使用深度学习进行验证码识别系统搭建(附项目资源)
目录
开发环境
1 项目介绍
2 导入所需库并定义超参数
3 验证码数据生成
4 构建数据管道
5 模型架构设计
6 模型训练及调参
7 模型评估与预测
8 改进策略
9 总结与展望
项目资源
开发环境
作者:嘟粥yyds
时间:2023年7月21日
集成开发工具:PyCharm Professional 2021.1和Google Colab
集成开发环境:Python 3.10.6
第三方库:tensorflow-gpu 2.10.0、numpy、matplotlib、captcha、random、string、os
1 项目介绍
验证码识别是计算机视觉和深度学习领域中的典型问题之一。验证码系统通过生成包含随机字符的图像或音频,用于区分人类用户和机器程序,防止批量自动化请求。然而传统规则和简单机器学习方法难以应对复杂变形的验证码。本项目旨在使用深度学习方法来破解验证码,构建一个端到端的验证码识别模型。
本项目使用Python和TensorFlow/Keras框架,其主要思路是:
- 使用captcha库随机生成含数字及字母的验证码图片,构建训练集、测试集和验证集。
- 应用卷积神经网络进行特征学习,使用预训练网络提升模型泛化能力。采用多任务学习框架,针对每个字符设计不同的分类任务。
- 构建模型输入数据管道,包括图像解码、数据增强、批处理等预处理。
- 训练卷积神经网络模型,使用回调函数实现模型检查点保存及早停等。
- 对测试集进行预测,输出分类结果,并与标签计算准确率。
- 可视化部分验证码结果,直观理解模型识别效果。
通过该项目的学习,可以掌握验证码识别任务的深度学习方法,包括大数据生成、卷积神经网络设计、迁移学习应用以及模型训练和评估方面的经验。这可以为其他验证码识别实际场景提供方法借鉴。
2 导入所需库并定义超参数
import tensorflow as tf
from tensorflow.keras.layers import Dense, GlobalAvgPool2D, Input
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.models import Model
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.callbacks import EarlyStopping, CSVLogger, ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.models import load_model
import numpy as np
import os
from tensorflow.keras.utils import plot_model
from captcha.image import ImageCaptcha
import random
import string
import matplotlib.pyplot as plt# 字符包含所有数字和所有大小写英文字母,一共 62 个
characters = string.digits + string.ascii_letters
# 类别数 62
num_classes = len(characters)
# 批次大小(128大概需要15G显存,若GPU显存不足可适当调小)
batch_size = 128
# 周期数
epochs = 30
# 训练集数据,大约 50000 张图片
train_dir = "./captcha/train/"
# 测试集数据,大约 10000 张图片
test_dir = "./captcha/test/"
# 测试集数据,大约 1000 张图片
val_dir = "./captcha/val/"
# 图片宽度
width = 160
# 图片高度
height = 603 验证码数据生成
为训练验证码识别模型,我们需要准备一个大规模的验证码图片数据集。本项目使用 python 的 captcha 库生成验证码图片。
首先定义所有可能的验证码字符,包含数字0-9和所有大小写字母,一共62个字符。
然后编写生成验证码图片的函数,主要步骤是:
- 随机生成一个4字符的验证码文本,每个字符在定义的字符集中随机取值。
- 使用 ImageCaptcha 库生成对应的验证码图片,宽160高60像素,RGB三通道。
- 保存图片到指定路径,文件名为验证码文本。
对训练集生成50,000张验证码图片,测试集10,000张,验证集1,000张。实际生成的图片可能不足定义的数量,因为重复的验证码会被覆盖。所有图片存放在不同目录下。
这样我们获得一个规模足够的验证码图片数据集,其中图片内容和名称都是随机生成的。这些数据可以用于模型的训练、评估和测试。
def create_directory_with_subdirectories(directory_path):
try:
# 创建主文件夹
os.makedirs(directory_path, exist_ok=True)
print(f"主文件夹captcha '{directory_path}' 创建成功或已存在!")
# 子文件夹1和子文件夹2的路径
subdirectory1_path = os.path.join(directory_path, "train")
subdirectory2_path = os.path.join(directory_path, "test")
subdirectory3_path = os.path.join(directory_path, "val")
# 检查子文件夹是否存在
if not os.path.exists(subdirectory1_path):
os.makedirs(subdirectory1_path)
print(f"子文件夹train '{subdirectory1_path}' 创建成功!")
else:
print(f"子文件夹train '{subdirectory1_path}' 已存在!")
if not os.path.exists(subdirectory2_path):
os.makedirs(subdirectory2_path)
print(f"子文件夹test '{subdirectory2_path}' 创建成功!")
else:
print(f"子文件夹test '{subdirectory2_path}' 已存在!")
if not os.path.exists(subdirectory3_path):
os.makedirs(subdirectory3_path)
print(f"子文件夹val '{subdirectory3_path}' 创建成功!")
else:
print(f"子文件夹val '{subdirectory2_path}' 已存在!")
except OSError as error:
print(f"创建文件夹出错:{error}")
# 调用函数来创建文件夹和子文件夹
main_directory_path = "./captcha"
create_directory_with_subdirectories(main_directory_path)
# 随机产生验证码,长度为 4
def random_captcha_text(char_set=characters, captcha_size=4):
# 验证码列表
captcha_text = []
for _ in range(captcha_size):
# 随机选择
c = random.choice(char_set)
# 加入验证码列表
captcha_text.append(c)
return captcha_text
# 生成字符对应的验证码
def gen_captcha_text_and_image(dir):
# 验证码图片宽高可以设置,默认 width=160, height=60
image = ImageCaptcha(width=160, height=60)
# 获得随机生成的验证码
captcha_text = random_captcha_text()
# 把验证码列表转为字符串
captcha_text = ''.join(captcha_text)
# 保存验证码图片
image.write(captcha_text, dir + captcha_text + '.jpg')
if_gen_train = True
if_gen_test = True
if if_gen_train:
# 产生 50000 次随机验证码 真正的数量可能会少于 50000 因为重名的图片会被覆盖掉
num = 50000
for i in range(num):
gen_captcha_text_and_image(train_dir)
print("训练集生成完毕")
if if_gen_test:
# 产生 10000 次随机验证码 真正的数量可能会少于 10000 因为重名的图片会被覆盖掉
num = 10000
for i in range(num):
gen_captcha_text_and_image(test_dir)
print("测试集生成完毕")
for _ in range(1000):
gen_captcha_text_and_image(val_dir)
print('验证集生成完毕')4 构建数据管道
在模型设计完成后,我们需要构建数据管道,对训练数据进行处理和供给。主要通过 TensorFlow 的 Dataset API 实现。
首先定义图像解码函数,读取验证码图片,解码为 RGB 3通道格式,并归一化到0-1范围。
然后定义标签处理函数,将 one-hot 编码的标签转换成4个分类任务的标签形式。
在这基础上,构建训练集和测试集的数据管道:
- 从文件路径读取图片和标签到数据集对象
- 乱序和批量化
- 应用图像和标签处理函数映射每一批数据
- 设置训练集迭代周期数
这样我们就得到可直接供模型训练的验证码图片数据集。
数据管道的构建可以确保数据以正确格式高效流入模型,是深度学习训练过程的基础。
# 获取所有验证码图片路径和标签
def get_filenames_and_classes(dataset_dir):
# 存放图片路径
photo_filenames = []
# 存放图片标签
y = []
for filename in os.listdir(dataset_dir):
# 获取文件完整路径
path = os.path.join(dataset_dir, filename)
# 保存图片路径
photo_filenames.append(path)
# 取文件名前 4 位,也就是验证码的标签
captcha_text = filename[0:4]
# 定义一个空 label
label = np.zeros((4, num_classes), dtype=np.uint8)
# 标签转独热编码
for _, ch in enumerate(captcha_text):
# 设置标签,独热编码 one-hot 格式
# characters.find(ch)得到 ch 在 characters 中的位置,可以理解为 ch 的编号
label[_, characters.find(ch)] = 1
# 保存独热编码的标签
y.append(label)
# 返回图片路径和标签
return np.array(photo_filenames), np.array(y)
# 图像处理函数
# 获得每一条数据的图片路径和标签
def image_function(filenames, label):
# 根据图片路径读取图片内容
image = tf.io.read_file(filenames)
# 将图像解码为 jpeg 格式的 3 维数据
image = tf.image.decode_jpeg(image, channels=3)
# 归一化
image = tf.cast(image, tf.float32) / 255.0
# 返回图片数据和标签
return image, label
# 标签处理函数
# 获得每一个批次的图片数据和标签
def label_function(image, label):
# transpose 改变数据的维度,比如原来的数据 shape 是(batch_size, 4, 62)
# tf.transpose(label, [1, 0, 2])计算后得到的 shape 为(4, batch_size, 62)
# 原来的第 1 个维度变成了第 0 维度,原来的第 0 维度变成了 1 维度,第 2 维不变
label = tf.transpose(label, [1, 0, 2])
# 返回图片内容和标签,注意这里标签的返回,我们的模型会定义 4 个任务,所以这里返回4个标签
# 每个标签的 shape 为(batch_size, num_classes)
return image, (label[0], label[1], label[2], label[3])
# 获取训练集图片路径和标签
x_train, y_train = get_filenames_and_classes(train_dir)
# 获取测试集图片路径和标签
x_test, y_test = get_filenames_and_classes(test_dir)
print(f'x_train.shape:{x_train.shape}, y_train.shape:{y_train.shape}')
# 创建 dataset 对象,传入训练集图片路径和标签
dataset_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# reshuffle_each_iteration=True,每次迭代都会随机打乱
dataset_train = dataset_train.shuffle(buffer_size=1000, reshuffle_each_iteration=True)
# map-可以自定义一个函数来处理每一条数据
dataset_train = dataset_train.map(image_function)
# 数据重复生成 1 个周期
dataset_train = dataset_train.repeat(1)
# 定义批次大小
dataset_train = dataset_train.batch(batch_size)
# 注意这个 map 和前面的 map 有所不同,第一个 map 在 batch 之前,所以是处理每一条数据
# 这个 map 在 batch 之后,所以是处理每一个 batch 的数据
dataset_train = dataset_train.map(label_function)
# 创建 dataset 对象,传入测试集图片路径和标签
dataset_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
# reshuffle_each_iteration=True,每次迭代都会随机打乱
dataset_test = dataset_test.shuffle(buffer_size=1000, reshuffle_each_iteration=True)
# map-可以自定义一个函数来处理每一条数据
dataset_test = dataset_test.map(image_function)
# 数据重复生成 1 个周期
dataset_test = dataset_test.repeat(1)
# 定义批次大小
dataset_test = dataset_test.batch(batch_size)
# 注意这个 map 和前面的 map 有所不同,第一个 map 在 batch 之前,所以是处理每一条数据
# 这个 map 在 batch 之后,所以是处理每一个 batch 的数据
dataset_test = dataset_test.map(label_function)
# 生成一个批次的数据和标签, 可以用于查看数据和标签的情况
x, y = next(iter(dataset_test))
print(f'x.shape:{x.shape}')
print(f'y.shape:{np.array(y).shape}')5 模型架构设计
模型架构设计是深度学习项目的关键。本项目中的验证码识别模型使用卷积神经网络,并采用迁移学习和多任务学习的思想。
首先加载预训练的 ResNet50 模型作为特征提取器。该模型在 ImageNet 数据集上训练,能提取通用的图像特征。
然后将验证码图片作为输入,经过 ResNet50 得到特征映射。添加全局平均池化层进行降维。
接下来的关键是采用多任务学习框架。 因为验证码是 4 个字符,我们设计 4 个不同的分类器,每个专门识别 1 个字符。具体是在特征输出上连接 4 个全连接层,对应 4 个字符类别的预测。
最后使用 Keras 的函数式 API 将上述组件连接起来,定义模型的输入和 4 个输出,构建起端到端的训练网络。
编译模型时,定义 4 个不同的 loss 函数针对 4 个字符进行优化。这样可以充分利用数据集,提升识别效果。
这种迁移学习和多任务学习的设计,利用了预训练模型和训练集中全部信息,是模型设计的重要方法。
# 载入预训练的 resnet50 模型
resnet50 = ResNet50(weights='imagenet', include_top=False, input_shape=(height, width, 3))
# 设置输入
inputs = Input((height, width, 3))
# 使用 resnet50 进行特征提取
x = resnet50(inputs)
# 平均池化
x = GlobalAvgPool2D()(x)
# 把验证码识别的 4 个字符看成是 4 个不同的任务
# 每个任务负责识别 1 个字符
x0 = Dense(num_classes, activation='softmax', name='out0')(x)
x1 = Dense(num_classes, activation='softmax', name='out1')(x)
x2 = Dense(num_classes, activation='softmax', name='out2')(x)
x3 = Dense(num_classes, activation='softmax', name='out3')(x)
# 定义模型
model = Model(inputs, [x0, x1, x2, x3])
# 可视化模型
plot_model(model, to_file='resnet50.png', show_shapes=True)图一:模型结构图
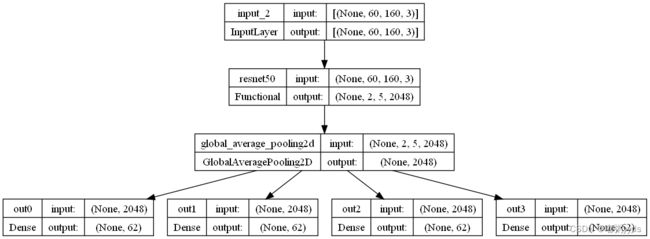
6 模型训练及调参
构建好模型和数据管道后,我们开始模型训练。主要采用以下技术:
- 设置优化器、损失函数等配置,编译模型。
- 模型训练过程中,使用回调函数实现断点续训,早停避免过拟合等。
- 训练过程可视化绘制准确率和损失函数曲线。
- 在验证集上测试模型性能。
- 通过调整训练周期、批大小、学习率等超参数,选择模型性能最佳的组合。
模型训练是一个迭代优化的过程,正确设置训练方式和评价指标非常关键。
本项目通过回调函数、训练曲线绘制和超参调优等方式,实现了验证码识别模型的有效训练。
# 4 个任务我们可以定义 4 个 loss
# loss_weights 可以用来设置不同任务的权重,验证码识别的 4 个任务权重都一样
model.compile(loss={'out0': 'categorical_crossentropy',
'out1': 'categorical_crossentropy',
'out2': 'categorical_crossentropy',
'out3': 'categorical_crossentropy'},
loss_weights={'out0': 1,
'out1': 1,
'out2': 1,
'out3': 1},
optimizer=SGD(learning_rate=1e-2, momentum=0.9),
metrics=['acc'])
# 监控指标统一使用 val_loss
# 使用 EarlyStopping 来让模型停止,连续 6 个周期 val_loss 没有下降就提前结束训练
# CSVLogger 保存训练数据
# ModelCheckpoint 保存所有训练周期中 val_loss 最低的模型
# ReduceLROnPlateau 学习率调整策略,连续 3 个周期 val_loss 没有下降当前学习率乘以0.1
callbacks = [EarlyStopping(monitor='val_loss', patience=6, verbose=1),
CSVLogger('Captcha_tfdata.csv'),
ModelCheckpoint('Best_Captcha_tfdata.h5', monitor='val_loss', save_best_only=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)]
# 训练模型
# 把之前定义的 dataset_train 和 dataset_test 传入进行训练
history = model.fit(x=dataset_train,
epochs=epochs,
validation_data=dataset_test,
callbacks=callbacks)30个epoch在batch_size为128的情况下需要40mins左右 ,读者可以酌情设置epoch和batch_size
Epoch 1/30
390/390 [==============================] - 206s 413ms/step - loss: 7.0428 - out0_loss: 1.6178 - out1_loss: 1.9870 - out2_loss: 1.9658 - out3_loss: 1.4722 - out0_acc: 0.5670 - out1_acc: 0.4828 - out2_acc: 0.4846 - out3_acc: 0.6052 - val_loss: 24.4671 - val_out0_loss: 5.1346 - val_out1_loss: 5.1664 - val_out2_loss: 6.1831 - val_out3_loss: 7.9830 - val_out0_acc: 0.0205 - val_out1_acc: 0.0155 - val_out2_acc: 0.0170 - val_out3_acc: 0.0162 - lr: 0.0100
Epoch 2/30
390/390 [==============================] - 137s 350ms/step - loss: 0.6549 - out0_loss: 0.1387 - out1_loss: 0.1889 - out2_loss: 0.1962 - out3_loss: 0.1311 - out0_acc: 0.9527 - out1_acc: 0.9383 - out2_acc: 0.9347 - out3_acc: 0.9545 - val_loss: 14.6547 - val_out0_loss: 3.3751 - val_out1_loss: 3.2783 - val_out2_loss: 3.1332 - val_out3_loss: 4.8681 - val_out0_acc: 0.3642 - val_out1_acc: 0.4040 - val_out2_acc: 0.4309 - val_out3_acc: 0.2406 - lr: 0.0100
......
Epoch 9/30
390/390 [==============================] - ETA: 0s - loss: 0.0195 - out0_loss: 0.0054 - out1_loss: 0.0050 - out2_loss: 0.0048 - out3_loss: 0.0043 - out0_acc: 0.9987 - out1_acc: 0.9989 - out2_acc: 0.9990 - out3_acc: 0.9991
Epoch 9: ReduceLROnPlateau reducing learning rate to 0.0009999999776482583.
390/390 [==============================] - 126s 322ms/step - loss: 0.0195 - out0_loss: 0.0054 - out1_loss: 0.0050 - out2_loss: 0.0048 - out3_loss: 0.0043 - out0_acc: 0.9987 - out1_acc: 0.9989 - out2_acc: 0.9990 - out3_acc: 0.9991 - val_loss: 0.4863 - val_out0_loss: 0.0992 - val_out1_loss: 0.1359 - val_out2_loss: 0.1397 - val_out3_loss: 0.1115 - val_out0_acc: 0.9708 - val_out1_acc: 0.9653 - val_out2_acc: 0.9634 - val_out3_acc: 0.9712 - lr: 0.0100
.......
Epoch 20/30
390/390 [==============================] - ETA: 0s - loss: 0.0031 - out0_loss: 7.4223e-04 - out1_loss: 7.9822e-04 - out2_loss: 8.4755e-04 - out3_loss: 6.8732e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000
Epoch 20: ReduceLROnPlateau reducing learning rate to 9.999999310821295e-05.
390/390 [==============================] - 127s 325ms/step - loss: 0.0031 - out0_loss: 7.4223e-04 - out1_loss: 7.9822e-04 - out2_loss: 8.4755e-04 - out3_loss: 6.8732e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000 - val_loss: 0.3237 - val_out0_loss: 0.0579 - val_out1_loss: 0.0918 - val_out2_loss: 0.1005 - val_out3_loss: 0.0735 - val_out0_acc: 0.9825 - val_out1_acc: 0.9757 - val_out2_acc: 0.9746 - val_out3_acc: 0.9825 - lr: 1.0000e-03
......
Epoch 27/30
390/390 [==============================] - ETA: 0s - loss: 0.0029 - out0_loss: 6.8830e-04 - out1_loss: 7.3973e-04 - out2_loss: 8.3113e-04 - out3_loss: 6.5832e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000
Epoch 27: ReduceLROnPlateau reducing learning rate to 9.999999019782991e-06.
390/390 [==============================] - 148s 380ms/step - loss: 0.0029 - out0_loss: 6.8830e-04 - out1_loss: 7.3973e-04 - out2_loss: 8.3113e-04 - out3_loss: 6.5832e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000 - val_loss: 0.3223 - val_out0_loss: 0.0576 - val_out1_loss: 0.0917 - val_out2_loss: 0.0999 - val_out3_loss: 0.0731 - val_out0_acc: 0.9825 - val_out1_acc: 0.9760 - val_out2_acc: 0.9749 - val_out3_acc: 0.9830 - lr: 1.0000e-04
Epoch 28/30
390/390 [==============================] - 137s 351ms/step - loss: 0.0030 - out0_loss: 6.9977e-04 - out1_loss: 7.5915e-04 - out2_loss: 8.3441e-04 - out3_loss: 6.6904e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000 - val_loss: 0.3222 - val_out0_loss: 0.0576 - val_out1_loss: 0.0917 - val_out2_loss: 0.0999 - val_out3_loss: 0.0731 - val_out0_acc: 0.9825 - val_out1_acc: 0.9760 - val_out2_acc: 0.9749 - val_out3_acc: 0.9831 - lr: 1.0000e-05
Epoch 29/30
390/390 [==============================] - 137s 350ms/step - loss: 0.0029 - out0_loss: 6.7813e-04 - out1_loss: 7.5350e-04 - out2_loss: 8.0466e-04 - out3_loss: 6.5595e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000 - val_loss: 0.3222 - val_out0_loss: 0.0576 - val_out1_loss: 0.0917 - val_out2_loss: 0.0999 - val_out3_loss: 0.0731 - val_out0_acc: 0.9826 - val_out1_acc: 0.9760 - val_out2_acc: 0.9748 - val_out3_acc: 0.9831 - lr: 1.0000e-05
Epoch 30/30
309/390 [======================>.......] - ETA: 23s - loss: 0.0029 - out0_loss: 6.7578e-04 - out1_loss: 7.5027e-04 - out2_loss: 8.1854e-04 - out3_loss: 6.5864e-04 - out0_acc: 1.0000 - out1_acc: 1.0000 - out2_acc: 1.0000 - out3_acc: 1.0000
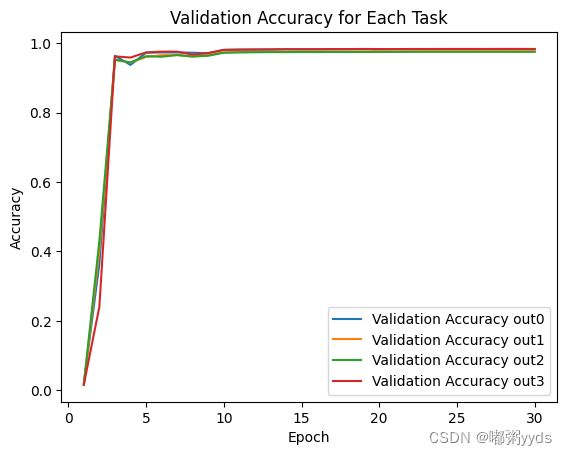
图二:训练集准确率
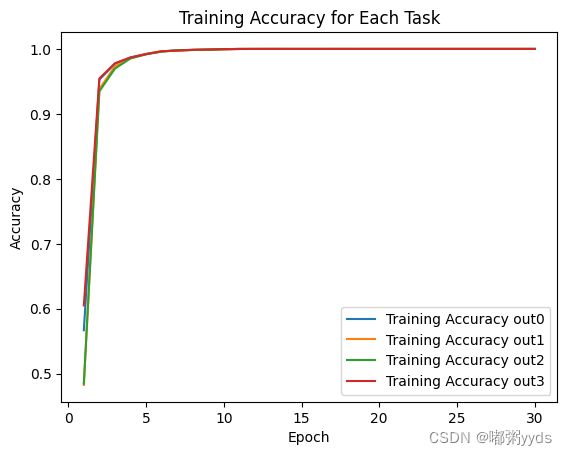
图三:测试集准确率
图四:训练集损失值
图五:测试集损失值

可以看到,模型在第10个epoch后提升就已经很不明显了,但我们设置的早停却并没有在该epoch附近结束模型训练,因为我们设置的检测指标是val_loss。若设为准确率则会触发早停。
7 模型评估与预测
模型训练完成后,我们利用测试集和验证集对模型性能进行评估。
首先在验证集上获得模型的预测结果,将预测标签和真实标签进行对比,可以计算出准确率。
然后随机抽取几个验证码图片,输入模型进行预测,输出预测的文字结果。
最后,将预测结果可视化地显示在验证码图片上,与真实的文字标签比较。
这可以直观地查看模型的预测效果,分析其错误识别的原因,判断模型在实际验证码样本上的准确率。
通过模型在测试集上的评估和预测,可以全面的判断模型性能,是否达到实用要求。此外还可以进行错误分析,指导进一步优化。
# 载入之前训练好的模型
model = load_model('Best_Captcha_tfdata.h5')
# 获取测试集图片路径和标签
x_val, y_val = get_filenames_and_classes(val_dir)
# 创建 dataset 对象,传入测试集图片路径和标签
dataset_test = tf.data.Dataset.from_tensor_slices((x_val, y_val))
dataset_test = dataset_test.shuffle(buffer_size=1000, reshuffle_each_iteration=True)
# map-可以自定义一个函数来处理每一条数据
dataset_test = dataset_test.map(image_function)
# 数据重复生成 1 个周期
dataset_test = dataset_test.repeat(1)
# 定义批次大小
dataset_test = dataset_test.batch(batch_size)
dataset_test = dataset_test.map(label_function)
# 用于统计准确率
acc_sum = 0
# 统计批次数量
n = 0
for x, y in dataset_test:
# 计算批次数量
n += 1
# 进行一个批次的预测
pred = model.predict(x)
# 获得对应编号
pred = np.argmax(pred, axis=-1)
# 获得标签数据
label = np.argmax(y, axis=-1)
# 计算这个批次的准确率然后累加到总的准确率统计中
acc_sum += (pred == label).all(axis=0).mean()
# 计算测试集准确率
print(acc_sum / n)4/4 [==============================] - 2s 19ms/step
4/4 [==============================] - 0s 24ms/step
4/4 [==============================] - 0s 23ms/step
4/4 [==============================] - 0s 21ms/step
4/4 [==============================] - 0s 23ms/step
4/4 [==============================] - 0s 23ms/step
4/4 [==============================] - 0s 20ms/step
4/4 [==============================] - 2s 183ms/step
0.9024939903846154模型的初始学习率为 0.01,随着模型训练学习率会逐渐降低。我们可以看到训练集的 4 个任务准确率都已经是 1 了,测试集的 4 个 任务准确率大约为 0.98 左右,有一定的过拟合现象也是正常的。 别看 0.98 的准确率好像挺高的,验证码识别可是要 4 个验证码都识别正确,最后的结果才算正确。所以真正的识别正确率大约是 4 个任务的正确率相乘约等于 0.92,在验证集上的结果也还可以,达到了0.90,当验证集规模增大时,准确率将会逼近甚至超过0.92。
# 把标签编号变成字符串
# 如[2,34,22,45]->'2ymJ'
def labels_to_text(labels):
ret = []
for l in labels:
ret.append(characters[l])
return "".join(ret)
# 把一个批次的标签编号都变成字符串
def decode_batch(labels):
ret = []
for label in labels:
ret.append(labels_to_text(label))
return np.array(ret)
# 获得一个批次数据
x, y = next(iter(dataset_test))
# 预测结果
pred = model.predict(x)
# 获得对应编号
pred = np.argmax(pred, axis=-1)
# shape 转换 (4,64)->(64,4)
pred = pred.T
# 获得标签数据
label = np.argmax(y, axis=-1)
# (4,64)->(64,4)
label = label.T
# 根据编号获得对应验证码
pred = decode_batch(pred)
# 根据编号获得对应验证码
label = decode_batch(label)
# 获取前 3 张图片数据
for i, image in enumerate(x[:3]):
# 显示图片
plt.imshow(image)
# 设置标题
plt.title('real:%s\npred:%s' % (label[i], pred[i]))
plt.axis('off')
plt.show()
图六:可视化预测情况



我们可以看到,要把 4 个验证码都预测正确其实还是挺难的,因为我这里做的验证码识别是需要区分大小写的,还有 0 小 o 大 O 等这些都比较容易混淆,所以能得到 90.2% 的准确率也还算不错了。
8 改进策略
通过绘制训练过程可视化准确率和损失函数曲线,我们可以知道模型在第10个epoch后提升就已经不明显了,限制模型进一步提升性能的关键元素就是数据集规模不大。
因此本项目提出的一种改进策略则是自定义数据生成器,无限生成验证码图像和对应的标签,使模型不断获得新数据进行训练。
由于该改进策略修改部分不多,与前面的代码相比,差异较小,故本文仅对自定义数据生成器部分做出讲解。
import os
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.layers import Input, Dense, GlobalAvgPool2D
from tensorflow.keras.models import Model, Sequential, load_model
from tensorflow.keras.callbacks import EarlyStopping, CSVLogger, ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.utils import Sequence, plot_model
from captcha.image import ImageCaptcha
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.use('TkAgg')
import numpy as np
import random
import string
# 字符包含所有数字和所有大小写英文字母,一共 62 个
characters = string.digits + string.ascii_letters
# 类别数
num_classes = len(characters)
# 批次大小
batch_size = 64
# 训练集批次数
# 训练集大小相当于是 64*1000=64000
train_steps = 1000
# 测试集批次数
# 测试集大小相当于是 64*100=6400
test_steps = 100
# 周期数
epochs = 20
# 图片宽度
width = 160
# 图片高度
height = 60
# 自定义数据生成器
# 我们这里的验证码数据集使用 captcha 模块生产出来的,一边生产一边训练,可以认为数据集是无限的。
# Sequence是Keras中用于生成数据批次的基类,它允许我们在训练过程中使用多线程来生成数据,并且能够自动地进行并行处理。
class CaptchaSequence(Sequence):
def __init__(self, characters, batch_size, steps, n_len=4, width=160, height=60):
# 字符集
self.characters = characters
# 批次大小
self.batch_size = batch_size
# 生成器生成多少个批次的数据
self.steps = steps
# 验证码长度
self.n_len = n_len
# 验证码图片宽度
self.width = width
# 验证码图片高度
self.height = height
# 字符集长度
self.num_classes = len(characters)
# 用于产生验证码图片
self.image = ImageCaptcha(width=self.width, height=self.height)
# 用于保存最近一个批次验证码字符
self.captcha_list = []
# 获得 index 位置的批次数据
def __getitem__(self, index):
# 初始化数据用于保存验证码图片
x = np.zeros((self.batch_size, self.height, self.width, 3), dtype=np.float32)
# 初始化数据用于保存标签
# n_len 是多任务学习的任务数量,这里是 4 个任务,batch 批次大小,num_classes 分类数量
y = np.zeros((self.n_len, self.batch_size, self.num_classes), dtype=np.uint8)
# 数据清 0
self.captcha_list = []
# 生产一个批次数据
for i in range(self.batch_size):
# 随机产生验证码
captcha_text = ''.join([random.choice(self.characters) for j in range(self.n_len)])
self.captcha_list.append(captcha_text)
# 生成验证码图片数据并进行归一化处理
x[i] = np.array(self.image.generate_image(captcha_text)) / 255.0
# j(0-3),i(0-61),ch(单个字符)
for j, ch in enumerate(captcha_text):
# 设置标签,独热编码 one-hot 格式
y[j, i, self.characters.find(ch)] = 1
# 返回一个批次的数据和标签
return x, [y[0], y[1], y[2], y[3]]
# 返回批次数量
def __len__(self):
return self.steps
# 测试生成器
# 一共一个批次,批次大小也是 1
data = CaptchaSequence(characters, batch_size=1, steps=1)
fig, axs = plt.subplots(2, 2, figsize=(10, 3))
for i in range(4):
# 产生一个批次的数据
x, y = data[0]
# 在子图中显示图片
axs[i // 2, i % 2].imshow(x[0])
# 验证码字符和对应编号
axs[i // 2, i % 2].set_title(data.captcha_list[0])
axs[i // 2, i % 2].axis('off')
plt.tight_layout()
plt.show()
if not os.path.exists('Best_Captcha.h5'):
# 载入预训练的 resnet50 模型
resnet50 = ResNet50(weights='imagenet', include_top=False, input_shape=(height, width, 3))
# 设置输入
inputs = Input((height, width, 3))
# 使用 resnet50 进行特征提取
x = resnet50(inputs)
# 平均池化
x = GlobalAvgPool2D()(x)
# 把验证码识别的 4 个字符看成是 4 个不同的任务
# 每个任务负责识别 1 个字符
# 任务 1 识别第 1 个字符,任务 2 识别第 2 个字符,任务 3 识别第 3 个字符,任务 4 识别第4 个字符
x0 = Dense(num_classes, activation='softmax', name='out0')(x)
x1 = Dense(num_classes, activation='softmax', name='out1')(x)
x2 = Dense(num_classes, activation='softmax', name='out2')(x)
x3 = Dense(num_classes, activation='softmax', name='out3')(x)
# 定义模型
model = Model(inputs, [x0, x1, x2, x3])
# 4 个任务我们可以定义 4 个 loss
# loss_weights 可以用来设置不同任务的权重,验证码识别的 4 个任务权重都一样
model.compile(loss={'out0': 'categorical_crossentropy',
'out1': 'categorical_crossentropy',
'out2': 'categorical_crossentropy',
'out3': 'categorical_crossentropy'},
loss_weights={'out0': 1,
'out1': 1,
'out2': 1,
'out3': 1},
optimizer=SGD(lr=1e-2, momentum=0.9),
metrics=['acc'])
# 监控指标统一使用 val_loss
# 使用 EarlyStopping 来让模型停止,连续 6 个周期 val_loss 没有下降就结束训练
# CSVLogger 保存训练数据
# ModelCheckpoint 保存所有训练周期中 val_loss 最低的模型
# ReduceLROnPlateau 学习率调整策略,连续 3 个周期 val_loss 没有下降当前学习率乘以0.1
callbacks = [EarlyStopping(monitor='val_loss', patience=6, verbose=1),
CSVLogger('Captcha.csv'),
ModelCheckpoint('Best_Captcha.h5', monitor='val_loss', save_best_only=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)]
# 训练模型
model.fit(x=CaptchaSequence(characters, batch_size=batch_size, steps=train_steps),
epochs=epochs,
validation_data=CaptchaSequence(characters, batch_size=batch_size, steps=test_steps),
callbacks=callbacks)
# 载入训练好的模型
model = load_model('Best_Captcha.h5')
# 测试模型,随机生成验证码
# 一共一个批次,批次大小也是 1
data = CaptchaSequence(characters, batch_size=1, steps=1)
for i in range(2):
# 产生一个批次的数据
x, y = data[0]
# 预测结果
pred = model.predict(x)
# 获得对应编号
captcha = np.argmax(pred, axis=-1)[:, 0]
# 根据编号获得对应验证码
pred = ''.join([characters[x] for x in captcha])
# 显示图片
plt.imshow(x[0])
# 验证码字符和对应编号
plt.title('real:%s\npred:%s' % (data.captcha_list[0], pred))
plt.axis('off')
plt.show()
# 自定义四个验证码
captcha_texts = ['0oO0', '1ilj', 'xXwW', 'sSkK']
fig, axs = plt.subplots(2, 2, figsize=(10, 10))
for i, captcha_text in enumerate(captcha_texts):
image = ImageCaptcha(width=160, height=60)
# 数据归一化
x = np.array(image.generate_image(captcha_text)) / 255.0
# 给数据增加一个维度变成 4 维
x = np.expand_dims(x, axis=0)
# 预测结果
pred = model.predict(x)
# 获得对应编号
captcha = np.argmax(pred, axis=-1)[:, 0]
# 根据编号获得对应验证码
pred = ''.join([characters[x] for x in captcha])
# 在子图中显示图片和预测结果
axs[i // 2, i % 2].imshow(x[0])
axs[i // 2, i % 2].set_title('real:%s\npred:%s' % (captcha_text, pred))
axs[i // 2, i % 2].axis('off')
plt.axis('off')
plt.tight_layout()
plt.show()
# 计算准确率,区分大小写
def accuracy(test_steps=100):
# 用于统计准确率
acc_sum = 0
for x, y in CaptchaSequence(characters, batch_size=batch_size, steps=test_steps):
# 进行一个批次的预测
pred = model.predict(x)
# 获得对应编号
pred = np.argmax(pred, axis=-1)
# 获得标签数据
label = np.argmax(y, axis=-1)
# 计算这个批次的准确率然后累加到总的准确率统计中
acc_sum += (pred == label).all(axis=0).mean()
# 返回平均准确率
return acc_sum / test_steps
print('---------------------------------------------')
# 计算准确率,区分大小写
print(f'模型准确率(区分大小写):{accuracy()}')
print('---------------------------------------------')
# 计算准确率,忽略大小写
def accuracy2(test_steps=100):
# 用于统计准确率
acc_sum = 0
for x, y in CaptchaSequence(characters, batch_size=batch_size, steps=test_steps):
# 进行一个批次的预测
pred = model.predict(x)
# 获得对应编号
pred = np.argmax(pred, axis=-1).T
# 保存预测值
pred_list = []
# 把验证码预测值转小写后保存
for c in pred:
# 根据编号获得对应验证码
temp_c = ''.join([characters[x] for x in c])
# 字母都转小写后保存
pred_list.append(temp_c.lower())
# 获得标签数据
label = np.argmax(y, axis=-1).T
# 保存标签
label_list = []
# # 把验证码标签值转小写后保存
for c in label:
# 根据编号获得对应验证码
temp_c = ''.join([characters[x] for x in c])
# 字母都转小写后保存
label_list.append(temp_c.lower())
# 计算这个批次的准确率然后累加到总的准确率统计中
acc_sum += (np.array(pred_list) == np.array(label_list)).mean()
# 返回平均准确率
return acc_sum / test_steps
print('---------------------------------------------')
# 计算准确率,忽略大小写
print(f'模型准确率(不区分大小写):{accuracy2()}')
print('---------------------------------------------')
图七:可视化部分生成器生成的训练数据
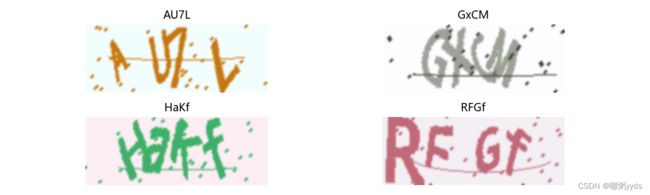
图八:自定义验证码识别结果可视化

-----------------------------------------------------
2/2 [==============================] - 0s 16ms/step
............
2/2 [==============================] - 0s 48ms/step
模型准确率(区分大小写):0.963125
----------------------------------------------------------------------------------------------------------
2/2 [==============================] - 0s 47ms/step
.........
2/2 [==============================] - 0s 41ms/step
模型准确率(不区分大小写):0.9884375
-----------------------------------------------------我们从测试结果可以看到使用自定义数据生成器产生更多的训练数据以后,模型的准确率提高到了 96.31%(区分大小写)非常高的准确率,如果不区分大小写准确率可以进一步提高到 98.84%。 在自定义验证码程序段中,我生成了'0oO0'、'1ilj'、'xXwW'和'sSkK'四种验证码,就问大家能不能分辨出哪个是 0,哪个是 o,哪个是 O,反正我肯定是分不出来,但是这个模型还能识别正确。我觉得我们训练的这个模型在这种类型的验证码识别准确率上应该是超过了人类。
9 总结与展望
通过这个验证码识别项目的实现,我们全面实践了一个深度学习项目的主要步骤,包括:
- 数据集准备:生成大量验证码图片数据
- 模型设计:构建卷积神经网络,采用迁移学习和多任务学习
- 数据处理:构建数据管道,处理图片和标签
- 模型训练:设定回调函数、超参数调整等
- 模型评估:计算准确率,可视化预测结果
一个端到端的深度学习项目涵盖数据、模型、训练、评估和改进等全部过程。这是一个非常好的编程实践,可以提高深度学习系统开发能力。
在项目的基础上,可以进行扩展和优化:
- 使用更大规模的数据集提升性能(已实现,其余方式读者若有兴趣可自行实现)
- 尝试不同模型结构,如注意力机制等
- 部署到服务器,处理实际产生的验证码
- 利用集成学习提高模型鲁棒性
通过不断优化和产品化,这个验证码识别项目可以应用到很多实际场景中,具有重要的应用价值。
项目资源
项目资源地址如下:0911duzhou/Deep-learning-verification-code-recognition-project (github.com)
若无法访问Github,也可在博主主页的资源里下载。