使用Python轻松批量读取Word文档及各种Word元素的文字内容
目录
引言
安装Python Word库
使用 Python 批量读取Word文档的文字内容
使用 Python 读取Word文档特定节的文字内容
使用 Python 读取Word文档特定段落的文字内容
使用 Python 读取Word文档特定页面的文字内容
使用 Python 读取Word文档特定行的文字内容
使用 Python 读取Word文档特定表格的文字内容
使用 Python 读取Word文档页眉和页脚的文字内容
引言
在现代办公环境中,Word文档是一种常见的文件格式,广泛用于书写、编辑和共享各种类型的文本内容。有时候,我们需要从Word文档中提取文字内容,以便进行进一步的处理和分析。通过编程的方式实现这一功能可以极大地提高工作效率,尤其是当需要处理大量文档或进行批量操作时。
这篇博客将探讨如何使用Python从整个Word文档及各种Word元素中读取文字内容:
- 使用 Python 批量读取Word文档的文字内容
- 使用 Python 读取Word文档特定节的文字内容
- 使用 Python 读取Word文档特定段落的文字内容
- 使用 Python 读取Word文档特定页面的文字内容
- 使用 Python 读取Word文档特定行的文字内容
- 使用 Python 读取Word文档特定表格的文字内容
- 使用 Python 读取Word文档页眉和页脚的文字内容
安装Python Word库
在Python中,我们可以使用Spire.Doc for Python库来读取Word文档的内容。
Spire.Doc for Python主要用于在Python应用程序中创建、读取、编辑和转换Word文件。它可以处理各种Word格式,包括Doc、Docx、Docm、Dot、Dotx、Dotm等。此外,还可以将Word文档转换为其他类型的文件格式,如Word转PDF、Word转RTF、Word转HTML、Word转文本、Word转图片、Word转OFD/XPS/PostScript。
你可以通过在终端运行以下命令来从PyPI安装Spire.Doc for Python:
pip install Spire.Doc使用 Python 批量读取Word文档的文字内容
从整个Word文档中提取文本很简单,只需使用Document.GetText()方法。具体步骤如下:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 使用Document.GetText()方法获取该Word文档的文字内容。
- 将获取的文字内容写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("测试.docx")
# 获取文档的文本内容
document_text = document.GetText()
# 将获取的文本内容保存到文本文件
with open("文档文字.txt", "w", encoding="utf-8") as file:
file.write(document_text)
document.Close()
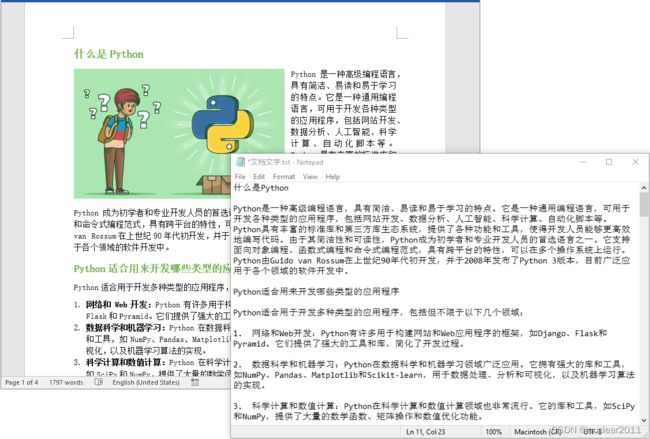
以上代码展示了如何读取一个Word文档的文本内容。如果需要使用Python批量读取一个文件夹下所有Word文档的文字内容,可以使用以下代码,该代码生成的文本文件将以Word文档本身的名称命名:
from spire.doc import *
from spire.doc.common import *
import os
def extract_text_from_word(filename):
document = Document()
document.LoadFromFile(filename)
document_text = document.GetText()
document.Close()
return document_text
# 输入文件夹路径
input_folder_path = "你的输入文件夹/"
# 输出文件夹路径
output_folder_path = "你的输出文件夹/"
# 遍历输入文件夹中的所有文件
for file_name in os.listdir(input_folder_path):
file_path = os.path.join(input_folder_path, file_name)
# 判断文件是否是以.docx或.doc结尾的Word文档
if file_name.endswith((".docx", ".doc")):
text_content = extract_text_from_word(file_path)
output_file = os.path.splitext(file_name)[0] + ".txt"
output_file_path = os.path.join(output_folder_path, output_file)
with open(output_file_path, "w", encoding="utf-8") as output:
output.write(text_content)
print(f"已提取文档内容并保存到文件: {output_file_path}")
使用 Python 读取Word文档特定节的文字内容
Word 文档可能包含不同的节,每个节都包含不同的内容。 Spire.Doc for Python 提供了Document.Sections[index] 属性,用于获取Word 文档中的特定节。 获取后,遍历该节中的段落,然后使用 Paragraph.Text 属性获取每个段落的文本。具体步骤如下:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 使用Document.Sections[index] 属性获取文档的特定节。
- 创建一个列表用于存储提取的文本。
- 遍历该节中的段落。
- 使用 Paragraph.Text 属性获取每个段落的文本并将它们添加至列表。
- 将列表的内容写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("测试.docx")
# 获取第一个节
section = document.Sections[0]
# 创建一个列表用于存储提取的文本
section_text = []
# 遍历第一节中的段落
for i in range(section.Paragraphs.Count):
paragraph = section.Paragraphs[i]
# 获取每个段落的文本并将它们添加至列表
section_text.append(paragraph.Text)
# 将列表的内容写入文本文件
with open("节文字.txt", "w", encoding="utf-8") as file:
file.write("\n".join(section_text))
document.Close()
使用 Python 读取Word文档特定段落的文字内容
要获取特定段落的文字内容,只需使用Section.Paragraphs[index]属性获取该段落,然后使用Paragraph.Text 属性获取它的文本。具体步骤如下:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 使用Document.Sections[index] 属性获取文档的特定节。
- 使用Section.Paragraphs[index]属性获取该节中特定的段落。
- 使用Paragraph.Text 属性获取该段落的文本。
- 将获取的文本写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("测试.docx")
# 获取第一个节
section = document.Sections[0]
# 获取该节的第二个段落
paragraph = section.Paragraphs[1]
# 获取该段落的文本
para_text = paragraph.Text
# 将获取的文本写入文本文件
with open("段落文字.txt", "w", encoding="utf-8") as file:
file.write(para_text)
document.Close()
使用 Python 读取Word文档特定页面的文字内容
技术上来说,Word 文档中没有“页面”的概念,因为Word文档本质上是流式文档,流式布局。 为了方便页面操作,Spire.Doc for Python提供了FixedLayoutDocument类,用于将Word文档转换为固定布局。 使用该类和它提供的属性,可以获取Word文档中特定页面的文本。具体步骤如下:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 创建FixedLayoutDocument类的实例,并将Document对象传给该类的构造函数。该步骤用于将Word文档转换为固定布局。
- 使用FixedLayoutDocument.Pages[index]属性获取特定页面,然后获取该页面的文本。
- 将获取的文本内容写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("测试.docx")
# 创建FixedLayoutDocument类的实例,并将Document对象传递给该类的构造函数
# 该步骤用于将Word文档转换为固定布局
layoutDoc = FixedLayoutDocument(document)
# 获取第一页
layoutPage = layoutDoc.Pages[0]
# 获取该页的文本
page_text = layoutPage.Text
# 将获取的文本写入文本文件
with open("页面文字.txt", "w", encoding="utf-8") as file:
file.write(page_text)
document.Close()
使用 Python 读取Word文档特定行的文字内容
一个Word页面可以包含多行文字,在某些特定情况下,你可能需要获取特定行的文字。以下步骤展示了如何获取Word文档特定行的文字内容:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 创建FixedLayoutDocument类的实例,并将Document对象传给该类的构造函数。该步骤用于将Word文档转换为固定布局。
- 使用FixedLayoutDocument.Pages[index]属性获取特定页面,然后获取该页面的特定行及其文本。
- 将获取的文本内容写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("测试.docx")
# 创建FixedLayoutDocument类的实例,并将Document对象传递给该类的构造函数
# 该步骤用于将Word文档转换为固定布局
layoutDoc = FixedLayoutDocument(document)
# 获取第一页
layoutPage = layoutDoc.Pages[0]
# 获取第一页第一列的第一行
line = layoutPage.Columns[0].Lines[0]
# 获取该行的文本
line_text = line.Text
# 将获取的文本写入文本文件
with open("行文字.txt", "w", encoding="utf-8") as file:
file.write(line_text)
document.Close()
使用 Python 读取Word文档特定表格的文字内容
Word文档中可能包含表格数据。提取表格数据有助于进行进一步数据处理或分析。以下步骤展示了如何获取Word文档中特定表格的数据内容:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 使用Document.Sections[index] 属性获取文档的特定节。
- 使用Section.Tables[index]属性获取该节中特定的表格。
- 创建一个列表用于存储提取的表格数据。
- 遍历表格中的所有行及每行的所有单元格。
- 对于每个单元格,遍历其所有的段落。
- 使用Paragraph.Text属性获取每个段落的文本并将它们添加至列表。
- 将列表的内容写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("报表.docx")
# 获取第一个节
section = document.Sections[0]
# 获取该节的第一个表格
table = section.Tables[0]
# 创建一个列表用于存储提取的表格数据
table_data = []
# 遍历表格的所有行
for i in range(table.Rows.Count):
row = table.Rows[i]
# 遍历每行的所有单元格
for j in range(row.Cells.Count):
cell = row.Cells[j]
# 遍历每个单元格的所有段落
for k in range(cell.Paragraphs.Count):
# 获取段落文本
paragraph = cell.Paragraphs[k]
text = paragraph.Text
# 将段落文本添加至列表
table_data.append(text + "\t")
table_data.append("\n")
# 将列表的内容写入文本文件
with open("表格数据.txt", "w", encoding = "utf-8") as text_file:
for data in table_data:
text_file.write(data)
document.Close()
使用 Python 读取Word文档页眉和页脚的文字内容
页眉和页脚是位于 Word 文档中每页顶部和底部的部分。 它们通常包含文档标题或其他补充信息。以下步骤展示了如何获取Word文档页眉和页脚的文字内容:
- 创建Document实例并使用Document.LoadFromFile()方法加载Word文档。
- 使用Document.Sections[index] 属性获取文档的特定节。
- 通过Section.HeadersFooters.Header和Section.HeadersFooters.Footer属性分别获取该节的页眉和页脚。
- 创建一个列表用于存储提取的文本。
- 遍历页眉中的所有段落,获取每个段落的文本并将其添加至列表。
- 遍历页脚中的所有段落,获取每个段落的文本并将其添加至列表。
- 将列表的内容写入文本文件。
from spire.doc import *
from spire.doc.common import *
# 创建Document实例
document = Document()
# 加载Word文档
document.LoadFromFile("页眉页脚.docx")
# 获取文档的第一个节
section = document.Sections[0]
# 获取该节的页眉
header = section.HeadersFooters.Header
# 获取该节的页脚
footer = section.HeadersFooters.Footer
# 创建列表用于存储提取的页眉和页脚文本内容
header_footer_text = []
header_footer_text.append("页眉文字:")
# 获取页眉的文本并将其添加至列表
for i in range(header.Paragraphs.Count):
headerPara = header.Paragraphs[i]
header_footer_text.append(headerPara.Text)
header_footer_text.append("页脚文字:")
# 获取页脚的文本并将其添加至列表
for i in range(footer.Paragraphs.Count):
footerPara = footer.Paragraphs[i]
header_footer_text.append(footerPara.Text)
# 将列表内容写入文本文件
with open("页眉页脚文字.txt", "w", encoding="utf-8") as file:
file.write("\n".join(header_footer_text))
document.Close()
这篇文章介绍了如何从Word文档及部分Word元素中提取文字内容,由于篇幅限制,并未涵盖所有的Word元素。你可以根据自己的文档元素,适当对代码进行修改或拓展。
本文完结。