlsql.net
如何将字串 String 转换成整数 int?
int i = Integer.valueOf(my_str).intValue();
int i=Integer.parseInt(str);
如何将字串 String 转换成Integer ?
Integer integer=Integer.valueOf(str);
如何将整数 int 转换成字串 String ?
1.
- PL/SQL的游标类型
百合不是茶
显示游标(静态游标)隐式游标游标的更新和删除%rowtyperef游标(动态游标)
游标是oracle中的一个结果集,用于存放查询的结果;
PL/SQL中游标的声明;
1,声明游标
2,打开游标(默认是关闭的);
3,提取数据
4,关闭游标
注意的要点:游标必须声明在declare中,使用open打开游标,fetch取游标中的数据,close关闭游标
隐式游标:主要是对DML数据的操作隐
- JUnit4中@AfterClass @BeforeClass @after @before的区别对比
bijian1013
JUnit4单元测试
一.基础知识
JUnit4使用Java5中的注解(annotation),以下是JUnit4常用的几个annotation: @Before:初始化方法 对于每一个测试方法都要执行一次(注意与BeforeClass区别,后者是对于所有方法执行一次)@After:释放资源 对于每一个测试方法都要执行一次(注意与AfterClass区别,后者是对于所有方法执行一次
- 精通Oracle10编程SQL(12)开发包
bijian1013
oracle数据库plsql
/*
*开发包
*包用于逻辑组合相关的PL/SQL类型(例如TABLE类型和RECORD类型)、PL/SQL项(例如游标和游标变量)和PL/SQL子程序(例如过程和函数)
*/
--包用于逻辑组合相关的PL/SQL类型、项和子程序,它由包规范和包体两部分组成
--建立包规范:包规范实际是包与应用程序之间的接口,它用于定义包的公用组件,包括常量、变量、游标、过程和函数等
--在包规
- 【EhCache二】ehcache.xml配置详解
bit1129
ehcache.xml
在ehcache官网上找了多次,终于找到ehcache.xml配置元素和属性的含义说明文档了,这个文档包含在ehcache.xml的注释中!
ehcache.xml : http://ehcache.org/ehcache.xml
ehcache.xsd : http://ehcache.org/ehcache.xsd
ehcache配置文件的根元素是ehcahe
ehcac
- java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderL
白糖_
javaeclipsespringtomcatWeb
今天学习spring+cxf的时候遇到一个问题:在web.xml中配置了spring的上下文监听器:
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
随后启动
- angular.element
boyitech
AngularJSAngularJS APIangular.element
angular.element
描述: 包裹着一部分DOM element或者是HTML字符串,把它作为一个jQuery元素来处理。(类似于jQuery的选择器啦) 如果jQuery被引入了,则angular.element就可以看作是jQuery选择器,选择的对象可以使用jQuery的函数;如果jQuery不可用,angular.e
- java-给定两个已排序序列,找出共同的元素。
bylijinnan
java
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class CommonItemInTwoSortedArray {
/**
* 题目:给定两个已排序序列,找出共同的元素。
* 1.定义两个指针分别指向序列的开始。
* 如果指向的两个元素
- sftp 异常,有遇到的吗?求解
Chen.H
javajcraftauthjschjschexception
com.jcraft.jsch.JSchException: Auth cancel
at com.jcraft.jsch.Session.connect(Session.java:460)
at com.jcraft.jsch.Session.connect(Session.java:154)
at cn.vivame.util.ftp.SftpServerAccess.connec
- [生物智能与人工智能]神经元中的电化学结构代表什么?
comsci
人工智能
我这里做一个大胆的猜想,生物神经网络中的神经元中包含着一些化学和类似电路的结构,这些结构通常用来扮演类似我们在拓扑分析系统中的节点嵌入方程一样,使得我们的神经网络产生智能判断的能力,而这些嵌入到节点中的方程同时也扮演着"经验"的角色....
我们可以尝试一下...在某些神经
- 通过LAC和CID获取经纬度信息
dai_lm
laccid
方法1:
用浏览器打开http://www.minigps.net/cellsearch.html,然后输入lac和cid信息(mcc和mnc可以填0),如果数据正确就可以获得相应的经纬度
方法2:
发送HTTP请求到http://www.open-electronics.org/celltrack/cell.php?hex=0&lac=<lac>&cid=&
- JAVA的困难分析
datamachine
java
前段时间转了一篇SQL的文章(http://datamachine.iteye.com/blog/1971896),文章不复杂,但思想深刻,就顺便思考了一下java的不足,当砖头丢出来,希望引点和田玉。
-----------------------------------------------------------------------------------------
- 小学5年级英语单词背诵第二课
dcj3sjt126com
englishword
money 钱
paper 纸
speak 讲,说
tell 告诉
remember 记得,想起
knock 敲,击,打
question 问题
number 数字,号码
learn 学会,学习
street 街道
carry 搬运,携带
send 发送,邮寄,发射
must 必须
light 灯,光线,轻的
front
- linux下面没有tree命令
dcj3sjt126com
linux
centos p安装
yum -y install tree
mac os安装
brew install tree
首先来看tree的用法
tree 中文解释:tree
功能说明:以树状图列出目录的内容。
语 法:tree [-aACdDfFgilnNpqstux][-I <范本样式>][-P <范本样式
- Map迭代方式,Map迭代,Map循环
蕃薯耀
Map循环Map迭代Map迭代方式
Map迭代方式,Map迭代,Map循环
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年
- Spring Cache注解+Redis
hanqunfeng
spring
Spring3.1 Cache注解
依赖jar包:
<!-- redis -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
- Guava中针对集合的 filter和过滤功能
jackyrong
filter
在guava库中,自带了过滤器(filter)的功能,可以用来对collection 进行过滤,先看例子:
@Test
public void whenFilterWithIterables_thenFiltered() {
List<String> names = Lists.newArrayList("John"
- 学习编程那点事
lampcy
编程androidPHPhtml5
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
- 架构师之流处理---------bytebuffer的mark,limit和flip
nannan408
ByteBuffer
1.前言。
如题,limit其实就是可以读取的字节长度的意思,flip是清空的意思,mark是标记的意思 。
2.例子.
例子代码:
String str = "helloWorld";
ByteBuffer buff = ByteBuffer.wrap(str.getBytes());
Sy
- org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1, column 1
Everyday都不同
$转义el表达式
最近在做Highcharts的过程中,在写js时,出现了以下异常:
严重: Servlet.service() for servlet jsp threw exception
org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1,
- 用Java实现发送邮件到163
tntxia
java实现
/*
在java版经常看到有人问如何用javamail发送邮件?如何接收邮件?如何访问多个文件夹等。问题零散,而历史的回复早已经淹没在问题的海洋之中。
本人之前所做过一个java项目,其中包含有WebMail功能,当初为用java实现而对javamail摸索了一段时间,总算有点收获。看到论坛中的经常有此方面的问题,因此把我的一些经验帖出来,希望对大家有些帮助。
此篇仅介绍用
- 探索实体类存在的真正意义
java小叶檀
POJO
一. 实体类简述
实体类其实就是俗称的POJO,这种类一般不实现特殊框架下的接口,在程序中仅作为数据容器用来持久化存储数据用的
POJO(Plain Old Java Objects)简单的Java对象
它的一般格式就是
public class A{
private String id;
public Str