今日arXiv最热NLP大模型论文:基于语言模型模拟的经济学研究
引言:经济选择预测的新视角
在经济决策的预测领域,传统方法通常受限于获取人类选择数据的难度。实验经济学研究大多集中在简单的选择设置上,而这些设置往往无法捕捉复杂的人类行为。近年来,人工智能社区通过两种方式为这一领域做出了贡献:一是探讨大型语言模型(LLMs)是否能在简单的选择预测设置中替代人类;二是通过机器学习(ML)的视角研究更复杂的实验经济学设置,这些设置涉及不完全信息、重复游戏和自然语言交流,尤其是基于语言的说服游戏。这引出了一个重要的启示:LLMs是否能够完全模拟经济环境并生成数据,以高效预测人类选择,从而替代复杂的经济实验室研究?
本文开创性地研究了这一主题,并证明了其可行性。本文展示了一个仅基于LLM生成数据的模型能够有效预测人类在基于语言的说服游戏中的行为,并且甚至能够超越基于实际人类数据训练的模型。
论文标题:
Can Large Language Models Replace Economic Choice Prediction Labs?
论文链接:
https://arxiv.org/pdf/2401.17435.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
研究背景:经济选择预测的挑战与数据获取的困难
1. 经济选择预测的重要性与挑战
经济选择预测是理解和预测人类决策行为的关键任务,尤其在经济学和市场营销领域中占有重要地位。然而,这一任务面临着不小的挑战。首先,预测模型的成功依赖于大量高质量的数据,但实际情况中,获取关于人类选择的数据往往充满困难。这些困难包括开发专门的工具和环境(例如用户友好的移动或网络应用程序)、处理隐私和法律问题以允许数据的收集、存储和使用。这些挑战导致了一个极其低效、昂贵、复杂且耗时的过程。
2. 数据获取的困难
获取人类选择数据的困难不仅仅在于技术层面。从伦理和法律角度来看,收集和使用个人数据需要解决隐私保护的问题。此外,实验经济学研究通常集中在简单的选择设置上,这限制了对复杂经济环境的理解。因此,研究者们需要寻找替代的方法来获取数据,以便更有效地预测人类的经济选择行为。
大语言模型(LLM)的崛起与经济环境模拟
1. 大型语言模型(LLM)的进步
近年来,大型语言模型(LLM)在多种应用领域取得了显著进展,包括文本摘要、机器翻译、情感分析等。这些模型展示了处理自然语言通信的能力,特别是在涉及不完全信息、重复游戏和自然语言沟通的复杂经济环境中。最近的研究表明,基于LLM的代理可以成功地作为经济和战略环境中的决策者,其中代理旨在从可能的多代理互动中最大化其收益。
2. LLM与经济环境模拟
LLM的潜力不仅仅在于模仿人类行为,还在于其生成合成但现实的数据的能力。如果LLM能够有效地模仿人类在经济设置中的行为,它们可以提供一种成本效益高、效率高、可扩展的替代方法,用于传统的人类选择预测模型训练方法。在本文中,我们展示了这种方法的有效性,特别是在研究基于语言的说服游戏的背景下。在这种游戏中,发送者(sender)通过选择性地呈现信息来影响接收者(receiver)的决策过程。我们的实验表明,仅使用LLM生成的数据训练的预测模型可以准确预测人类的选择行为,甚至在样本量足够大时,性能超过了使用实际人类数据训练的模型。
通过这些研究,我们可以看到LLM在模拟经济环境和生成用于有效预测人类选择的数据方面的巨大潜力。这为未来在没有复杂经济实验室研究的情况下,使用LLM全面模拟经济环境提供了灵感和可能性。
研究核心:语言基础说服游戏中的人类行为预测
1. 实验设计:使用LLM生成数据预测人类决策
在本研究中,我们展示了在一个基本的经济设置中,即说服游戏的背景下,使用LLM生成数据预测人类行为的有效性。说服游戏的核心概念涉及一个发送者,其目标是通过选择性地呈现信息来影响接收者的决策。通常,发送者拥有关于世界实际状态的机密知识,而接收者并不知晓。基于这些私有信息,发送者战略性地传达信息以影响接收者的决策过程。虽然说服游戏的各种经济方面已经得到了充分研究(例如,最优发送者信息揭示策略的特征),但我们的研究重点不同:我们的目标是解决在重复交互中预测固定发送者对抗人类决策者的任务,而不在训练集中包含人类选择数据。
研究采用了Apel等人(2022年)引入的游戏。在这个游戏中,一个旅行代理(专家)试图通过向决策者(DM)提供有关酒店的文本信息来说服决策者接受他们的酒店。酒店的真实质量是专家的私有信息,决策者只有在酒店质量高时才能从接受交易中获益。随着游戏通过几轮的进行,专家与决策者之间的互动加深,产生了复杂的战略行为,包括学习过程、合作努力和惩罚策略。重要的是,在基于语言的游戏中,理论模型中风格化的抽象消息空间被真实的文本数据所取代。
该研究采用Shapira等人(2023年)收集的人类行为数据,并使用它来定义我们的人类选择预测任务。与Shapira等人(2023年)研究的离策略评估不同,我们的目标是在不包含任何人类生成数据的训练集中,准确预测人类选择,并且完全依赖LLM生成的数据。
实验揭示了一个基于LLM玩家生成的数据集训练的预测模型可以准确预测人类选择行为。事实上,它甚至可以超过基于实际人类选择数据训练的模型,只要样本量足够大。在许多现实生活场景中,生成大量LLM基础样本要比获取即使是小量的人类选择数据集容易得多。在专家总是天真地发送最好的评论而不考虑酒店的真实质量的情况下,这种预测准确性的提高在任何样本量下都会观察到,而不仅仅是在足够大的样本量下。这种专家策略具有特殊的重要性,因为Raifer等人(2022年)在类似的与人类决策者的说服设置中证明了其实证效果。
此外,研究还展示了在生成这个数据集时,通过创建不同玩家类型的角色变化可以减少获得一定准确性水平所需的样本量。然后,分析了每种角色类型对数据集整体质量的平均边际贡献。
实验结果:LLM数据对人类行为的准确预测
1. 针对SendBest策略的预测
在SendBest策略下,专家总是无论酒店的真实质量如何,都会发送得分最高的评论。我们的实验结果表明,当专家采用这种策略时,即使是在任何样本大小的情况下,使用LLM生成的数据训练的预测模型也能够准确预测人类决策者的行为,并且优于使用真实人类数据训练的模型。这种策略在现实生活中的应用非常广泛,因为它代表了一种非常常见且典型的行为,即专家试图贪婪地说服非精明的用户接受优惠。
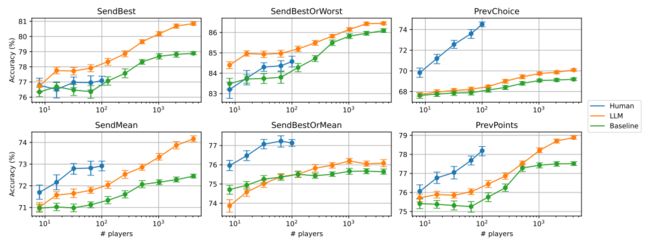
2. 针对SendBestOrMean策略的预测
SendBestOrMean策略指的是,如果酒店质量好,专家总是发送最好的评论;如果酒店质量差,专家则发送与酒店平均得分最接近的评论。这种策略非常接近标准产品采纳设置中发送者的优选策略。然而,我们的研究发现,在SendBestOrMean策略下,使用LLM生成的数据训练的模型在预测人类决策时的准确性并不如使用真实人类数据训练的模型,即使是在非常大的数据集上也是如此。
通过这些实验结果,我们可以看出,LLM生成的数据在预测人类在特定策略下的行为方面具有显著的潜力,尤其是在SendBest策略下。同时,这些发现也揭示了在SendBestOrMean策略下使用LLM生成的数据进行预测时存在的局限性。未来的研究可以进一步探索如何提高在这些策略下的预测准确性,以及如何更好地利用LLM生成的数据来预测人类在各种经济设置中的行为。
人格多样化对预测准确性的影响
在经济选择预测的领域,人格多样化是一个值得关注的因素。最近的研究表明,通过引入不同的人格类型(persona types)来生成大型语言模型(LLM)的数据集,可以有效降低达到特定预测准确性所需的样本量。这一发现对于提高训练过程的效率具有重要意义。
1. 样本量减少
实验结果显示,在包含多种人格类型的玩家生成的数据集中,达到特定准确性水平所需的玩家数量较少。这表明,使用多种人格类型可以提高训练过程的效率。例如,当数据集仅包含默认人格类型的玩家时,与包含所有可能人格类型的玩家混合的数据集相比,达到相同准确性水平所需的样本量更大。
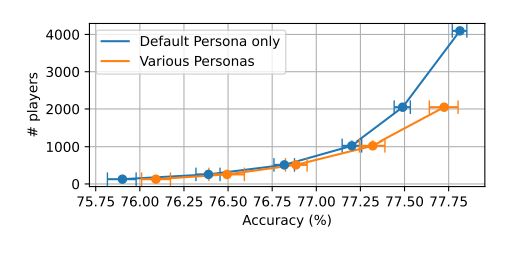
2. 人格类型的边际贡献
进一步的分析表明,不同人格类型对整体预测质量的平均边际贡献大致相同。这意味着,每种人格类型在增强数据集价值方面都发挥着同等重要的作用。为了量化这一贡献,研究者采用了著名的Shapley值概念,这是一种在机器学习解释性中广泛使用的方法。通过这种方法,研究者能够评估每种人格类型生成的数据集对初始数据集预测质量的平均增量贡献。
结论与展望:LLM在经济选择预测中的应用前景
本研究的主要目标是展示如何使用LLM生成的数据来训练人类选择预测模型。通过在语言基础的说服游戏中的应用,我们展示了一个训练模型,该模型仅使用LLM生成的数据,甚至在数据点足够多时,可以超越使用实际人类生成数据训练的模型的结果。这一发现对于理解合成数据在经济环境中增强人类选择预测的潜力具有重要意义。
1. LLM生成数据的预测能力
我们的分析显示,尽管LLM生成的数据在某些特定专家策略下的表现不如基于实际人类数据的训练模型,但在大多数情况下,LLM方法的表现优于使用人类数据的标准方法。特别是在预测人类对SendBest专家策略的反应时,LLM方法表现出色,这一策略在实际中被证明对人类决策者具有很强的说服力。
2. 未来研究方向
尽管本文的发现是初步的,并且特定于我们的实验环境,但它们提供了一种新的方法来研究和预测人类行为。未来的研究可以专注于探索LLM生成数据在说服游戏之外的预测能力,以及引入结合人类和合成数据的混合方法,以更准确地预测战略性人类决策。另一个研究方向是更仔细地研究(并解释)LLM方法在特定专家策略下的表现,以界定这种方法的边界和局限性。这些研究方向都旨在增强我们对LLM在存在激励和人类行为的机器学习应用中的理解。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接

