React系列之虚拟DOM、FIBER和DIFF算法
文章目录
- 虚拟 DOM 和 DIFF 算法
-
- 虚拟DOM
-
- 虚拟DOM对象
- 虚拟DOM的优势
- 预防XSS
- DIFF算法
-
- 旧的DIFF算法
- Fiber树
- 渲染过程
- 算法过程
-
- key 的作用
虚拟 DOM 和 DIFF 算法
虚拟DOM
React使用虚拟DOM来更新真正的DOM。
DOM表示“文档对象模型”,浏览器遵循HTML指令来构造文档对象模型。当浏览器加载HTML并呈现用户界面时,HTML文档中所有元素都会变成DOM元素。每次DOM更新的时候都要重新渲染UI,UI越多,DOM更新的成本就越高。
虚拟DOM是一个对象,真实DOM是一个DOM,DOM上默认挂载很多属性和方法,所以从结构上来看:虚拟DOM要比真实DOM轻很多。
在传统的Web应用中,数据的变化会实时地更新到用户界面中,于是每次数据微小的变化都会引起DOM的渲染。而虚拟DOM的目:是将所有的操作聚集到一块,计算出所有的变化后,统一更新一次虚拟DOM。
虚拟DOM对象
{
type: 'div',
props: { class: 'Index' },
children: [
{
type: 'div',
children: '我是小杜杜'
},
{
type: 'ul',
children: [
{
type: 'li',
children: 'React'
},
]
}
]
}
主要属性有 type:实际的标签;props:标签内部的属性(除key和ref,会形成单独的key名)和 children: 为子节点内容,依次循环。
虚拟DOM的优势
提高效率:
使用原生JS的时候,我们需要的关注点在操作DOM上,而React会通过虚拟DOM来确保DOM的匹配,也就是说,我们关注的点不在时如何操作DOM,怎样更新DOM,React会将这一切处理好。此时,我们更加关注于业务逻辑,从而提高开发效率。
性能提升:
实际上,React会将整个DOM保存为虚拟DOM,如果有更新,都会维护两个虚拟DOM,以此来比较之前的状态和当前的状态,并会确定哪些状态被修改,然后将这些变化更新到实际DOM上,一旦真正的DOM发生改变,也会更新UI。
浏览器在处理DOM的时候会很慢,处理JavaScript会很快。所以在虚拟DOM感受到变化的时候,只会更新局部,而非整体。同时,虚拟DOM会减少了非常多的DOM操作,所以性能会提升很多。
超强的兼容性:
React基于虚拟DOM实现了一套自己的事件机制,并且模拟了事件冒泡和捕获的过程,采取事件代理、批量更新等方法,从而磨平了各个浏览器的事件兼容性问题。
虚拟DOM一定会提高性能吗?
通过上面的理解,很多人认为虚拟DOM一定会提高性能,一定会更快,其实这个说法有点片面,因为虚拟DOM虽然会减少DOM操作,但也无法避免DOM操作。
它的优势是在于diff算法和批量处理策略,将所有的DOM操作搜集起来,一次性去改变真实的DOM, 但在首次渲染上,虚拟DOM会多了一层计算,消耗一些性能,所以有可能会比html渲染的要慢。
预防XSS
React有两层防XSS攻击的设计:
第一是 ReactDOM 负责 DOM 层的所有事务,在渲染所有输入内容前,就会默认进行转义。所有的内容在渲染之前都被转换成了字符串。这样可以有效地防止 XSS(cross-site-scripting, 跨站脚本)攻击。
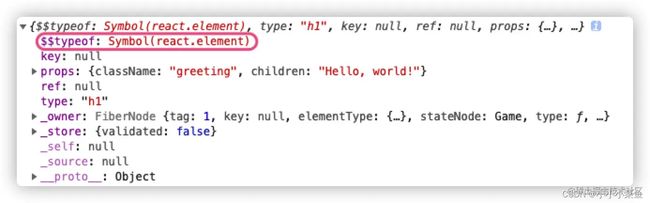
第二是在虚拟DOM创建时有一个属性 $$typeof,它是一个特殊的属性,用于标识这是一个 React 元素对象。并且使用 Symbol 数据类型作为 value。用户存储的 JSON 对象可以是任意的字符串,这可能会带来潜在的危险,而 JSON 对象不能存储于 Symbol 类型的变量,React 可以在渲染的时候把没有 typeof 标识的组件过滤掉,从而达到预防 XSS 的功能。
DIFF算法
旧的DIFF算法
旧的 diff 算法,也就是在 16 版本之前,采用深度遍历的方式,将各个节点及其子节点压入栈中,递归的找完所有节点。
因为整个过程是递归实现的,中间不能中断,中断后需要重新开始,如果树的层级较深,会导致整个更新过程时间(js执行)过长,出现阻碍页面渲染和用户交互卡顿等问题。所以后面才有了 Fiber 链表结构和可以随时中断的 diff。
Fiber树
fiber 是一种数据结构,可以用一个纯 js 对象来表示。
fiber 对象:
{
type. 节点类型(元素,文本,组件)
props 节点属性
stateNode 节点DOM对象 | 组件实例对象
tag 节点标记
effects 数组,存储需要更改的Fiber对象
effectTag 当前Fiber要被执行的操作 (新增,删除,修改)
parent 当前Fiber的父级Fiber
child 当前Fiber的子级Fiber 注意 一个节点只能有一个子级 其他的子级是这个子级的兄弟fiber
sibling 当前fiber的下一个兄弟Fiber
alternate Fiber备份 fiber对比时使用
}
在 16 之后,为了优化性能,会先把 ReactElement 树转换成 fiber 树,fiber 树利用了链表的思想,每个节点会维护指向父节点、兄弟节点、子节点的指针。这种链表结构使得 React 能够更灵活地执行任务、暂停和中断渲染过程,将整个更新任务分为多个小任务,在中间可以把执行权交给浏览器执行用户交互和渲染等操作,这样页面卡顿情况减少,提高了用户体验。
从 vdom 转成 fiber 的过程叫做 reconcile(调和),这个过程是可以打断的,由 scheduler 调度执行。
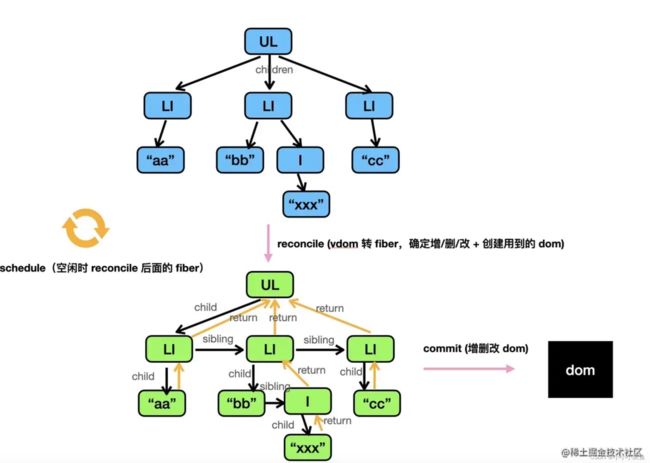
diff 算法作用在 reconcile 阶段:第一次渲染不需要 diff,直接 ReactElement 转 fiber。再次渲染的时候,会产生新的 ReactElement,这时候要和之前的 fiber 做下对比,决定怎么产生新的 fiber,并对可复用的节点打上修改的标记,剩余的旧节点打上删除标记,新节点打上新增标记。
渲染过程
React 的工作流程主要分为 render (reconcile + schedule) 和 commit 两个阶段:
render 阶段:jsx 在代码编译阶段经 babel 转化成由 React.createElement() 包裹的代码段,在 render 阶段该代码段被执行后便生成了对应的 ReactElement,根据 ReactElement 来创建 Fiber 树;React 采用“双缓存”的思想,因此同一时刻维持有两棵 Fiber 树 ,一颗是应浏览器当前已渲染的 DOM 树,而另一棵则是初始化时或者组件状态更新后由 reconciler 创建的一个工作副本。(可中断)
commit 阶段指的是把新的 Fiber 树渲染到页面上 ,当然这个过程并不会是全量更新,而是根据创建新 Fiber 树时打的一些“标记”(effectTag),来确定在某个 DOM 节点上具体做什么操作,比如更新文本、删除节点等,以尽量小的代价来在 DOM 上还原新 FIber 树 ;新 FIber 树会在 commit 后被标记为 current。(不可中断)
算法过程
diff 算法的目的就是用较少的步骤完成从旧树到新树的转换,为什么不是说最少,因为两棵树的转换的最小时间复杂度算法是On^3,如果节点多的话开销会很大,diff 算法在时间复杂度和操作复杂度之间找了一个平衡,只用了On的时间复杂度完成,它是基于三个前提:
- 只对同级元素进行Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。
- 不同类型的两个元素会产生不同的树
- 开发人员可以使用 key 属性来表示哪些子元素在不同的渲染中是固定的。
首先比较根节点,
- 如果节点类型不一致直接删掉重新创建。
- 如果一致的话分为DOM标签和组件:
- DOM标签会保留节点,继续对比属性更新属性即可。
- 组件的话会执行相应的生命周期函数,然后在render中的节点中继续用以上方法对比。
比较子节点时会依照key来尽量保留元素。
实现过程:
分为两个阶段:
第一阶段:一一对比,如果节点类型一样,表示可以服用旧的元素,利用旧fiber和新的元素的props生成新的fiber节点,并打标update。
如果不一样表示不能复用,旧 fiber 打上删除标志,生成新 fiber,并打标新增。
结束第一轮遍历后新旧树都存在没有对比过的元素,说明需要进行二次遍历:
第二阶段:将老 Fiber 节点放入 map,遍历新的 ReactElement 看有没有能复用的,有的话就打上更新的 effectTag。这样遍历完新的 ReactElement 之后,map 里剩下一些,这些是不可复用的,那就删掉,打上删除的 effectTag;如果新的 ReactElement 中还有一些没找到复用节点的,就直接创建,打上新增的 effectTag。这样就完成了更新时的 reconcile 过程。
key 的作用
当同一层级的某个节点添加了对于其他同级节点唯一的key属性,当它在当前层级的位置发生了变化后。react diff算法通过新旧节点比较后,如果发现了key值相同的新旧节点,就会执行移动操作,而不会执行原策略的删除旧节点,创建新节点的操作。这大大提高了React性能和渲染效率。
key只是针对同一层级的节点进行了diff比较优化,而跨层级的节点互相之间的key值没有影响。
不建议用index作为key,比如在用index作key的情况下,当我们对原始的数据list进行了某些元素的顺序改变操作,导致了新旧集合中在进行diff比较时,相同index所对应的新旧的节点其文本不一致了,就会出现一些节点需要更新渲染文本,而如果用了其他稳定的唯一标识符作为key,则只会发生位置顺序变化,无需更新渲染文本,提升了性能。
用index作为key在非受控组件中也会出现bug —> 新增输入框时已输入文本内容移位。