视觉slam十四讲学习笔记(四)相机与图像
- 理解理解针孔相机的模型、内参与径向畸变参数。
- 理解一个空间点是如何投影到相机成像平面的。
- 掌握OpenCV的图像存储与表达方式。
- 学会基本的摄像头标定方法。
目录
前言
一、相机模型
1 针孔相机模型
2 畸变
单目相机的成像过程
3 双目相机模型
4 RGB-D 相机模型
二、图像
计算机中图像的表示
三、图像的存取与访问
1 安装OpenCV
2 存取与访问
总结
前言
前面介绍了“机器人如何表示自身位姿”的问题,部分地解释了 SLAM 经典模型中变量的含义和运动方程部分。本文要讨论“机器人如何观测外部世界”,也就是观测方程部分。而在以相机为主的视觉 SLAM 中,观测主要是指相机成像的过程。
哔哩哔哩课程链接:视觉SLAM十四讲ch5_哔哩哔哩_bilibili
一、相机模型
相机将三维世界中的坐标点(单位为米)映射到二维图像平面(单位为像素)的过程能够用一个几何模型进行描述。这个模型有很多种,其中最简单的称为针孔模型。
针孔模型是很常用,而且有效的模型,它描述了一束光线通过针孔之后,在针孔背面投影成像的关系。在本文用一个简单的针孔相机模型来对这种映射关系进行建模。同时,由于相机镜头上的透镜的存在,会使得光线投影到成像平面的过程中会产生畸变。因此,使用针孔和畸变两个模型来描述整个投影过程。
先给出相机的针孔模型,再对透镜的畸变模型进行讲解。这两个模型能够把外部的三维点投影到相机内部成像平面,构成了相机的内参数。
1 针孔相机模型
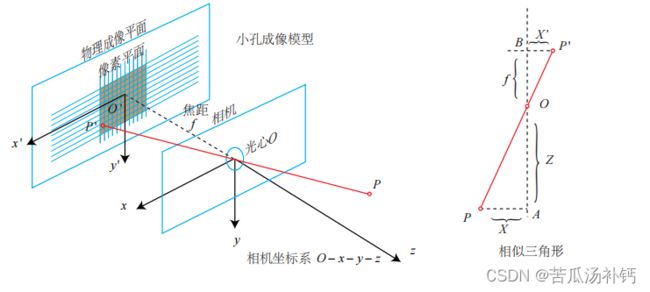
现在来对这个简单的针孔模型进行几何建模。设 O − x − y − z 为相机坐标系,习惯上让 z 轴指向相机前方,x 向右,y 向下。O 为摄像机的光心,也是针孔模型中的针孔。现实世界的空间点 P,经过小孔 O 投影之后,落在物理成像平面 O′ − x ′ − y ′ 上,成像点为 P ′。设 P 的坐标为 [X, Y, Z] T,P ′ 为 [X′ , Y ′ , Z′ ] T,并且设物理成像平面到小孔的距离为 f(焦距)。那么,根据三角形相似关系,有:

其中负号表示成的像是倒立的。为了简化模型,我们把可以成像平面对称到相机前方,和三维空间点一起放在摄像机坐标系的同一侧,如下公式的样子所示。这样做可以把公 式中的负号去掉,使式子更加简洁:

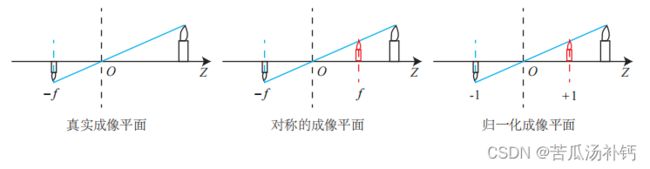
真实成像平面,对称成像平面,归一化成像平面的图示如上图。

描述了点 P 和它的像之间的空间关系。不过,在相机中,我们最终获得的是一个个的像素,这需要在成像平面上对像进行采样和量化。为了描述传感器将感受到的光线转换成图像像素的过程,设在物理成像平面上固定着一个像素平面 o − u − v。在像素平面得到了 P ′ 的像素坐标:[u, v] T。
像素坐标系通常的定义方式是:原点 o ′ 位于图像的左上角,u 轴向右与 x 轴平行,v轴向下与 y 轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。设像素坐标在 u 轴上缩放了 α 倍,在 v 上缩放了 β 倍。同时,原点平移了 [cx, cy] T。那么,P ′ 的坐标与像素坐标 [u, v] T 的关系为:

并把 αf 合并成 fx,把 βf 合并成 fy,得:

其中,f 的单位为米,α, β 的单位为像素每米,所以fx, fy 的单位为像素。把该式写成矩阵形式,会更加简洁,不过左侧需要用到齐次坐标:

把中间的量组成的矩阵称为相机的内参数矩阵(Camera Intrinsics)K。通常认为,相机的内参在出厂之后是固定的,不会在使用过程中发生变化。有的相机生产厂商会告诉你相机的内参,而有时需要自己确定相机的内参,也就是所谓的标定。
除了内参之外,自然还有相对的外参。上面使用的是 P 在相机坐标系下的坐标。由于相机在运动,所以 P 的相机坐标应该是它的世界坐标(记为 Pw),根据相机的当前位姿,变换到相机坐标系下的结果。相机的位姿由它的旋转矩阵 R 和平移向量 t 来描述。那么有:

相机的位姿 R, t 又称为相机的外参数(Camera Extrinsics)。相比于不变的内参,外参会随着相机运动发生改变,同时也是 SLAM中待估计的目标,代表着机器人的轨迹。上式两侧都是齐次坐标。因为齐次坐标乘上非零常数后表达同样的含义,所以可以简单地把 Z 去掉:

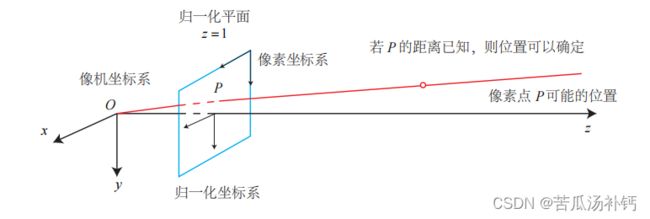
可以看到,右侧的 T Pw 表示把一个世界坐标系下的齐次坐标,变换到相机坐标系下。为了使它与 K 相乘,需要取它的前三维组成向量——因为 T Pw 最后一维为 1。此时,对于这个三维向量,还可以按照齐次坐标的方式,把最后一维进行归一化处理,得到了 P 在相机归一化平面上的投影:
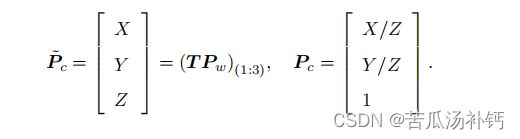
这时 Pc 可以看成一个二维的齐次坐标,称为归一化坐标。它位于相机前方 z = 1 处的平面上。该平面称为归一化平面。由于 Pc 经过内参之后就得到了像素坐标,所以可以把像素坐标 [u, v] T,看成对归一化平面上的点进行量化测量的结果。
2 畸变
为了获得好的成像效果,在相机的前方加了透镜。透镜的加入对成像过程中光线的传播会产生新的影响: 一是透镜自身的形状对光线传播的影响,二是在机械组装过程中,透镜和成像平面不可能完全平行,这也会使得光线穿过透镜投影到成像面时的位置发生变化。
由透镜形状引起的畸变称之为径向畸变。在针孔模型中,一条直线投影到像素平面上还是一条直线。可是,在实际拍摄的照片中,摄像机的透镜往往使得真实环境中的一条直线在图片中变成了曲线。越靠近图像的边缘,这种现象越明显。由于实际加工制作的透镜往往是中心对称的,这使得不规则的畸变通常径向对称。它们主要分为两大类,桶形畸变和枕形畸变,如图所示。
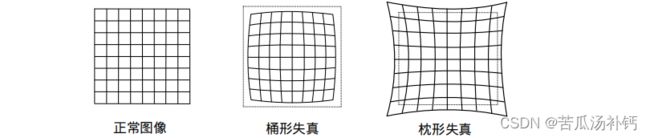
桶形畸变是由于图像放大率随着离光轴的距离增加而减小,而枕形畸变却恰好相反。在这两种畸变中,穿过图像中心和光轴有交点的直线还能保持形状不变。
除了透镜的形状会引入径向畸变外,在相机的组装过程中由于不能使得透镜和成像面严格平行也会引入切向畸变。

在相机成像过程中,由于镜头等因素会引起畸变,因此需要进行畸变校正以得到图像中物体的真实位置。畸变通常可以通过畸变模型进行建模,其中五个畸变系数是指径向畸变和切向畸变的参数。
-
径向畸变(Radial Distortion): 这是由于镜头非理想形状引起的畸变。径向畸变通常分为两个方面:正径向畸变和负径向畸变。正径向畸变使图像中心附近的点向外弯曲,而负径向畸变则使其向内弯曲。
-
切向畸变(Tangential Distortion): 切向畸变是由于镜头和图像平面之间的不平行引起的。这种畸变使图像中的物体看起来被挤压或拉伸。
畸变模型一般可以用以下公式表示:
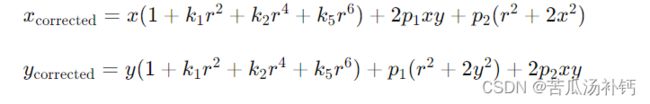
其中,xcorrected,ycorrected 是校正后的像素坐标,x,y 是原始的像素坐标,k1,k2,k5 是径向畸变系数,p1,p2 是切向畸变系数,r2=x2+y2。
这些参数通过相机标定的过程来获取,标定通常使用一组已知空间坐标的点和对应的图像坐标点。标定后,这些畸变系数就能用于校正图像中的点位置,使其更准确地映射到空间坐标系。
相机畸变的纠正:

这个过程通常由图像处理库或相机标定工具提供的函数来实现。在OpenCV中,undistort函数用于畸变校正。确保在使用这些函数之前进行相机标定以获取畸变系数。
单目相机的成像过程

3 双目相机模型
双目相机是一种具有两个摄像头的系统,模拟人类双眼视觉以获得深度信息。双目相机模型可以基于摄像头之间的几何关系、相机参数和成像原理进行分类。以下是一些常见的双目相机模型:
-
平行轴双目模型(Parallel Stereo Model): 在平行轴双目模型中,两个摄像头的光轴是平行的,即两个摄像头处于相同的水平平面上。这种模型简化了几何关系,使得深度估计更容易,但在实际中较少见。
-
共轴双目模型(Coaxial Stereo Model): 在共轴双目模型中,两个摄像头的光轴是共轴的,即两个摄像头位于同一光学轴上。这种模型常用于一些特殊应用,如显微镜等。
-
基线双目模型(Baseline Stereo Model): 基线是指两个摄像头之间的距离。在基线双目模型中,基线的大小会直接影响深度估计的精度。通常,基线越长,深度信息的精度越高,但相应的计算开销也会增加。
-
非共面双目模型(Non-Coplanar Stereo Model): 在非共面双目模型中,两个摄像头的光心不在同一平面上。这种情况下,深度估计可能需要考虑额外的几何变换。
-
鱼眼双目模型(Fisheye Stereo Model): 有时候,双目系统使用鱼眼镜头,使得摄像头能够捕捉更广阔的视野。在这种情况下,通常需要特殊的几何模型来处理图像畸变。
像素点可能存在的位置:
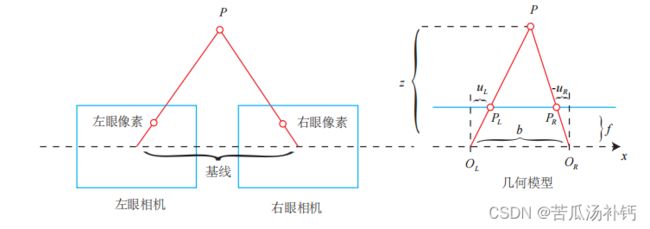
双目相机的成像模型如下图所示。OL, OR 为左右光圈中心,蓝色框为成像平面,f 为焦距。uL 和 uR 为成像平面的坐标。请注意按照图中坐标定义,uR 应该是负数,所以图中标出的距离为 −uR。
通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。
双目相机一般由左眼和右眼两个水平放置的相机组成。当然也可以做成上下两个目,但主流双目都是做成左右的。在左右双目的相机中,可以把两个相机都看作针孔相机。它们是水平放置的,意味两个相机的光圈中心都位于 x 轴上。它们的距离称为双目相机的基线(Baseline, 记作 b),是双目的重要参数。
考虑一个空间点 P,它在左眼和右眼各成一像,记作 PL, PR。由于相机基线的存在,这两个成像位置是不同的。理想情况下,由于左右相机只有在 x 轴上有位移,因此P 的像也只在 x 轴(对应图像的 u 轴)上有差异。记它在左侧的坐标为 uL,右侧坐标为 uR。那么,它们的几何关系如图5-6右侧所示。根据三角形 P −PL −PR 和 P −OL −OR的相似关系,有:

这里 d 为左右图的横坐标之差,称为视差(Disparity)。根据视差,可以估计一个像素离相机的距离。视差与距离成反比:视差越大,距离越近。同时,由于视差最小为一个像素,于是双目的深度存在一个理论上的最大值,由 fb 确定。我们看到,当基线越长时,双目最大能测到的距离就会变远;反之,小型双目器件则只能测量很近的距离。
虽然由视差计算深度的公式很简洁,但视差 d 本身的计算却比较困难。需要确切地知道左眼图像某个像素出现在右眼图像的哪一个位置(即对应关系),这件事亦属于“人类觉得容易而计算机觉得困难”的事务。当想计算每个像素的深度时,其计算量与精度都将成为问题,而且只有在图像纹理变化丰富的地方才能计算视差。由于计算量的原因,双目深度估计仍需要使用 GPU 或 FPGA 来计算。
4 RGB-D 相机模型
RGB-D相机是一类同时提供RGB(彩色)和深度信息的相机。这些相机可以在计算机视觉和机器人领域中发挥重要作用,因为深度信息可以用于三维场景理解和物体感知。以下是一些常见的RGB-D相机:
-
Microsoft Kinect系列: Kinect是一系列由微软推出的RGB-D相机。最早的Kinect for Xbox 360和后来的Kinect for Windows都包含了深度传感器,它们使用结构光技术进行深度测量。
-
Intel RealSense系列: Intel RealSense相机是一系列集成了RGB和深度传感器的产品。它们使用多种深度技术,包括飞行时间(Time-of-Flight)和结构光。
-
Asus Xtion系列: Asus Xtion相机是与Kinect类似的RGB-D相机,使用结构光技术来获取深度信息。
-
Occipital Structure Sensor: Structure Sensor是一款针对iOS设备的RGB-D相机,可以附加到iPad或iPhone上,提供深度信息。
-
Orbbec Astra系列: Orbbec Astra是一系列RGB-D相机,使用飞行时间技术,适用于各种计算机视觉和机器人应用。
目前的 RGB-D 相机按原理可分为两大类:
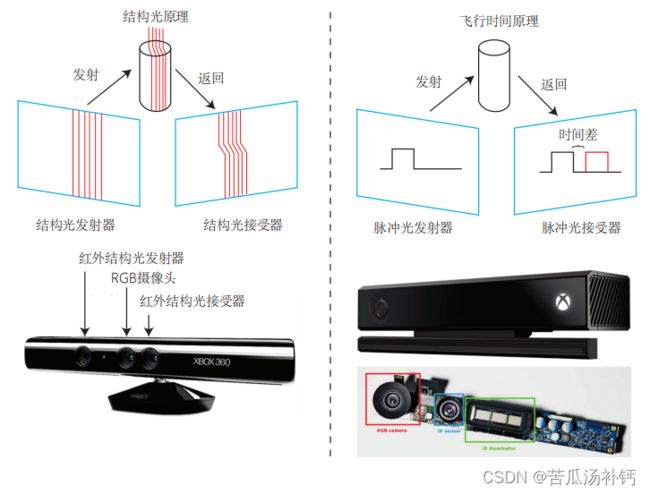
- 1. 通过红外结构光(Structured Light)来测量像素距离的。例子有 Kinect 1 代、ProjectTango 1 代、Intel RealSense 等;
- 2. 通过飞行时间法(Time-of-flight, ToF)原理测量像素距离的。例子有 Kinect 2 代和一些现有的 ToF 传感器等。
无论是结构光还是 ToF,RGB-D 相机都需要向探测目标发射一束光线(通常是红外光)。在结构光原理中,相机根据返回的结构光图案,计算物体离自身的距离。而在 ToF中,相机向目标发射脉冲光,然后根据发送到返回之间的光束飞行时间,确定物体离自身的距离。ToF 原理和激光传感器十分相似,不过激光是通过逐点扫描来获取距离,而 ToF相机则可以获得整个图像的像素深度,这也正是 RGB-D 相机的特点。所以,如果把一个 RGB-D 相机拆开,通常会发现除了普通的摄像头之外,至少会有一个发射器和一个接收器。
在测量深度之后,RGB-D 相机通常按照生产时的各个相机摆放位置,自己完成深度与彩色图像素之间的配对,输出一一对应的彩色图和深度图。可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云(Point Cloud)。对RGB-D 数据,既可以在图像层面进行处理,亦可在点云层面处理。
RGB-D 相机能够实时地测量每个像素点的距离。但是,由于这种发射-接受的测量方式,使得它使用范围比较受限。用红外进行深度值测量的 RGB-D 相机,容易受到日光或其他传感器发射的红外光干扰,因此不能在室外使用,同时使用多个时也会相互干扰。对于透射材质的物体,因为接受不到反射光,所以无法测量这些点的位置。此外,RGB-D 相机在成本、功耗方面,都有一些劣势。
二、图像
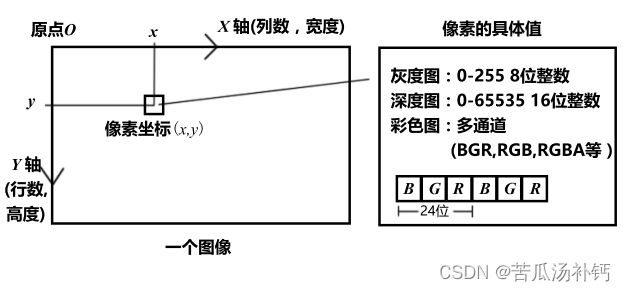
相机加上镜头,把三维世界中的信息转换成了一个由像素组成的照片,随后存储在计算机中,作为后续处理的数据来源。在数学中,图像可以用一个矩阵来描述;而在计算机中,它们占据一段连续的磁盘或内存空间,可以用二维数组来表示。这样一来,程序就不必区别它们处理的是一个数值矩阵,还是有实际意义的图像了。
计算机中图像的表示
计算机中图像的表示通常使用像素(Pixel)的矩阵或张量来表达。图像可以是灰度图像(单通道)或彩色图像(多通道)。以下是两种常见的图像表示方式:
灰度图像表示:
-
单通道矩阵: 灰度图像由一个二维矩阵表示,其中每个元素代表图像中对应位置的像素值。像素值通常在0到255的范围内,表示灰度强度。
-
灰度图像张量: 在深度学习中,灰度图像也可以表示为三维张量,其中第三个维度的大小为1。这种表示形式更适用于与多通道彩色图像的处理方式一致。
彩色图像表示:
-
三通道矩阵: 彩色图像通常由三个独立的二维矩阵(红、绿、蓝通道)组成,每个矩阵表示相应通道的像素值。这种表示方式称为RGB(Red, Green, Blue)表示。
-
彩色图像张量: 彩色图像可以表示为三维张量,其中最后一个维度的大小为3,分别对应于红、绿、蓝通道。在深度学习中,张量表示更为普遍。
其他表示方式:
-
HSV表示: 除了RGB表示外,还可以使用HSV(Hue, Saturation, Value)或其他颜色空间表示图像,具体颜色空间的选择取决于应用需求。
-
浮点数表示: 在一些应用中,像素值可能以浮点数表示,表示更为丰富的信息,例如在图像处理中的滤波操作。
程序中的访问形式:
unsigned char pixel = image[y][x];图像的表示方式取决于应用场景和任务,不同的表示方式适用于不同的计算机视觉和图像处理应用。在深度学习中,通常使用张量表示,并且神经网络的输入层被设计为接受相应的图像张量。
三、图像的存取与访问
1 安装OpenCV
在 ubuntu 下,可以选择从源代码安装和只安装库文件两种方式:
- 从源代码安装,是指从 OpenCV 网站下载所有的 OpenCV 源代码。并在你的机器上编译安装,以便使用。好处是可以选择的版本比较丰富,而且能看到源代码,不过需要花费一些编译时间;
- 只安装库文件,是指通过 Ubuntu 来安装由 Ubuntu 社区人员已经编译好的库文件,这样你就无需重新编译一遍。
由于我的openCV版本是4.8.1,所以我修改了cmakelist.txt

2 存取与访问
然后就是熟悉的步骤

./imageBasics ./ubuntu.png图像宽为1200,高为674,通道数为3
遍历图像用时:0.00727802 秒。
总结
以上就是今天要讲的内容,本文包括相机与图像的基本概念。并通过一个演示程序,来理解在 OpenCV 中,图像存取与访问其中的像素的。