日常节省 30%计算资源:阿里云实时计算 Flink 自动调优实践
摘要:本文整理自阿里云开发工程师,Apache Flink Contributor 钟旭阳,在 Flink Forward Asia 2022 生产实践的分享。本篇内容主要分为四个部分:
- 历史背景
- 框架简介
- 案例介绍
- 未来规划
点击查看原文视频 & 演讲PPT
一、历史背景
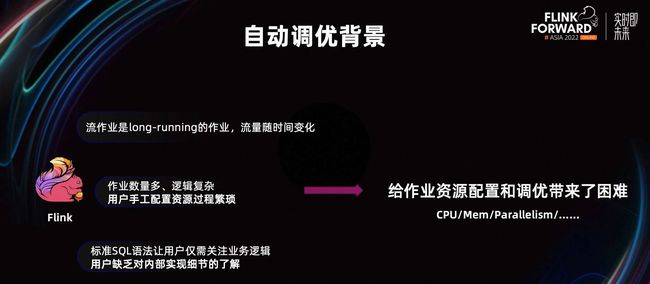
批作业在算子实际处理数据时,可以提前感知到要处理的这部分数据有多大。从而可以根据数据量的大小,选择合适的资源处理数据。但流作业是一种 long-running 的作业,它的特点是流量会随着时间进行变化。
我们没有办法在流作业刚启动时,就预估到未来的流量有多少,需要多少资源。没有一份初始的通用资源配置可以适用于一个流作业的所有场景。
并且,在通常情况下,用户需要维护许多的 Flink 作业,其中会有很多逻辑复杂、节点很多的作业。如果靠每个用户手工配置这些作业的资源配置,这一过程是比较繁琐的。对于每个用户来说,也是不太现实的。
同时,因为 Flink SQL 的广泛推广,用户只需要关心自己的业务逻辑,就能够使用 Flink 的能力。但也正是因为 Flink SQL 易用性,让用户缺乏对 Flink 内部实现细节的了解,调优成本会比较高。
综合以上的种种问题,给作业资源配置和调优带来一定的困难。

如果一份作业设置了不太合理的资源配置,在资源配置设置较高时,会增加业务的成本。从作业上看,资源的利用率会更低。在资源配置设置比较低的时候,会使整个作业的处理能力不足,导致作业出现吞吐比较低,延迟攀升的情况。在资源严重不足时,还会导致出现 Failover 的情况大大增加,从而影响整个作业的平稳运行。

我们期望作业自动调优的目标比较简单,即配置一份在保障作业无延迟的前提下,尽可能的提高作业整体的吞吐量,提高作业的资源利用率,让资源不再成为作业的瓶颈。
二、框架简介

在 2016 年,我们支持使用资源配置、文件配置的方式,为作业设置一些资源。当时作业以 DataStream 作业和 TableApi 作业为主。
我们通过提前预编译的方式,将每个节点的初始资源配置进行输出。让用户根据这份初始的资源配置,进行修改。然后,在提交作业运行时,通过参数,带上这份最新的配置,就可以让这份新配置生效。但是,由于作业资源存放在文件当中,我们很难将需要修改的节点,和实际使用运行的节点,建立起对应的关系。
对于大作业来说,它们的资源文件过于复杂。比如我需要调节 50 个节点中某个 AGG 的算子,但是该作业中 AGG 算子一共有四、五个。很难确认哪一个 AGG 算子,才是我们需要调整的那个算子。
因此,在 2017 年我们对其进行了改进,支持了可视化的配置。用户可以通过可视化的拓扑图,来修改指定的节点资源。它的好处是,映射关系会更加的清晰,用户修改起来会更加的简单方便。
随着 SQL 作业的广泛应用,在这个版本里我们也增加了对 SQL 作业的调优支持,来弥补社区不支持细粒度设置 SQL 作业每个算子资源配置的不足。但这个版本仍然存在一些问题,比如大作业的拓扑图仍然很复杂,用户定位任务瓶颈时,需要多次运行作业,不断地重试调节可能有问题的节点。
在 2018 年,我们支持了半自动配置 AutoConf。它的特点是,能够结合作业的历史运行情况,通过一系列的算法,计算出此次启动时,需要多少推荐资源。但是它的缺点也很明显,针对无历史运行记录的作业,第一份配置通常是比较保守的,需要用户经过多轮迭代启停才能最终确定一份比较合理的资源配置。
在 2019 年,我们支持了全自动的配置 AutoScale。它能够在作业运行时动态自适应的修改资源配置。这个版本基本不需要用户干预,它能够很好的支持改并存、改内存等修改资源配置的能力。但这个版本依然存在一些问题,由于 AutoScale 是运行在JM内部的,因此天然不支持一些类似动态启停、查看运行历史记录等等的运维需求,在 JM 异常时,调优也无法继续工作,同时也不支持修改拓扑等策略,版本升级比较依赖 Flink 自身的版本。
在 2020 年,推出了独立部署的调优服务 Autopilot。相比于它的前身,Autopilot 的调优服务会更加易用。用户可以在界面手动看到的调优历史,明确的知道 Autopilot 根据作业的哪些情况,做过哪些调整。整个流程对用户更加透明化。即使没有开启 Autopilot,也可以为每个用户的作业,提供一些辅助的调用信息,给用户手工调优带来一定的帮助。
在 Autopilot 中,我们支持了更加丰富的调优策略,例如 JM 的资源优化,动态拆迁 chain 优化作业等。

Autopilot 调优主要调节的资源配置分为以下两种,分别是基础模式和专家模式。
在基础模式中,用户可以统一配置 TM 的 CPU 和内存,以及作业并发度。对于所有算子而言,这些资源都是同构的,TM 数量取决于每个 TM 中,可以有多少的 Slot。基础模式的特点是,配置简单,适合每个节点资源差异比较小的作业。
在专家模式中,用户可以单独配置每个算子所需要的 CPU、内存、并发等等,高度定制化,各个算子的资源是异构的。使用专家模式可以更好的提高资源的利用率,满足作业高吞吐的需求,节省资源。适合每一个节点资源差异比较大的作业。

Autopilot 自动调优框架,主要有以下几个特点。
首先,它支持多个类型的 Flink 作业,Flink SQL 作业、DataStream 作业和 Python 作业,都可以使用 Autopilot 的调优能力。
其次,它支持多种运行模式。
在半自动模式下,我们支持定时调优,让用户指定不同的时间段,选择不同的资源配置运行。适合一些突出的流量高峰场景和低谷场景。
在全自动的模式下,我们细分了资源分析模式和自动调优模式。在资源分析模式下,Autopilot 仅给出建议,不会自动重启作业,适合一些不能启停作业的敏感时期,比如大促期间。自动调优模式将根据流量的变化,自适应的改变作业的资源结构,最大程度的帮用户解决成本问题,比较适合日常的作业运行。

Autopilot 调优的基本思路如下。
首先,我们会从 Flink 上采集当前作业的 Metrics,也会从一些其他的诊断系统,拿到一些作业的运行指标,进行分析。
然后,通过这些原始的指标分析,得到一些复合型指标。通过所有的指标生成多个带有资源配置优化方案的调优计划。在执行计划时,从众多的资源配置方案中,选择一份最紧急的或最优的方案,更新作业配置。
在更新作业配置时,会优先查看调优计划是不是满足热更新的要求。如果满足热更新要求,会调用 JM 的 Rest 接口更新作业。如果不满足条件,会用 backup 方案,让作业管理平台启停作业。

在采集分析 Metric 阶段,除了使用原始的 Metric 信息,例如 CPU 利用率,Slot 利用率,内存利用率,Source 的延迟等等,也会生成复合型 Metric。比如当前延迟是不是可以 catch up,当前数据的倾斜程度是不是很严重等等,从而生成不同资源配置的调优计划。
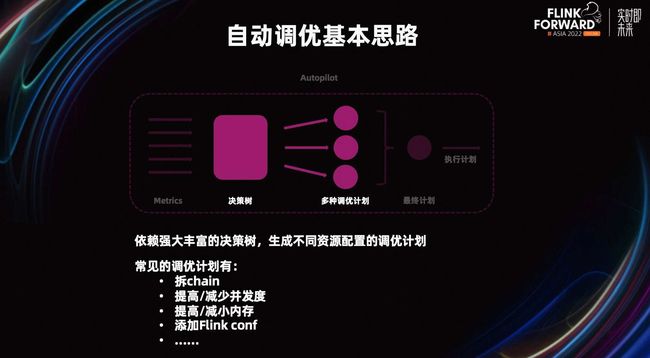
常见的调优计划分为以下几种:拆 chain、提高/减少并发度、提高/减少内存、添加 Flink conf 等等。最终,从多项调优计划中,选择一份最佳的计划执行。

目前,Autopilot 支持两种更新作业的方式。
- 热更新作业配置,它的好处是处理速度更快,重启的成本更低,但目前仅仅支持调节并发度。
- 调用管理平台,重启作业的 API。它的好处是可以支持所有的调优场景,来做一个最终的 backup。
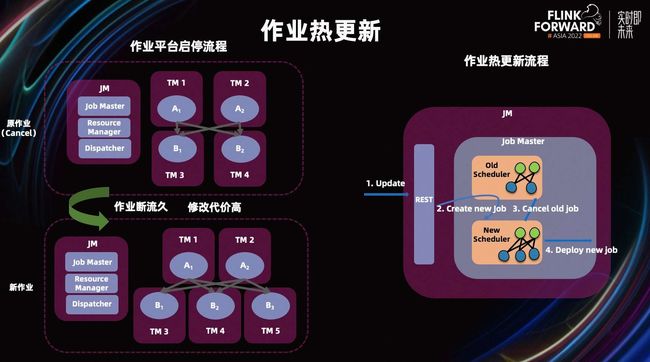
如上图所示,是作业平台启停流程和作业热更新流程。我们以修改并发度为例,在作业平台启停流程时,我们需要将原作业停止,然后提交新的作业。等待新的作业在 K8s 等平台上重新部署和运行。在整个流程中,作业断流的时间较长,修改带来的代价会比较高。
右图是作业热更新流程。我们通过 Rest 接收一份更新请求。然后,在 Job Master 里,基于当前作业修改生成新的作业,然后再停止老的作业,最终部署一份新的作业。相较于作业平台,热更新节省了启动初始化 Master 节点的时间,比作业平台启停,起停的成本更低。
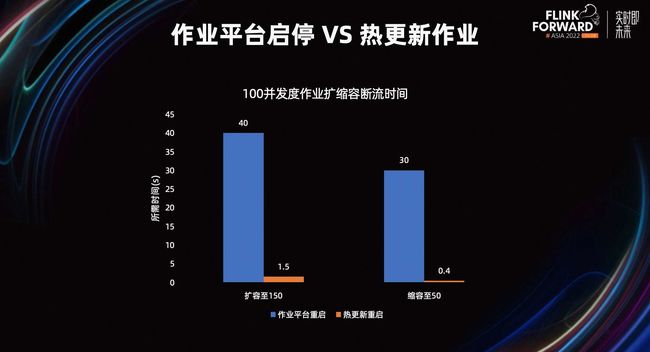
上图是 100 并发度作业扩缩容断流时间对比,在扩容到 150 并发度时,作业平台启动需要花费 40 秒左右,热更新重启只需要 1.5 秒左右。
在缩容到 50 并发度时,作为平台重启需要 30 秒左右,热更新重启仅需要花费 0.4 秒。
从这张图可以看到,热更新重启比调优作业平台重启,在重启时间上有更加明显的优势。从而能够最大限度的降低用户作业断流的风险,减少修改资源配置的成本。

潮汐流量是指流量的高峰和低谷,时间段具有周期性和可预见性。以电商平台每年的双十一活动为例,双十一时的配置和平时闲时的配置差异比较大。直播平台白天的配置,和晚上的配置差异也比较大。在这种流量高峰低谷的时间段比较明显,并且时间段比较固定的场景,应用定时策略会更加的简单高效。

定时策略主要针对自动调优无法覆盖的场景。在应用自动调优时,如果流量频繁抖动的化,最终会导致作业不断进行调用,从而使作业不断重启。
在流量变化比较慢的时候,由于作业在一段时间内,Autopilot 只感知到当前最高的流量。因此,可能会出现无法一次调优到位的情况,需要经过很多次迭代才会达到比较好的效果。
定时策略就是为了解决以上问题。它能够允许用户针对作业的业务特点,设置作业的最佳资源状态。在流量抖动比较频繁时,不会重启作业。当用户有一份流量在高峰或低谷时需要用多少资源配置的先验知识时,能够用定时调优一次性的将作业调到一个比较好的状态,也能够避开一些作业的敏感时期。

上图是定时调优的基本思路。Autopilot 在内部维护了多个资源配置的日历,当某个时间点需要触发定时策略,会选用该时间点的资源配置,更新作业配置。
这里的更新同样可以分为热更新和作业管理平台进行重启。Autopilot 也会自动检查新增或更新的定时策略时间是否和已有的定时策略时间冲突。
三、案例介绍
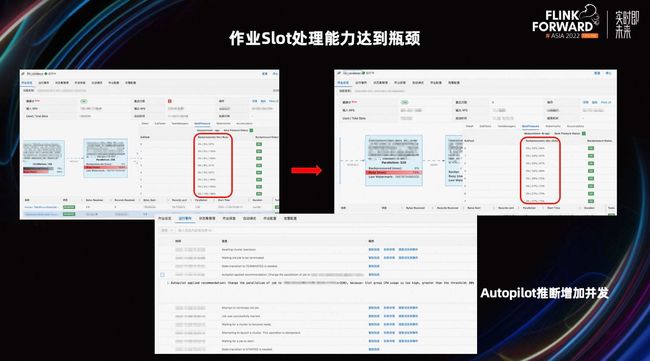
上图是作业 Slot 处理能力达到瓶颈的案例,可以看到在左图右边的节点上,该节点每个值都很高,基本上达到了百分百,表明当前 Slot 的利用率很高。如果作业长时间处于这种状态,会引起 Failover,影响作业的稳定性。前面的算子已经被该算子反压,导致延时会不断增加。
为了解决这个问题,Autopilot 将该算子的并发提高到 320。修改之后,出现了右图所示的情况,该算子的 Slot 利用率,降低到比较正常的水准。

上图是一个 TM 内存使用率过低的案例,可以看到用户在一开始申请了 4G 内存,但在实际作业中,TM 只使用了 1G 左右,造成了内存浪费。作业成本较高,白白花费了 3G 内存的钱。
Autopilot 识别到这种情况,将 TM 内存从 4G 降低到 1.6G,帮助用户降低了作业成本。之所以降到了 1.6G,是因为 Flink 侧有最低内存设定的限制。如果调优太低,会导致作业直接起不来。

上图是一个业务流量周期变化的案例,可以看到,左上角作业的 TPS 有一个先高、后低、再高的过程。下面部分是,Autopilot 识别到流量变化,自动调整了作业的并发度。
在流量低谷时,降低了整体并发度,因此需要的数量大大降低。在流量高峰时,出现延迟,重新进行扩容,保障高流量下作业的平稳运行。最终实现资源的弹性扩缩容,有效降低了资源的使用,节约成本的同时,提高了作业的稳定性。

上图是大促之后自动降低资源,节约成本的案例。在大促期间,作业一般会使用比较高额的资源。一般情况下,用户无法知道大促的流量什么时候结束,什么时候需要将作业资源配置,切换到较低的闲时状态。
如果我们切换的较早,会导致预判流量失误,造成较大的流量冲击作业,导致作业不稳定。如果切换较晚,会浪费过量的资源。Autopilot 辅助业务方在大促结束后,根据流量来平稳、并且快速降低作业使用的资源,节约成本。

上图是一个设定不同时间段的定时策略案例。我们可以设定早上 9 点到晚上 7 点,为业务的高峰期。在这段高峰期中,使用 30 并发度。在晚上 7 点到早上 9 点,为业务的低谷期,在这期间用 10 并发度。图中是具体设置资源和设置资源时间段的示意图。
四、未来规划

未来,Autopilot 的主要目标是,进一步帮助用户降本增效。Autopilot 将从三个角度不断努力。
首先,我们将致力于提高 Autopilot 的易用性,方便用户使用。我们将支持插件化的能力,允许用户自定义一些调优能力。比如自己排列组合一些 Metric,设定一些调优策略,来满足自身业务的需要。 增强外部集成的能力,开发提供 SDK 和 Open API 接口。
其次,我们将让 Autopilot 更加智能、更加专业。一个方向是,探索机器学习的一些策略,依靠现在成熟的机器学习算法,提前进行流量预测,并发预测等工作。另一个方向是,结合集群信息和上游依赖作业信息,进行调优。比如在流量高峰时,在上游的作业被自动调优的同时,下游被依赖的作业也可以顺势进行一定的自动调优。
最后,Autopilot 的稳定性是我们不断努力的方向。一方面,我们会持续的加强热更新的能力,让更多的调优计划支持热更新,减小重启带来的断流等较高的调优成本问题。另一方面,让 Autopilot 覆盖更多的场景来满足不同的作业 Pattern,让其更加全面,比如说 SQL 的写法本身就有问题,UDF 实现方式有问题,有较大的外部 IO、源表 Partition 数导致无法进一步调高并发度,维表或结果表性能不行等等的诸多问题。
点击查看原文视频 & 演讲PPT
更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
0 元试用 实时计算 Flink 版(5000CU*小时,3 个月内)
了解活动详情:阿里云免费试用 - 阿里云
