JAVA面试八股文【全网最全】
多同学会问Java面试八股文有必要背吗?
我的回答是:很有必要。你可以讨厌这种模式,但你一定要去背,因为不背你就进不了大厂。
国内的互联网面试,恐怕是现存的、最接近科举考试的制度。
一、java
(1)集合
1.list:LinkedList、ArrayList和Vector
- LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
- ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
- Vector 接口实现类 数组, 同步, 线程安全
2.set:HashSet和TreeSet
- HashSet 使用哈希表存储元素,元素可以是null
- LinkedHashSet 链表维护元素的插入次序
- TreeSet 底层实现为红黑树,元素排好序,元素不可以是null
3.map:HashMap、TreeMap和HashTable
- 线程安全
- HshaMap线程不安全
- TreeMap线程不安全
- HashTable线程安全
- 空值
- HashMap一个null key,多个null value
- TreeMap不能null key,多个null value
- HashTable都不能有null
-
继承和接口篇幅限制下面就只能给大家展示小册部分内容了。包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
- HashMap继承AbstractMap,实现接口Map
- TreeMap继承AbstractMap,实现接口NavigableMap(SortMap的一种)
- HashTable继承Dictionary,实现接口Map
- 顺序
- HashMap中key是无序的
- TreeMap是有序的
- HashTable是无序的
- 构造函数
- HashMap有调优初始容量和负载因子
- TreeMap没有
- HashTable有
- 数据结构
- HashMap是链表+数组+红黑树
- TreeMap是红黑树
- HashTable是链表+数组
4.list、set和map的区别
- list:元素按进入先后有序保存,可重复
- set:不可重复,并做内部排序
- map:代表具有映射关系的集合,其所有的key是一个Set集合,即key无序且不能重复。
5.HashMap扩容机制
- 数组的初始容量为16,而容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模预算(据说提升了5~8倍)。
- 数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组。这个0.75就是默认的负载因子,可由构造器传入。我们也可以设置大于1的负载因子,这样数组就不会扩充,牺牲性能,节省内存。
- 为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时(7或8),会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时(6),又会将红黑树转换回单向链表提高性能。
- 对于第三点补充说明,检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。所以上面也说了链表长度的阈值是7或8,因为会有一次放弃转换的操作。
6.HashMap中的循环链表是如何产生的(jdk1.7)
- 由于jdk1.7中采用头插法,在多线程中,存在两个线程同时对链表进行扩容的情况,执行transfer函数(链表数据转移)会导致链表数据倒置,当两个线程同时此操作,就导致链表死循环
7.B树和B+树的区别
- B树是二叉排序树进化而来;B+树是分块查找进化而来
- B+树叶节点包含所有数据,非叶节点仅起到索引作用;B树终端节点及以上都包含数据且不重复(叶节点只是一个概念,并不存在)
- B+树叶节点包含了全部关键字
- B+树支持顺序查找和多路查找,B树只支持多路查找
8. HashMap为什么用红黑树而不是AVL树或者B+树
- AVL树更加严格平衡,因此可以提供更快的査找效果。因此,对于查找密集型任务使用AVL树没毛病。 但是对于插入密集型任务,红黑树要好一些。
- B/B+树的节点可以存储多个数据,当数据量不够多时,数据都会”挤在“一个节点中,查询效率会退化为链表。
9.CopyOnWriteArrayList的原理
- 线程并发访问进行读操作时,没有加锁限制
- 写操作时,先将容器复制一份,再在新的副本上执行写操作,此时写操作是上锁的。结束之后再将原容器的引用指向新容器。注意,在上锁执行写操作的过程中,如果有需要读操作,会作用在原容器上。因此上锁的写操作不会影响到并发访问的读操作。
10.BlockingQueue中有哪些方法
篇幅限制下面就只能给大家展示小册部分内容了。包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
- 共四组增删API
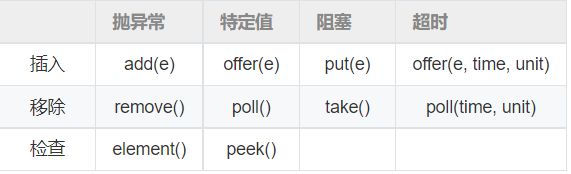
- 抛异常:如果操作无法立即执行,则抛一个异常;
- 特定值:如果操作无法立即执行,则返回一个特定的值(一般是 true / false)。
- 阻塞:如果操作无法立即执行,则该方法调用将会发生阻塞,直到能够执行;
- 超时:如果操作无法立即执行,则该方法调用将会发生阻塞,直到能够执行。但等待时间不会超过给定值,并返回一个特定值以告知该操作是否成功(典型的是true / false)。
(2)多线程
1.Java中线程安全的基本数据结构
- string
- HashTable
- ConcurrentHashMap
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- Vector
- stringBuffer
2.创建线程有哪几种方式
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
- 线程池
- 七大参数
- 核心线程数
- 最大线程数
- 空闲线程存活时间
- 时间单位
- 任务队列
- 线程工厂
- 拒绝策略
- 拒绝并抛出异常
- 拒绝忽略任务
- 抛弃队列头部任务
- 返回给调用线程执行
- 七大参数
3.线程的生命周期
- 线程的状态有五种:新建(new)、就绪(start())、运行(分配到cpu)、阻塞和死亡
- CPU在多条线程之间切换,于是线程状态也会多次在运行、就绪之间切换。
- 出现阻塞的情况
- 线程调用sleep()方法主动放弃所占用的处理器资源。
- 线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞。
- 线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有。
- 线程在等待某个通知(notify)
- 程序调用了线程的suspend()方法将该线程挂起。但这个方法容易导致死锁,所以应该尽量避免使用该方法。
- 解除阻塞重新进入就绪状态的情况
- 调用sleep()方法的线程经过了指定时间
- 线程调用的阻塞式IO方法已经返回。
- 线程成功地获得了试图取得的同步监视器。
- 线程正在等待某个通知时,其他线程发出了一个通知。
- 处于挂起状态的线程被调用了resume()恢复方法。
- 出现死亡的情况
- run()或call()方法执行完成,线程正常结束
- 线程抛出一个未捕获的Exception或Error。
- 直接调用该线程的stop()方法来结束该线程,该方法容易导致死锁,通常不推荐使用
4.如何实现线程同步
- 同步方法(synchronized)
- 同步代码块
- ReentrantLock
- volatile
篇幅限制下面就只能给大家展示小册部分内容了。包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
5.Java多线程之间的通信方式
- wait()、notify()、notifyAll()。采用采用synchronized来保证线程安全
- await()、signal()、signalAll()。采用lock保证线程安全
- BlockingQueue。当生产者线程试图向BlockingQueue中放入元素时,如果该队列已满,则该线程被阻塞;当消费者线程试图从BlockingQueue中取出元素时,如果该队列已空,则该线程被阻塞。
6.sleep()和wait()的区别
- sleep()是Thread类中的静态方法,而wait()是Object类中的成员方法;
- sleep()可以在任何地方使用,而wait()只能在同步方法或同步代码块中使用
- sleep()不会释放锁,而wait()会释放锁,并需要通过notify()/notifyAll()重新获取锁。
7.synchronized与Lock的区别
- synchronized是Java关键字,在JVM层面实现加锁和解锁;Lock是一个接口,在代码层面实现加锁和解锁
- synchronized可以用在代码块上、方法上;Lock只能写在代码里。
- synchronized在代码执行完或出现异常时自动释放锁;Lock不会自动释放锁,需要在finally中显示释放锁。
- synchronized会导致线程拿不到锁一直等待;Lock可以设置获取锁失败的超时时间。
- synchronized无法得知是否获取锁成功;Lock则可以通过tryLock得知加锁是否成功。
- synchronized锁可重入、不可中断、非公平;Lock锁可重入、可中断、可公平/不公平,并可以细分读写锁以提高效率
8.乐观锁和悲观锁的区别
9.公平锁与非公平锁
- 非公平锁: 当线程争夺锁的过程中,会先进行一次CAS尝试获取锁,若失败,则进入acquire(1)函数,进行一次tryAcquire再次尝试获取锁,若再次失败,那么就通过addWaiter将当前线程封装成node结点加入到Sync队列,这时候该线程只能乖乖等前面的线程执行完再轮到自己了
- 公平锁: 当线程在获取锁的时候,会先判断Sync队列中是否有在等待获取资源的线程。若没有,则尝试获取锁,若有,那么就那么就通过addWaiter将当前线程封装成node结点加入到Sync队列中
10.volatile
- 保证可见性,不保证原子性
- 禁止指令重排
(3)其他
1.面向对象三大特性
- 封装:(将数据和代码捆绑在一起,防止外界干扰)把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏
- 继承:(让一个类型的对象拥有另一个类型的对象的属性的方法)可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展
- 多态:(就是一个事物拥有不同形式的能力)父类引用指向子类对象,从而具备多种形态
2.Object类的常用方法
- equals()
- hashCode()
- toString()
- getClass()
- wait()
- notify()
- notifyall()
- clone()
- finalize()
3.string、stringBuffer和stringBuilder
- string不可变、线程安全
- stringBuffer可变,效率低,线程安全
- stringBuilder可变、效率高,线程不安全
4.抽象类与接口的区别
- 抽象类属于继承,只能继承一个;接口可以实现多个
- 抽象类有构造方法;接口没有构造方法
- 抽象类的成员变量可以是变量也可以是常量;接口的成员变量只能是常量,默认修饰符public static final
- 抽象类的成员方法可以是抽象的也可以是具体实现的;接口在jdk1.7只能是抽象的成员方法,jdk1.8之后可以有具体实现且必须用default修饰。并且接口也可以有静态方法,static修饰。
- 抽象类和接口的选择:如果关注的是一个事务的本质,就用抽象类;关注一个操作的时候就用接口。比如,关注一个人,男人或女人,这时候关注的是本质,就用抽象类。关注每种人吃东西,睡觉各种动作不同,就需要用接口,定义一个模板,分别去实现。
5.java的基本数据类型
- byte:1字节(8位),数据范围是 -2^7 ~ 2^7-1。
- short:2字节(16位),数据范围是 -2^15 ~ 2^15-1。
- int:4字节(32位),数据范围是 -2^31 ~ 2^31-1。
- long:8字节(64位),数据范围是 -2^63 ~ 2^63-1。
- float:4字节(32位),数据范围大约是 -3.410^38 ~ 3.410^38。
- double:8字节(64位),数据范围大约是 -1.810^308 ~ 1.810^308。
- char:2字节(16位),数据范围是 \u0000 ~ \uffff。
- boolean:Java规范没有明确的规定,不同的JVM有不同的实现机制。
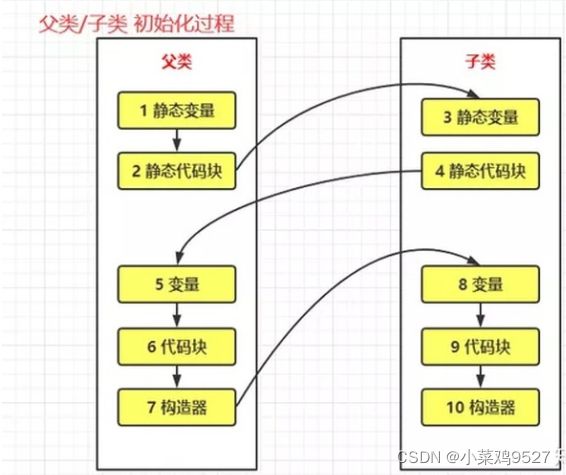
6.java代码块执行顺序
- 父类静态代码块
- 子类静态代码块
- 父类构造代码块
- 父类构造方法
- 子类构造代码块
- 子类构造方法
- 普通代码块
7.static关键字
- 修饰成员变量:该静态变量在内存中只有一个副本。只要静态变量所在的类被加载,这个静态变量就会被分配空间
- 修饰成员方法:调用该方法只需类名.方法名;静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的。在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都必须依赖具体的对象才能够被调用。
- 修饰代码块:在类初次被加载的时候,会按照static块的顺序来依次执行每个static块,并且只会执行一次。
- 修饰内部类:静态内部类不能直接访问外部类的非静态成员,但,可以通过new 外部类().成员的方式访问;
8.覆盖(重写)和重载的区别
- 重写一般是子类重写父类方法(一对一),垂直关系;重载一般是一个类中多个方法重载(多个之间),水平关系
- 重写方法之间参数相同;重载方法之间参数不同
- 重写不可以修改返回值类型;重载可以修改返回值类型
9.java四个访问修饰符
- private:本类中
- default:本包中
- protected:不同包的子类
- public:所有
10.全局变量和局部变量的区别
-
成员变量:
-
成员变量是在类的范围里定义的变量;
-
成员变量有默认初始值;
-
未被static修饰的成员变量也叫实例变量,它存储于对象所在的堆内存中,生命周期与对象相同;
-
被static修饰的成员变量也叫类变量,它存储于方法区中,生命周期与当前类相同。
-
-
局部变量:
-
局部变量是在方法里定义的变量;
-
局部变量没有默认初始值;
-
局部变量存储于栈内存中,作用的范围结束,变量空间会自动的释放。
-
11.hashCode()和equals()的关系
- hashCode求的是对象的散列码(一般是对象的储存地址),equals是根据地址比较对象是否相同
- 如果两个对象相等,则它们必须有相同的哈希码
- 如果两个对象有相同的哈希码,则它们未必相等
12.为什么要重写hashCode()和equals()
- Object类提供的equals()方法默认是用==来进行比较的,也就是说只有两个对象是同一个对象时,才能返回相等的结果。而实际的业务中,我们通常的需求是,若两个不同的对象它们的内容是相同的,就认为它们相等。
13.反射
- JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
14.cookie和session的区别
- 存储位置不同:cookie存放于客户端;session存放于服务端。
- 隐私策略不同:cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的;session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。
- 生命周期不同:设置cookie的属性,达到cookie长期有效的效果;session只需关闭窗口该session就会失效,因此session不能长期有效。
- cookie有存储上限,3k左右;session没有
篇幅限制下面就只能给大家展示小册部分内容了。包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
15.get和post请求的区别
- url可见性:get,参数url可见;post,url参数不可见
- 数据传输上:get,通过拼接url进行传递参数;post,通过body体传输参数
- 缓存性:get请求是可以缓存的;post请求不可以缓存
- 后退页面的反应:get请求页面后退时,不产生影响;post请求页面后退时,会重新提交请求
- 安全性:这个也是最不好分析的,原则上post肯定要比get安全,毕竟传输参数时url不可见。
- get一般传输数据大小不超过2k-4k;post请求传输数据的大小根据php.ini 配置文件设定,也可以无限大。
16.前后端数据交互
-
form表单
-
HttpServletRequest/HttpServletResponse
-
@RequestParam
- 数据在url后 path?id=1
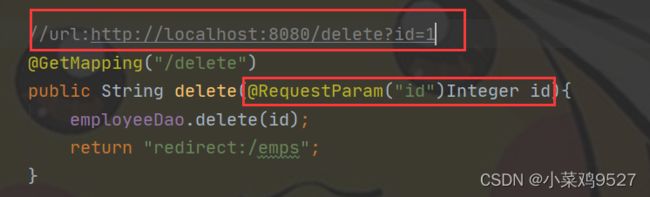
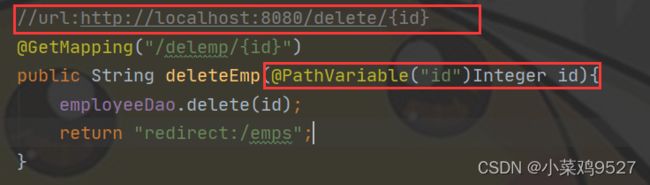
- @PathVariable
- 数据在url后 path/{id}
- @RequestBody
- 以json数据为例,首先有一个类

- 然后前端传过来数据
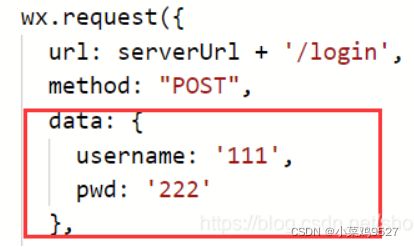
- 后端接收
- 以json数据为例,首先有一个类
- 数据在url后 path?id=1

- ModelAndView(只向前端传输数据)
- 配置视图解析器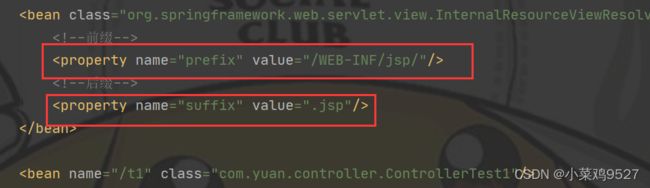
- 创建ModelAndView对象,添加返回的数据和地址
- model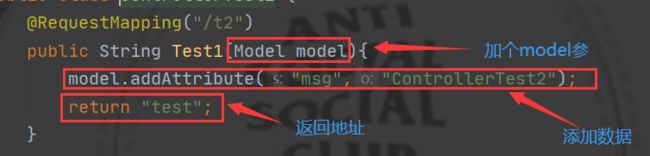
- jquery实现的ajax
- 前端

- eg:
-
数据传输载体类
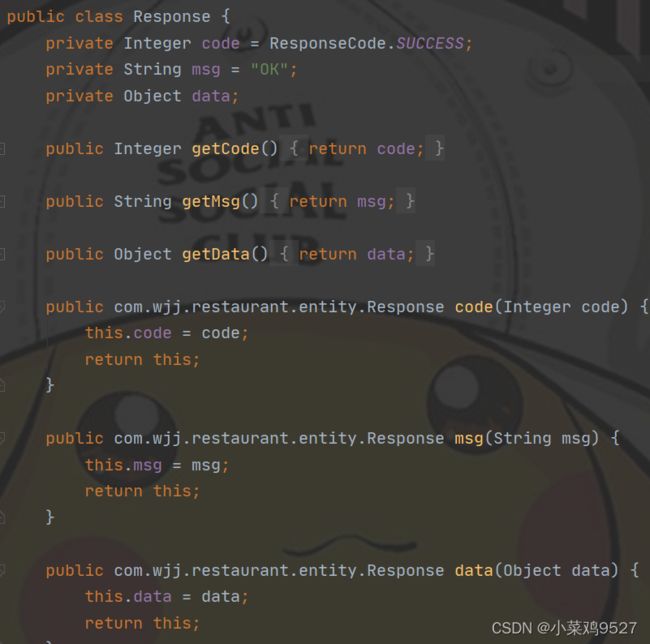
-
前端部分
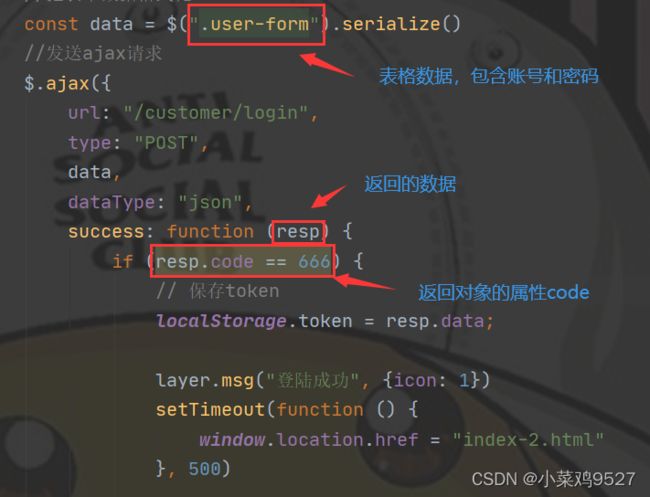
-
后台部分
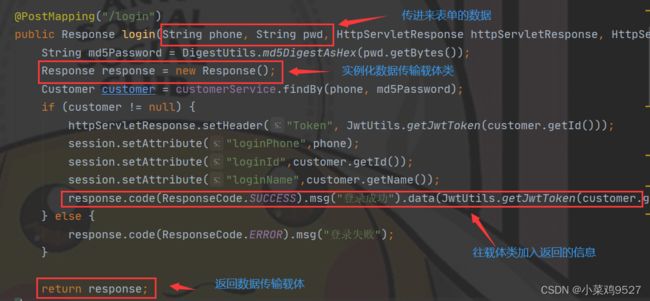
-
- 前端
17.IO分类
- 按流方向分:输入流,输出流
- 按数据单位分:字节流,字符流
篇幅限制下面就只能给大家展示小册部分内容了。包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取
- 按功能分:节点流,处理流
18.处理哈希冲突的方法
- 开放定址法(再散列法)
- 线性探测再散列
- 二次探测再散列
- 伪随机探测再散列
- 再哈希法
- 拉链法
19.throw和throws的区别
- throws跟在方法声明后,后面跟的是异常类名;throw在方法内,后面跟的是异常类实例
- throws后面可以跟多个异常类;throw只能抛出一个异常对象
- throws抛出异常,异常由调用者处理;throw由方法体内的语句来处理
20.23种设计模式
- 创建型(5):工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
- 结构型(7):适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
- 行为型(11):策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
21.设计模式的几个原则
- 单一职责原则
- 接口隔离原则
- 里氏替换原则
- 开闭原则
- 迪米特原则
- 依赖倒置原则
- 合成复用原则
22.spring中涉及的设计模式
- 工厂模式:BeanFactory和ApplicationContext来创建对象
- 单例模式:Bean默认为单例模式
- 代理模式:AOP动态代理
- 模板方法:jdbcTemplete,restTemplete(http请求工具)
- 适配器模式:mvc中的处理器适配
- 观察者模式:spring时间驱动
二、JVM
1.JVM包含哪几部分
- 类加载器
- 运行时数据区(堆、栈、方法区、本地方法栈和程序计数器)
- 方法区:静态变量、常量、类信息和运行时常量池
- 程序计数器:每个线程都有一个程序计数器,就像一个指针,指向方法去中的方法字节码(比如每次读下一条指令的时候给它+1)
- 本地方法栈:登记native方法,在执行引擎的时候加载本地库
- 栈:生命周期和线程同步;不存在垃圾回收问题;存放八大基本类型、对象引用变量名、实例的方法
- 堆:类的实例、字符串常量池
- 新生区:伊甸园区、幸存0区、幸存1区
- 养老区
- 永久区(方法区的具体实现,jdk1.8后改为叫元空间,一部分人认为他不应该划分在堆内,一部分人认为应该划分在堆内)
- 执行引擎
- 本地库接口

2.双亲委派机制
- 类加载器收到类加载的请求
- 将这个请求委托给父类加载器去完成,一直向上委托,直到启动类加载器
- 启动类加载器能执行就结束,否则抛出异常,依次向下通知子类进行加载
- 优点:
- 从最内层开始加载,外层恶意同名类得不到加载从而无法使用
- 严格通过包来区分了访问域,外层恶意的类通过内置代码也无法访问到内层类
3.创建对象内存分析
(案例取自遇见狂神说的java课程视频)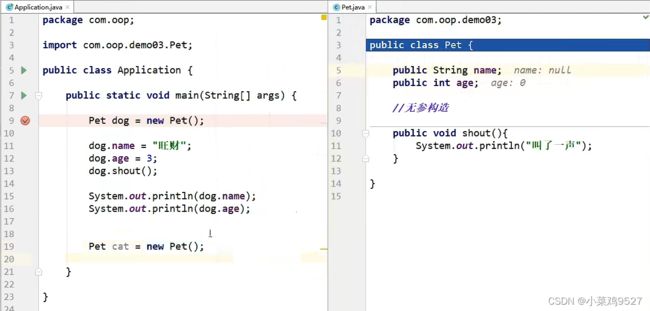
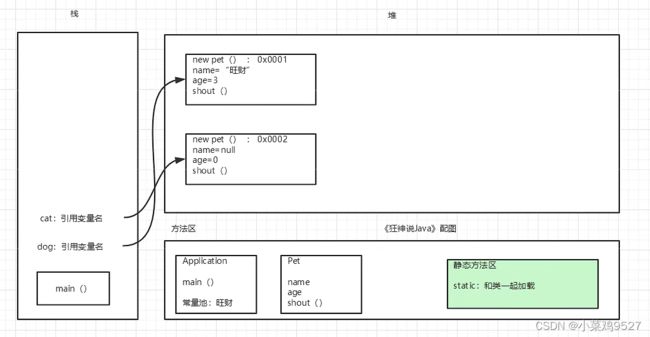
4.JAVA对象实例化过程
- 类的加载初始化
- 加载:载入class对象,不一定是从class文件获取,可以是jar包,或者动态生成的class
- 连接
- 验证:校验class字节流是否符合当前jvm规范
- 准备:为 类变量 分配内存并设置变量的初始值( 默认值 )。如果是final修饰的对象则是赋值声明值
- 解析:将常量池的符号引用替换为直接引用
- 初始化
- 使用
- 卸载
- 对象的初始化
5.GC时候哪些需要回收
- 引用计数算法
- 可达性分析算法
6.三种基本的GC算法
- 标记-清除算法
内存中的对象构成一棵树,当有效的内存被耗尽的时候,程序就会停止,做两件事,第一:标记,标记从树根可达的对象,第二:清除不可达的对象。标记清除的时候程序会停止运行
缺点:递归效率低性能低;释放空间不连续容易导致内存碎片;会停止整个程序运行; - 复制算法
把内存分成两块区域:空闲区域和活动区域,第一还是标记,标记之后把可达的对象复制到空闲区,将空闲区变成活动区,同时把以前活动区对象清除,变成空闲区。
缺点:速度快但耗费空间 - 标记-整理算法
在标记清除算法之后不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存。 - 分代收集算法,即新生代、老年代、永久代
- 内存效率:复制算法>标记清除算法>标记压缩算法(时间复杂度)
- 内存整齐度:复制算法=标记压缩算法>标记清除算法
- 内存利用率:复制算法<标记清除算法=标记压缩算法
7.jdk、jre和jvm
- jdk:java开发工具包。包括java运行环境(jre),java工具,java基础的类库
- jre:java运行环境。包括jvm标准实现及java核心类库
- jvm:java虚拟机,一种抽象化的计算机
三、mysql
1.数据库三大范式
- 第一范式:强调的是列的原子性,即列不能够再分成其他几列。
- 第二范式:在第一范式基础上,必须有一个主键其他字段必须完全依赖于主键,而不能只依赖于主键的一部分。
- 第三范式:在前两个范式基础上,非主键列必须直接依赖于主键,不能存在传递依赖。
2.防止sql注入
- 代码层防止sql注入攻击的最佳方案就是sql预编译(prepareedstatement类)
- 规定数据长度,能在一定程度上防止sql注入
- 严格限制数据库权限,能最大程度减少sql注入的危害
篇幅限制下面就只能给大家展示小册部分内容了。包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记的【点击此处即可】即可免费获取