ASN.1探索 - 2 基础知识(3)
转自: http://wmfbravo.blog.163.com/
感谢: wmfbravo
2 基础知识
& 注释:
本章的内容主要翻译自《ASN.1 Communication between Heterogeneous Systems》。
2.11 子类型约束
2.11.1 单值约束(Single Value Constraint)
最简单的的子类型约束就是单值约束,即将一个类型限制为一个值,以圆括号将该值列在类型声明之后即可,如:
Two ::= INTEGER (2)
Day ::= ENUMERATED
{
monday(0), tuesday(1), wednesday(2), thursday(3), friday(4), saturday(5), sunday(6)
}
Wednesday ::= Day (wednesday)
FourZ ::= IA5String ("ZZZZ")
Afters ::= CHOICE
{
cheese IA5String,
dessert ENUMERATED
{
profiterolles(1), sabayon(2),fraisier(3)
}
}
CompulsoryAfters ::= Afters (dessert:sabayon)
如果该值的选择可以是多个中的一个,则可以用“|”将被选值列出,如:
WeekEnd ::= Day (saturday|sunday)
PushButtonDial ::= IA5String ("0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"|"*"|"#")
2.11.2 类型包含约束(Type Inclusion Constraint)
当声明一个类型和另一个类型拥有同样的约束时,只需要将被参考类型列出,如:
FrenchWeekEnd ::= Day (WeekEnd)
还可以这样使用:
LongWeekEnd ::= Day (WeekEnd|monday)
注意:在1994以前的标准中必须使用INCLUDES关键字,以后的标准不再是必须的。
2.11.3 值域约束(Value Range Constraint)
对于数学中的整数和实数,可以用区间来约束。在ASN.1中使用“..”来表示区间,“<”用来限定边界,如:
Number ::= INTEGER
From3to15 ::= Number (3..15)
From3excludedTo15excluded ::= Number (3<..<15)
关键字MIN和MAX用来表征基本类型的最小、最大值。
对于实数类型,下面两个定义:
T ::= REAL (0..<fmantissa 5,base 10,exponent 0g)
U ::= T (fmantissa 2,base 10,exponent 0g..MAX)
的结果使得类型U等价于:
U ::= REAL ({mantissa 2,base 10,exponent 0}..<{mantissa 5,base 10,exponent 0})
2.11.4 大小约束(Size Constraint)
主要对类型内存空间大小进行约束,对基本类型的约束,如:
Exactly31BitsString ::= BIT STRING (SIZE (31))
StringOf31BitsAtTheMost ::= BIT STRING (SIZE (0..31))
EvenNumber ::= INTEGER (2|4|6|8|10)
EvenLengthString ::=IA5String (SIZE (EvenNumber))
NonEmptyString ::= OCTET STRING (SIZE (1..MAX))
前两个类型的区别在于,第二个的长度是一个区间,从0到31;而第一个的长度固定是31。
对SEQUENCE OF和SET OF的约束,如:
ListOfStringsOf5Characters ::= SEQUENCE OF PrintableString (SIZE (5))
ListOf5StringsOf5Characters ::=
SEQUENCE (SIZE (5)) OF PrintableString (SIZE (5))
2.11.5 字符表约束(Alphabet Constraint)
主要是对字符串类型的值进行约束,如:
Morse ::= PrintableString (FROM ("."|"-"|" "))
IDCardNumber ::=NumericString (FROM ("0".."9"))
PushButtonDialSequence ::=IA5String (FROM ("0".."9"|"*"|"#"))
下面这个类型定义,虽然没有错,但却没有意义:
WrongType ::= IA5String (FROM ("Albert".."Zoe"))
因为字符串类型定义需要声明字符而不是字符串。
下面两个定义是等价的:
Dna ::= PrintableString (FROM ("TAGC"))
Dna::= PrintableString (FROM ("T"|"A"|"G"|"C"))
2.11.6 正则表达式约束(Regular Expression Contraint)
也是用于对字符串值的约束,通过关键字PATTERN来声明具体的正则表达式。如:
DateAndTime ::= VisibleString(PATTERN "\d#2/\d#2/\d#4-\d#2:\d#2")
-- DD/MM/YYYY-HH:MM
正则表达式的用法就不详细介绍,下面给出正则表达式的含义:
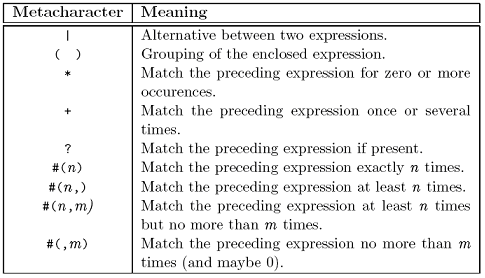
Figure 2-8 正则表达式含义
2.11.7 对SEQUENCE OF或者SET OF成员的约束
如前所述,我们可以对SEQUENCE OF或者SET OF进行约束。但是,当其成员是从其它模块IMPORTS而来时,我们不能添加约束来重定义。因此我们通过WITH COMPONENT来进入到被组合类型的定义,再添加约束。如:
TextBlock ::= SEQUENCE OF VisibleString
添加约束:
AddressBlock ::= TextBlock (WITH COMPONENT (SIZE (1..32)))
DigitBlock ::= TextBlock (WITH COMPONENT (NumericString))
这两个定义相当于:
AddressBlock ::= SEQUENCE OF VisibleString (SIZE (1..32))
DigitBlock ::= SEQUENCE OF VisibleString (NumericString)
当然,关键字WITH COMPONENT可以和其它约束一起使用,如:
IntegerMatrix ::= SEQUENCE SIZE (6) OF SEQUENCE SIZE (6) OF INTEGER
CoordinateMatrix ::=
IntegerMatrix (WITH COMPONENT (WITH COMPONENT (-100..100)))
相当于:
CoordinateMatrix ::=
SEQUENCE SIZE (6) OF SEQUENCE SIZE (6) OF INTEGER (-100..100)
2.11.8 对SEQUENCE、SET或者CHOICE成员的约束
对于SEQUENCE和SET多个成员进行约束,我们使用WITH COMPONENTS来添加约束,注意关键字结尾有S(因为SEQUENCE和SET成员是不同类型的)。
对类型:
Quadruple ::= SEQUENCE
{
alpha ENUMERATED {state1, state2, state3},
beta IA5String OPTIONAL,
gamma SEQUENCE OF INTEGER,
delta BOOLEAN DEFAULT TRUE
}
添加约束后为:
Quadruple1 ::= Quadruple (WITH COMPONENTS
{
...,
alpha (state1),
gamma (SIZE (5))
})
符号“…”指示只对显式声明的成员进行约束,其它成员保留。注意对SEQUENCE类型,声明约束时仍然要保持成员的顺序。
对于声明为OPTIONAL的成员(声明为DEFAULT的也类似),还可以使用关键字PRESENT和ABSENT来表示在约束中该成员出现还是不出现。如:
Quadruple2 ::= Quadruple (WITH COMPONENTS
{
alpha (state1),
beta (SIZE (5|12)) PRESENT,
gamma (SIZE (5)),
delta OPTIONAL
})
如果约束列出了成员列表,则PRESETN和ABSENT可以省略,如:
Quadruple3 ::=
Quadruple (WITH COMPONENTS falpha, beta, gammag)
WITH COMPONENTS还可以应用于REAL、EMBEDDED PDV、EXTERNAL、CHARACTER STRING和INSTANCE OF。
应用于CHOICE类型时,WITH COMPONENTS用来指示哪些选项被禁止或者哪些选项可供选择。
对类型:
Choice ::= CHOICE { a A, b B, c C, d D }
添加约束后为:
ChoiceCD ::= Choice (WITH COMPONENTS {..., a ABSENT, b ABSENT})
ChoiceA1 ::= Choice (WITH COMPONENTS {..., a PRESENT})
ChoiceA2 ::= Choice (WITH COMPONENTS {a PRESENT})
ChoiceBCD ::= Choice (WITH COMPONENTS {a ABSENT, b, c})
2.11.9 对OCTET STRING内容的约束
使用CONTAINING和ENCODED BY来对OCTET STRING类型的内容进行约束,以达到更为灵活的传输语法。
如:
MoreCompact ::= OCTET STRING (CONTAINING MyType ENCODED BY {joint-iso-itu-t asn1 packed-encoding(3) basic(0) unaligned(1)})
MyType ::= SEQUENCE { -- ....... -- }
这里明确指定了OCTET STRING的内容是MyType并且使用PER进行编码。则ASN.1编译器在这部分将调用PER编解码器。
ENCODE BY可以指明具体的编码规则,可以是PER、CER等,也可以是用ECN编码控制标记描述的自定义编码规则。如果没有ENCODED BY,则该部分使用和当前模块相同的编码方式。
对没有CONTAINING的部分,如:
Document ::= OCTET STRING (ENCODED BY pdf)
pdf OBJECT IDENTIFIER ::= { -- OID pour le codage PDF -- }
ASN.1编译器将调用对应的解码器如Acrobat Reader浏览器。
2.11.10 约束的组合
可以将前面所述的各种约束适当组合,得到更为准确的描述,如:
PhoneNumber ::= NumericString (FROM ("0".."9"))(SIZE (10))
描述的是电话号码。
除此之外,常见的组合类型有:

Figure 2-9 四种常见的组合操作
l C1 UNION C2或者C1|C2方式,前面已经介绍过。如:
PushButtonDialSequence ::= IA5String (FROM ("0".."9"|"*"|"#"))
l C1 INTERSECTION C2或者C1^C2方式,如:
SaudiName ::= BasicArabic (SIZE (1..100) ^ Level2)
l C1 EXCEPT C2方式,如:
Lipogramme ::= IA5String (FROM (ALL EXCEPT ("e"|"E")))
l ALL EXCEPT C1方式,如:
InvokeId ::= CHOICE { present INTEGER, absent NULL }
DAP-InvokeIdSet ::= InvokeId (ALL EXCEPT absent:NULL)
2.11.11 约束的扩展
在约束中也可以添加扩展标记,如:
A ::= INTEGER (0..10, ...)
在新版本中,可以这样扩展:
A ::= INTEGER (0..10, ..., 12)
类型A的值可以为0到10和12。
和SEQUENCE、SET和CHOICE类型不同,在约束中不能第二个扩展标记,也没有版本描述符“[[ ]]”。此外,在模块声明中,EXTENSIBILITY IMPLIED语句不会对约束产生影响。
可以使用异常描述符来明确定义可以通知给接收方应用层不符合根约束时的异常,如:
E ::= INTEGER (1..10, ...!Exception:too-large-integer)
Exception ::= ENUMERATED {too-large-integer, ...}
特别在SIZE约束中使用扩展情况下,添加异常声明就很有用。
在后面讨论参数化时,当一个子类型约束包含一个抽象语法的参数,那么这个约束就是隐含扩展的,因为每个参数的实例都会修改约束。如:
ImplementedUnivStr{UniversalString:Level} ::=
UniversalString (FROM ((Level UNION BasicLatin))
!characterSet-problem)
characterSet-problem INTEGER ::= 4
通常也建议在自定义约束中添加异常描述。
2.11.12 自定义约束
除了ASN.1中前面介绍的约束,还可以通过关键字CONSTRAINED BY来引入自定义约束,它通常都会在编解码过程中引入特定的处理。例如,在ASN.1/C++接口(TeleManagement Forum, X/Open. { ASN.1/C++. Application Programming Interface. { Report 1.0 (draft 10a), 1996. ftp://ftp.tmforum.org/nmfsets/component/cs322/)中,在有用户自定义约束类型的一个值编码前或者解码后,一个程序员指定的函数就会被调用。这个函数可以检查信息约束已被遵守,并且数据中的操作已被执行。
自定义约束还能用来指示SEQUENCE或者SET间成员的复杂约束。
通常在CONSTRAINED BY之后是一些注释,这些在扫描阶段会被忽略。但自定义约束要求编译器在生成文件中编解码部分插入一个对用户自定义函数的调用。
示例:
Reject ::= SEQUENCE {
invokeId InvokeId,
problem CHOICE
{
general [0] GeneralProblem,
invoke [1] InvokeProblem,
returnResult [2] ReturnResultProblem,
returnError [3] ReturnErrorProblem
}
} (CONSTRAINED BY {-- must conform to the above --
-- definition --} ! RejectProblem:general-mistypedPDU)
用户自定义约束经常会用到参数,参数被放在花括号中。如:
Encrypted{TypeToBeEnciphered} ::= BIT STRING (CONSTRAINED
BY {-- must be the result of the encipherment --
-- of some BER-encoded value of --
TypeToBeEnciphered} !Error:securityViolation)
Error ::= ENUMERATED {securityViolation}
2.12 表示上下文交换类型
2.12.1 EXTERNAL类型
不推荐使用。可以用EMBEDDED PDV类型替代。
它的等效SEQUENCE结构为:
EXTERNAL ::= [UNIVERSAL 8] IMPLICIT SEQUENCE
{
direct-reference OBJECT IDENTIFIER OPTIONAL,
indirect-reference INTEGER OPTIONAL,
data-value-descriptor ObjectDescriptor OPTIONAL,
encoding CHOICE {
single-ASN1-type [0] ANY,
octet-aligned [1] IMPLICIT OCTET STRING,
arbitrary [2] IMPLICIT BIT STRING
}
}
2.12.2 EMBEDDED PDV类型
EMBEDDED PDV类型等效于:
EMBEDDED PDV ::= [UNIVERSAL 11] IMPLICIT SEQUENCE
{
identification CHOICE
{
syntaxes SEQUENCE
{
abstract OBJECT IDENTIFIER,
transfer OBJECT IDENTIFIER
},
syntax OBJECT IDENTIFIER,
presentation-context-id INTEGER,
context-negotiation SEQUENCE
{
presentation-context-id INTEGER,
transfer-syntax OBJECT IDENTIFIER
},
transfer-syntax OBJECT IDENTIFIER,
fixed NULL
},
data-value OCTET STRING
}
其中identification的选项:
l syntaxes(注意有s)表征编码规则中抽象语法和传输语法的对象标识;
l syntax表征抽象语法和编码规则;
l presentation-context-id是协商后的表示上下文(只用于OSI环境中,即一对抽象语法和传输语法);
l context-negotiation用于表示上下文协商,可能在连接建议开始或者连接过程中上下文修改;
l transfer-syntax。此时,抽象语法应该是应用设计者固定采用的方式,并且发送、接收双方都已明确;
l fixed表明发送、接收双方都已知道抽象语法和传输语法。
2.12.3 CHARACTER STRING类型
CHARACTER STRING是EMBEDDED PDV的一个具体应用,在一些特殊场合下的字符串类型,可能不想如前述标准类型那样采用标准的编码方式,而是希望其字符抽象语法和字符传输语法能在通讯系统标识层间协商或者在环境合适时直接使用字符串。该类型等效于:
CHARACTER STRING ::= [UNIVERSAL 29] SEQUENCE
{
identification CHOICE
{
syntaxes SEQUENCE
{
abstract OBJECT IDENTIFIER,
transfer OBJECT IDENTIFIER
},
syntax OBJECT IDENTIFIER,
presentation-context-id INTEGER,
context-negotiation SEQUENCE
{
presentation-context-id INTEGER,
transfer-syntax OBJECT IDENTIFIER
},
transfer-syntax OBJECT IDENTIFIER,
fixed NULL
},
string-value OCTET STRING
}
与EMBEDDED PDV相比,蓝色部分不相同。
2.13 信息对象类、信息对象和信息对象集合
在ASN.1中,信息对象类用于正式描述哪些类型和值单独不能表达的属性,这些属性通常被翻译作为类型和值之间的语法链接。在协议描述中,可以先不考虑这些限制性属性,以后再通过信息对象类添加。虽然信息对象不会被编码,但是ASN.1编译器在生成编解码器时却是要用到它的。
2.13.1 基本语法Default Syntax
信息对象类用关键字Class,名字以大写字母开头。其成员域以“&”开头,名字是小写字母或者大写字母开头。符号“&”使得信息对象类的域和SEQUENCE和SET的成员有明显的区别。因此,如果一个名字是以“&”开头,则一定是一个信息对象类的域。域名字的后面可以是一个类型或者其它类或者本类中其它域,而且可以用OPTIONAL、DEFAULT或者UNIQUE标识。和SEQUENCE、SET不同的是,类中域不仅可以是值,也可以是一个类型,值集合,信息对象或者信息对象集合,因此OPTIONAL和DEFAULT的含义更为广泛。如:
FUNCTION ::= CLASS
{
&ArgumentType ,
&ResultType DEFAULT NULL,
&Errors ERROR OPTIONAL,
&code INTEGER UNIQUE
}
对应的一个信息对象(表示两个数相加的操作)为:
addition-of-2-integers FUNCTION ::=
{
&ArgumentType SEQUENCE { a INTEGER, b INTEGER },
&ResultType INTEGER,
-- empty error list by default
&code 1
}
关于域的名字是大写还是小写字母,请看下表:
Table 2-7 域名字的大小写含义

下面这个示例使用到了上面所有7中情况:
OTHER-FUNCTION ::= CLASS
{
&code INTEGER (0..MAX) UNIQUE,
&Alphabet BMPString
DEFAULT {Latin1 INTERSECTION Level1},
&ArgumentType ,
&SupportedArguments &ArgumentType OPTIONAL,
&ResultType DEFAULT NULL,
&result-if-error &ResultType DEFAULT NULL,
&associated-function OTHER-FUNCTION OPTIONAL,
&Errors ERROR DEFAULT
{rejected-argument | memory-fault}
}
rejected-argument ERROR ::= {-- object definition --}
memory-fault ERROR ::= {-- object definition --}
相应的,代表两个数相加操作的信息对象为:
other-addition-of-2-integers OTHER-FUNCTION ::=
{
&ArgumentType Pair,
&SupportedArguments {PosPair | NegPair},
&ResultType INTEGER,
&result-if-error 0,
&code 1
}
Pair ::= SEQUENCE {a INTEGER, b INTEGER}
PosPair ::= Pair (WITH COMPONENTS {a(0..MAX), b(0..MAX)})
NegPair ::= Pair (WITH COMPONENTS {a(MIN..0), b(MIN..0)})
2.13.2 用户友好语法 User-Friendly Syntax
用户友好语法是由关键字WITH SYNTAX在信息对象类定义中引入的,放在定义之后。其中,对有OPTIONAL、DEFAULT标记的域,相应部分要用“[ ]”来吧标记。如:
OTHER-FUNCTION ::= CLASS
{
&code INTEGER (0..MAX) UNIQUE,
&Alphabet BMPString
DEFAULT {Latin1 INTERSECTION Level1},
&ArgumentType ,
&SupportedArguments &ArgumentType OPTIONAL,
&ResultType DEFAULT NULL,
&result-if-error &ResultType DEFAULT NULL,
&associated-function OTHER-FUNCTION OPTIONAL,
&Errors ERROR DEFAULT
{rejected-argument | memory-fault}
}
WITH SYNTAX
{
ARGUMENT TYPE &ArgumentType,
[SUPPORTED ARGUMENTS &SupportedArguments,]
[RESULT TYPE &ResultType,
[RETURNS &result-if-error IN CASE OF ERROR,]]
[ERRORS &Errors,]
[MESSAGE ALPHABET &Alphabet,]
[ASSOCIATED FUNCTION &associated-function,]
CODE &code
}
memory-fault ERROR ::= {-- object definition --}
注意:
l 全部大写的词不能是类型或者值。
l 如果出现连续的可选部分,他们的名字不能相同。
l 可选部分RETURNS是在RESULT之中的,这样就不能不管&ResultType域而给&result-if-error分配值。
l 为每个域之前添加一个大写的名字不是必须的,但是建议这样做。
当一个信息对象类有用户友好语法是,相应信息对象的定义时就要使用。如:
addition-of-2-integers OTHER-FUNCTION ::=
{
ARGUMENT TYPE Pair,
SUPPORTED ARGUMENTS {PosPair | NegPair},
RESULT TYPE INTEGER,
RETURNS 0 IN CASE OF ERROR,
CODE 1
}
这是,名字,逗号等必须和WITH SYNTAX中的顺序一致。
ASN.1的语法模型也会使用WITH SYNTAX,因此应当避免该部分过于详细、冗长。
2.13.3 示例:X.500协议中的ATTRIBUTE和MATCHING-RULE
信息对象类定义:
ATTRIBUTE ::= CLASS
{
&derivation ATTRIBUTE OPTIONAL,
&Type OPTIONAL,
&equality-match MATCHING-RULE OPTIONAL,
&ordering-match MATCHING-RULE OPTIONAL,
&substrings-match MATCHING-RULE OPTIONAL,
&single-valued BOOLEAN DEFAULT FALSE,
&collective BOOLEAN DEFAULT FALSE,
&no-user-modification BOOLEAN DEFAULT FALSE,
&usage Attribute-Usage
DEFAULT userApplications,
&id OBJECT IDENTIFIER UNIQUE
}
WITH SYNTAX
{
[SUBTYPE OF &derivation]
[WITH SYNTAX &Type]
[EQUALITY MATCHING RULE &equality-match]
[ORDERING MATCHING RULE &ordering-match]
[SUBSTRINGS MATCHING RULE &substrings-match]
[SINGLE VALUE &single-valued]
[COLLECTIVE &collective]
[NO USER MODIFICATION &no-user-modification]
[USAGE &usage]
ID &id
}
AttributeUsage ::= ENUMERATED
{userApplications(0), directoryOperation(1), distributedOperation(2), dSAOperation(3) }
MATCHING-RULE ::= CLASS
{
&AssertionType OPTIONAL,
&id OBJECT IDENTIFIER UNIQUE
}
WITH SYNTAX
{
[SYNTAX &AssertionType]
ID &id
}
信息对象定义:
name ATTRIBUTE ::=
{
WITH SYNTAX DirectoryString
EQUALITY MATCHING RULE caseIgnoreMatch
ID {joint-iso-itu-t ds(5) attributeType(4) 2} }
DirectoryString ::= CHOICE
{
teletexString TeletexString (SIZE (1..maxSize)),
printableString PrintableString (SIZE (1..maxSize)),
universalString UniversalString (SIZE (1..maxSize)),
bmpString BMPString (SIZE (1..maxSize)),
utf8String UTF8String (SIZE (1..maxSize))
}
maxSize INTEGER ::= 25
caseIgnoreMatch MATCHING-RULE ::=
{
SYNTAX DirectoryString
ID {id-mr 2}
}
id-mr OBJECT IDENTIFIER ::= { joint-iso-itu-t ds(5) matchingRule(13)
}
2.13.4 值集合与信息对象集合
前 面已经多次介绍过值集合以及四种关系。这里要说明的是,当在信息对象集合中使用扩展标记时,这说明该集合是动态扩展的,通讯中的应用层在运行中可以增加或 者删除该集合中的值。需要注意的是,类型、子类型、值集合使用的扩展标记是静态扩展的,只能在新版本的描述中增加或者删除,不能动态修改。如:
ExtensibleMatchingRules MATCHING-RULE ::=
{caseIgnoreMatch | booleanMatch | integerMatch, ... }
2.13.5 访问对象、对象集合中的信息
从对象中抽取信息,我们在对象参考后使用“.”。如:
caseIgnoreMatchValue caseIgnoreMatch.&AssertionType ::=
printableString:"Escher"
具体的约定如下表:
Table 2-8 对象信息抽取约定

2.13.6 示例
surname ATTRIBUTE ::=
{ -- family name
SUBTYPE OF name
WITH SYNTAX DirectoryString
ID id-at-surname
}
givenName ATTRIBUTE ::=
{ -- first name
SUBTYPE OF name
WITH SYNTAX DirectoryString
ID id-at-givenName
}
countryName ATTRIBUTE ::=
{ -- country
SUBTYPE OF name
WITH SYNTAX PrintableString (SIZE (2)) -- [ISO3166] codes
SINGLE VALUE TRUE
ID id-at-countryName
}
SupportedAttributes ATTRIBUTE ::={surname | givenName | countryName}
一个简单的应用信息对象的例子:
AttributeIdAndValue3 ::= SEQUENCE
{
ident ATTRIBUTE.&id({SupportedAttributes}),
value ATTRIBUTE.&Type({SupportedAttributes}{@ident})
}
注意使用了符号“@”,表示value与indent之间的关系。此外还使用对象集合SupportedAttributes来进行限定。该类型的一个值为:
val AttributeIdAndValue3 ::=
{
ident id-at-countryName ,
value PrintableString:"F"
}
当多个SEQUENCE、SET、CHOICE、SEQUENCE OF和SET OF嵌套在一起时,使用符号“@”指定组合类型的成员过程中,需要和“.”结合在一起使用,才能保证含义明确。如果形式为“@indent1.indent2.indent3”,那么indent1应当是从该组合类型的最高层开始的;如果形式为“@.indent1”,则indent应当是从该组合类型的最低层开始的。如前面AttributeIdAndValue3还可以定义为:
AttributeIdAndValue3 ::= SEQUENCE
{
ident ATTRIBUTE.&id({SupportedAttributes}),
value ATTRIBUTE.&Type({SupportedAttributes}{@.ident})
}
一个更为复杂的例子为:
FilterItem ::= CHOICE
{
equality [0] AttributeValueAssertion,
substrings [1] SEQUENCE {
type Attribute.&id({SupportedAttributes}),
strings SEQUENCE OF CHOICE
{
initial [0] ATTRIBUTE.&Type
({SupportedAttributes}{@substrings.type}),
any [1] ATTRIBUTE.&Type
({SupportedAttributes}{@substrings.type}),
final [2] ATTRIBUTE.&Type
({SupportedAttributes}{@substrings.type}) }
},
greaterOrEqual [2] AttributeValueAssertion,
lessOrEqual [3] AttributeValueAssertion,
present [4] AttributeType,
approximateMatch [5] AttributeValueAssertion,
extensibleMatch [6] MatchingRuleAssertion
}
又如:
Attribute-desc ::= SEQUENCE
{
usage ATTRIBUTE.&usage({SupportedAttributes}),
list SEQUENCE OF SEQUENCE
{
ident ATTRIBUTE.&id({SupportedAttributes}{@usage}),
value ATTRIBUTE.&Type
({SupportedAttributes}{@usage,@.ident})
}
}
注意这里value部分使用了},既和usage相关,又和最低层的ident相关。用图表示该结构为:
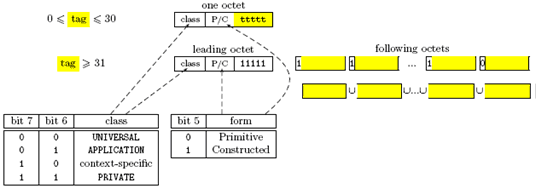
Figure 2-10 双成员相关约束示例
该一个典型值为:
att-desc Attribute-desc ::=
{
usage userApplications,
list
{
{ ident id-at-objectClass, value oid },
{ ident id-at-aliasedEntryName, value distinguishedName }
}
}
2.13.7 预定义TYPE-IDENTIFIER信息对象类和INSTANCE OF类型
预定义信息对象类TYPE-IDENTIFIER的定义如下:
TYPE-IDENTIFIER ::= CLASS
{
&id OBJECT IDENTIFIER UNIQUE,
&Type
}
WITH SYNTAX
{
&Type IDENTIFIED BY &id
}
一个应用示例为:
Authentication-value ::= CHOICE
{
charstring [0] IMPLICIT GraphicString,
bitstring [1] BIT STRING,
external [2] EXTERNAL,
other [3] IMPLICIT SEQUENCE
{
other-mechanism-name MECHANISM-NAME.&id({ObjectSet}),
other-mechanism-value MECHANISM-NAME.&Type
({ObjectSet}{@.other-mechanism-name})
}
}
在ASN.1中经常出现从TYPE-IDENTIFIER中抽取信息的情况,为此提供预定义类型INSTANCE OF,其典型形式为:
SEQUENCE
{
type-id DefinedObjectClass.&id ({ObjectSet }),
value [0] DefinedObjectClass.&Type
({ObjectSet gf@.type-id})
}
INSTANCE OF只用来抽取TYPE-IDENTIFIER的信息,而且通常建议将对象集合列出。INSTANCE OF的UNIVERSAL Tag和EXTERNAL一样都是8。
一个应用为:
ExtendedBodyPart ::= SEQUENCE
{
parameters [0] INSTANCE OF TYPE-IDENTIFIER OPTIONAL,
data INSTANCE OF TYPE-IDENTIFIER
}
(CONSTRAINED BY {-- must correspond to the ¶meters --
-- and &data fields of a member of -- IPMBodyPartTable})
2.13.8 预定义ABSTRACT-SYNTAX信息对象类
预定义信息对象类ABSTRACT-SYNTAX的定义如下:
ABSTRACT-SYNTAX ::= CLASS
{
&id OBJECT IDENTIFIER,
&Type ,
&property BIT STRING {handles-invalid-encodings(0)}
DEFAULT {}
}
WITH SYNTAX
{
&Type IDENTIFIED BY &id
[HAS PROPERTY &property]
}
该信息对象类应用比较少,主要是在PDU部分有应用。如:
ProtocolName-Abstract-Syntax-Module {iso member-body(2)
f(250) type-org(1) ft(16) asn1-book(9) chapter15(3) protocol-name(0)}
DEFINITIONS ::= BEGIN
IMPORTS ProtocolName-PDU FROM ProtocolName-Module {iso
member-body(2) f(250) type-org(1) ft(16) asn1-book(9) chapter15(3) protocol-name(0)module1(2)};
protocolName-Abstract-Syntax ABSTRACT-SYNTAX ::=
{ProtocolName-PDU IDENTIFIED BY protocolName-Abstract-Syntax-id}
protocolName-Abstract-Syntax-id OBJECT IDENTIFIER ::=
{iso member-body(2) f(250) type-org(1) ft(16) asn1-book(9) chapter15(3) protocol-name(0) abstract-syntax(0)}
protocolName-Abstract-Syntax-descriptor ObjectDescriptor
::= "Abstract syntax of ProtocolName"
protocolName-Transfer-Syntax-id OBJECT IDENTIFIER ::=
{iso member-body(2) f(250) type-org(1) ft(16) asn1-book(9) chapter15(3) protocol-name(0) transfer-syntax(1)}
protocolName-Transfer-Syntax-descriptor ObjectDescriptor
::= "Transfer syntax of ProtocolName"
END
在表示层数据定义中:
PDV-list ::= SEQUENCE
{
transfer-syntax-name Transfer-syntax-name OPTIONAL,
presentation-context-identifier Presentation-context-identifier,
presentation-data-values CHOICE
{
single-ASN1-type [0] ABSTRACT-SYNTAX.&Type
(CONSTRAINED BY {-- Type which corresponds to --
-- the presentation context identifier --}),
octet-aligned [1] IMPLICIT OCTET STRING,
arbitrary [2] IMPLICIT BIT STRING
}
}
2.14 宏Macro
自1994版本标准后,宏Macro已经被信息对象类和信息对象取代了。但在一些比较早的协议中(如X.400与X.500协议),还使用了Macro。
宏定义需要用到关键词:MACRO、BEGIN、END、TYPE NOTATION和VALUE NOTATION。
基本结构为:
MACRO-NAME MACRO ::=
BEGIN
TYPE NOTATION ::= -- type syntax --
VALUE NOTATION ::= -- value syntax --
-- grammatical productions used for defining
-- the type syntax and the value syntax
END


2.14.1 例1-COMPLEX NUMBER
COMPLEX MACRO ::=
BEGIN
TYPE NOTATION ::= "Re" "=" type(ReType) ","
"Im" "=" type(ImType)
VALUE NOTATION ::= value(ReValue ReType) "+"
value(ImValue ImType) "i"
<VALUE SEQUENCE { real-p ReType,
imaginary-p ImType} ::=
{ real-p ReValue,
imaginary-p ImValue }>
END
相应的,取值可以为:
c1 COMPLEX
Re = INTEGER,
Im = INTEGER ::=
5 + 3 i
由“<”“>”部分定义的是宏等效的“纯”ASN.1定义,如c1等效定义为:
c1 SEQUENCE
{
real-p INTEGER,
imaginary-p INTEGER
} ::= {
real-p {5},
imaginary-p {3}
}
2.14.2 例2-OPERATION
OPERATION MACRO ::=
BEGIN
TYPE NOTATION ::= Argument Result Errors LinkedOperations
VALUE NOTATION ::= value (VALUE
CHOICE { localValue INTEGER,
globalValue OBJECT IDENTIFIER })
Argument ::= "ARGUMENT" NamedType | empty
Result ::= "RESULT" ResultType | empty
Errors ::= "ERRORS" "{" ErrorNames "}" | empty
LinkedOperations ::=
"LINKED" "{" LinkedOperationNames "}"
| empty
ResultType ::= NamedType | empty
NamedType ::= identifier type | type
ErrorNames ::= ErrorList | empty
ErrorList ::= Error | ErrorList "," Error
Error ::= value(ERROR) | type
LinkedOperationNames ::= OperationList | empty
OperationList ::= Operation | OperationList "," Operation
Operation ::= value(OPERATION) | type
END
相应一个值为:
get-subscriber-name OPERATION
ARGUMENT NumericString (SIZE (10))
RESULT IA5String
ERRORS {unknown, db-unavailable}
::= localValue:1
2.15 参数化Parameterization
为了描述更为通用的数据结构,在ASN.1中,可以对SEQUENCE、SET和CHOICE进行参数化,参数以花括号表示,放在名字之后。如:
DirectoryString{INTEGER:maxSize} ::= CHOICE
{
teletexString TeletexString (SIZE (1..maxSize)),
printableString PrintableString (SIZE (1..maxSize)),
universalString UniversalString (SIZE (1..maxSize)),
bmpString BMPString (SIZE (1..maxSize)),
utf8String UTF8String (SIZE (1..maxSize))
}
其中参数maxSize是以小写字母开头的,而且有INTEGER类型限定(governed)。
下表详细描述了各种参数化的情况:
Table 2-9 参数分类

使用上述参数化类型:
SubstringAssertion ::= SEQUENCE OF CHOICE
{
initial [0] DirectoryString{ub-match},
any [1] DirectoryString{ub-match},
final [2] DirectoryString{ub-match}
}
ub-match INTEGER ::= 128
当然SubstringAssertion类型更为通用的形式是(这种情况成为参数的传播):
SubstringAssertion{INTEGER:maxSize} ::= SEQUENCE OF CHOICE
{
initial [0] DirectoryString{ub-match},
any [1] DirectoryString{ub-match},
final [2] DirectoryString{ub-match}
}
参数的作用域范围和它右面定义范围相同。
当参数是一个类型时,要注意其tag应当是明确的。如果模块不是AUTOMATIC TAGS模式,则需要明确指定。
此外,当参数是一个类型时,也可以用它作为另一个值或者值集合参数的限定,如:
GeneralForm{T, T:val} ::= SEQUENCE
{
info T DEFAULT val,
comments IA5String
}
该类型的一个特化是:
Form ::= GeneralForm{BOOLEAN, TRUE}
在信息对象中使用参数化:
MESSAGE-PARAMETERS ::= CLASS
{
&max-priority-level INTEGER,
&max-message-buffer-size INTEGER,
&max-reference-buffer-size INTEGER
}
WITH SYNTAX
{
MAXIMUM PRIORITY &max-priority-level
MAXIMUM MESSAGE BUFFER &max-message-buffer-size
MAXIMUM REFERENCE BUFFER &max-reference-buffer-size
}
Message-PDU{MESSAGE-PARAMETERS:param} ::= SEQUENCE
{
priority INTEGER (0..param.&max-priority-level !Exception:priority),
message UTF8String (SIZE(0..param.&max-message-buffer-size)
!Exception:message),
comments UTF8String (SIZE(0..param.&max-reference-buffer-size)
!Exception:comments)
}
Exception ::= ENUMERATED {priority(0), message(1), comments(2), ...}
当在模块中导入、导出参数化类型时,建议在其后用花括号给出参数化引用,如:
Forward{OPERATION:OperationSet} OPERATION ::=
{
OperationSet | OperationSet.&Linked.&Linked |
OperationSet.&Linked.&Linked.&Linked.&Linked
}
Reverse{OPERATION:OperationSet} OPERATION ::=
{
Forward{{OperationSet.&Linked}}
}
在模块导入、导出时:
ModuleName DEFINITIONS ::=
BEGIN
EXPORTS Forward{}, Reverse{}, ForwardAndReverse;
IMPORTS
OPERATION FROM Remote-Operations-Information-Objects
{joint-iso-itu-t remote-operations(4)
informationObjects(5) version1(0)}
Forward{}, Reverse{} FROM Remote-Operations-Useful-Definitions
{joint-iso-itu-t remote-operations(4)
useful-definitions(7) version1(0)};
-- dynamically extensible object set:
MyOperationSet OPERATION ::= {...}
-- non-parameterized definition:
ForwardAndReverse OPERATION ::=
{Forward{{MyOperationSet}} UNION Reverse{{MyOperationSet}}}
END
前面讨论过参数传播的情况,但是一般传播迟早都会结束于最高层的类型:PDU。它构成了通讯系统间交换消息的抽象语法(Abstract Syntax)。如果最终的PDU中因具体实现而还留有参数,这种称为抽象语法参数(Parameter of Abstract Syntax),它只能出现在子类型约束中。如:
CharacterString{INTEGER:max-length} ::= CHOICE
{
teletexString TeletexString (SIZE (1..max-length)
!exceeds-max-length),
printableString PrintableString (SIZE (1..max-length)
!exceeds-max-length)
}
exceeds-max-length INTEGER ::= 999
---第二部分结束---