【旧文更新】【优秀毕设】人脸识别打卡/签到/考勤管理系统(OpenCV+最简基本库开发、可移植树莓派 扩展网络图像推流控制 验证码及Excel邮件发送等功能)
【旧文更新】【优秀毕设】人脸识别打卡/签到/考勤管理系统(OpenCV+最简基本库开发、可移植树莓派 扩展网络图像推流控制 验证码及Excel邮件发送等功能)
文章目录
- 关于旧文新发
- 毕设结构
-
- 主页面
- 验证码
- 识别效果
- 管理页面
- 人脸信息采集
- 管理
- 实时数据更新
- 签到结果
- 邮件发送
- 网络前端效果
- 实时图像推流
- 附录:列表的赋值类型和py打包
-
- 列表赋值
-
- BUG复现
- 代码改进
- 优化
- 总结
- py打包
- 附录:关于旧文新发
关于旧文新发
为何要进行旧文新发?
因为我在2023年博客之星评选中发现 有的人转载、抄袭他人文章 稍微改动几下也能作为高质量文章入选
所以我将把我的旧文重新发一次 然后也这样做
2023年博客之星规则:

毕设结构
该系统利用Harr级联检测和LPBH进行人脸检测和训练、识别
利用Tkinter完成界面搭建
利用Flask+HTML完成网络实时图像推流及控制
利用captcha.image 完成验证码功能
利用xlsxwriter将数据保存为Excel文档
利用email库发送邮件
功能如下图所示 所有功能均可实现
cv2版本: 推荐4.4.0.46 安装opencv-python和opencv-contrib-python
部分资源:
download.csdn.net/download/weixin_53403301/85545163
基础完整资源:
download.csdn.net/download/weixin_53403301/85744946
视频:
【优秀毕设开源】人脸识别打卡/签到/考勤管理系统(OpenCV+最简基本库反向开发、可移植树莓派 扩展网络图像推流控制 验证码及Excel邮件发送等功能)
【优秀毕设开源】基于OpenCV的人脸识别打卡/签到/考勤管理系统(最简基本库开发、可基于树莓派)
部分代码:
# -*- coding: utf-8 -*-
"""
Created on Mon May 31 23:39:19 2021
@author: ZHOU
"""
# -*- coding: utf-8 -*-
import tkinter as tk # 调用窗口tk
from tkinter import ttk
from tkinter.filedialog import askopenfilename
import tkinter.messagebox
from PIL import Image, ImageTk, ImageDraw, ImageFont # 调用图像处理库pillow
import cv2 # 调用OpenCV图像处理库
import threading # 调用threading多线程运行库
import time # 调用系统时间戳库
import os # 调用os多操作系统接口库
import re
import numpy as np
from captcha.image import ImageCaptcha
import random
import string
import xlsxwriter
import smtplib
import email.mime.multipart
import email.mime.text
from email.mime.application import MIMEApplication
from flask import Flask,render_template, request, Response
import socket
global network_flag
network_flag = 0
local_post = 1212
local_ip = None
for i in range(12):
try:
s = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
s.connect(("8.8.8.8",80))
local_ip = str(s.getsockname()[0])
s.close()
print("Network Enable")
network_flag = 1
break
except:
print("Network Error...")
network_flag = 0
time.sleep(5)
app = Flask(__name__)
star_pic_path = "./star.png"
pic_path = "./dataset"
train_path = "./trainer"
data_path = "./data"
train_nb_path = "/train_nb.txt"
train_time_path = "/train_time.txt"
name_id_path = "/name_id.txt"
email_set_path = "/email_set.txt"
admin_path = "/admin.txt"
yml_path = "/trainer.yml"
temp_path = "./temp"
save_path = "./save"
date_path = "/date.txt"
sign_in_mode_path = "/sign_in_mode.txt"
company_path = "/company.txt"
department_path = "/department.txt"
class_id_path = "/class_id.txt"
global today_temp_path
now_today = time.time()
today_temp_path = "/today_"+str(time.localtime(now_today).tm_year)+"_"+str(time.localtime(now_today).tm_mon)+"_"+str(time.localtime(now_today).tm_mday)+".txt"
cascadePath = "./cascade/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)
font = cv2.FONT_HERSHEY_SIMPLEX
recognizer = cv2.face.LBPHFaceRecognizer_create()
try:
recognizer.read(train_path+yml_path)
except:
print("缺失训练数据文件,请先训练数据")
cam_flag = 0
global img2
img2 = None
global img_flag
img_flag = 0
global login_flag
login_flag = 0
global doing_change_record_date_flag
doing_change_record_date_flag = 0
global auto_send_flag
auto_send_flag = 0
# -*- coding: utf-8 -*-
"""
Created on Mon Apr 25 23:25:45 2022
@author: 16016
"""
import xlsxwriter
import time
def txt_excel(filename):
fp = open(filename,encoding="utf-8")
x = 0
y = 0
lines = fp.readlines()
today_list = (lines[0].split("\n")[0]).split("-")
xls = xlsxwriter.Workbook('record_' + today_list[0]+"_"+today_list[1]+"_"+today_list[2] + '.xlsx')
sheet = xls.add_worksheet('record_' + today_list[0]+"_"+today_list[1]+"_"+today_list[2])
sheet.write(0,0,"姓名")
for j in lines:
for i in range(1,len(j.split('|'))):
item = j.split('|')[i].strip(' ')
sheet.write(x,y,item)
y += 1 # 另起一列
x += 1 # 另起一行
y = 0 # 初始成第一列
fp.close()
xls.close()
filename = './temp/today_2022_4_25.txt'
xlsname = './save/学生签到表'
txt_excel(filename)
<html>
<meta http-equiv="refresh" content="60">
<head>
<title>人脸识别签到管理系统</title>
</head>
<body>
<h1>人脸识别签到管理系统</h1>
<form action="/" method="post">
<p><input type="submit" style="font-size:50px" name="send" value="发送数据">
<input type="submit" style="font-size:50px" name="maul" value="刷新网页"></p>
<p>
<table>
{% for k,v in data_dict.items() %}
<tr>
<td>{{k}}</td>
<td>{{v[0]}}</td>
<td>{{v[1]}}</td>
<td>{{v[2]}}</td>
<td>{{v[3]}}</td>
<td>{{v[4]}}</td>
</tr>
{% endfor %}
</table>
</p>
<p><input type="submit" style="font-size:50px" name="update" value="更新记录日期">
<input type="submit" style="font-size:50px" name="back" value="回退记录日期"></p>
</form>
<img src="{{ url_for('video_feed') }}" height="520" style="float:left">
</body>
</html>
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 26 15:16:42 2022
@author: 16016
"""
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import smtplib
import email.mime.multipart
import email.mime.text
from email.mime.application import MIMEApplication
def send_email(file_path,smtp_host, smtp_port, sendAddr, password, recipientAddrs, subject='', content=''):
'''
:param smtp_host: 域名
:param smtp_port: 端口
:param sendAddr: 发送邮箱
:param password: 邮箱密码
:param recipientAddrs: 发送地址
:param subject: 标题
:param content: 内容
:return: 无
'''
msg = email.mime.multipart.MIMEMultipart()
msg['from'] = sendAddr
msg['to'] = recipientAddrs
msg['subject'] = subject
content = content
txt = email.mime.text.MIMEText(content, 'plain', 'utf-8')
msg.attach(txt)
if file_path != '':
# 添加附件地址
part = MIMEApplication(open(file_path, 'rb').read())
part.add_header('Content-Disposition', 'attachment', filename="name_id.xlsx") # 发送文件名称
msg.attach(part)
try:
smtpSSLClient = smtplib.SMTP_SSL(smtp_host, smtp_port) # 实例化一个SMTP_SSL对象
loginRes = smtpSSLClient.login(sendAddr, password) # 登录smtp服务器
print(f"登录结果:loginRes = {loginRes}") # loginRes = (235, b'Authentication successful')
if loginRes and loginRes[0] == 235:
print(f"登录成功,code = {loginRes[0]}")
smtpSSLClient.sendmail(sendAddr, recipientAddrs, str(msg))
print(f"mail has been send successfully. message:{str(msg)}")
smtpSSLClient.quit()
else:
print(f"登陆失败,code = {loginRes[0]}")
except Exception as e:
print(f"发送失败,Exception: e={e}")
try:
subject = 'Python 测试邮件'
content = '这是一封来自 Python 编写的测试邮件。'
send_email('','smtp.qq.com', 465, '', '', '', subject, content)
except Exception as err:
print(err)
主页面

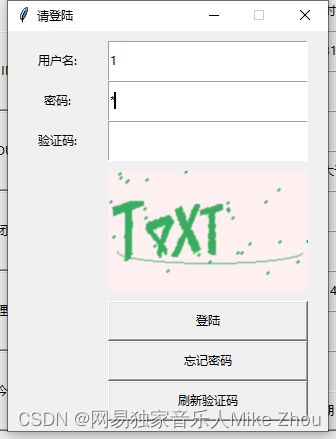
验证码
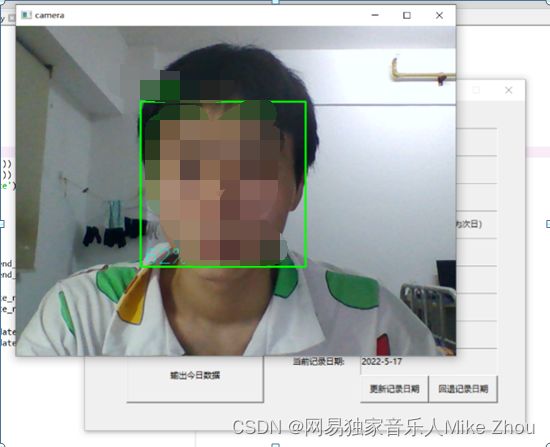
识别效果
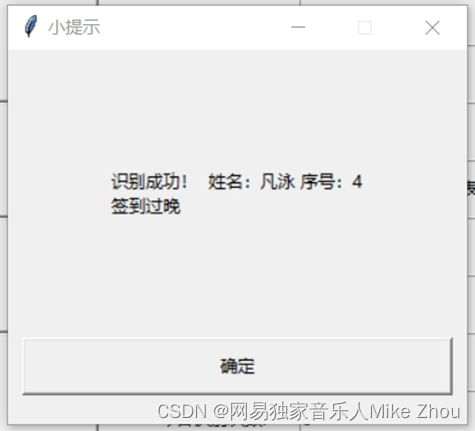
管理页面
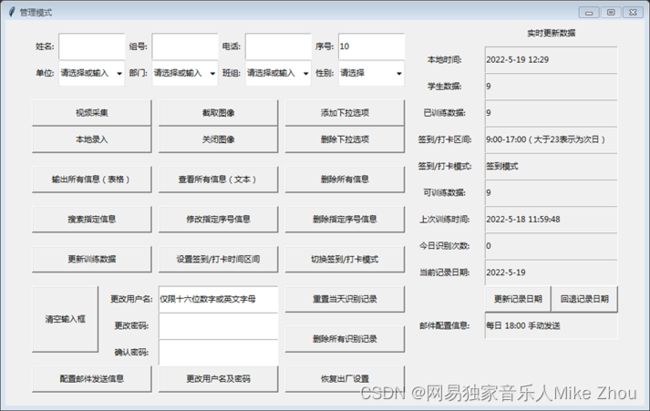
数据保存除了用户信息和签到信息外 还可以判断是否迟到、早退并计算工作时长
人脸信息采集

管理

实时数据更新

签到结果

邮件发送
网络前端效果
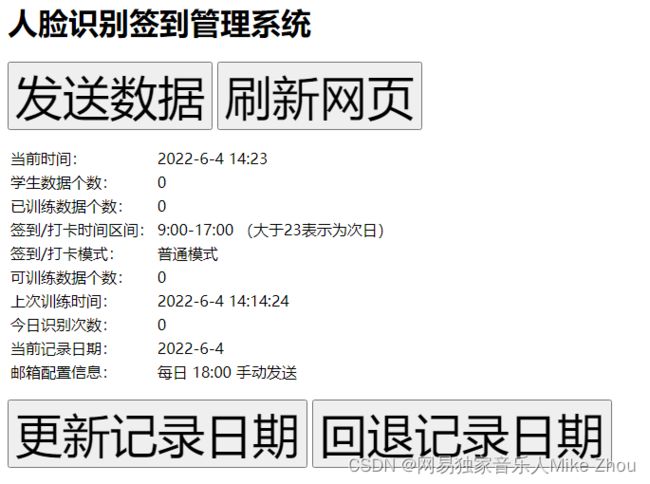
实时图像推流
(在识别时(IN/OUT功能)会推流到网络中 管理员通过IP地址可以实现监控效果)


附录:列表的赋值类型和py打包
列表赋值
BUG复现
闲来无事写了个小程序 代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
我在程序中 做了一个16次的for循环 把列表a的每个值后面依次加上"_"和循环序号
比如循环第x次 就是把第x位加上_x 这一位变成x_x 我在输出测试中 列表a的每一次输出也是对的
循环16次后列表a应该变成[‘0_0’, ‘1_1’, ‘2_2’, ‘3_3’, ‘4_4’, ‘5_5’, ‘6_6’, ‘7_7’, ‘8_8’, ‘9_9’, ‘10_10’, ‘11_11’, ‘12_12’, ‘13_13’, ‘14_14’, ‘15_15’] 这也是对的
同时 我将每一次循环时列表a的值 写入到空列表c中 比如第x次循环 就是把更改以后的列表a的值 写入到列表c的第x位
第0次循环后 c[0]的值应该是[‘0_0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘10’, ‘11’, ‘12’, ‘13’, ‘14’, ‘15’] 这也是对的
但是在第1次循环以后 c[0]的值就一直在变 变成了c[x]的值
相当于把c_list[0]变成了c_list[1]…以此类推 最后得出的列表c的值也是每一项完全一样
我不明白这是怎么回事
我的c[0]只在第0次循环时被赋值了 但是后面它的值跟着在改变
如图:

第一次老出bug 赋值以后 每次循环都改变c[0]的值 搞了半天都没搞出来
无论是用appen函数添加 还是用二维数组定义 或者增加第三个空数组来过渡 都无法解决
代码改进
后来在我华科同学的指导下 突然想到赋值可以赋的是个地址 地址里面的值一直变化 导致赋值也一直变化 于是用第二张图的循环套循环深度复制实现了
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
for i in range(16):
c_list[j].append(a_list[i])
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
print(c_list,'\n')
解决了问题

优化
第三次是请教了老师 用copy函数来赋真值
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list.copy()
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
同样能解决问题

最后得出问题 就是指针惹的祸!
a_list指向的是个地址 而不是值 a_list[i]指向的才是单个的值 copy()函数也是复制值而不是地址
如果这个用C语言来写 就直观一些了 难怪C语言是基础 光学Python不学C 遇到这样的问题就解决不了
C语言yyds Python是什么垃圾弱智语言
总结
由于Python无法单独定义一个值为指针或者独立的值 所以只能用列表来传送
只要赋值是指向一个列表整体的 那么就是指向的一个指针内存地址 解决方法只有一个 那就是将每个值深度复制赋值(子列表内的元素提取出来重新依次连接) 或者用copy函数单独赋值
如图测试:





部分代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 20 16:45:48 2021
@author: 16016
"""
def text1():
A=[1,2,3]
B=[[],[],[]]
for i in range(len(A)):
A[i]=A[i]+i
B[i]=A
print(B)
def text2():
A=[1,2,3]
B=[[],[],[]]
A[0]=A[0]+0
B[0]=A
print(B)
A[1]=A[1]+1
B[1]=A
print(B)
A[2]=A[2]+2
B[2]=A
print(B)
if __name__ == '__main__':
text1()
print('\n')
text2()
py打包
Pyinstaller打包exe(包括打包资源文件 绝不出错版)
依赖包及其对应的版本号
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py 打包exe
Pyinstaller -F -w setup.py 不带控制台的打包
Pyinstaller -F -i xx.ico setup.py 打包指定exe图标打包
打包exe参数说明:
-F:打包后只生成单个exe格式文件;
-D:默认选项,创建一个目录,包含exe文件以及大量依赖文件;
-c:默认选项,使用控制台(就是类似cmd的黑框);
-w:不使用控制台;
-p:添加搜索路径,让其找到对应的库;
-i:改变生成程序的icon图标。
如果要打包资源文件
则需要对代码中的路径进行转换处理
另外要注意的是 如果要打包资源文件 则py程序里面的路径要从./xxx/yy换成xxx/yy 并且进行路径转换
但如果不打包资源文件的话 最好路径还是用作./xxx/yy 并且不进行路径转换
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
而后再spec文件中的datas部分加入目录
如:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
而后直接Pyinstaller -F setup.spec即可
如果打包的文件过大则更改spec文件中的excludes 把不需要的库写进去(但是已经在环境中安装了的)就行
这些不要了的库在上一次编译时的shell里面输出
比如:


然后用pyinstaller --clean -F 某某.spec
附录:关于旧文新发
为何要进行旧文新发?
因为我在2023年博客之星评选中发现 有的人转载、抄袭他人文章 稍微改动几下也能作为高质量文章入选
所以我将把我的旧文重新发一次 然后也这样做
2023年博客之星规则: