AI多模态实战教程:面壁智能MiniCPM-V多模态大模型问答交互、llama.cpp模型量化和推理

一、项目简介
MiniCPM-V 系列是专为视觉-语⾔理解设计的多模态⼤型语⾔模型(MLLMs),提供⾼质量的⽂本输出,已发布4个版本。
1.1 主要模型及特性
(1)MiniCPM-Llama3-V 2.5:
- 参数规模: 8B
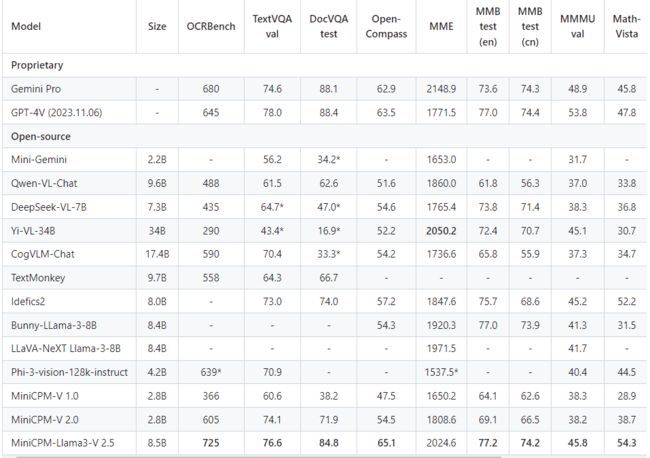
- 性能: 超越GPT-4V-1106、Gemini Pro、Qwen-VL-Max和Claude 3,⽀持30+种语⾔,多模态对话,增强OCR
- 和指令跟随能⼒。
- 部署: 量化、编译优化,可⾼效部署于端侧设备上的CPU和NPU。
(2)MiniCPM-V 2.0
- 参数规模: 2B
- 性能: 超越Yi-VL 34B、CogVLM-Chat 17B和Qwen-VL-Chat 10B,可处理任意纵横⽐和180万像素图像(例
- 如,1344x1344),低幻觉率。
1.2 MiniCPM-Llama3-V 2.5 关键特性
- 领先的性能
- 平均得分65.1(OpenCompass),超越多款专有模型。
- 强⼤的OCR能⼒
- 处理任意纵横⽐和180万像素图像,OCRBench评分700+,提供全⽂OCR提取和表格到Markdown转换
- 等⾼级实⽤功能。
- 值得信赖的⾏为
- 采⽤RLAIF-V⽅法,幻觉率10.3%,优于GPT-4V-1106。
- 多语⾔⽀持
- ⽀持30+种语⾔(含德语、法语、⻄班⽛语、意⼤利语、韩语等)。
- ⾼效部署
- 模型量化、CPU/NPU优化,实现端侧设备上的150倍图像编码加速和3倍语⾔解码加速。
- 易⽤性
- ⽀持llama.cpp、ollama,GGUF格式量化模型,LoRA微调,流输出,本地WebUI演示和HuggingFace
- Spaces交互演示。
1.3 MiniCPM-V 2.0 关键特性
MiniCPM-V 2.0,这是MiniCPM系列的多模态版本。该模型基于MiniCPM 2.4B和SigLip-400M构建,总共有2.8B参数。MiniCPM-V 2.0显示出强⼤的OCR和多模态理解能⼒,在开源模型中的OCRBench上表现出⾊,甚⾄在场景⽂本理解上可以与Gemini Pro相媲美。
- 前沿性能
- 在多个基准测试中表现优异(如 OCRBench、TextVQA 等)。
- 超越 Qwen-VL-Chat 9.6B、CogVLM-Chat 17.4B 和 Yi-VL 34B。
- 强⼤的 OCR 能⼒,与 Gemini Pro 性能相当。
- 可信⾏为
- 使⽤多模态 RLHF 技术防⽌⽣成不符合事实的⽂本。
- 与 GPT-4V 在防⽌幻觉⽅⾯匹配。
- ⾼分辨率图像处理
- 接受 180万像素(例如,1344x1344)的图像,⽀持任意⻓宽⽐。
- 提升对细粒度视觉信息的感知能⼒。
- ⾼效能
- ⾼效部署于⼤多数 GPU 和个⼈电脑,⽀持移动设备。
- 使⽤感知器重采样技术,降低内存成本并提升速度。
- 双语⽀持
- ⽀持英语和中⽂的双语多模态能⼒。
- 基于 VisCPM 技术,实现跨语⾔的⼀般化多模态能⼒。
⼆、案例实战
2.1 环境配置
conda create -n cpm python=3.11
conda activate cpm
# 下载项⽬,并进⾏依赖包安装
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
pip install -r requirements.txt
# 单独安装
pip install bitsandbytes streamlit gguf2. 模型下载
# 前提,安装git和git-lfs【可选,如果已安装,则跳过】
sudo apt update
sudo apt install git
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo
bash
sudo apt-get install git-lfs
git lfs install
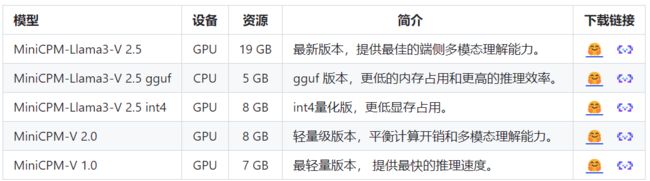
# 下载模型,以int4量化的MiniCPM-Llama3-V-2_5为例
git clone https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5-int4[无法访问外网的同学,可以把上面最后一行改为国内镜像地址:
git clone https://hf-mirror.com/openbmb/MiniCPM-Llama3-V-2_5-int4]
三. 本地 WebUI Demo
3.1 基于 Gradio 实现
# 注意:需要修改脚本 web_demo_2.5.py 中的代码:
# ① model_path = xxx
# ② server_port = xxx
cd MiniCPM-V/
python web_demo_2.5.py3.2 基于 Streamlit 实现
# 注意:需要修改脚本 web_demo_streamlit-2_5.py 中的代码:
# ① model_path = xxx
# ② model = AutoModel.from_pretrained(model_path, trust_remote_code=True,
torch_dtype=torch.float16, device_map="cuda")
streamlit run web_demo_streamlit-2_5.py --server.port 6006 --server.address 0.0.0.0四. 多轮对话
# 注意:需要修改 chat.py 中的代码:
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True,
device_map="cuda")
self.model.eval()新建demo.py
# 案例-多轮对话
from chat import MiniCPMVChat, img2base64
import torch
import json
torch.manual_seed(0)
chat_model = MiniCPMVChat("/root/autodl-tmp/models/MiniCPM-Llama3-V-2_5-int4")
im_64 = img2base64('./assets/airplane.jpeg')
# 第⼀轮对话
msgs = [{"role": "user",
"content": "Tell me the model of this aircraft."}]
inputs = {"image": im_64,
"question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
# 第⼆轮对话
# 传递多轮对话的历史上下⽂
msgs.append({"role": "assistant",
"content": answer})
msgs.append({"role": "user",
"content": "Introduce something about Airbus A380."})
inputs = {"image": im_64,
"question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)五. 基于 llama.cpp 推理
5.1 环境配置
# 1. 下载项⽬
git clone -b minicpm-v2.5 https://github.com/OpenBMB/llama.cpp.git
cd llama.cpp
# 2. 安装 g++ (可选,如果已经安装,则跳过)
sudo apt update
sudo apt install g++
# 3. 在项⽬ llama.cpp/ ⽬录下,执⾏命令
make
make minicpmv-cli5.2 模型量化
# 4. 模型格式转换,hf -> gguf
# 【可选操作】可以直接 下载gguf模型
python ./examples/minicpmv/minicpmv-surgery.py -m /root/autodl-tmp/models/MiniCPM-Llama3-
V-2_5python ./examples/minicpmv/minicpmv-convert-image-encoder-to-gguf.py -m /root/autodltmp/models/MiniCPM-Llama3-V-2_5 --minicpmv-projector /root/autodl-tmp/models/MiniCPMLlama3-V-2_5/minicpmv.projector --output-dir /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/
--image-mean 0.5 0.5 0.5 --image-std 0.5 0.5 0.5python ./convert.py /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/model --outtype f16 --
vocab-type bpe# 5. quantize int4 version
./quantize /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/model/model-8B-F16.gguf
/root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/model/ggml-model-Q4_K_M.gguf Q4_K_M5.3 模型推理
# 6. 基于量化版模型进⾏推理
# run f16 version
./minicpmv-cli -m /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/model/model-8B-F16.gguf --
mmproj /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/mmproj-model-f16.gguf -c 4096 --temp
0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image /root/autodl-tmp/MiniCPMV/assets/airplane.jpeg -p "What is in the image?"# run quantized int4 version(4bit量化推理)
./minicpmv-cli -m /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/model/ggml-modelQ4_K_M.gguf --mmproj /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/mmproj-model-f16.gguf -c
4096 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image /root/autodltmp/MiniCPM-V/assets/airplane.jpeg -p "What is in the image?"# or run in interactive mode(交互模式)
./minicpmv-cli -m /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/model/ggml-modelQ4_K_M.gguf --mmproj /root/autodl-tmp/models/MiniCPM-Llama3-V-2_5/mmproj-model-f16.gguf -c
4096 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image /root/autodltmp/MiniCPM-V/assets/airplane.jpeg -i