Boost.Log教程参考
Boost.Log
【译】Boost官方文档 log 模块,地址 https://www.boost.org/doc/libs/1_76_0/libs/log/doc/html/index.html
动机
如今,应用程序快速的增长,变得复杂且难以测试和调试。大多数情况下,应用程序在远程站点上运行,一旦发生故障,开发人员几乎没有机会监控其执行并找出故障原因。此外,如果应用程序行为严重依赖于异步的处理过程,例如是被反馈或其他进程活动,则即使是本地调试也可能出现问题。
这是日志记录可以提供帮助的地方。应用程序将有关执行的所有基本信息存储在日志中,当出现问题时,此信息可用于分析程序行为并进行必要的更正。日志记录还有其他非常有用的地方,例如收集统计信息和突出显示事件(即指示某些情况已发生或应用程序遇到某些问题)。事实证明,这些任务对于许多现实世界的工业应用至关重要。
该库皆在使用应用程序开发人员的日志记录变的更加容易。它提供了广泛的开箱即用的工具以及用于扩展库的公共接口。库的目标主要目标是:
- 简单。一个小的示例代码片段应该足以了解该库的,并可以使用其基本功能。
- 可扩展性。用户应该能够扩展库的功能以收集信息将其存储到日志中。
- 表现。该库对用户的应用程序的性能影响尽可能的小。
定义
以下是一些将在整个文档中广泛使用的术语的定义:
- 日志记录:用户的应用程序收集的单个信息包,它是要放置日志时候的候选信息,在简单的情况下,日志记录在被日志库处理后在日志文件中表示为一行文本。
- 属性:属性是一条元信息,可用于专门化日志记录。在Boost.Log中,属性具有特定接口的函数对象表示,调用时返回实际的属性值。
- 属性值:属性值是从属性中获取的实际数据,此数据附加到特定日志记录并由库处理。值可以有不同的类型(整数、字符串、和更复杂的,包括用户定义的类型)。属性值的一些示例:当前时间戳值、文件名、行号、当前作用域等。属性值被封装在类型隐藏包装器中、因此此属性的实际类型在接口中不可见。值的实际(隐藏)类型有时候被称为存储类型。
- (属性)值访问:一种处理属性值的方式。这种方法涉及一个应用于数据值的函数对象(访问者)。访问者应该知道属性值的存储类型以便于对其进行处理。
- (属性)值提取:当调用者尝试获取对存储值的引用时处理属性值的一种方式。调用者应该知道属性值的存储类型以便能够提取它。
- 日志接收器:一个目标,所有日志记录在从用户的应用程序收集 后都会馈送到该目标。接收器定义了日志记录将被存储或处理的位置和方式。
- 日志来源:用户应用程序用来放置日志的入口点。在一个简单的情况下,它就是一个对象(记录器),它维护一组属性,这属性将用于根据用户的请求形成日志记录。但是,可以肯定地创建一个源,它会在某些副事件上发出日志记录(例如,通过拦截和解析另一个应用程序的控制台输出)。
- 日志过滤器:一个谓词,它接受一个日志记录并告诉该记录是应该通过还是丢弃。谓词通常根据附加到记录的属性值形成决策。
- 日志格式化程序:从日志记录生成到最终文本输出函数对象。一些接收器,例如二进制日志接收器,可能不需要它,尽管几乎所有基于文本的接收器都会使用格式化程序来组成其输出。
- 日志核心:维护源与接收器之间的连接并通过过滤器应用于记录的全局实体。主要在日志库的初始化时使用。
- 国际化:操作宽字符的能力。
- TLS:线程本地存储,拥有一个变量的概念,该变量对于访问它的每个线程具有独特的值。
- 实时传输时间:运行时类型信息。这是所需的c++语言支持的数据结构dynamic_cast和typeid操作员功能正常。
设计概念
Boost.Log 被设计为非常模块化和可扩展的。它支持窄字符和宽字符日志记录。窄字符记录器和宽字符记录器都提供类似的功能,因此在大多数文档中,将仅描述窄字符接口。
该库由三个主要层组成:日志数据收集层、收集数据处理层和连接前两层的中心枢纽。设计如下图所示
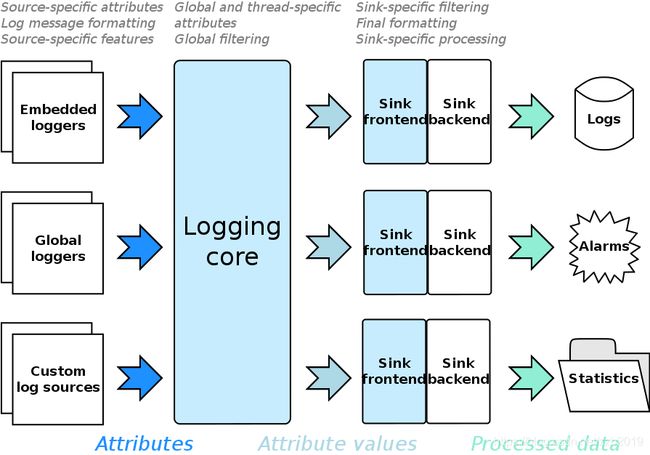
箭头显示了日志信息流的方向 - 从左侧的应用程序部分到右侧的最终存储(如果有)。存储是可选的,因为日志处理的结果可能包括一些操作,而实际上并未将信息存储在任何地方。例如,如果您的应用程序处于临界状态,它可以发出将被处理的特殊日志记录,以便用户在系统托盘中的应用程序图标上看到错误消息作为工具提示通知并听到警报声. 这是一个非常重要的库功能:它与收集、处理日志数据以及实际上数据日志记录的组成正交。这允许将库不仅用于经典日志记录,
日志来源
回到图中,在左侧,您的应用程序在记录器的帮助下发出日志记录 - 特殊对象提供流来格式化最终将被写入日志的消息。该库提供了许多不同的记录器类型,您可以自己制作更多记录器,扩展现有的记录器类型。记录器被设计为不同功能的混合,可以以任何组合相互组合。您可以简单地开发自己的功能并将其添加到汤中。您将能够像其他人一样使用构造的记录器 - 将其嵌入到您的应用程序类中或创建和使用记录器的全局实例。这两种方法都有其好处。将记录器嵌入到某个类中提供了一种将日志与该类的不同实例区分开来的方法。另一方面,在函数式编程中,在某处拥有一个全局记录器并对其进行简单访问通常更方便。
一般来说,库不需要使用loggers来写日志。更通用的术语“日志源”指的是通过构建日志记录来启动日志记录的实体。其他日志源可能包括捕获的子应用程序的控制台输出或从网络接收的数据。但是,记录器是最常见的日志源类型。
属性和属性值
为了启动日志记录,日志源必须将与日志记录关联的所有数据传递到日志记录核心。这些数据,或者更准确地说,数据获取的逻辑用一组命名属性表示。每个属性基本上都是一个函数,其结果称为“属性值”,实际上会在进一步的阶段进行处理。属性的一个示例是返回当前时间的函数。它的结果 - 特定时间点 - 是属性值。
共有三种属性集:
-
全球的
-
线程特定的
-
特定来源
图中可以看到前两组是由日志核心维护的,不需要日志源传递来启动日志。参与全局属性集的属性会附加到曾经创建的任何日志记录。显然,特定于线程的属性仅附加到由它们在集合中注册的线程创建的记录。特定于源的属性集由启动日志记录的源维护,这些属性仅附加到通过该特定源生成的记录。
当源启动日志记录时,从所有三个属性集的属性中获取属性值。然后,这些属性值形成一组命名的属性值,并对其进行进一步处理。您可以向集合中添加更多属性值;这些值只会附加到特定的日志记录,不会与日志记录源或日志记录核心相关联。您可能会注意到,同名属性可能出现在多个属性集中。这种冲突是按优先级解决的:全局属性的优先级最低,特定于源的属性的优先级最高;发生冲突时,优先级较低的属性将被排除在外。
记录核心和过滤
当组成属性值集时,日志记录核心决定是否要在接收器中处理此日志记录。这称为过滤。有两层过滤可用:全局过滤首先应用于日志核心本身,并允许快速擦除不需要的日志记录;特定于接收器的过滤是第二个应用,分别用于每个接收器。特定于接收器的过滤允许将日志记录定向到特定接收器。请注意,此时哪个日志源发出记录并不重要,过滤仅依赖于附加到记录的属性值集。
必须提到的是,对于给定的日志记录过滤只执行一次。显然,只有在过滤开始之前附加到记录的那些属性值才能参与过滤。一些属性值,如日志记录消息,通常在过滤完成后附加到记录上;这些值不能在过滤器中使用,它们只能由格式化程序和接收器本身使用。
接收器和格式
如果日志记录通过至少一个接收器的过滤,则该记录被认为是可消费的。如果接收器支持格式化输出,则这是进行日志消息格式化的时间点。格式化的消息连同组成的属性值集被传递到接受记录的接收器。请注意,格式化是在每个接收器的基础上执行的,以便每个接收器都可以以其自己的特定格式输出日志记录。
正如您在上图中可能已经注意到的那样,接收器由两部分组成:前端和后端。进行这种划分是为了将接收器的通用功能(例如过滤、格式化和线程同步)提取到单独的实体(前端)中。Sink 前端由库提供,很可能用户不必重新实现它们。另一方面,后端是扩展库最有可能的地方之一。实际处理日志记录的是接收器后端。可以有一个接收器将日志记录存储到文件中;可以有一个接收器,通过网络将日志记录发送到远程日志处理节点;可能有上述接收器将记录消息放入工具提示通知中 - 您可以命名它。
除了上述主要工具外,该库还提供了多种辅助工具,例如属性、对格式化程序和过滤器的支持、表示为 lambda 表达式,甚至是库初始化的基本帮助程序。您可以在详细功能描述部分找到它们的描述。但是,对于新用户,建议从教程部分开始发现库。
教程
琐碎的日志记录
对于那些不想阅读大量手册只需要一个简单的日志记录工具来说,该BOOST_LOG_TRIVIAL宏接受严重级别并生成支持插入运算符的类流对象(示例如下)。作为此代码的结果,日志消息将打印在控制台上。该宏有以下特点 :
-
除了记录消息,输出中的每条日志记录都包含时间戳、当前线程标识和严重性级别。
-
从不同线程并发写入日志是安全的,日志消息不会被破坏。
-
正如稍后将展示的,可以用于过滤。
需要提的一点是,宏以及库提供的其他类似宏并不是库提供的唯一接口。可以在不适用任何宏的情况下发布日志记录。
#include
int main(int, char*[])
{
BOOST_LOG_TRIVIAL(trace) << "A trace severity message";
BOOST_LOG_TRIVIAL(debug) << "A debug severity message";
BOOST_LOG_TRIVIAL(info) << "An informational severity message";
BOOST_LOG_TRIVIAL(warning) << "A warning severity message";
BOOST_LOG_TRIVIAL(error) << "An error severity message";
BOOST_LOG_TRIVIAL(fatal) << "A fatal severity message";
return 0;
}
带过滤器的简单日志记录
虽然严重性级别可用于提供信息目的,但您通常希望应用过滤器以仅输出重要记录并忽略其余记录。通过在库核心中设置全局过滤器很容易做到这一点,如下所示:
#include
#include
#include
namespace logging = boost::log;
void init()
{
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
int main(int, char*[])
{
init();
BOOST_LOG_TRIVIAL(trace) << "A trace severity message";
BOOST_LOG_TRIVIAL(debug) << "A debug severity message";
BOOST_LOG_TRIVIAL(info) << "An informational severity message";
BOOST_LOG_TRIVIAL(warning) << "A warning severity message";
BOOST_LOG_TRIVIAL(error) << "An error severity message";
BOOST_LOG_TRIVIAL(fatal) << "A fatal severity message";
return 0;
}
现在,如果我们运行此代码示例,前两个日志记录将被忽略,而其余四个将传递到控制台。
注意:请记住,仅当记录通过过滤时才会执行流表达式。不要在流表达式中指定关键业务调用,因为如果记录被过滤掉,这些调用可能不会被调用。
关于过滤器设置表达式,必须说几句话。由于我们正在设置全局过滤器,因此我们必须获取日志记录核心实例。这就是 它的作用 - 它返回一个指向核心单例的指针。 日志核心的方法设置了全局过滤功能。 logging::core::get()set_filter
此示例中的过滤器构建为Boost.Phoenix lambda 表达式。在我们的例子中,这个表达式由一个逻辑谓词组成,它的左参数是一个占位符,描述要检查的属性,右参数是要检查的值。该severity关键字是由图书馆提供的占位符。此占位符标识模板表达式中的严重性属性值;此值应具有名称“严重性”和类型severity_level. 该属性由库自动提供,以备不时之需;用户只需要在日志语句中提供它的值。占位符与排序运算符一起创建一个函数对象,日志记录核心将调用该函数对象来过滤日志记录。因此,只有严重级别不低于的日志记录info 才能通过过滤器并最终出现在控制台上。
可以构建更复杂的过滤器,将这样的逻辑谓词相互组合,甚至定义您自己的函数(包括 C++11 lambda 函数)作为过滤器。我们将在以下部分返回过滤。
设置接收器
有时,琐碎的日志记录并不能提供足够的灵活性。例如,人们可能想要更复杂的日志处理逻辑,而不是简单的打印在控制台上。为了自定义它,您必须构建日志接收器并将它们注册到日志记录核心。这通常应该只在应用程序的启动代码中的某处完成一次。必须提到的是,在前面的部分中,我们没有初始化任何接收器,无论如何,琐碎的日志记录都以某种方式起作用。这是因为库包含一个默认接收器,当用户没有设置任何接收器的时候,该接收器作为后备。这个接收器总是以我们在前面例子中看到的固定格式将日志记录打印到控制台。提供默认接收器主要是为了允许立即使用简单的日志记录,而无需任何库的初始化。将任何接收器添加到日志核心后,将不再使用默认接收器,不过,您仍然可以使用简单的日志宏。
释放文件记录
作为起点,以下是您将日志初始化到文件的方法:
void init()
{
logging::add_file_log("sample.log");
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
添加的部分是对add_file_log函数的调用,顾名思义,该函数会初始化一个将日志记录存储到文件中的日志接收器,该函数还接受许多自定义选项,例如文件轮换间隔和大小限制。例如:
#include
#include
#include
#include
#include
#include
#include
#include
namespace logging = boost::log;
namespace src = boost::log::sources;
namespace sinks = boost::log::sinks;
namespace keywords = boost::log::keywords;
#if 0
void init()
{
logging::add_file_log("sample.log");
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log",
keywords::rotation_size = 10 * 1024 * 1024,
keywords::time_based_rotation = sinks::file::rotation_at_time_point(0, 0, 0),
keywords::format = "[%TimeStamp%]: %Message%"
);
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
#else
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log", /*< file name pattern >*/
keywords::rotation_size = 10 * 1024 * 1024, /*< rotate files every 10 MiB... >*/
keywords::time_based_rotation = sinks::file::rotation_at_time_point(0, 0, 0), /*< ...or at midnight >*/
keywords::format = "[%TimeStamp%]: %Message%" /*< log record format >*/
);
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
#endif
int main(int, char*[])
{
init();
logging::add_common_attributes();
using namespace logging::trivial;
src::severity_logger< severity_level > lg;
BOOST_LOG_SEV(lg, trace) << "A trace severity message";
BOOST_LOG_SEV(lg, debug) << "A debug severity message";
BOOST_LOG_SEV(lg, info) << "An informational severity message";
BOOST_LOG_SEV(lg, warning) << "A warning severity message";
BOOST_LOG_SEV(lg, error) << "An error severity message";
BOOST_LOG_SEV(lg, fatal) << "A fatal severity message";
return 0;
}
您可以看到选项以命名形式传递给函数。图书馆的许多其他地方采用了这种方法,您可以注册多个接收器,当您独立于其他接收器发出日志记录时,每个接收器都会接收和处理日志记录。
更多的细节
如果您需要对接收器配置进行更全面的控制,或者想要使用比通过辅助函数可用的接收器更多的接收器,您可以手动注册接收器。
在最简单的形式中,对add_file_log上一节的函数的调用等同于:
#include
#include
#include
#include
#include
#include
#include
#include
#include
namespace logging = boost::log;
namespace src = boost::log::sources;
namespace sinks = boost::log::sinks;
//[ example_tutorial_file_manual
void init()
{
// Construct the sink
typedef sinks::synchronous_sink< sinks::text_ostream_backend > text_sink;
boost::shared_ptr< text_sink > sink = boost::make_shared< text_sink >();
// Add a stream to write log to
sink->locked_backend()->add_stream(
boost::make_shared< std::ofstream >("sample.log"));
// Register the sink in the logging core
logging::core::get()->add_sink(sink);
}
//]
int main(int, char*[])
{
init();
src::logger lg;
BOOST_LOG(lg) << "Hello world!";
return 0;
}
好的,您可能注意到接收器的第一件事是它们由两个类组成:前端和后端。前端(即synchronous_sink)负责所有接收器的各种常见任务,例如线程同步模型、过滤以及基于文本的接收器的格式化。后端(text_ostream_backend)上面的类)实现了特定于接收器的所有内容,例如在这种情况下写入文件。该库提供了许多开箱即用的前端和后端。
synchronous_sink上面 的类模板表明接收器是同步的,即它允许多个线程同时登录,并在发生争用时阻塞。这意味着后端text_ostream_backend根本不必担心多线程。还有其他接收器前端可用,
本text_ostream_backend类格式写入日志记录到STL兼容的流。我们在上面使用了文件流,但我们可以使用任何类型的流。例如,将输出添加到控制台可能如下所示:
#include
// 我们必须提供一个空的删除器来避免销毁全局流对象
boost::shared_ptr< std::ostream > stream(&std::clog, boost::null_deleter());
sink->locked_backend()->add_stream(stream);
请注意注册多个不同的接收器和注册一个接收器与多个目标流之间的区别。虽然前者允许独立定制每个接收器的输出,但如果不需要这种定制,后者的工作速度会快得多。此功能特定于此特定后端。
该库提供了许多 提供不同日志处理逻辑的后端。例如,通过指定syslog后端,您可以通过网络将日志记录发送到 syslog 服务器,或者通过设置Windows NT 事件日志后端,您可以使用标准 Windows 工具监视应用程序运行时间。
这里值得注意的最后一件事是locked_backend 访问接收器后端的成员函数调用。它用于获得对后端的线程安全访问,并由所有接收器前端提供。这个函数返回一个指向后端的智能指针,只要它存在,后端就会被锁定(这意味着即使另一个线程尝试记录并且日志记录被传递到接收器,它也不会被记录,直到您释放后端)。唯一的例外是unlocked_sink前端根本不同步,只是简单地向后端返回一个未锁定的指针。
创建记录器和写入日志
专用记录器对象
现在我们定义了日志的存储位置和方式,是时候继续尝试记录日志了。为了做到这一点,必须创建一个日志记录源。在我们的例子中,这将是一个记录器对象。 src::logger lg; 就这么简单。可能会注意到我们之前并没有为琐碎的日志记录创建任何记录器。事实上,记录器是由库提供的,并在幕后使用。
与接收器不同,源不需要在任何地方注册,因为它们直接与日志记录核心交互。另外请注意,库提供了两个版本的记录器:线程安全和非线程安全的。对于非线程安全的记录器,不同的线程记录器的不同实例写入日志是安全的,因此每个写入日志的线程都应该有一个单独的记录器。可以从不同的线程同时访问线程安全的对应物,但这涉及到锁定,并且在大量日志记录情况下可能会减慢速度。线程安全记录器类型_mt在其名称中带有后缀。
全局记录器对象
如果您不能将记录器放入您的类中(假设你没有),该库提供了一种声明全局记录器的方法,如下方式:
BOOST_LOG_INLINE_GLOBAL_LOGGER_DEFAULT(my_logger, src::logger_mt)
my_logger是一个用户定义的标签名称,稍后将用于检索记录器实例,并且logger_mt是记录器类型。库提供的或用于定义的任何记录器类型都可以参与声明。但是,由于记录器只有一个实例,您通常希望在多线程应用程序中将线程安全记录器用于全局记录器。
稍后您可您可以像这样获取记录器:
src::logger_mt& lg = my_logger::get();
该lg会指的是一个和整个应用程序的记录器的唯一实例,即使应用程序由多个模块组成。该get函数本身是线程安全的,因此不需要在它周围进行额外的同步。
写日志
无论您使用哪种记录器(类成员或全局,线程安全与否),要将日志记录写入记录器,您可以这样写:
logging::record rec = lg.open_record()
if(rec)
{
logging::record_ostream strm(rec);
strm<<"Hello , World";
strm.flush();
lg.push_record(boost::move(rec));
}
在这里,open_record函数调用确定要构造的记录是否将被至少一个接收器消耗,在此阶段应用过滤,如果要消费记录,函数返回一个有效的记录对象,可以填写记录消息字符串。之后,可以通过调用来完成记录处理push_record。当然,上面的语法可以很容易地封装在宏中,实际上,鼓励用户编写自己的宏,而不是直接使用c++记录器的接口。上面的日志记录可以这样写:
BOOST_LOG(lg) << "Hello, World!";
看起来有点短,不是吗?在BOOST_LOG宏中,与其他同类的方法一起被库定义。它自动提供类似STL的流,以便使用普通插入表达格式化消息。编写、编译和执行所有这些代码后,您应该可以看到“Hello,World!“ 记录在sample.log中。
以下是完整代码:
#include
#include
#include
#include
#include
#include
namespace logging = boost::log;
namespace src = boost::log::sources;
namespace keywords = boost::log::keywords;
BOOST_LOG_INLINE_GLOBAL_LOGGER_DEFAULT(my_logger, src::logger_mt)
void logging_function1()
{
src::logger lg;
//[ example_tutorial_logging_manual_logging
logging::record rec = lg.open_record();
if (rec)
{
logging::record_ostream strm(rec);
strm << "Hello, World!";
strm.flush();
lg.push_record(boost::move(rec));
}
//]
}
void logging_function2()
{
src::logger_mt& lg = my_logger::get();
BOOST_LOG(lg) << "Greetings from the global logger!";
}
int main(int, char*[])
{
logging::add_file_log("sample.log");
logging::add_common_attributes();
logging_function1();
logging_function2();
return 0;
}
向日志添加更多信息:属性
在前面的部分中,我们多次提到属性,在这里,我们将了解如何使用属性向日志记录添加更多的数据。
每个日志记录可以附加多个命名属性值。属性可以表示在有关发生日志记录的条件的任何基本信息,例如代码中的位置、可执行模块名称、当前日期和时间,或与您的特定应用程序和执行环境相关的任何数据。一个属性可能表现为一个值生成器,在这种情况下,它会为它所涉及的每个日志记录返回一个不同的值。 一旦属性生成值,后者就独立于创建者,可以被过滤器、格式化程序使用和下沉。但是为了使用属性值,必须知道它的名称和类型,或者至少它可能具有的一组类型。
除此之外,如设计概述中所述部分,有三个可能的属性范围:特定于源的、特定于线程的和全局的。生成日志记录时,这三个集合中的属性值将合并为一个集合并传递给接收器。这意味着属性的起源对接收器没有影响。任何属性都可以在任何范围内注册。注册时,属性会被赋予一个唯一的名称,以便可以对其进行搜索。如果碰巧在多个作用域中发现相同的命名属性,则在任何进一步处理(包括过滤和格式化)中都会考虑来自最具体作用域的属性。这种行为可以使用在本地记录器中注册的属性覆盖全局或线程范围的属性,下面是对属性注册过程的描述。
常用属性
几乎所有的应用程序中都可能使用的属性。日志记录计数器和时间戳是不错的选择。它们可以通过单个函数调用添加:
logging::add_common_attributes();
使用此调用属性"LineID",“TimeStamp”,“ProcessID”,"ThreadID"被全局注册。"LineId"属性是一个计数器,为每条记录递增,第一个记录获得标识符1。
"TimeStamp"属性总是生产当前时间(即创建日志记录的时间,而不是写入它到文件的时间).最后两个属性标识发出每个日志记录的进程和线程。
注:在单线程构建中,未注册“ThreadID”属性。默认情况下,当应用程序启动时候,不会在库中注册任何属性。应用程序必须在开始写入日志之前在库中注册所有必要的属性。这可以作为库初始化的一部分来完成。好奇的读者可能想知道微不足道的日志记录是如何工作的。答案是默认接收器实际上不适用任何属性值(严重性级别除外)来组成其输出。这样做是为了避免对琐碎日志进行任何初始化的需要。一旦你使用过滤器或格式化程序和非默认接收器,您将必须注册您需要的属性。
该add_common_attributes函数是这里描述的几个便利助手之一。
某些属性记录器构造时自动注册。例如,severity_logger注册特定于源的属性“严重性”,可用于不同的日志记录添加强调级别。例如:
// We define our own severity levels
enum severity_level
{
normal,
notification,
warning,
error,
critical
};
void logging_function()
{
// The logger implicitly adds a source-specific attribute 'Severity'
// of type 'severity_level' on construction
src::severity_logger< severity_level > slg;
BOOST_LOG_SEV(slg, normal) << "A regular message";
BOOST_LOG_SEV(slg, warning) << "Something bad is going on but I can handle it";
BOOST_LOG_SEV(slg, critical) << "Everything crumbles, shoot me now!";
}
注:您可以通过为此类型定义自己的格式规范。它将被库格式化程序自动使用。
所述的BOOST_LOG_SEV宏的作用非常像BOOST_LOG 不同之处在于它需要在一个额外的参数open_record的记录器的方法。改BOOST_LOG_SEV宏可以与此等价物来替换:
void manual_logging()
{
src::severity_logger< severity_level > slg;
logging::record rec = slg.open_record(keywords::severity = normal);
if (rec)
{
logging::record_ostream strm(rec);
strm << "A regular message";
strm.flush();
slg.push_record(boost::move(rec));
}
}
您可以在此处看到open_record可以采用命名参数。库提供的一些记录器类型支持此类附加参数,用户在编写自己的记录器时当然可以使用此种方法。
更多属性
让我们看看add_common_attributes 我们在简单表单部分中使用的那个函数背后是什么。它可能看起来像这样:
void add_common_attributes()
{
boost::shared_ptr< logging::core > core = logging::core::get();
core->add_global_attribute("LineID", attrs::counter< unsigned int >(1));
core->add_global_attribute("TimeStamp", attrs::local_clock());
// other attributes skipped for brevity
}
这里的couter和local_clock组件是属性类,它们派生自公共接口attribute。该库提供了许多其他属性类,包括function在值获取时调用某些函数对象的属性。例如,我们可以以类的方式注册一个named_scope属性:
core->add_global_attribute("Scope", attrs::named_scope());
这将使我们能够为应用程序生成每个日志记录在日志中存储范围名称,这是它的使用方法:
void named_scope_logging()
{
BOOST_LOG_NAMED_SCOPE("named_scope_logging");
src::severity_logger< severity_level > slg;
BOOST_LOG_SEV(slg, normal) << "Hello from the function named_scope_logging!";
}
特定于记录器的属性并不比全局属性有用。严重性级别和通道名称是在源级别实施的最明显的候选者。没有什么可以阻止您向记录器添加更多属性,如下所示:
void tagged_logging()
{
src::severity_logger< severity_level > slg;
slg.add_attribute("Tag", attrs::constant< std::string >("My tag value"));
BOOST_LOG_SEV(slg, normal) << "Here goes the tagged record";
}
现在,通过此记录器生成的所有日志记录都将使用特定属性进行标记。此属性值稍后可用于过滤和格式化。
属性的另一个很好用的用途是能够标记由应用程序的不同部分生成的日志记录,以突显与单个进程相关的活动。甚至可以实现一个粗略的分析工具来检测性能瓶颈。例如:
void timed_logging()
{
BOOST_LOG_SCOPED_THREAD_ATTR("Timeline", attrs::timer());
src::severity_logger< severity_level > slg;
BOOST_LOG_SEV(slg, normal) << "Starting to time nested functions";
logging_function();
BOOST_LOG_SEV(slg, normal) << "Stopping to time nested functions";
}
现在,从该logging_function函数或它调用的任何其他函数生成的每个日志记录都包含“时间轴”属性,该属性具有自注册该属性以来经过的高精度持续时间。根据这些读数,人们将能够检测到代码的哪些部分需要更多或更少的时间来执行。离开函数作用域后,“时间轴”属性将被注销timed_logging。
定义属性占位符
正如我们将在接下里这部分中看到的,定义一个描述应用程序使用的特定属性的关键字很有用。这个关键字将能够参与过滤和格式化表达式,就像severity我们在前几节中使用的占位符一样。例如,要为我们在前面示例中使用的一些属性定义占位符,我们可以这样写:
BOOST_LOG_ATTRIBUTE_KEYWORD(line_id, "LineID", unsigned int)
BOOST_LOG_ATTRIBUTE_KEYWORD(severity, "Severity", severity_level)
BOOST_LOG_ATTRIBUTE_KEYWORD(tag_attr, "Tag", std::string)
BOOST_LOG_ATTRIBUTE_KEYWORD(scope, "Scope", attrs::named_scope::value_type)
BOOST_LOG_ATTRIBUTE_KEYWORD(timeline, "Timeline", attrs::timer::value_type)
每个宏定义一个关键字。第一个参数是占位符名称,第二个参数是属性名称,最后一个参数是属性值类型。定义后,占位符可用于模板表达式和库的其他一些上下文。
日志记录格式
如果您尝试运行前几节中的示例,您可能已经注意到只有日志记录消息会写入文件。这是未设置格式化程序时库的默认行为。即使您向 日志记录核心或记录器添加了属性,属性值也不会到达输出,除非您指定将使用这些值的格式化程序。
回到前面教程部分中的示例之一:
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log",
keywords::rotation_size = 10 * 1024 * 1024,
keywords::time_based_rotation = sinks::file::rotation_at_time_point(0, 0, 0),
keywords::format = "[%TimeStamp%]: %Message%"
);
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
在add_file_log函数的情况下,该format参数允许指定日志记录的格式。如果您更喜欢手动设置接收器,接收器前端set_formatter为此提供了成员函数。
可以通过多种方式指定格式,如下所述。
Lambda 风格的格式化程序
您可以使用lambda样式的表达式创建格式化程序,如下所示:
//完整代码
#include
#include
#include
#include
#include
#include
#include
#include
namespace logging = boost::log;
namespace src = boost::log::sources;
namespace expr = boost::log::expressions;
namespace keywords = boost::log::keywords;
#if 1
//[ example_tutorial_formatters_stream
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log",
// This makes the sink to write log records that look like this:
// 1: A normal severity message
// 2: An error severity message
keywords::format =
(
expr::stream
<< expr::attr< unsigned int >("LineID")
<< ": <" << logging::trivial::severity
<< "> " << expr::smessage
)
);
}
//]
#else
//[ example_tutorial_formatters_stream_date_time
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log",
// This makes the sink to write log records that look like this:
// YYYY-MM-DD HH:MI:SS: A normal severity message
// YYYY-MM-DD HH:MI:SS: An error severity message
keywords::format =
(
expr::stream
<< expr::format_date_time< boost::posix_time::ptime >("TimeStamp", "%Y-%m-%d %H:%M:%S")
<< ": <" << logging::trivial::severity
<< "> " << expr::smessage
)
);
}
//]
#endif
int main(int, char*[])
{
init();
logging::add_common_attributes();
using namespace logging::trivial;
src::severity_logger< severity_level > lg;
BOOST_LOG_SEV(lg, trace) << "A trace severity message";
BOOST_LOG_SEV(lg, debug) << "A debug severity message";
BOOST_LOG_SEV(lg, info) << "An informational severity message";
BOOST_LOG_SEV(lg, warning) << "A warning severity message";
BOOST_LOG_SEV(lg, error) << "An error severity message";
BOOST_LOG_SEV(lg, fatal) << "A fatal severity message";
return 0;
}
这里的stream是流的占位符,用于格式化记录。其他插入参数,例如attr和message,是定义应该存储在流中的内容的操作符。我们已经severity在过滤表表达式中看到了占位符,这里它用于格式化程序。这是一个很好的统一:您可以在过滤器和格式化程序中使用相同的占位符。该attr占位符类似于severity占位符,因为它代表的属性值太多。不同之处在于severity占位符代表具有名称“严重性”和类型的特定属性和trivial::severity_levelattr可用于表示任何属性。否则这两个占位符是等效的。例如,可以替换severity为以下内容:
expr::attr("Severity")
注意:如上一节所示,可以severity为用户属性定义占位符。作为模板表达式中更简单语法的额外好处,此类占位符允许将有关属性(名称和值类型)的所有信息集中在占位符定义中。这使得编码不容易出错(您不会拼错属性名称或指定不正确的值类型),因此是定义新属性并在模板表达式中使用它们的推荐方法。
还有其他格式化程序操纵器为日期、时间和其他类型提供高级支持。一些操纵器接受自定义其行为的附加参数。这些参数中大多数都是命名的,可以以Boost.Paramter样式传递。
对于更改,让我们看看手动初始化接收器时它是如何完成的:
//完整代码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
namespace logging = boost::log;
namespace src = boost::log::sources;
namespace expr = boost::log::expressions;
namespace sinks = boost::log::sinks;
namespace keywords = boost::log::keywords;
void init()
{
typedef sinks::synchronous_sink text_sink;
boost::shared_ptr sink = boost::make_shared();
sink->locked_backend()->add_stream(
boost::make_shared("sample.log"));
sink->set_formatter
(
expr::stream
//line id will be written in hex,8-digits,zero-filled
<("LineID")
<<":>"<"<add_sink(sink);
}
int main(int, char*[])
{
init();
logging::add_common_attributes();
using namespace logging::trivial;
src::severity_logger< severity_level > lg;
BOOST_LOG_SEV(lg, trace) << "A trace severity message";
BOOST_LOG_SEV(lg, debug) << "A debug severity message";
BOOST_LOG_SEV(lg, info) << "An informational severity message";
BOOST_LOG_SEV(lg, warning) << "A warning severity message";
BOOST_LOG_SEV(lg, error) << "An error severity message";
BOOST_LOG_SEV(lg, fatal) << "A fatal severity message";
return 0;
}
这里的stream是流的占位符,用于记录格式化记录。其他插入参数,例如attr和message,是定义应该存储在流中的内容的操作符。我们已经在在过滤表达式serverity中看到了占位符,这里它用于格式化程序。这是一个很好的统一:您可以在过滤器和格式化程序中使用相同的占位符。改attr占位符类似于serverity占位符,因为它代表的属性值太多。不同之处在于severity占位符代表具有名称“严重性”和类型的特定属性和 trivil::severity_levelattr可用于表示任何属性。否则这两个占位符是等效的。例如,可以替换成severity为以下内容:
expr::attr("Severity")
如上一节所示,可以severity为用户属性定义占位符。作为模板表达式中更简单语法的额外好处,此类占位符允许将有关属性(名称和值类型)的所有信息集中在占位符定义中。这使得编码不易出错(您不会拼错属性名称或指定不正确的值类型),因此是定义新属性并在模板表达式中使用它们的推荐方法。
还有其他格式化程序操纵器为日期、时间和其他类型提供高级支持。一些操作器接受自定义行为的附加参数。大多数这些参数都是命名的,可以以Boost.Parameter风格传递。
对于更改,让我们看看手动初始化接收器时候它是如何完成的:
void init()
{
typedef sinks::synchronous_sink text_sink;
boost::shared_ptr sink = boost::make_shared();
sink->locked_backend()->add_stream(
boost::make_shared("samle.log"));
sink->set_formatter
(
expr::stream
//line id will be written in hex,8-digits,zero-filled
<("LineID")
<<":<"<"<add_sink(sink);
}
可以看到,可以在表达式中绑定格式更改操作符;这些操作符在格式化日志记录时影响后续的属性值格式,就像使用流一样。
Boost.Format风格格式化程序
作为替代方案,您可以使用类似于Boost.Format的语法定义格式化程序。与上述相同的格式化程序可以写成如下:
void init()
{
typedef sinks::synchronous_sink text_sink;
boost::shared_ptr sink = boost::make_shared();
sink->locked_backend()->add_stream(
boost::make_shared("sample.log"));
//this makes the sink to write log records that look like this;
//1: A normal severity message
//2: An error serverity message
sink->set_formatter
(
expr::format("%1%,<%2%>,%3%")
% expr ::attr("LineID")
% logging ::trivial::severity
% expr::smessage
);
logging::core::get()->add_sink(sink);
}
该format占位符接受格式字符串格式化的所有参数位置规范,请注意,目前仅支持位置格式。相同的格式规范可用于add_file_log和类似的功能。
专业格式化程序
该库format占位符接受格式字符串格式化的所有参数位置规范。请注意,这些格式化程序提供对格式化值的扩展控制。例如,可以使用与Boost.DateTime兼容的格式化字符串来描述日期和时间格式:
void init()
{
logging::add_file_log
(
keywords::file_name = "smple_%N."log,
//This makes the sink to write log records that look like this:
//YYYY-MM-DD HH:MI:SS: A normal severity message
//YYYY-MM-DD HH:MI:SS: An error serverity message
keywords::format =
(
expr::stream
<("TimeStamp","%Y-%m-%d %H:%M:%S")
<<":<"<"< 相同的格式化程序也可以在Boost.Format风格的格式化程序的上下文使用。
作为格式化程序的字符串模板
在某些情况下,文本模板被接受为格式化程序。在这种情况下,调用库初始化支持代码以解析模板并重建适当的格式化程序。使用这种方法时需要记住许多注意事项,但在这里只简要描述模板格式就足够了。
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log",
keywords::format = "[%TimeStamp%]:%Message%"
);
}
在这里,format参数接受这样的格式模板。该模板可能包含许多用百分号 ( %)括起来的占位符。每个占位符必须包含要插入的属性值名称而不是占位符。该占位符将日志记录信息来替代。 %Message%
注:set_formatter方法 中的接收器后端不接受文本格式模板。为了将文本模板解析为格式化函数,必须调用parse_formatter函数。
自定义格式化函数
您可以将自定义格式化程序添加到支持格式化的接收器后端。格式化程序实际上是一个支持以下签名的函数对象:
void(logging::record_view const& rec, logging::basic_formatting_ostream < CharT >& strm);
这CharT是目标字符类型。只要日志记录视图rec通过过滤并存储在日志中,就会调用格式化程序 。
注意:记录视图与记录非常相似。显着的区别是视图是不可变的并且实现了浅拷贝。格式化程序和接收器仅对记录视图进行操作,这可以防止它们在其他线程中的其他接收器仍在使用时修改记录。
格式化的记录应该通过插入到 STL 兼容的输出流中来组成strm。这是自定义格式化程序函数用法的示例:
//完整代码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
namespace logging = boost::log;
namespace src = boost::log::sources;
namespace expr = boost::log::expressions;
namespace sinks = boost::log::sinks;
//[ example_tutorial_formatters_custom
void my_formatter(logging::record_view const& rec, logging::formatting_ostream& strm)
{
// Get the LineID attribute value and put it into the stream
strm << logging::extract< unsigned int >("LineID", rec) << ": ";
// The same for the severity level.
// The simplified syntax is possible if attribute keywords are used.
strm << "<" << rec[logging::trivial::severity] << "> ";
// Finally, put the record message to the stream
strm << rec[expr::smessage];
}
void init()
{
typedef sinks::synchronous_sink< sinks::text_ostream_backend > text_sink;
boost::shared_ptr< text_sink > sink = boost::make_shared< text_sink >();
sink->locked_backend()->add_stream(
boost::make_shared< std::ofstream >("sample.log"));
sink->set_formatter(&my_formatter);
logging::core::get()->add_sink(sink);
}
//]
int main(int, char*[])
{
init();
logging::add_common_attributes();
using namespace logging::trivial;
src::severity_logger< severity_level > lg;
BOOST_LOG_SEV(lg, trace) << "A trace severity message";
BOOST_LOG_SEV(lg, debug) << "A debug severity message";
BOOST_LOG_SEV(lg, info) << "An informational severity message";
BOOST_LOG_SEV(lg, warning) << "A warning severity message";
BOOST_LOG_SEV(lg, error) << "An error severity message";
BOOST_LOG_SEV(lg, fatal) << "A fatal severity message";
return 0;
}
重新审视过滤
我们在前面的章节中已经接触过过滤,但我们几乎没有触及表面。现在我们能够向日志记录添加属性并设置接收器,我们可以构建我们需要的任何复杂过滤。让我们考虑这个例子:
BOOST_LOG_ATTRIBUTE_KEYWORD(line_id, "LineID", unsigned int)
BOOST_LOG_ATTRIBUTE_KEYWORD(severity, "Severity", severity_level)
BOOST_LOG_ATTRIBUTE_KEYWORD(tag_attr, "Tag", std::string)
void init()
{
// Setup the common formatter for all sinks
logging::formatter fmt = expr::stream
<< std::setw(6) << std::setfill('0') << line_id << std::setfill(' ')
<< ": <" << severity << ">\t"
<< expr::if_(expr::has_attr(tag_attr))
[
expr::stream << "[" << tag_attr << "] "
]
<< expr::smessage;
// Initialize sinks
typedef sinks::synchronous_sink< sinks::text_ostream_backend > text_sink;
boost::shared_ptr< text_sink > sink = boost::make_shared< text_sink >();
sink->locked_backend()->add_stream(
boost::make_shared< std::ofstream >("full.log"));
sink->set_formatter(fmt);
logging::core::get()->add_sink(sink);
sink = boost::make_shared< text_sink >();
sink->locked_backend()->add_stream(
boost::make_shared< std::ofstream >("important.log"));
sink->set_formatter(fmt);
sink->set_filter(severity >= warning || (expr::has_attr(tag_attr) && tag_attr == "IMPORTANT_MESSAGE"));
logging::core::get()->add_sink(sink);
// Add attributes
logging::add_common_attributes();
}
在这个示例中,我们初始化了两个接收器——一个用于完整的日志文件,另一个用于仅用于重要消息。两个接收器都将写入具有相同日志记录格式的文本文件,我们首先对其进行初始化并保存到fmt变量中。该 formatter类型是一个类型擦除的函数对象,带有格式化程序调用签名;在许多方面,它可以被视为类似于 或不同之处在于它从不为空。还有 过滤器。 boost::function``std::function``a similar function object
值得注意的是,格式化程序本身在此处包含一个过滤器。如您所见,该格式包含一个条件部分,该部分仅在日志记录包含“Tag”属性时出现。该has_attr谓词检查记录是否包含“变量”的属性值和控件是否被放入该文件或没有。我们使用属性关键字为谓词指定属性的名称和类型,但也可以在has_attr调用站点中指定它们。此处更详细地解释了条件格式化程序。
进一步进行两个接收器的初始化。第一个接收器没有任何过滤器,这意味着它会将每条日志记录保存到文件中。我们呼吁set_filter第二个接收器仅保存严重性不低于warning 或具有值为“IMPORTANT_MESSAGE”的“Tag”属性的日志记录。如您所见,过滤器语法与通常的 C++ 非常相似,尤其是在使用属性关键字时。
与格式化程序一样,也可以使用自定义函数作为过滤器。从根本上说,过滤器函数必须支持以下签名:
bool (logging::attribute_value_set const& attrs);
当过滤器被调用时,attrs 将包含一组完整的属性值,可用于决定是否应该传递或抑制日志记录。如果过滤器返回 true,则日志记录将被构建并由接收器进一步处理。否则,该记录将被丢弃。
Boost.Phoenix 在构建过滤器方面非常有帮助。它允许从attrs 集合中自动提取属性值,因为它的bind实现与属性占位符兼容。可以通过以下方式修改前面的示例:
bool my_filter(logging::value_ref< severity_level, tag::severity > const& level,
logging::value_ref< std::string, tag::tag_attr > const& tag)
{
return level >= warning || tag == "IMPORTANT_MESSAGE";
}
void init()
{
// ...
namespace phoenix = boost::phoenix;
sink->set_filter(phoenix::bind(&my_filter, severity.or_none(), tag_attr.or_none()));
// ...
}
如您所见,自定义过滤器接收属性值作为单独的参数,并包装到value_ref模板中。此包装器包含对指定类型的属性值的可选引用;如果日志记录包含所需类型的属性值,则引用有效。中使用的关系运算符my_filter 可以无条件应用,因为false如果引用无效,它们将自动返回。剩下的部分是用bind表达式完成的,该表达式将识别severity 和tag_attr关键字并在将它们传递给 之前提取相应的值my_filter。
由于与Boost.Phoenix集成相关的限制 (参见#7996),当属性关键字与或一起使用时,如果缺少属性值,则需要明确指定回退策略。在上面的示例中,这是通过调用 完成的,如果未找到该值,则结果为空。在其他情况下,此策略是默认设置。还有其他策略可以替代。
phoenix::bind``phoenix::function``or_nonevalue_ref
您可以通过编译和运行测试来尝试这是如何工作的。
宽字符记录
该库支持记录包含国家字符的字符串。基本上有两种方法可以做到这一点。在类 UNIX 系统上,通常使用一些多字节字符编码(例如 UTF-8)来表示国家字符。在这种情况下,库可以像用于纯 ASCII 日志记录那样使用,不需要额外的设置。
在 Windows 上,通常的做法是使用宽字符串来表示国家字符。此外,大多数系统 API 都是面向宽字符的,这需要 Windows 特定的接收器也支持宽字符串。另一方面,通用接收器,如文本文件接收器,是面向字节的(因为,你在文件中存储字节,而不是字符)。这会强制库在接收器需要时执行字符代码转换。要为此设置库,必须为接收器注入具有适当codecvt 方面的语言环境。Boost.Locale 可用于生成这样的语言环境。让我们看一个例子:
// Declare attribute keywords
BOOST_LOG_ATTRIBUTE_KEYWORD(severity, "Severity", severity_level)
BOOST_LOG_ATTRIBUTE_KEYWORD(timestamp, "TimeStamp", boost::posix_time::ptime)
void init_logging()
{
boost::shared_ptr< sinks::synchronous_sink< sinks::text_file_backend > > sink = logging::add_file_log
(
"sample.log",
keywords::format = expr::stream
<< expr::format_date_time(timestamp, "%Y-%m-%d, %H:%M:%S.%f")
<< " <" << severity.or_default(normal)
<< "> " << expr::message
);
// The sink will perform character code conversion as needed, according to the locale set with imbue()
std::locale loc = boost::locale::generator()("en_US.UTF-8");
sink->imbue(loc);
// Let's add some commonly used attributes, like timestamp and record counter.
logging::add_common_attributes();
}
首先我们来看看我们传入format 参数的formatter 。我们使用窄字符格式化程序初始化接收器,因为文本文件接收器处理字节。可以在格式化程序中使用宽字符串,但不能在格式字符串中使用,就像我们在format_date_time函数中使用的那样 。另请注意,我们使用message 关键字来表示日志记录消息。此占位符 支持窄字符和宽字符消息,因此格式化程序将同时使用这两种字符。作为格式化过程的一部分,库将使用我们设置为 UTF-8 的灌输语言环境将宽字符消息转换为多字节编码。
属性值也可以包含宽字符串。与日志记录消息一样,这些字符串将使用嵌入的语言环境转换为目标字符编码。
这里缺少的一件事是我们的severity_level 类型定义。类型只是一个枚举,但如果我们想支持窄字符和宽字符接收器的格式,它的流操作符必须是一个模板。如果我们使用不同的字符类型创建多个接收器,这可能很有用。
enum severity_level
{
normal,
notification,
warning,
error,
critical
};
template< typename CharT, typename TraitsT >
inline std::basic_ostream< CharT, TraitsT >& operator<< (
std::basic_ostream< CharT, TraitsT >& strm, severity_level lvl)
{
static const char* const str[] =
{
"normal",
"notification",
"warning",
"error",
"critical"
};
if (static_cast< std::size_t >(lvl) < (sizeof(str) / sizeof(*str)))
strm << str[lvl];
else
strm << static_cast< int >(lvl);
return strm;
}
现在我们可以发出日志记录。我们可以使用w 名称中带有前缀的记录器来组成宽字符消息。
void test_narrow_char_logging()
{
// Narrow character logging still works
src::logger lg;
BOOST_LOG(lg) << "Hello, World! This is a narrow character message.";
}
void test_wide_char_logging()
{
src::wlogger lg;
BOOST_LOG(lg) << L"Hello, World! This is a wide character message.";
// National characters are also supported
const wchar_t national_chars[] = { 0x041f, 0x0440, 0x0438, 0x0432, 0x0435, 0x0442, L',', L' ', 0x043c, 0x0438, 0x0440, L'!', 0 };
BOOST_LOG(lg) << national_chars;
// Now, let's try logging with severity
src::wseverity_logger< severity_level > slg;
BOOST_LOG_SEV(slg, normal) << L"A normal severity message, will not pass to the file";
BOOST_LOG_SEV(slg, warning) << L"A warning severity message, will pass to the file";
BOOST_LOG_SEV(slg, error) << L"An error severity message, will pass to the file";
}
如您所见,宽字符消息组合类似于窄日志记录。请注意,您可以同时使用窄字符和宽字符日志;所有记录都将由我们的文件接收器处理。
必须注意,一些接收器(主要是 Windows 特定的接收器)允许指定目标字符类型。当日志记录中需要国家字符时,wchar_t 在这些情况下应始终将其用作目标字符类型,因为接收器将使用宽字符 OS API 来处理日志记录。在这种情况下,所有窄字符串都将使用执行格式化时灌输到接收器中的语言环境来加宽。