用Lucene写的一个HelloWorld
下面是今天初次看的一点Lucene,整理出笔记备忘~~
下载这个文件lucene-2.4.0.zip到任意目录并解压,得到lucene-core-2.4.0.jar。
这里有Lucene的API:http://hudson.zones.apache.org/hudson/job/Lucene-trunk/javadoc//index.html
注意:Lucene 2.0以上使用的JDK版本不能低于1.5.0。
在My Eclipse建立一个Java Project,可命名为"Hello Lucene"。
设置Project->Properties->Java Compiler, 选中"Enable project specific settings"。
在项目中建立一个Package,命名为"test",并添加一个名为"HelloWorld.java"的Class。
在项目中新建Folder,命名为lib。把lucene-core-2.4.0.jar用鼠标拖到lib中。
设置Project->Properties->Java Build Path,在Library选项卡中单击"Add JARs"按钮,把项目中的lucene-core-2.4.0.jar添加进去。使用项目内部的lucene-core-2.4.0.jar 就不用担心外部环境变量的影响了。
然后编写HelloWorld.java (直接拷贝代码了……)
1
 package
test;
package
test;
2
3
import
java.io.BufferedReader;
4
import
java.io.File;
5
import
java.io.FileReader;
6
import
java.io.IOException;
7
import
java.io.InputStreamReader;
8
import
java.io.Reader;
9
import
java.util.Date;
10
11
import
org.apache.lucene.analysis.Analyzer;
12
import
org.apache.lucene.analysis.standard.StandardAnalyzer;
13
import
org.apache.lucene.document.Document;
14
import
org.apache.lucene.document.Field;
15
import
org.apache.lucene.index.CorruptIndexException;
16
import
org.apache.lucene.index.IndexWriter;
17
import
org.apache.lucene.index.Term;
18
import
org.apache.lucene.queryParser.ParseException;
19
import
org.apache.lucene.queryParser.QueryParser;
20
import
org.apache.lucene.search.BooleanClause;
21
import
org.apache.lucene.search.BooleanQuery;
22
import
org.apache.lucene.search.IndexSearcher;
23
import
org.apache.lucene.search.PhraseQuery;
24
import
org.apache.lucene.search.Query;
25
import
org.apache.lucene.search.ScoreDoc;
26
import
org.apache.lucene.search.TermQuery;
27
import
org.apache.lucene.search.TopDocCollector;
28
import
org.apache.lucene.search.WildcardQuery;
29
import
org.apache.lucene.store.FSDirectory;
30
import
org.apache.lucene.store.LockObtainFailedException;
31
32 /**
/**
33 * @version Lucene 2.4.0
* @version Lucene 2.4.0
34 * @author hj
35 * @date 2009.1.8
36 * @see http://www.ibm.com/developerworks/cn/java/j-lo-lucene1/
37 * @see http://blog.chinaunix.net/u/8780/showart_396199.html
38 * @see Lucene视频教程.rar
39 * (shortcut key to add package: ctrl+shift+m)
40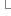 */
*/
41
public
class
HelloWorld
{
42
43 private String path = "D:/index";
44
45 /**
/**
46 * create index for strings
47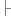 */
*/
48 private void createIndex(){
49
50 IndexWriter writer;
51 try {
52 writer = new IndexWriter(path,new StandardAnalyzer(),true,IndexWriter.MaxFieldLength.UNLIMITED);
53 Document docA = new Document();
54 Field fieldA = new Field("content","搜索引擎",Field.Store.YES,Field.Index.ANALYZED);
55 docA.add(fieldA);
56
57 Document docB = new Document();
58 Field fieldB = new Field("content","建立索引",Field.Store.YES,Field.Index.ANALYZED);
59 docB.add(fieldB);
60
61 writer.addDocument(docA);
62 writer.addDocument(docB);
63 writer.optimize();
64 writer.close();
65
66 } catch (Exception e) {
67 // TODO Auto-generated catch block
68 e.printStackTrace();
69 }
70
71 }
72
73 /**
74 * create a WildcardQuery term
75 * @return Query
76 */
77 private Query wildcardQuery(){
78 Term term = new Term("content","搜");
79 return new WildcardQuery(term);
80 }
81
82 /**
83 * create a PhraseQuery term
84 * @return Query
85 */
86 private Query phraseQuery(){
87 PhraseQuery phraseQuery = new PhraseQuery();
88 phraseQuery.setSlop(2);
89 phraseQuery.add(new Term("content","搜"));
90 phraseQuery.add(new Term("content","擎"));
91 return phraseQuery;
92 }
93
94 /**
95 * create a BooleanQuery term
96 * @return Query
97 */
98 private Query booleanQuery(){
99 Term term1 = new Term("content","搜");
100 Term term2 = new Term("content","引");
101
102 TermQuery termQuery1 = new TermQuery(term1);
103 TermQuery termQuery2 = new TermQuery(term2);
104
105 BooleanQuery booleanQuery = new BooleanQuery();
106 booleanQuery.add(termQuery1,BooleanClause.Occur.SHOULD);
107 booleanQuery.add(termQuery2,BooleanClause.Occur.SHOULD);
108
109 return booleanQuery;
110 }
111
112 private Query queryParser(){
113 QueryParser queryParser = new QueryParser("content",new StandardAnalyzer());
114 try {
115 return queryParser.parse("搜索 擎");
116 } catch (ParseException e) {
117 // TODO Auto-generated catch block
118 e.printStackTrace();
119 }
120 return null;
121 }
122
123 /**
124 * search method
125 */
126 private void search(){
127 try {
128 IndexSearcher searcher = new IndexSearcher(path);
129 //Query query= wildcardQuery();
130 //Query query = phraseQuery();;
131 //Query query = booleanQuery();
132 Query query = queryParser();
133 TopDocCollector collector = new TopDocCollector(10);
134 searcher.search(query,collector);
135 ScoreDoc[] hits = collector.topDocs().scoreDocs;
136 //Hits hits = searcher.search(query);
137
138 Document doc;
139 for(int i=0;i<hits.length;i++){
140
141 System.out.println(hits[i].doc);
142 System.out.println(hits[i].score);
143
144 doc = searcher.doc(hits[i].doc);
145 System.out.println(doc.toString());
146 }
147
148 } catch (Exception e) {
149 // TODO Auto-generated catch block
150 e.printStackTrace();
151 }
152 }
153
154 /**
155 * create index for *.txt
156 */
157 private void TxtFileIndexer() {
158 //indexDir is the directory that hosts Lucene's index files
159 File indexDir = new File(path);
160 //dataDir is the directory that hosts the text files that to be indexed
161 File dataDir = new File(path);
162 Analyzer luceneAnalyzer = new StandardAnalyzer();
163 File[] dataFiles = dataDir.listFiles();
164 IndexWriter writer;
165 try {
166 writer = new IndexWriter(indexDir,luceneAnalyzer,true,IndexWriter.MaxFieldLength.UNLIMITED);
167
168 long startTime = new Date().getTime();
169
170 for(int i=0;i<dataFiles.length;i++){
171 if(dataFiles[i].isFile() && dataFiles[i].getName().endsWith(".txt")){
172 System.out.println("Indexing file " + dataFiles[i].getCanonicalPath());
173
174 Document doc = new Document();
175 Reader txtReader = new FileReader(dataFiles[i]);
176 //document.add(Field.Text("path",dataFiles[i].getCanonicalPath()));
177 //document.add(Field.Text("contents",txtReader));
178 doc.add(new Field("path",dataFiles[i].getCanonicalPath(),Field.Store.YES,Field.Index.ANALYZED));
179 doc.add(new Field("contents",txtReader));
180 writer.addDocument(doc);
181
182 }
183 }
184 writer.optimize();
185 writer.close();
186 long endTime = new Date().getTime();
187
188 System.out.println("It takes " + (endTime - startTime) + " milliseconds to create index for the text files in directory " + dataDir.getPath());
189 } catch (Exception e) {
190 // TODO Auto-generated catch block
191 e.printStackTrace();
192 }
193 }
194
195 /**
196 * search method with a parameter
197 * @param keywords
198 */
199 private void TxtFileSearcher(String keywords){
200 try{
201 FSDirectory directory = FSDirectory.getDirectory(path);
202 IndexSearcher searcher = new IndexSearcher(directory);
203
204 Term term = new Term("contents",keywords);
205 TermQuery termQuery = new TermQuery(term);
206
207 TopDocCollector collector = new TopDocCollector(10);
208 searcher.search(termQuery,collector);
209 ScoreDoc[] hits = collector.topDocs().scoreDocs;
210
211 System.out.println("共有" + searcher.maxDoc()+"条索引,命中" + hits.length + "条");
212
213 int docId;
214 Document doc;
215 for(int i=0;i<hits.length;i++){
216 docId = hits[i].doc;
217 System.out.println(docId);
218 //System.out.println(hits[i].score);
219 doc = searcher.doc(docId);
220 System.out.println(doc.toString());
221 }
222 }catch(Exception e){
223 e.printStackTrace();
224 }
225 }
226
227 public static void main(String[] args) {
228/*
229 System.out.println("请输入要查找的关键字,例如shinhwa:");
230 BufferedReader stdin = new BufferedReader(new InputStreamReader(System.in));
231
232 String keywords = new String();
233 try {
234 keywords = stdin.readLine();
235
236 HelloWorld hw = new HelloWorld();
237
238 hw.TxtFileSearcher(keywords);
239 } catch (IOException e) {
240 // TODO Auto-generated catch block
241 e.printStackTrace();
242 }
243*/
244 HelloWorld hw = new HelloWorld();
245 hw.createIndex();
246 hw.search();
247 }
248}
249
250
251
package
test;2
3
import
java.io.BufferedReader;4
import
java.io.File;5
import
java.io.FileReader;6
import
java.io.IOException;7
import
java.io.InputStreamReader;8
import
java.io.Reader;9
import
java.util.Date;10
11
import
org.apache.lucene.analysis.Analyzer;12
import
org.apache.lucene.analysis.standard.StandardAnalyzer;13
import
org.apache.lucene.document.Document;14
import
org.apache.lucene.document.Field;15
import
org.apache.lucene.index.CorruptIndexException;16
import
org.apache.lucene.index.IndexWriter;17
import
org.apache.lucene.index.Term;18
import
org.apache.lucene.queryParser.ParseException;19
import
org.apache.lucene.queryParser.QueryParser;20
import
org.apache.lucene.search.BooleanClause;21
import
org.apache.lucene.search.BooleanQuery;22
import
org.apache.lucene.search.IndexSearcher;23
import
org.apache.lucene.search.PhraseQuery;24
import
org.apache.lucene.search.Query;25
import
org.apache.lucene.search.ScoreDoc;26
import
org.apache.lucene.search.TermQuery;27
import
org.apache.lucene.search.TopDocCollector;28
import
org.apache.lucene.search.WildcardQuery;29
import
org.apache.lucene.store.FSDirectory;30
import
org.apache.lucene.store.LockObtainFailedException;31
32
/**
33
* @version Lucene 2.4.034
* @author hj35
* @date 2009.1.836
* @see http://www.ibm.com/developerworks/cn/java/j-lo-lucene1/37
* @see http://blog.chinaunix.net/u/8780/showart_396199.html38
* @see Lucene视频教程.rar39
* (shortcut key to add package: ctrl+shift+m)40
*/
41
public
class
HelloWorld
{
42
43
private String path = "D:/index";44
45
/**
46
* create index for strings47
*/48
private void createIndex(){49
50
IndexWriter writer;51
try {52
writer = new IndexWriter(path,new StandardAnalyzer(),true,IndexWriter.MaxFieldLength.UNLIMITED);53
Document docA = new Document();54
Field fieldA = new Field("content","搜索引擎",Field.Store.YES,Field.Index.ANALYZED);55
docA.add(fieldA);56
57
Document docB = new Document();58
Field fieldB = new Field("content","建立索引",Field.Store.YES,Field.Index.ANALYZED);59
docB.add(fieldB);60
61
writer.addDocument(docA);62
writer.addDocument(docB);63
writer.optimize();64
writer.close();65
66
} catch (Exception e) {67
// TODO Auto-generated catch block68
e.printStackTrace();69
} 70
71
}72
73
/**74
* create a WildcardQuery term75
* @return Query76
*/77
private Query wildcardQuery(){78
Term term = new Term("content","搜");79
return new WildcardQuery(term); 80
}81
82
/**83
* create a PhraseQuery term84
* @return Query85
*/86
private Query phraseQuery(){87
PhraseQuery phraseQuery = new PhraseQuery();88
phraseQuery.setSlop(2);89
phraseQuery.add(new Term("content","搜"));90
phraseQuery.add(new Term("content","擎"));91
return phraseQuery;92
}93
94
/**95
* create a BooleanQuery term96
* @return Query97
*/98
private Query booleanQuery(){99
Term term1 = new Term("content","搜");100
Term term2 = new Term("content","引");101
102
TermQuery termQuery1 = new TermQuery(term1);103
TermQuery termQuery2 = new TermQuery(term2);104
105
BooleanQuery booleanQuery = new BooleanQuery();106
booleanQuery.add(termQuery1,BooleanClause.Occur.SHOULD);107
booleanQuery.add(termQuery2,BooleanClause.Occur.SHOULD);108
109
return booleanQuery;110
}111
112
private Query queryParser(){113
QueryParser queryParser = new QueryParser("content",new StandardAnalyzer());114
try {115
return queryParser.parse("搜索 擎");116
} catch (ParseException e) {117
// TODO Auto-generated catch block118
e.printStackTrace();119
}120
return null; 121
}122
123
/**124
* search method125
*/126
private void search(){127
try {128
IndexSearcher searcher = new IndexSearcher(path);129
//Query query= wildcardQuery();130
//Query query = phraseQuery();;131
//Query query = booleanQuery();132
Query query = queryParser();133
TopDocCollector collector = new TopDocCollector(10);134
searcher.search(query,collector);135
ScoreDoc[] hits = collector.topDocs().scoreDocs;136
//Hits hits = searcher.search(query);137
138
Document doc;139
for(int i=0;i<hits.length;i++){140
141
System.out.println(hits[i].doc);142
System.out.println(hits[i].score);143
144
doc = searcher.doc(hits[i].doc);145
System.out.println(doc.toString());146
}147
148
} catch (Exception e) {149
// TODO Auto-generated catch block150
e.printStackTrace();151
} 152
}153
154
/**155
* create index for *.txt156
*/157
private void TxtFileIndexer() {158
//indexDir is the directory that hosts Lucene's index files159
File indexDir = new File(path);160
//dataDir is the directory that hosts the text files that to be indexed161
File dataDir = new File(path);162
Analyzer luceneAnalyzer = new StandardAnalyzer();163
File[] dataFiles = dataDir.listFiles();164
IndexWriter writer;165
try {166
writer = new IndexWriter(indexDir,luceneAnalyzer,true,IndexWriter.MaxFieldLength.UNLIMITED);167
168
long startTime = new Date().getTime();169
170
for(int i=0;i<dataFiles.length;i++){171
if(dataFiles[i].isFile() && dataFiles[i].getName().endsWith(".txt")){172
System.out.println("Indexing file " + dataFiles[i].getCanonicalPath());173
174
Document doc = new Document();175
Reader txtReader = new FileReader(dataFiles[i]);176
//document.add(Field.Text("path",dataFiles[i].getCanonicalPath()));177
//document.add(Field.Text("contents",txtReader));178
doc.add(new Field("path",dataFiles[i].getCanonicalPath(),Field.Store.YES,Field.Index.ANALYZED));179
doc.add(new Field("contents",txtReader));180
writer.addDocument(doc);181
182
} 183
}184
writer.optimize();185
writer.close();186
long endTime = new Date().getTime();187
188
System.out.println("It takes " + (endTime - startTime) + " milliseconds to create index for the text files in directory " + dataDir.getPath());189
} catch (Exception e) {190
// TODO Auto-generated catch block191
e.printStackTrace();192
}193
}194
195
/**196
* search method with a parameter197
* @param keywords198
*/199
private void TxtFileSearcher(String keywords){200
try{201
FSDirectory directory = FSDirectory.getDirectory(path);202
IndexSearcher searcher = new IndexSearcher(directory);203
204
Term term = new Term("contents",keywords);205
TermQuery termQuery = new TermQuery(term);206
207
TopDocCollector collector = new TopDocCollector(10);208
searcher.search(termQuery,collector); 209
ScoreDoc[] hits = collector.topDocs().scoreDocs;210
211
System.out.println("共有" + searcher.maxDoc()+"条索引,命中" + hits.length + "条");212
213
int docId;214
Document doc;215
for(int i=0;i<hits.length;i++){216
docId = hits[i].doc;217
System.out.println(docId);218
//System.out.println(hits[i].score);219
doc = searcher.doc(docId);220
System.out.println(doc.toString());221
} 222
}catch(Exception e){223
e.printStackTrace();224
} 225
}226
227
public static void main(String[] args) {228
/*229
System.out.println("请输入要查找的关键字,例如shinhwa:");230
BufferedReader stdin = new BufferedReader(new InputStreamReader(System.in));231
232
String keywords = new String();233
try {234
keywords = stdin.readLine();235
236
HelloWorld hw = new HelloWorld();237
238
hw.TxtFileSearcher(keywords); 239
} catch (IOException e) {240
// TODO Auto-generated catch block241
e.printStackTrace();242
} 243
*/ 244
HelloWorld hw = new HelloWorld();245
hw.createIndex();246
hw.search(); 247
}248
}
249
250
251
不同版本的Lucene支持的函数不同,写的时候需要根据版本修改一下。这个小例子没实现什么功能了。默认情况下中文被分成单个字。TermQuery是以字或单词为单位搜索,WildcardQuery是使用正则表达式匹配,可在单词内部进行深度优先搜索。