为自监督学习重构去噪扩散模型
在这项研究中,作者检验了最初用于图像生成的去噪扩散模型(DDM)的表示学习能力。其理念是解构DDM,逐渐将其转化为经典的去噪自动编码器(DAE)。这一解构过程让大家能够探索现代DDM的各个组成部分如何影响自监督的表征。观察到,只有极少数现代组件对学习好的表征至关重要,而其他许多组件则不重要。研究最终得出了一种高度简化的方法,在很大程度上类似于经典的DAE。
来自:Deconstructing Denoising Diffusion Models for Self-Supervised Learning
目录
- 背景概述
-
- 相关工作
- 去噪扩散模型
- 重构扩散模型
-
- 用于自监督学习的DDM重定向
- 重构Tokenizer
- 走向经典的DAE
- 总结
背景概述
去噪是当前计算机视觉和其他领域生成模型的核心。如今,这些方法通常被称为去噪扩散模型(DDM),学习了一种去噪自编码器(DAE),它可以去除由扩散过程驱动的多个级别的噪声。这些方法实现了令人印象深刻的图像生成质量,尤其是高分辨率、逼真的图像。这不禁让人想到,这些生成模型非常好,似乎对理解视觉内容有很强的表示。
虽然DAE是当今生成模型的强大力量,但它最初是为了以自监督的方式从数据中学习表示而提出的。在当今的表示学习社区中,DAE最成功的变体可以说是基于“masking noise”,例如预测语言中的缺失文本(例如,BERT)或图像中的缺失patch(例如,MAE)。然而,在概念上,这些基于mask的变体与去除加性噪声(例如,高斯噪声)存在显著不同:mask的token明确指定未知与已知内容,但在分离加性噪声的任务中没有明确的信号可用。然而,今天的DDM主要基于加性噪声,这意味着它们可以在不显式标记未知和已知内容的情况下学习表示。
最近,人们对DDM的表征学习能力越来越感兴趣。特别是,这些研究直接来自最初用于生成的预训练DDM,并评估其表示质量以进行识别。他们报告说,使用这些模型取得了令人鼓舞的结果。然而,这些开创性的研究显然留下了悬而未决的问题:这些现成的模型是为生成而设计的,而不是识别;目前还不清楚表示能力是通过去噪过程还是扩散过程获得的。
在这项工作中,作者对这些最近的探索相关初始化的方向进行了更深入的研究。不像之前使用面向生成的现成(off-the-shelf)DDM,作者训练面向识别的模型。核心是解构DDM,逐步将其转变为经典的DAE。通过这个解构性的研究过程,作者考察了现代DDM的每一个方面,目的是学习表征。这一研究过程使我们对DAE学习良好表示的关键组件有了新的理解。
令人惊讶的是,作者发现主要的关键组件是标记器(tokenizer),它创建了一个低维的潜在空间。有趣的是,这一观察结果在很大程度上独立于tokenizer的具体情况:作者探索了标准VAE、patch-wise VAE、patch-wise AE和patch-wise PCA编码器。发现使DAE能够实现良好的表示的是低维潜在空间,而不是tokenizer的细节。
由于PCA的有效性,解构轨迹最终达到了一个与经典DAE高度相似的简单架构(图1)。使用patch-wise PCA将图像投影到潜在空间上,添加噪声,然后通过逆PCA将其投影回来。然后训练一个自动编码器来预测去噪图像。作者将这种架构称为“潜在去噪自动编码器”(l-DAE,latent Denoising Autoencoder)。
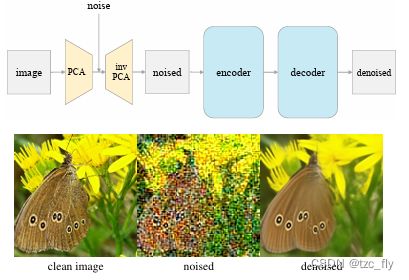
- 图1:这种简单的架构在很大程度上类似于经典的DAE(主要区别是将噪声添加到潜在的DAE中),并实现了有竞争力的自监督学习性能。
解构轨迹还揭示了DDM和经典DAE之间的许多其他有趣的特性。例如,即使使用单个噪声水平(即,不使用DDM的噪声scheduling),也可以让l-DAE获得不错的结果。使用多个级别的噪声的作用类似于一种形式的数据增强,这可能是有益的,但不是一个促成因素。根据这一点和其他观察结果,作者认为DDM的表示能力主要是通过去噪驱动的过程获得的,而不是扩散驱动的过程。
最后,作者将结果与以前的基线进行比较。一方面,我们的结果比现有的结果要好得多:这正如预期的那样,因为这是解构的起点。另一方面,结果没有达到基线对比学习方法和基于mask的方法,但差距缩小了。研究表明,在DAE和DDM的方向上还有更多的研究空间。
相关工作
在机器学习和计算机视觉的历史上,图像(或其他内容)的生成与无监督或自监督学习的发展密切相关。生成方法在概念上是非监督或自监督学习的形式,在没有标记数据的情况下训练模型,学习输入数据的基本分布。人们普遍认为,模型生成高保真度数据的能力表明了其学习良好表示的潜力。例如,生成对抗性网络(GAN)激发了人们对对抗性表示学习的广泛兴趣。变分自动编码器(VAE)最初被概念化为近似数据分布的生成模型,现已发展成为学习局部表示(“tokens”)的标准,例如VQV AE和变体。图像修复本质上是条件图像生成的一种形式,它产生了一系列现代表示学习方法,包括上下文编码器Context Encoder和masked自动编码器(MAE)。
类似地,去噪扩散模型出色的生成性能因其在表示学习中的潜力而引起关注。目前已经开始通过评估现有的预训练DDM来研究这一方向。然而,注意到,虽然模型的生成能力表明了一定程度的理解能力,但它并不一定转化为对下游任务有用的表示。因此该研究深入探讨了这些问题。
另一方面,尽管去噪自动编码器(DAE)为基于自动编码的表示学习奠定了基础,但它们的成功主要局限于涉及基于mask破坏的场景。最近很少或根本没有研究报告具有加性高斯噪声的经典DAE的结果,作者认为根本原因是简单的DAE基线(图2a)表现不佳。
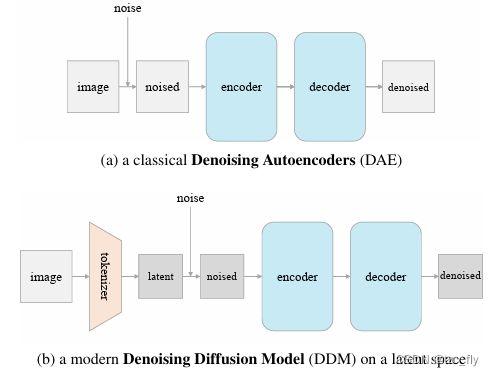
- 图2:一个经典DAE和一个现代DDM。a:在图像空间中添加并预测噪声的经典DAE,b:在潜在空间上操作的最先进的DDM(例如DIT),在latent space中添加并预测噪声。
去噪扩散模型
解构研究始于去噪扩散模型。简要描述了DDM如下。
扩散过程从干净的数据点 z 0 z_{0} z0开始,按顺序添加噪声。在指定的时间step t t t,加噪后的数据 z t z_{t} zt为: z t = γ t z 0 + σ t ϵ z_{t}=\gamma_{t}z_{0}+\sigma_{t}\epsilon zt=γtz0+σtϵ其中, ϵ ∼ N ( 0 , I ) \epsilon\sim N(0,I) ϵ∼N(0,I)是一个从高斯分布采样的noise map, γ t \gamma_{t} γt和 σ t \sigma_{t} σt分别定义了信号和噪声的scaling因子。此外, γ t 2 + σ t 2 = 1 \gamma_{t}^{2}+\sigma_{t}^{2}=1 γt2+σt2=1。
以时间step t t t为条件,学习去噪扩散模型来去除噪声。不同于DAE预测干净的输入,DDM预测噪声 ϵ \epsilon ϵ。损失为最小化: ∣ ∣ ϵ − n e t ( z t ) ∣ ∣ 2 ||\epsilon-net(z_{t})||^{2} ∣∣ϵ−net(zt)∣∣2其中, n e t ( z t ) net(z_{t}) net(zt)是网络输出。在给定以时间步长 t t t为条件的噪声调度下,针对多个噪声水平来训练网络。在生成过程中,迭代地应用经过训练的模型,直到它达到干净信号 z 0 z_{0} z0。
DDM可以在两种类型的输入空间上操作。一个是原始像素空间,其中原始图像 x 0 x_{0} x0直接用作 z 0 z_{0} z0。另一种选择是在tokenizer产生的潜在空间上构建DDM,见图2b。在这种情况下,预训练的tokenizer f f f(通常是一个自编码器),比如VQVAE被用于 z 0 = f ( x 0 ) z_{0}=f(x_{0}) z0=f(x0)。
DiT:Diffusion Transformer
该研究从DiT开始,选择这种基于Transformer的DDM有几个原因:i.与其他基于UNet的DDM不同,基于Transformer的架构可以与Transformer驱动的其他自监督学习基线进行更公平的比较;ii.DiT在编码器和解码器之间有更清晰的区别,而UNet的编码器和解码器通过skip连接,并且在评估编码器时可能需要在网络改动上付出额外的努力;iii.DiT的训练速度比其他基于UNet的DDM快得多,同时实现了更好的生成质量。
作者使用DiT-Large(DiT-L)变体作为DDM基线。在DiT-L中,编码器和解码器加在一起的大小为ViT-L(24个blocks)。作者评估编码器的表示质量(linear probe accuracy),编码器有12个blocks,称为 1 2 L \frac{1}{2}L 21L(half large)。
Tokenizer
DiT是潜在扩散模型(LDM)的一种形式,它使用VQGAN tokenizer。VQGAN tokenizer将(256,256,3)的输入图像转换到 ( 32 , 32 , 4 ) (32,32,4) (32,32,4)的latent map。
开始的baseline
默认情况下,作者在ImageNet上以256×256像素的分辨率训练400个epochs的模型。DiT baseline的结果见表1(第一行)。使用DiT-L,作者报告使用其 1 2 L \frac{1}{2}L 21L编码器的线性探头精度为57.5%。该DiT-L模型的生成质量为11.6。
重构扩散模型
解构轨迹分为三个阶段。作者首先调整了DiT中以生成为中心的设置,使其更倾向于自监督学习。接下来,逐步解构和简化tokenizer。最后,作者试图扭转尽可能多的DDM驱动设计,将模型推向经典的DAE。
用于自监督学习的DDM重定向
虽然DDM在概念上是DAE的一种形式,但它最初是为了生成图像而开发的。DDM中的许多设计都面向生成任务。有些设计对于自监督学习是不合法的(例如,涉及类别标签);如果不考虑视觉质量,则其他一些是不必要的。在本节中,作者为了自监督学习的目的重新调整了DDM基线,总结见表1。

- 表1:从DiT baseline开始,并在ImageNet上评估其线性探针精度(acc)。每一行都基于对前一行的修改。使用类标签的灰色条目不是自监督学习的结果。
移除类别-条件
高质量的DDM通常在类标签上进行条件训练,这可以在很大程度上提高生成质量。但是,在自监督学习中,标签的使用是不行的。作为第一步,作者在baseline中删除类条件。令人惊讶的是,尽管生成质量如预期的那样受到极大的损害(FID从11.6提高到34.2),但去除类别条件显著提高了线性探针的精度,从57.5%提高到62.1%(表1)。作者假设,直接将模型条件化为类标签会减少模型对编码的信息需求,删除类条件可以强制模型学习更多语义。
重构VQGAN
在baseline中,LDM的VQGAN tokenizer使用多个损失项进行训练:i.自动编码重建损失;ii.KL散度正则化损失;iii.基于针对ImageNet分类训练的VGGNet的感知损失;iv.具有判别器的对抗性损失。
由于感知损失涉及有监督的预训练网络,使用用这种损失训练的VQGAN是不合法的。相反,作者在其中消除了感知损失。使用这种tokenizer将线性探针的准确率从62.5%显著降低到58.4%(表1)。这种比较表明,用感知损失(带有类标签)训练的tokenizer本身提供了语义表示。
作者训练下一个VQGAN tokenizer,它可以进一步消除对抗性损失。它将线性探头的精度从58.4%略微提高到59.0%(表1)。tokenizer在这一点上本质上是一个VAE。还注意到,消除这两种损失都会损害生成质量。
替换噪声调度
在生成任务中,目标是逐步将噪声图转换为图像。因此,原始噪声调度在噪声很大的图像上花费了许多时间步长(图3)。如果模型不是面向生成的,那么这是没有必要的。
为了进行自监督学习,作者研究了一种更简单的噪声调度。具体来说,让 γ t 2 γ^{2}_{t} γt2在[0,1]的范围内线性衰减(图3)。这一变化大大提高了线性探头的精度,从59.0%提高到63.4%(表1),表明原始调度过于关注噪声较大的状态。另一方面,正如预期的那样,这样做会进一步损害生成能力,导致FID为93.2。
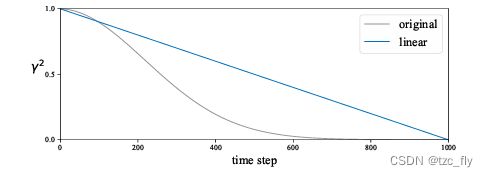
- 图3:原始调度器设置 γ t 2 = ∏ s = 1 t ( 1 − β s ) \gamma_{t}^{2}=\prod_{s=1}^{t}(1-\beta_{s}) γt2=∏s=1t(1−βs),如果使用线性调度器,可以减少step。让模型一开始就关注比较干净的数据,而不是纯纯的噪声。
总体而言,表1中的结果表明,自监督学习表现与生成质量无关。DDM的表示能力不一定是其生成能力的结果。
重构Tokenizer
接下来,通过进行实质性的简化来进一步解构VAE tokenizer。作者将以下四种自动编码器变体作为tokenizer进行比较,每种变体都是前一种的简化版本。
卷积VAE
到目前为止,解构被引导到VAE tokenizer,现在将VAE的编码器和解码器设置为卷积网络 f ( ⋅ ) f(\cdot) f(⋅)和 g ( ⋅ ) g(\cdot) g(⋅)。卷积VAE被如下损失最小化: ∣ ∣ x − g ( f ( x ) ) ∣ ∣ 2 + K L [ f ( x ) ∣ N ( 0 , I ) ] ||x-g(f(x))||^{2}+KL[f(x)|N(0,I)] ∣∣x−g(f(x))∣∣2+KL[f(x)∣N(0,I)]其中, x x x是VAE的输入图像。
Patch-wise VAE
接下来考虑简化情况,VAE的编码器和解码器都是线性投影,并且VAE的输入 x x x是一个patch,最小化损失为: ∣ ∣ x − U T V x ∣ ∣ 2 + K L [ V x ∣ N ( 0 , I ) ] ||x-U^{T}Vx||^{2}+KL[Vx|N(0,I)] ∣∣x−UTVx∣∣2+KL[Vx∣N(0,I)]这里, x x x表示flatten为 D D D维向量的patch。 U U U和 V V V都是 d × D d×D d×D矩阵,其中 d d d是潜在空间的维数。patch大小设置为16×16像素。
Patch-wise AE
作者通过去除正则化项对VAE进行进一步简化: ∣ ∣ x − U T V x ∣ ∣ 2 ||x-U^{T}Vx||^{2} ∣∣x−UTVx∣∣2因此,这个tokenizer本质上是patch上的自动编码器(AE),编码器和解码器都是线性投影。
Patch-wise PCA
最后,考虑一个更简单的变体,它在patch空间上执行主成分分析(PCA)。很容易证明PCA等效于AE的一个特殊情况: ∣ ∣ x − V T V x ∣ ∣ 2 ||x-V^{T}Vx||^{2} ∣∣x−VTVx∣∣2其中, V V V符合 V V T = I ∈ R d × d VV^{T}=I\in R^{d\times d} VVT=I∈Rd×d,PCA可以简单地通过在一大组随机采样的patch上进行特征分解来计算,不需要基于梯度的训练。
由于使用patch的简单性,对于三个patch tokenizer,我们可以在patch空间中可视化它们的滤波器(图4)。

- 图4:patch tokenizer的可视化。每个滤波器对应于线性投影矩阵 V : d × D V:d×D V:d×D的一行,为了可视化,将其整形为16×16×3。
表2总结了使用这四种tokenizer变体的DiT的线性探针准确性。作者展示了关于潜在维度“per token”的结果。PCA tokenizer的有效性在很大程度上将现代DDM推向经典DAE。
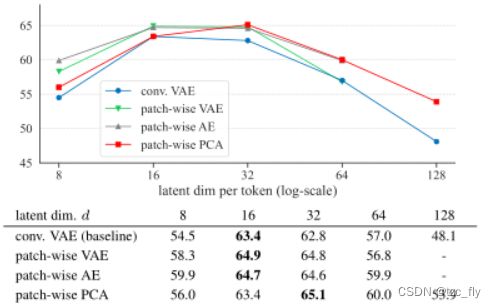
- 表2:线性探针精度与latent维度的权衡。利用DiT模型,作者研究了用于计算潜在空间的tokenizer的四种变体。作者改变潜在空间的维度 d d d(per token)。通过上面的图显示出来。尽管在体系结构和损失函数方面存在差异,但tokenizer的所有四种变体都表现出相似的趋势。
高分辨率、基于像素的DDM在自监督学习方面较差
在继续之前,报告了一个与上述观察结果一致的额外的消融实验。具体来说,考虑一种naive tokenizer,它对从resized image中提取的patch执行identity mapping。在这种情况下,token是由patch的所有像素组成的展平向量。在图5中,作者展示了这种“pixel-based” tokenizer的结果,该tokenizer分别对256、128、64和32的图像大小进行操作,patch大小为16、8、4、2。这些token化空间的“潜在”维度分别为768、192、48和12。在所有情况下,Transformer的序列长度都保持不变(256)。
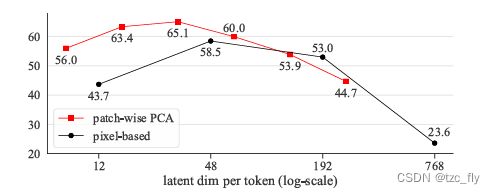
- 图5:pixel-based的tokenizer的线性探测结果,分别在256、128、64和32的图像大小上操作,补丁大小为16、8、4、2。这些token化空间的“潜在”维度分别为768、192、48和12。与之前研究的其他tokenizer类似,这种基于像素的标记器呈现出类似的趋势:相对较小的潜在空间维度是最优的。
这些比较表明,tokenizer和由此产生的潜在空间对于DDM或DAE在自监督学习场景中至关重要。特别是,在像素空间上应用具有加性高斯噪声的经典DAE会导致较差的结果。
走向经典的DAE
接下来,继续解构轨迹,目标是尽可能接近经典的DAE。作者试图消除当前基于PCA的DDM和经典DAE之间仍然存在的每一个方面。通过这个解构过程,作者更好地理解了每一个现代设计如何影响经典DAE。表3给出了下面讨论的结果。

- 表3:从Patch-wise PCA标记器开始,迈向经典DAE。每一行都基于对前一行的修改。
预测干净的数据(而不是噪声)
虽然现代DDM通常预测噪声 ε ε ε,但经典DAE预测的是干净数据。作者通过最小化以下损失函数来检验这种差异: λ t ∣ ∣ z 0 − n e t ( z t ) ∣ ∣ 2 \lambda_{t}||z_{0}-net(z_{t})||^{2} λt∣∣z0−net(zt)∣∣2其中, z 0 z_{0} z0是干净数据(latent空间中), λ t = γ t 2 \lambda_{t}=\gamma_{t}^{2} λt=γt2是基于 t t t的loss权重,为不同等级的噪声引入去噪贡献。直观地说,它只是对更干净的数据的损失项给予了更多的重视(large γ t 2 \gamma_{t}^{2} γt2)。
随着预测干净数据(而不是噪声)的修改,线性探头的精度从65.1%下降到62.4%(表3)。这表明预测目标的选择会影响表示质量。尽管在这一步中受到了下降影响,但从现在起,作者依然坚持这种修改,因为目标是向经典DAE迈进。
移除输入scaling
在现代DDM中,输入按 γ t γ_t γt因子缩放。这在传统DAE中并不常见。接下来,作者研究去除输入缩放因子,即设置 γ t = 1 γ_t=1 γt=1。由于 γ t γ_t γt是固定的,我们需要直接在 σ t σ_t σt上定义一个噪声调度。作者简单地将 σ t σ_t σt设置为从0到 2 \sqrt{2} 2的线性调度。此外,根据经验将等式中的权重设置为 λ t = 1 / ( 1 + σ t 2 ) λ_t=1/(1+σ^{2}_{t}) λt=1/(1+σt2)。此后获得了63.6%的准确率(表3),这有缩放的62.4%相比是有利的。这表明缩放数据是不必要的。
使用逆PCA对图像空间进行运算
到目前为止,对于探索过的所有条目,该模型在tokenizer产生的潜在空间上运行。理想情况下,作者希望可以直接在图像空间上工作,同时仍然具有良好的准确性。利用主成分分析,可以通过逆主成分分析来实现这一目标。这个想法如图1所示。特别地,通过PCA基(即 V V V)将输入图像投影到潜在空间中,在潜在空间中添加噪声,并通过逆PCA基( V T V^{T} VT)将带噪的潜在空间投影回图像空间。图1(底部)显示了在潜在空间中添加了噪声的示例图像。有了这个有噪声的图像作为网络的输入,我们可以应用直接对图像进行操作的标准ViT网络,就好像没有tokenizer一样。
进一步将其应用于输出侧(即,用逆PCA预测图像空间上的输出)具有63.9%的准确度。结果表明,用逆PCA在图像空间上操作可以获得与在潜在空间上操作类似的结果。
预测原始图像
虽然逆PCA可以在图像空间中产生预测目标,但该目标不是原始图像。这是因为PCA对于任何降维都是有损编码器。相比之下,直接预测原始图像是一种更自然的解决方案。当让网络预测原始图像时,引入的“噪声”包括两部分:i.加性高斯噪声,其固有维数为 d d d,ii.PCA重建误差,其固有维数为 D − d D−d D−d( D D D为768)。作者对这两部分的损失进行了不同的加权。
形式上,使用干净的原始图像 x 0 x_{0} x0和网络预测 n e t ( x t ) net(x_{t}) net(xt),可以计算投影到全PCA空间上的残差 r r r: r = V ( x 0 − n e t ( x t ) ) r=V(x_{0}-net(x_{t})) r=V(x0−net(xt)),这里 V V V是PCA基 D × D D\times D D×D。然后最小化: λ t ∑ i = 1 D w i r i 2 \lambda_{t}\sum_{i=1}^{D}w_{i}r_{i}^{2} λti=1∑Dwiri2其中, i i i表示向量 r r r的第 i i i维。 w i w_{i} wi对PCA重建误差的损失进行加权。采用该公式,预测原始图像的线性探头精度达到64.5%(表3)。
这个变体在概念上非常简单:它的输入是一个噪声图像,其噪声来自PCA潜在空间中,它的预测是原始的干净图像(图1)。
单级噪声
最后,出于好奇,作者进一步研究了具有单级噪声的变体。并注意到,由噪声调度给出的多级噪声是由DDM中的扩散过程驱动的;在传统DAE中,这在概念上是不必要的。
作者将噪声水平 σ σ σ固定为常数( 1 / 3 \sqrt{1/3} 1/3)。使用这种单级噪声实现了61.5%的良好精度,与多级噪声对应(64.5%)相比,降低了3%。使用多级别的噪声类似于DAE中的一种数据增强形式:这是有益的,但不是一个促成因素。这也意味着DDM的表示能力主要是通过去噪驱动过程获得的,而不是扩散驱动过程。
总结
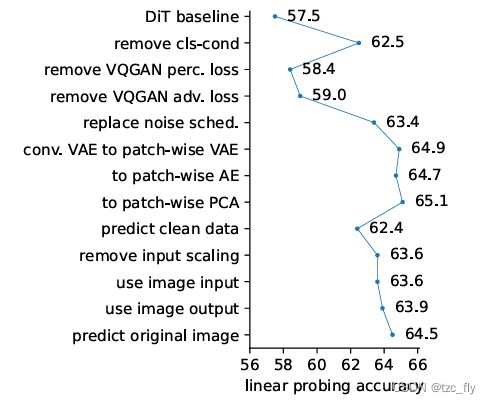
作者解构了现代DDM,并将其推向经典DAE(图6)。其中撤销了许多现代设计,在概念上只保留了从现代DDM继承的两种设计:i.添加了噪声的低维潜在空间;ii.多级噪声。作者使用表3末尾的条目作为最后的DAE实例化(如图1所示),并将这种方法称为“潜在去噪自动编码器”,简称l-DAE。
- 图6:从现代DDM到l-DAE的整体解构轨迹。每一行都基于对前一行的修改。