#数据结构# 单链表的实现3(C语言)
目录
6.尾删结点(SListPopBack):
7.头删结点(SListPopFront):
8.在pos位置之后插入数据x(SListInsertAfter):
9.删除pos位置的数据(SListErase):
10.销毁链表(SListDestroy):
6.尾删结点(SListPopBack):
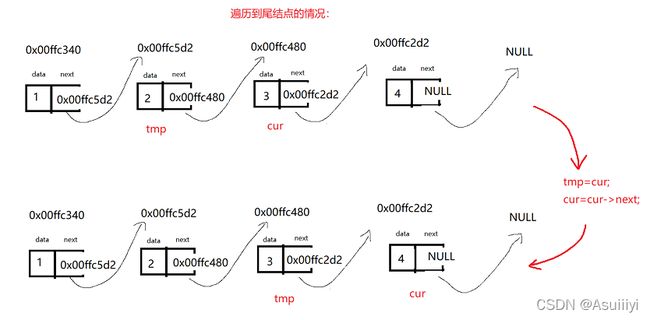
思路:我们需要找到最后一个结点,并且删除并释放内存,而倒数第二个结点即成为了新的尾结点。
因此,我们不仅要得到尾结点的地址,还要得到倒数第二个结点的地址。
仅仅通过一次遍历,我们能得到尾结点,但是倒数第二个结点不能得到,我们可以通过建立一个临时的SListNode指针 tmp,保存当前结点的前一个结点,所以当遍历结束时,我们就可以得到尾结点以及倒数第二个结点:
建立临时结点:
SListNode* tmp = NULL;判断:链表为空时,尾删无效。
if (*pplist == NULL)
{
printf("SList is empty\n");
}完整函数:
void SListPopBack(SListNode** pplist)// 单链表的尾删
{
if (*pplist == NULL)
{
printf("SList is empty\n");
}
else
{
SListNode* cur = *pplist;
SListNode* tmp = NULL;
while (cur->next != NULL)
{
tmp = cur;//tmp作为标记上一个cur的位置
cur = cur->next;
}
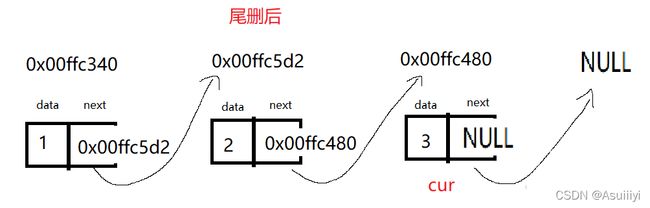
free(cur); //释放尾结点
tmp->next = NULL;
}
}
7.头删结点(SListPopFront):
跟尾删细节相似,头结点为空,头删无效,这里直接暴力检查:
assert(pplist);实质:删除头结点,并让第二个结点作为新的头结点。
注意事项 :我们在删除并释放头结点的时候,需要发现的是,头结点的next指向第二个结点,若我们直接释放头结点,我们将无法找到第二个结点乃至整个链表,我们需要做的,是建立一个临时SListNode指针保存第二个指针的地址,即头结点的next指针,再进行释放头结点的操作。
SListNode* tmp = (*pplist)->next;
free(pplist);
*pplist = tmp;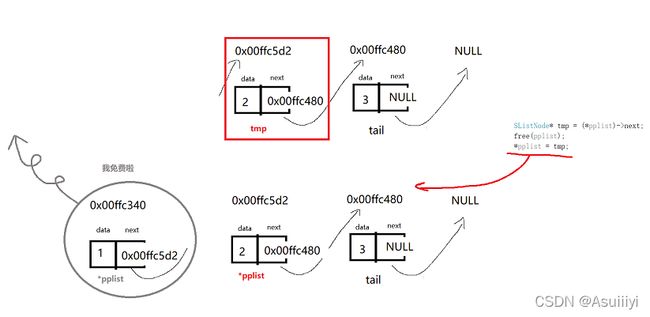
完整函数:
void SListPopFront(SListNode** pplist)// 单链表头删
{
assert(pplist);
if (*pplist == NULL)
{
return;
}
else
{
SListNode* tmp = (*pplist)->next;
free(pplist);
*pplist = tmp;
}
}8.在pos位置之后插入数据x(SListInsertAfter):
为什么是在pos位置之后插入,而不是在pos位置前插入呢?
在pos位置前插入,我们需要四点:
1、找到pos前一个结点的位置。
2、找到pos结点位置。
3、修改pos前一个结点的next,使得next指向新插入结点。
4、新结点的next指向pos结点。
在pos位置后插入,我们只需要三点:
1、找到pos结点位置。
2、新结点的next指向pos结点的next。
3、pos结点的next指向新结点。
这样比较,发现二者之间的方法是类似的,但是前者操作更为繁杂,因此我们选择后者,即在pos位置后插入数据。
注意:判断pos位置为头结点是时,其效果与尾插类似,可以直接引用尾插函数。
void SListInsertAfter(SListNode** pplist, SListNode* pos, SLTDataType x)//单链表在pos位置之后插入x
{
assert(pos);
SListNode* newnode = BuySListNode(x);
if (pos == *pplist)
{
SListPushFront(pplist, x);
}
else
{
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;//新结点负责联系pos原来的下一个结点的位置
pos->next = newnode;//修改: pos下一个结点的位置变为新结点的位置
}
}9.删除pos位置的数据(SListErase):
删除pos位置,为了串联pos前一个结点与pos后一个结点,我们需要保存pos前一结点的位置,以便释放pos位置结点后,链表可以保持联系,这里我们定义一个SListNode结构体指针prev:
SListNode* prev = *pplist;指针prev则代表当前结点的前一结点的位置,当我们遍历到pos位置时,为了释放pos位置结点,而且要保留pos的下一个结点地址,我们要做的,就是把pos前一个结点的next变为pos后一个结点的地址,即:
prev->next = pos->next;这个时候我们已经实现把pos位置结点移出链表了,这时候我们再把pos的地址释放,置空。
完整函数:
void SListErase(SListNode** pplist, SListNode* pos)//删除pos位置
{
assert(pplist);
assert(pos);
if (*pplist == pos)
{
SListPopFront(pplist);
}
else
{
SListNode* prev = *pplist;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}10.销毁链表(SListDestroy):
使用完链表以后,为了释放内存,我们需要销毁链表,如果太直肠子,直接把头结点释放的话,我们就找不到下一个结点了,这也是单链表的缺陷,因此我们可以设置临时指针SListNode* tmp,tmp指向当前结点的前一个结点,因为,为了联系下一个结点,我们需要当前结点的next指针,所以不可以直接把当前结点直接释放,我们先用tmp存入当前结点,然后使结点寻找到下一个结点,我们再把tmp存放的结点释放:
完整代码:
void SListDestory(SListNode* plist)//销毁链表
{
assert(plist);
SListNode* tmp = NULL;
while (plist->next != NULL)
{
tmp = plist;
plist = plist->next;
free(tmp);
}
free(plist);
}