Design a high performance cache for multi-threaded environment
如何设计一个支持高并发的高性能缓存库
不 考虑并发情况下的缓存的设计大家应该都比较清楚,基本上就是用map/hashmap存储键值,然后用双向链表记录一个LRU来用于缓存的清理。这篇文章 应该是讲得很清楚http://timday.bitbucket.org/lru.html。但是考虑到高并发的情况,如何才能让缓存保持高性能呢?
高并发缓存需要解决2个问题:1. 高效率的内存分配;2. 高效率的读取,插入和清理数据。关于第一个问题涉及到高效率的内存分配器,使用成熟的jemalloc/tcmalloc足够满足需求。这里探讨下如何解决第二个问题。
由 于缓存系统的特点, 每次读取缓存都需要更新一些访问信息(最后读取时间,访问频率),在清理时会根据这些信息使用不同的策略来进行数据清理,这样看来似乎每次的读操作都变成 了写操作。看过几篇文章都比较集中在如何优化这个读操作修改LRU的行为。例如: http://www.ebaytechblog.com/2011 /08/30/high-throughput-thread-safe-lru-caching/#.UzvEb3V53No 以及 http://openmymind.net/High-Concurrency-LRU-Caching/, 但是这种情况下不论怎么优化,使用链表的LRU始终是个瓶颈, 因为每次读操作只能一个线程来修改这个LRU链表,并且修改都是集中在链表的两端。有些文章甚至使用lock-free的doubled linked list来减少锁竞争。 一些成熟的缓存系统如memcached,使用的是全局的LRU链表锁,而redis是单线程的所以不需要考虑并发的问题。由于这些都是远程的缓存服务 器,因此它们的瓶颈往往是网卡,所以并发上面并不需要什么高要求。
仔 细思考后,发现在并发的情况下使用LRU链表来记录访问信息其实并不合适,会导致严重的锁竞争,这点无法避免。因此,需要彻底放弃使用LRU链表。鉴于缓 存系统的特性,可以做如下假设: 缓存如果达到阀值,可以使插入立即返回失败。这样,我们可以使用一个预分配的数组来记录所有的cache item的访问信息。整个结构如下:
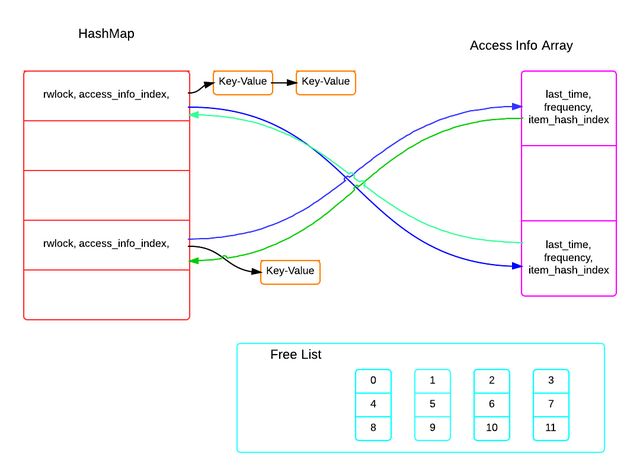
concurrent cache system arch
可 以看到锁粒度是hashmap里面的bucket级别,每次读操作只需对相应的bucket加锁,然后更新bucket对应的访问信息数组元素即可,由于 每个bucket对应的访问信息是独立占据数组的一个元素的,因此bucket锁就保证了访问信息的线程安全。这样就解决了读取操作的并发竞争问题。
接 下来看看如何解决插入问题。从图可以看到,每个bucket的需要分配一个独立的access info位置索引,多线程插入的时候会发生竞争,为了减少竞争,可以预先生成一个目前空闲的位置链表,这样插入的时候,每个线程可以根据当前的 bucket索引选择从不同的free链表里面分配一个位置。这样锁竞争可以分散到多个free list上面,每次插入时把分配过的位置索引从free list 移除。
最 后,清理过程可以放在一个独立线程里面,为了避免插入因为缓存满了而返回失败,每次在缓存快满的时候(free list的size不够用了),进行一次access info array扫描。根据不同的缓存清除策略和访问信息(时间和频率)来决定哪些位置索引是可以重新释放到free list列表。由于扫描过程中无需加锁,扫描对读取和插入操作是没有性能影响的。只有最后进行释放时才会对需要释放的bucket和free list进行加锁,锁竞争大大减少。
如上设计,大大减少了缓存的读取,插入和清理过程中的锁竞争问题,并且读取和插入都是O(1)的,并不会因为缓存系统的增大影响性能(清理后台线程可能会跑的久点,可以选择性清理来优化)。这样一个支持高并发的缓存系统就完成了。
简 单的实现后,实测在8核CPU上面8线程读,8线程写,可以跑到 读写TPS均在1M/S以上,参考官方单线程的redis的benchmark数据 Using a unix domain socket 排除网络瓶颈,SET/GET的TPS大概在200k/s 左右,可以看到这样一个高并发的cache基本上是scalable的。