Using JDO 2.0: JDOQL Part II
Welcome to Part II of my four-part series on JDOQL. The articles in this series illustrate the new capabilities which the forthcoming JDO 2.0 standard is bringing to JDOQL.
The series is comprised of:
JDOQL Part I -New operator and method support, paging of query results, and datastore-delegated "deletion by query".
JDOQL Part II -Projection, aggregation and the grouping ad de-duplication (making distinct) of query results.
JDOQL Part III -A new single-string representation of JDOQL, along with implicit parameter and variable definitions for more concise queries.
JDOQL Part IV -Using SQL as a query language - power at the expense of tight coupling between your code and the database schema.
This particular article uses the separately discussed domain object model and data set forHammer.org - The Online Auction Domain. Here is a quick link to theUML diagramfor the persistent domain.
Other useful resources include SolarMetric's 2-pageJDOQL 2.0 Quick Referenceand the unprintablePDF Editionof my own book, Java Data Objects (Addison-Wesley).
Selecting Winning Bids as Data not Objects - Projection
In JDO 1.0 all queries returned collections of persistent instances. For example, a query over the AuctionItem extent would return a Collection of actual AuctionItem instances which matched the filter criteria. In most cases this is what you want. JDO handles the mapping between the in-memory objects and their database representation; your application has at its disposal real objects and their inherent behaviour.
However, in certain use-cases the application doesn't care about real objects. All that might be wanted is access to the persistent data, and a simple data structure might be preferable to an object from which that same data must then be extracted.
Consider a requirement to select all AuctionItems for which the winning bid is greater than the reserve price, and then to extract the title, reserve price, winning bid amount and the name of the bidder for display to the user (perhaps through JSP, perhaps through Swing, etc).
JDOQL (#17) without projection -kodo workbench screenshot
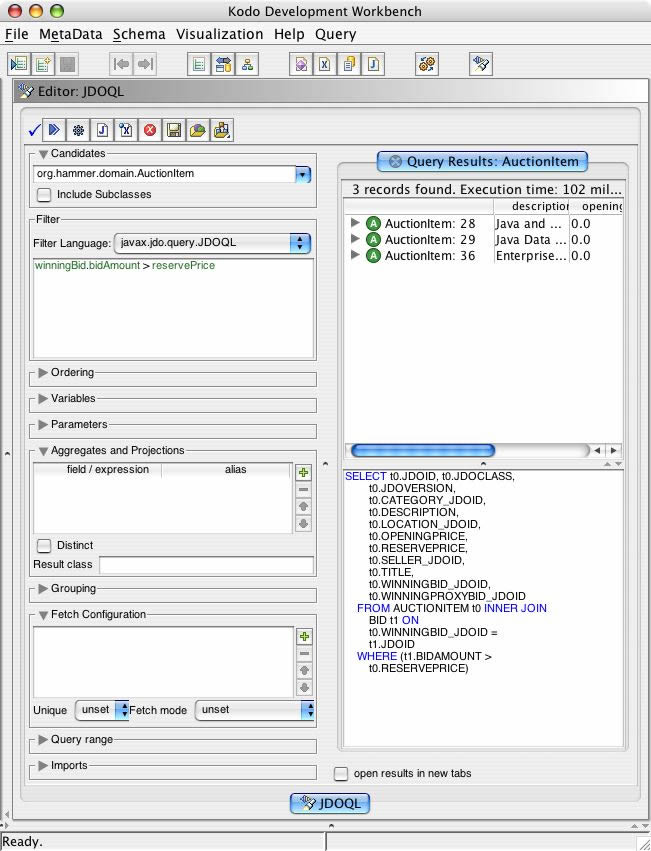{kind=link}
Without using JDO 2.0's new projection feature, this is how it might have been achieved:
Query q = pm.newQuery (AuctionItem.class, "winningBid.bidAmount >
reservePrice");
Collection results = (Collection) q.execute ();
Collection data = new ArrayList();
Iterator iter = results.iterator();
while (iter.hasNext()) {
AuctionItem item = (AuctionItem) iter.next();
Object[] row = new Object[4];
row[0] = item.getTitle();
row[1] = item.getReservePrice();
row[2] = item.getWinningBid().getBidAmount();
row[3] = item.getWinningBid().getBidder().getUser().getUserName();
data.add(row);
}
At the end of the iteration, the application has programmatically achieved a Collection of 4-element Object[]s, each with four data items that have been retrieved from the appropriate AuctionItem and its collaborating objects. However the result is arduous to code, and not necessarily efficient to execute.
JDOQL (#18) with projection - kodo workbench screenshot
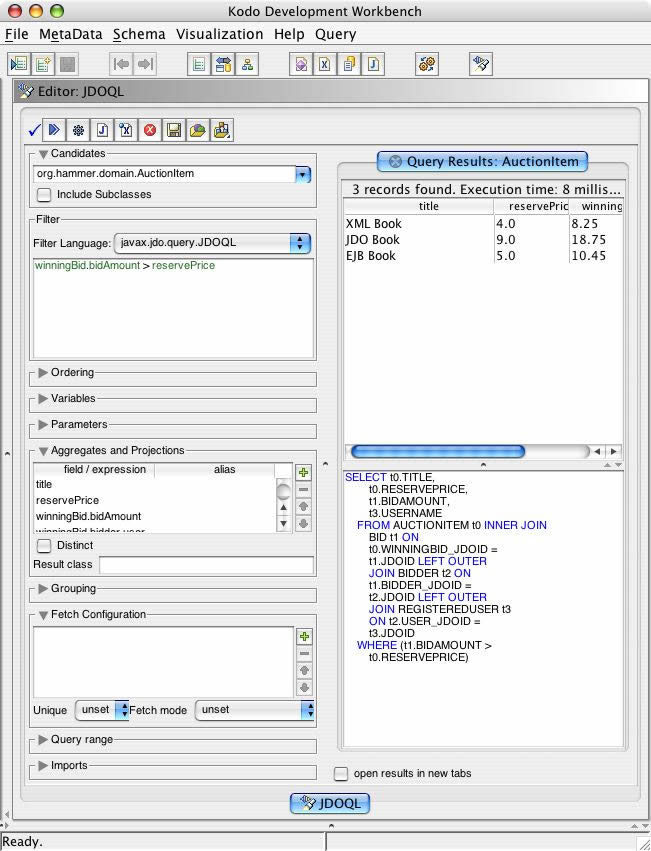{kind=link}
JDO 2.0 addresses this requirement by supporting projection, which is represented by the "result" clause of a Query. The result clause is a comma-delimited list of field expressions, which might be persistent fields of the candidate class or fields of other classes reachable from the candidate class. The keyword "this" can be used to refer to the matching instance itself. Access to persistent object ids is provided through the JDOHelper.getObjectId() method.
Query q = pm.newQuery (AuctionItem.class, "winningBid.bidAmount >
reservePrice");
q.setResult ("title, reservePrice, winningBid.bidAmount,
winningBid.bidder.user.userName");
Collection results = (Collection)q.execute ();
Results
The results of the two code snippets are identical, in both structure and contents, but the version which exploits the result clause for projection is much simpler to write and can more easily be implemented efficiently.
| title | reservePrice | bidAmount | userName |
| XML Book | 4.00 | 8.25 | Jaques |
| JDO Book | 9.00 | 18.75 | Sophie |
| EJB Book | 5.00 | 10.45 | David |
To Project Or Not To Project
JDO is an object-relational mapping technology. As such it abstracts developers from much of the of composing objects from field-level data, and of decomposing objects back into field-level data. Projection allows users selectively to bypass this functionality.
Each projected field may be of a simple type (data) or of a persistence-capable type (objects). When a persistence-capable type is part of a projection JDO continues to manage the projected object. The code snippet below includes a RegisteredUser object in the projection instead of just the RegisteredUser's name field value:
About Object IDs
Returning tabular data structures to a client or for display through a JSP is very powerful. However, occasionally the client needs to know the Object ID for each row, so that the correct ID can be used in subsequent requests. For instance, a Swing client might display the JTable of auction items, allowing the user to select one for a more detailed enquiry. The subsequent enquiry can be more efficiently satisfied if the client passes back the corresponding Object ID. To facilitate this the Object IDs must have been part of the data structure which the client received.
q.setResult ("title, reservePrice, winningBid.bidAmount,
winningBid.bidder.user");
So, when should one project field-level data and when should one project persistence-capable object types?
DOproject field-level data when:
- the data will be used but not altered, typically when the values are to be sent outside the JDO tier for read-only (display-only) purposes.
DO NOTproject field-level data when:
- you would have to constitute objects (analogous to the persistence-capable classes) from this field-level data;consider detachment instead of projection.
- you need to change the data and have those changes synchronized in the database; project persistence-capable objects instead and let JDO do the hard work for you.
- you intend merely to dictate fetch patterns for queries;use the JDO 2.0 fetch plan capability instead.
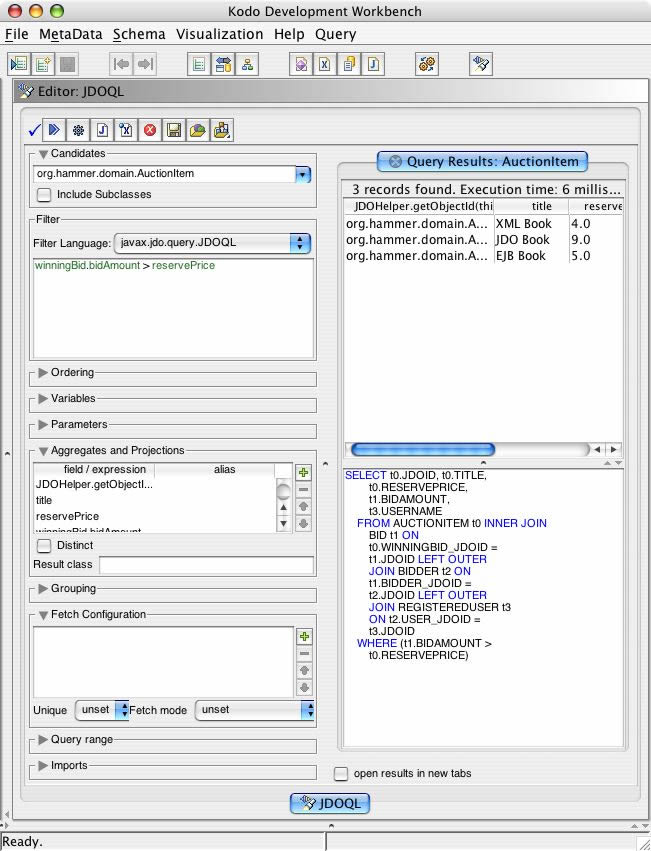{kind=link}
Object IDs can be included in projected results by using the JDOHelper.getObjectId() method in the result clause itself, as illustrated by the example below.
Query q = pm.newQuery (AuctionItem.class, "winningBid.bidAmount >
reservePrice");
q.setResult ("JDOHelper.getObjectId(this), title,
reservePrice, winningBid.bidAmount, winningBid.bidder.user.userName");
Collection results = (Collection)q.execute ();
Results
The results now include the Object ID for each selected auction item.
| Object ID | title | reservePrice | bidAmount | userName |
| org.hammer.domain.AuctionItem-39 | XML Book | 4.00 | 8.25 | Jaques |
| org.hammer.domain.AuctionItem-41 | JDO Book | 9.00 | 18.75 | Sophie |
| org.hammer.domain.AuctionItem-40 | EJB Book | 5.00 | 10.45 | David |
SQL
For reference, here's the SQL which was generated by the projected query including the Object ID:
SELECT t0.JDOID, t0.TITLE, t0.RESERVEPRICE, t1.BIDAMOUNT, t3.USERNAME FROM AUCTIONITEM t0 INNER JOIN BID t1 ON t0.WINNINGBID_JDOID = t1.JDOID LEFT OUTER JOIN BIDDER t2 ON t1.BIDDER_JDOID = t2.JDOID LEFT OUTER JOIN REGISTEREDUSER t3 ON t2.USER_JDOID = t3.JDOID WHERE (t1.BIDAMOUNT > t0.RESERVEPRICE)
Single field projections
There are two special cases of projection which warrant illustration here. These both involve projections of a single field expression. In the case that the projection contains only one field there is no need for the Object[] container. The results of the query are then a collection of the field's type (or corresponding wrapper type) or, if the query's unique property is true, a single instance of the field's type (or corresponding wrapper type).
These cases are best illustrated with two examples.
JDOQL (#20) for non-unique single field projection -kodo workbench screenshot
{kind=link}
The first example selects only the email addresses of the registered users. The single field is of type String, but since the query is not unique the result is a Collection of String objects.
Query q = pm.newQuery (RegisteredUser.class);
q.setResult ("emailAddress");
Collection results = (Collection)q.execute ();
// execution returns a Collection
Iterator iter = results.iterator();
while (iter.hasNext()) {
String email = (String) iter.next();
// the Collection contains Strings not Object[]s
// further processing as required
}
Result
| emailAdddress |
| [email protected] |
| [email protected] |
| [email protected] |
| [email protected] |
| [email protected] |
JDOQL (#21) for unique single field projection -kodo workbench screenshot
{kind=link}
The second query selects the email address of a specific user. I have explicitly set the query's "unique" property to true, as I expect at most one instance to match the filter. The result is therefore a single String object, without any surrounding container.
Query q = pm.newQuery (RegisteredUser.class, "userName == 'Sophie'");
q.setResult ("emailAddress");
q.setUnique(true);
String email = (String) q.execute();
// execution returns a single String object
Result
| emailAdddress |
| [email protected] |
Selecting Distinct Data for Winning Bids
When a JDOQL query selects back persistent instances of a candidate class there is no reason to de-duplicate the results; the uniqueness of instances in the collection result is guaranteed by JDO.
However, once a query employs projection (by listing one or more fields in the "result" clause), it becomes quite feasible for the result to contain duplicates.
Consider the following query which selects just the user name of the bidder who has placed the winning bid for each item where the reserve price has been exceeded:
JDOQL (#22) without distinct -kodo workbench screenshot
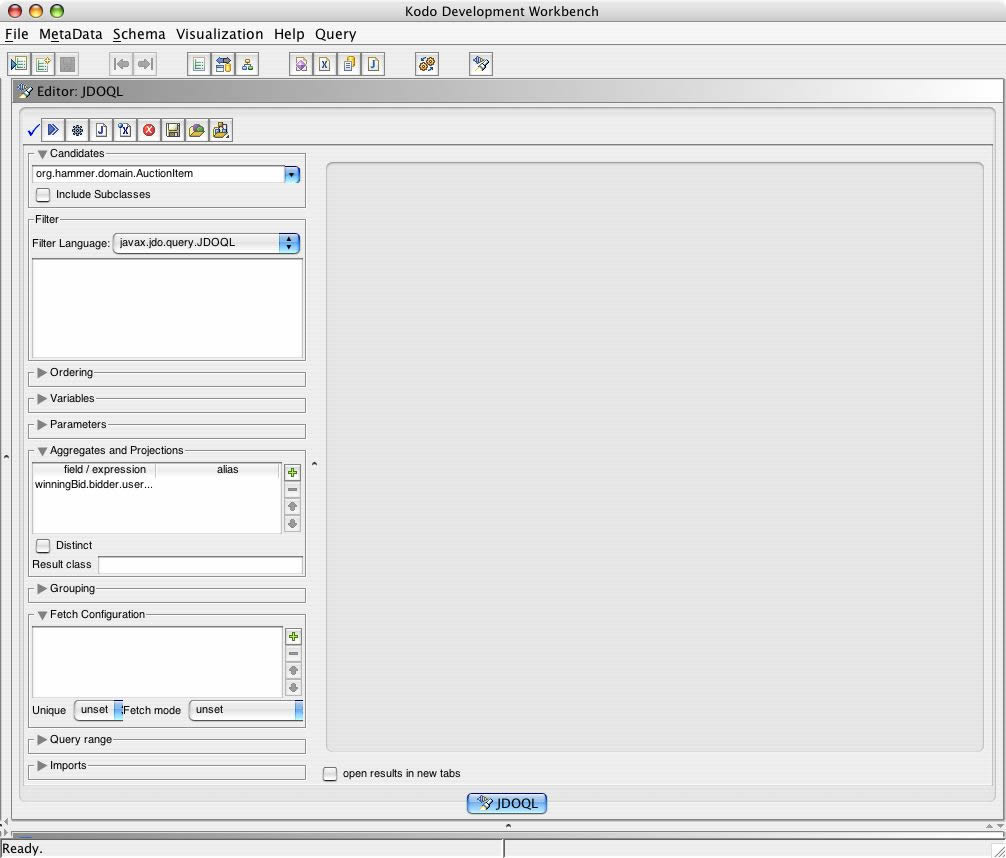{kind=link}
Query q = pm.newQuery (AuctionItem.class);
q.setResult ("winningBid.bidder.user.userName");
Collection results = (Collection)q.execute ();
| userName |
| Jaques |
| Sophie |
| Sophie |
| David |
| Jaques |
Jaques and Sophie each placed the winning bid against more than one item.
Depending on the application's particular use-case it may be prefereble to have distinct results. Deduplicating such data cannot be efficiently achieved on the client and, where large datasets are involved, doing so might well be impracticable.
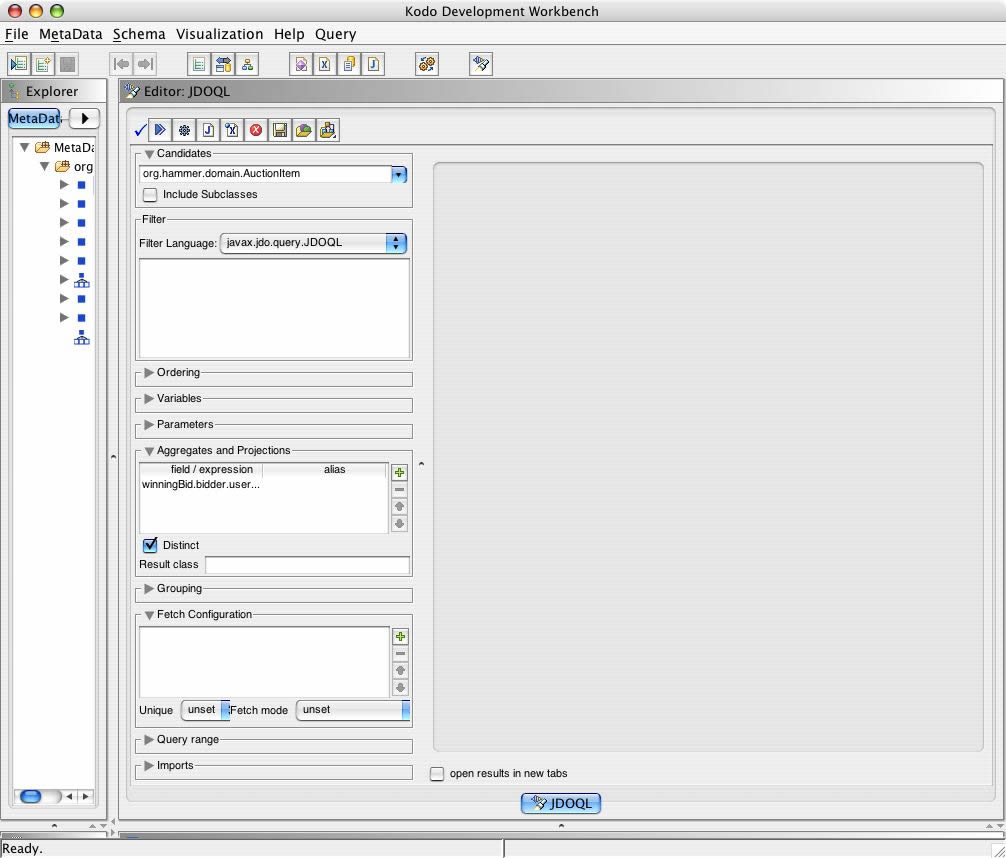
To solve this problem JDO 2.0 adds support for thedistinctkeyword, which is only legitimate as the first word of a query result clause. This capability is translated into the appropriate SQL for the underlying database in order that de-duplication might be achieved in the most efficient manner possible.
JDOQL (#23) using distinct -kodo workbench screenshot
{kind=link}
Here's the revised query:
Query q = pm.newQuery (AuctionItem.class);
q.setResult ("distinct winningBid.bidder.user.userName");
Collection results = (Collection)q.execute ();
And the results:
| userName |
| David |
| Jaques |
| Sophie |
SQL
Finally here's the SQL that was generated:
SELECT DISTINCT t3.USERNAME FROM AUCTIONITEM t0 LEFT OUTER JOIN BID t1 ON t0.WINNINGBID_JDOID = t1.JDOID LEFT OUTER JOIN BIDDER t2 ON t1.BIDDER_JDOID = t2.JDOID LEFT OUTER JOIN REGISTEREDUSER t3 ON t2.USER_JDOID = t3.JDOID
Selecting Winning Bids as Custom JavaBeans - Result Classes
Without projection, a JDOQL query always returns one or more instances of the candidate class. Projection allows the query author to identify a list of desired fields and field expressions; the result of query execution is then one or more Object[]s, each of which contains the selected field values corresponding to one of the instances which matches the filter criteria.
Sometimes, however, it is not desirable to get back an Object[] per matching instance. Object[]s can be difficult to work with, and a JavaBean class might be more appropriate. In this context a JavaBean is a class with a public no-arg constructor and get/set methods for each of its properties.
JDO 2.0 allows queries to be given the class descriptor of a JavaBean class which is to hold the query result. This is known as the "result class". Fields of matching instances are mapped to properties of this class, one JavaBean instance per matching persistent candidate class instance. The default mapping between fields of the projection and properties of the JavaBean is based on the field name itself, but the query author can specify an alias for each projected field if necessary. The specified alias is then used to determine the corresponding JavaBean property.
Technically the result class can be simpler than a proper JavaBean; JDO does not require accessor (get) methods for the properties, and indeed it is legitimate to use public fields instead of properties.
Projection without result class
Here is an example query from an earlier section, which projects a couple of fields and reachable field expressions for auction items whose reserve prices have been exceeded.
Query q = pm.newQuery (AuctionItem.class,
"winningBid.bidAmount > reservePrice");
q.setResult ("title, reservePrice, winningBid.bidAmount,
winningBid.bidder.user.userName");
Collection results = (Collection)q.execute ();
Iterator iter = results.iterator();
while (iter.hasNext()) {
Object[] row = (Object[]) iter.next();
// additional processing as required
}
Results
The results of this query is a Collection of Object[]. For my data set the results were:
| title | reservePrice | bidAmount | userName |
| XML Book | 4.00 | 8.25 | Jaques |
| JDO Book | 9.00 | 18.75 | Sophie |
| EJB Book | 5.00 | 10.45 | David |
Defining the JavaBean result class
Now here is the source code for a JavaBean which is intended to hold the same information.
public class WinningBidBean {
private String title;
private double reservePrice;
private double bestBid;
private String userName;
public String getTitle() {return title;}
public double getReservePrice()
{return reservePrice;}
public double getBestBid() {return bestBid;}
public String getUserName() {return userName;}
public void setTitle(String title)
{this.title = title;}
public void setReservePrice(double reservePrice)
{this.reservePrice = reservePrice;}
public void setBestBid(double bestBid)
{this.bestBid = bestBid;}
public void setUserName(String userName)
{this.userName = userName;}
}
The default no-arg constructor is public.
Projection with result class
Now that we have the JavaBean class it is easy to have the query populate instances of WinningBidBean instead of Object[]. To do so we need to set the result class of the query. We also have to set an alias for the winning bid amount, which must correspond to the "bestBid" property of the bean. Field winningBid.bidder.user.userName also needs an alias as it is not a field of the candidate class, so we have explicitly aliased it to "userName".
JDOQL (#24) -kodo workbench screenshot
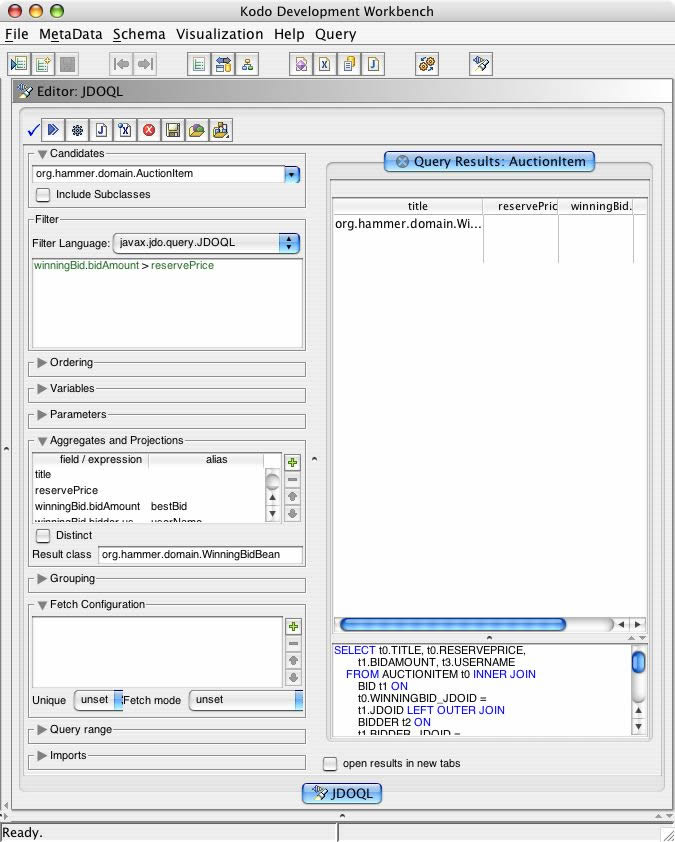{kind=link}
Here's the resulting query.
Query q = pm.newQuery (AuctionItem.class,
"winningBid.bidAmount > reservePrice");
q.setResult ("title, reservePrice, winningBid.bidAmount
as bestBid, winningBid.bidder.user.userName as userName");
q.setResultClass(WinningBidBean.class);
Collection results = (Collection)q.execute ();
Iterator iter = results.iterator();
while (iter.hasNext()) {
WinningBidBean row = (WinningBidBean) iter.next();
// additional processing as required
}
Results
Naturally the query will select and return the same values. All that is different is the type that contains the returned values. In this case the return is a collection of WinningBidBean instances.
Projection into a concrete Map implementation
There is one final variation on this theme which is worthy of illustration here. Instead of specifying a JavaBean class as the "resultClass" of a query, you can specify a concrete class which implements the java.util.Map interface. Each field projected from the query is put into the map against a key which is that field's name (or alias).
JDOQL (#25) -kodo workbench screenshot
{kind=link}
This example projects the same data into a Map, and the illustrates the keys against which each field value resides.
Query q = pm.newQuery (AuctionItem.class,
"winningBid.bidAmount > reservePrice");
q.setResult ("title, reservePrice, winningBid.bidAmount
as bestBid, winningBid.bidder.user.userName as userName");
q.setResultClass(HashMap.class);
Collection results = (Collection)q.execute ();
Iterator iter = results.iterator();
while (iter.hasNext()) {
Map row = (Map) iter.next();
System.out.println(row.get("title"));
System.out.println(row.get("reservePrice"));
System.out.println(row.get("bestBid"));
System.out.println(row.get("userName"));
}
Summarizing Auction Data - Aggregation
Historically JDOQL was focussed on retrieving instances persistent classes from the database. The result returned from query execution was a Collection of instances which match the filter criteria.
The addition of projection to JDOQL has allowed authors to write queries which retrieve data structures instead of instances, through the specification of a query "result" clause which lists comma-delimited fields and field expressions. Returned from the execution of such a query is one or more Object[] or JavaBean instances.
Another new feature of JDO 2.0 is the addition of aggregate functions to the query language. Here are the supported aggregate functions and their Java types:
| Aggregate Function | Java Type to which Aggregate Evaluates |
| count(field) | Long |
| sum(field) | Long for integral types, the field's type for non-integral numeric types. |
| avg(field) | Field's type |
| min(field) | Field's type |
| max(field) | Field's type |
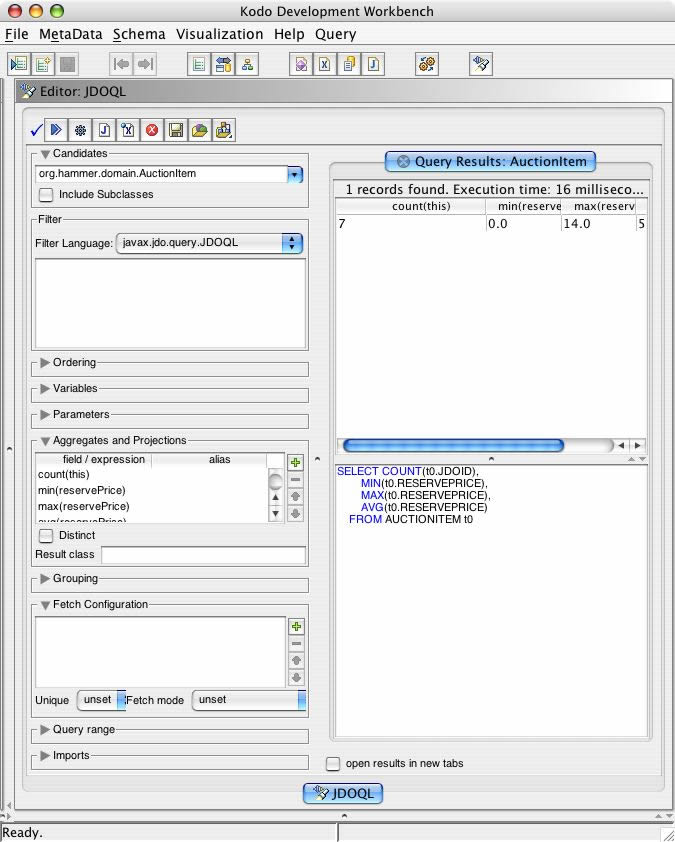
The query result clause can contain aggregate expressions in addition to fields and field expressions. Any query which uses aggregates and does not have a grouping clause (see later) implicitly returns at most one row, so there is no need to explicitly invoke setUnique(true).
JDOQL (#26) -kodo workbench screenshot
{kind=link}
Heres a query which illustrates these aggregate functions.
Query q = pm.newQuery (AuctionItem.class);
q.setResult ("count(this), min(reservePrice), max(reservePrice),
avg(reservePrice), sum(reservePrice)");
// unique=true implicitly since the query result includes
aggregation without grouping
// thus the returned Object[] is not wrapped by a Collection
Object[] result = (Object[]) q.execute ();
Result
The field reservePrice is of type double, hence the aggregate functions applied to it evaluate to instances of Double. Count evaluates to a Long.
| count | min | max | avg | sum |
| 7 0 | .00 | 14.00 | 5.00 | 35.00 |
SQL
SELECT COUNT(t0.JDOID), MIN(t0.RESERVEPRICE), MAX(t0.RESERVEPRICE), AVG(t0.RESERVEPRICE), SUM(t0.RESERVEPRICE) FROM AUCTIONITEM t0
Unique single-aggregate queries
If a JDOQL query is configured as unique (the author expects no more than 1 matching row) then the query result is not wrapped in a Collection. Furthermore, if the result clause of the query contains only a single expression then the resulting value is not wrapped in an Object[]. Finally, if the result clause of a query contains only aggregate expressions, then the query is implicitly unique. Thus the simple case becomes very straight-forward indeed.
Below is a query which selects the total exposure of an individual user. This is the sum of all bids which they have placed that are currently winning bids.
JDOQL (#27) -kodo workbench screenshot
{kind=link}
Query q = pm.newQuery(Bid.class, "bidder.user.userName==name && this == item.winningBid");
q.setResult ("sum(bidAmount)");
q.declareParameters ("String name");
Double result = (Double) q.execute("Sophie");
Results
Notice that the object returned from query execution is a Double. There is no need to mess around with Collections and Object[]s to extract the desired result.
| sum |
| 20.50 |
SQL
Here is the SQL which was executed against my database schema:
SELECT SUM(t0.BIDAMOUNT) FROM BID t0 INNER JOIN BIDDER t1 ON t0.BIDDER_JDOID = t1.JDOID INNER JOIN REGISTEREDUSER t2 ON t1.USER_JDOID = t2.JDOID INNER JOIN AUCTIONITEM t3 ON t0.ITEM_JDOID = t3.JDOID WHERE (t2.USERNAME = 'Sophie' AND t0.JDOID = t3.WINNINGBID_JDOID)
Grouping Aggregate Results
Aggregate results are incredibly useful in isolation. However, combined with grouping capabilities they become even more powerful.
Consider a requirement to identify the largest bids which a particular user has placed. Using aggregation alone we can establish that the largest bid which Sophie has placed was for 18.75.
JDOQL (#28) -kodo workbench screenshot
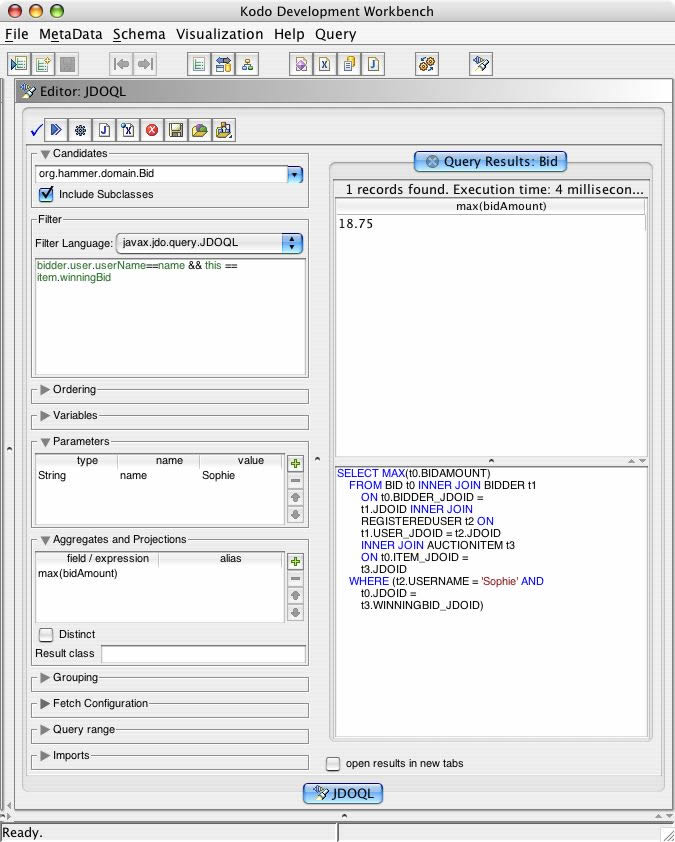{kind=link}
Query q = pm.newQuery (Bid.class, "bidder.user.userName == name");
q.setResult ("max(bidAmount)");
q.declareParameters ("String name");
Double result = (Double) q.execute ("Sophie");
Results
| max |
| 18.75 |
SQL
SELECT MAX(t0.BIDAMOUNT) FROM BID t0 INNER JOIN BIDDER t1 ON t0.BIDDER_JDOID = t1.JDOID INNER JOIN REGISTEREDUSER t2 ON t1.USER_JDOID = t2.JDOID WHERE (t2.USERNAME = 'Sophie')
But surely it is more useful to know the largest bids which Sohpie has placed on a per-auction item basis? This can be achieved by grouping the max(bidAmount) by item.
JDOQL (#29) -kodo workbench screenshot
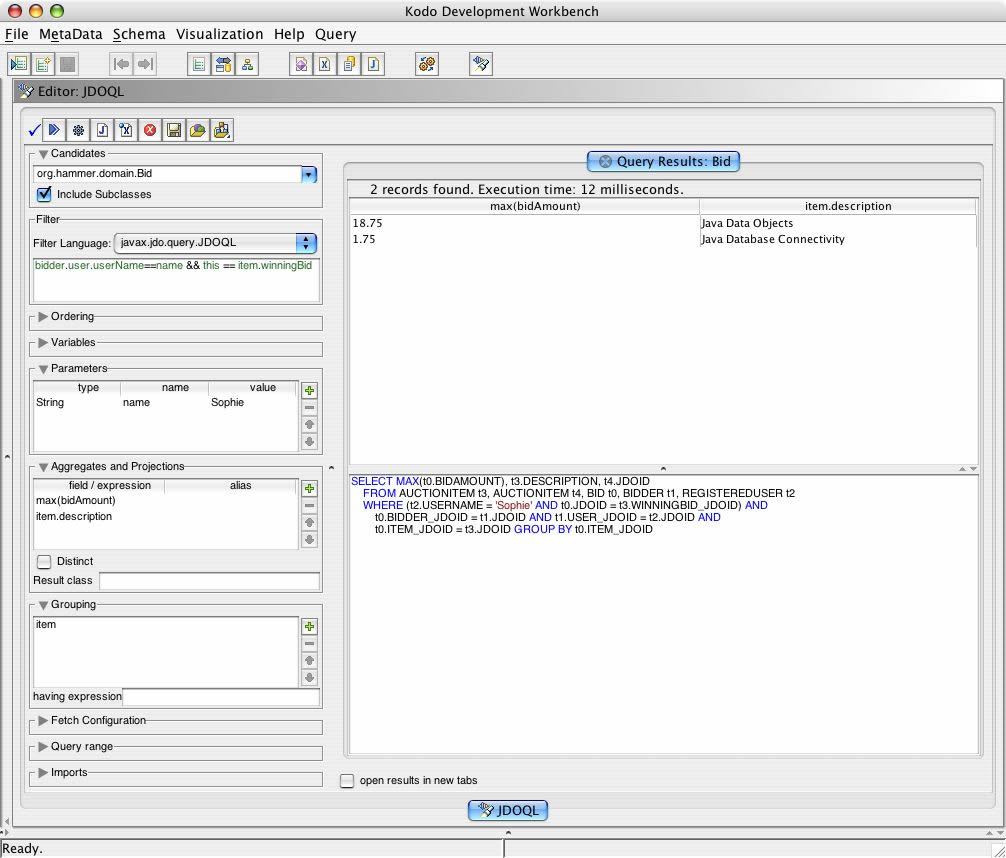{kind=link}
Query q = pm.newQuery (Bid.class, "bidder.user.userName==name");
q.setResult ("max(bidAmount), item.description");
q.setGrouping ("item");
q.declareParameters ("String name");
Collection results = (Collection) q.execute ("Sohpie");
Results
| max | item.description |
| 7.75 | Java and XML |
| 18.75 | Java Data Objects |
| 1.75 | Java Database Connectivity |
| 10.05 | Enterprise Javabeans |
| 13.00 | Java Modeling In Color With UML |
SQL
SELECT MAX(t0.BIDAMOUNT), t3.DESCRIPTION FROM BID t0 INNER JOIN BIDDER t1 ON t0.BIDDER_JDOID = t1.JDOID INNER JOIN REGISTEREDUSER t2 ON t1.USER_JDOID = t2.JDOID LEFT OUTER JOIN AUCTIONITEM t3 ON t0.ITEM_JDOID = t3.JDOID WHERE (t2.USERNAME = 'Sophie') GROUP BY t0.ITEM_JDOID
Having
Finally, perhaps only maximum bids of over a particular threshold are considered significant. Aggregate data cannot be constrained in the filter clause itself, but criteria involving aggregates can be specified in the having clause.
The example below groups Sohpie's maximum bids by item and only shows those for which the maximum bid exceeds 10.00.
JDOQL (#30) -kodo workbench screenshot
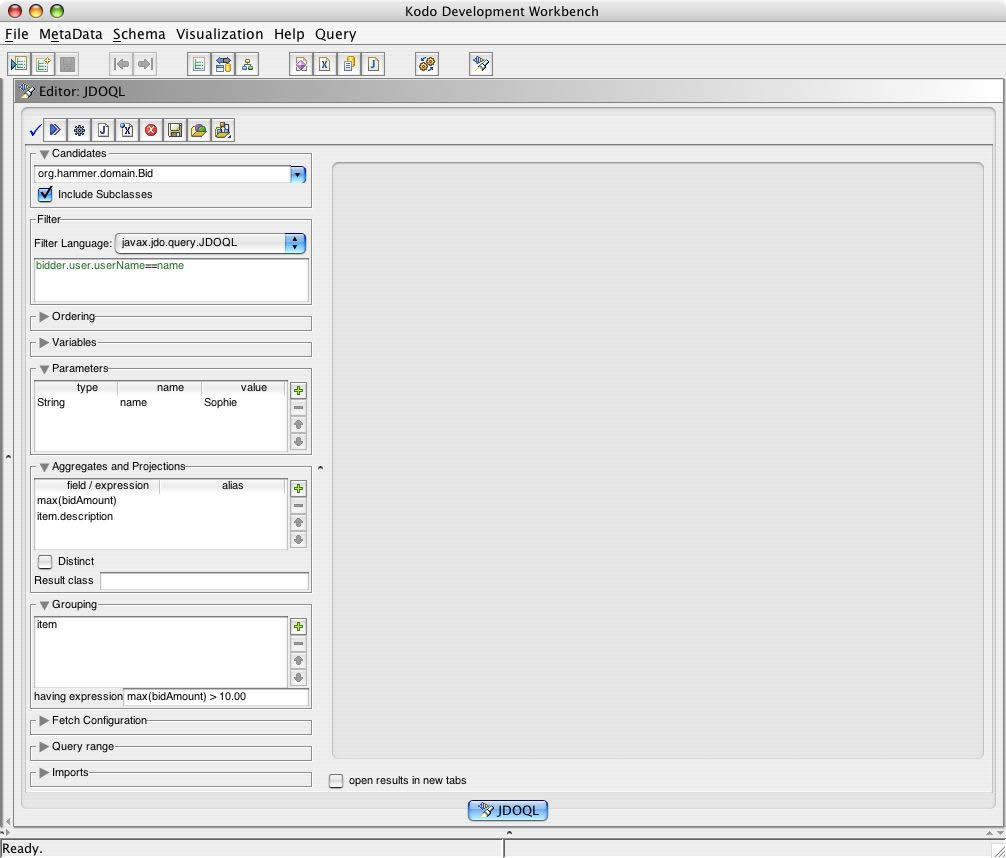{kind=link}
Query q = pm.newQuery(Bid.class, "bidder.user.userName==name");
q.setResult ("max(bidAmount), item.description");
q.setGrouping ("item having max(bidAmount) > 10.00");
q.declareParameters ("String name");
Collection results = (Collection) q.execute("Sophie");
Results
Only rows with the aggregate max(bidAmount) which exceed 10 are included.
| max | item.description |
| 18.75 | Java Data Objects |
| 10.05 | Enterprise Javabeans |
| 13.00 | Java Modeling In Color With UML |
SQL
Here is the SQL for the final example. Bear in mind that, although not all SQL databases support the HAVING clause, JDOQL queries which use this capability are entirely portable. Result exclusion will be undertaken by the JDO implementation if the database lacks native support.
SELECT MAX(t0.BIDAMOUNT), t3.DESCRIPTION FROM BID t0 INNER JOIN BIDDER t1 ON t0.BIDDER_JDOID = t1.JDOID INNER JOIN REGISTEREDUSER t2 ON t1.USER_JDOID = t2.JDOID LEFT OUTER JOIN AUCTIONITEM t3 ON t0.ITEM_JDOID = t3.JDOID WHERE (t2.USERNAME = 'Sophie') GROUP BY t0.ITEM_JDOID HAVING MAX(t0.BIDAMOUNT) > 10