【原创】java中各种集合类的实现浅析
【LinkedList】
LinkedList使用了链表来实现List功能,而且是双向循环链表,它的Entry定义如下:
private static class Entry<E> { //保存放入list中的对象 E element; //当前节点的下一节点 Entry<E> next; //当前节点的上一节点 Entry<E> previous; //新构造的entry,next节点为头节点,previous为尾节点, //新插入的节点在尾节点之后 Entry(E element, Entry<E> next, Entry<E> previous) { this.element = element; this.next = next; this.previous = previous; } }
插入一个节点时:
private Entry<E> addBefore(E o, Entry<E> e) { Entry<E> newEntry = new Entry<E>(o, e, e.previous); //定义节点在链表中的链接方式,插入一个新节点 newEntry.previous.next = newEntry; newEntry.next.previous = newEntry; size++; modCount++; return newEntry; }
可见,只需要移动指针即可,当按照节点索引删除时,需要将节点先查询到:
private Entry<E> entry(int index) { if (index < 0 || index >= size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); //定位头节点 Entry<E> e = header; //如果要寻找的索引小于链表长度的一半,则从头开始找,否则从尾部开始找 if (index < (size >> 1)) { for (int i = 0; i <= index; i++) e = e.next; } else { for (int i = size; i > index; i--) e = e.previous; } return e; }
可见,此时变成了顺序查找,不过此处小小的优化了一下,如果按照对象来删除,那就成了全表扫描了,呵呵:
public boolean remove(Object o) { if (o==null) { for (Entry<E> e = header.next; e != header; e = e.next) { if (e.element==null) { remove(e); return true; } } } else { for (Entry<E> e = header.next; e != header; e = e.next) { if (o.equals(e.element)) { remove(e); return true; } } } return false; }
【ArrayList】
使用数组来实现,相对来说,通过数组下标访问效率很高,但是通过对象访问效率仍然不高,大量的使用了System.arrayCopy方法来拷贝数组。
【Vector】
和arraylis比较相似,都是使用数组来实现,不过二者空间扩展的方式不同,arraylist默认为50%+1,vector为一倍,而且操作方法都是线程安全的,不过效率要慢。
【HashMap】
HashMap的原理比以上都要复杂,可以说HashMap是集成了链表的快速增删和数组的快速随机读取功能于一身,仔细看了下HashMap的源码,其结构如下:
其内部的Entry定义:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; final int hash; //定义了一个指针,指向该节点的下一个节点 Entry<K,V> next; /** * Create new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } public K getKey() { return HashMap.<K>unmaskNull(key); } public V getValue() { return value; } public V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; }
可见,entry内部定义了一个指针(引用),该引用就是指向其他节点,这不就是一个单链表吗?下面看一下往map中增加对象时的方法:
public V put(K key, V value) { if (key == null) return putForNullKey(value); //首先获取该key的hash值 int hash = hash(key.hashCode()); //通过该hash值结合hash表的长度,计算出该key应该落在数组的哪个位置 int i = indexFor(hash, table.length); //找到数组位置后,遍历该数组的entry节点,通过头节点的指针遍历所有的entry,找到目标节点 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
可见,hashMap的结构有点像查字典,如果想要查一个字,首先根据字的拼音(hash值)找到字所在的大体位置(数组),找到大体位置,然后一个个的去对比找到确定的位置。如这张图,左边就是数组,数组中都存放着一个entry头节点,而每个头节点后面都串联着很多entry,当要查找时,首先计算查找对象的hash值,确定该对象在哪个数组中,找到数组位置(随机访问)后,拿到entry头节点,然后线性遍历该链表,找到对应的具体节点,可见,hashmap解决冲突的办法就是链接地址法,将所有hash值相同的对象链接起来。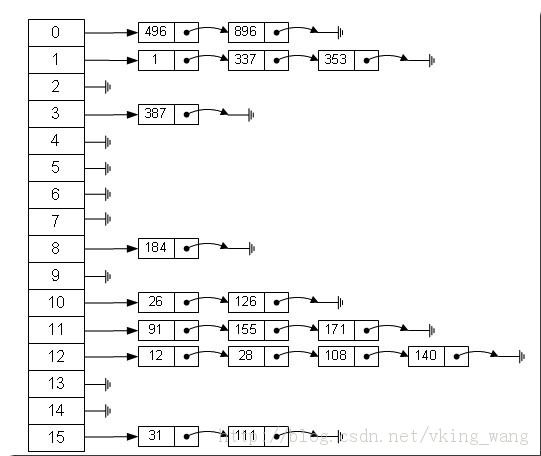
【linkedHashMap】
继承自HashMap,大部分功能都由HashMap来实现,不同的是其中的Entry,使用一个双向链表来维护节点插入的顺序,而且使用LRU算法来维护链表中节点的顺序,对于经常使用的节点,将其拿到链表的最前面。
private static class Entry<K,V> extends HashMap.Entry<K,V> { // These fields comprise the doubly linked list used for iteration. Entry<K,V> before, after; Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } /** * Remove this entry from the linked list. */ private void remove() { before.after = after; after.before = before; }
LinkedHashMap.Entry继承自HashMap.Entry,可见,除了自身的before和after指针之外,还继承了一个next指针,其中,这三个指针的用处分别为:
before和after维护着节点的插入顺序,这就像一根线,将节点按照插入顺序穿起来,而存在一个header引用,表示头节点,而next指针仍然起着链接hash冲突的节点。当执行hash查找时,仍然使用先table再链表的形式,而当迭代时,会按照before和after指针串联的方式进行迭代,
其中有before和after指针,指针的连接标示着节点的插入顺序,当迭代的时候按照这个顺序来迭代。
我画了个图简单描述如下:

图中虚线部分就是before和after指针,实线部分就是next指针,而黑体箭头就是header节点,代表最先插入的节点或者最近用到的节点。
【TreeMap】
treemap是排序的map,背后使用了平衡二叉树来实现,具体的是红黑树,看它的entry定义:
static class Entry<K,V> implements Map.Entry<K,V> { K key; V value; Entry<K,V> left = null; Entry<K,V> right = null; Entry<K,V> parent; boolean color = BLACK; /** * Make a new cell with given key, value, and parent, and with * <tt>null</tt> child links, and BLACK color. */ Entry(K key, V value, Entry<K,V> parent) { this.key = key; this.value = value; this.parent = parent; }
可见,entry就是树的一个节点,其中定义了一个color属性,代表红黑。由于使用红黑树来实现,当插入新节点或者删除节点时,需要重新调整树,使其满足红黑规则:
public V put(K key, V value) { //首先找到root节点 Entry<K,V> t = root; //如果root为空,则新建一个节点 if (t == null) { incrementSize(); root = new Entry<K,V>(key, value, null); return null; } //依次根据root往下遍历 while (true) { //此处相当于二分查找,将当前节点和目标节点对比,如果小就往右走,否则往左走 int cmp = compare(key, t.key); if (cmp == 0) { //如果想等,直接覆盖替换 return t.setValue(value); } else if (cmp < 0) { //如果小则往左走 //如果左节点不为空,那么直接再次左移 if (t.left != null) { t = t.left; } else { //否则就增加空间,然后新建节点,将该节点插入到空的节点处 incrementSize(); t.left = new Entry<K,V>(key, value, t); //插入了新节点,打破了平衡,所以需要重新调整树使其满足红黑规则 fixAfterInsertion(t.left); return null; } } else { // cmp > 0 if (t.right != null) { t = t.right; } else { incrementSize(); t.right = new Entry<K,V>(key, value, t); fixAfterInsertion(t.right); return null; } } } }
由于使用了平衡查找树,所以查找节点时效率是很高的,就是一个二分查找树:
private Entry<K,V> getEntry(Object key) { Entry<K,V> p = root; K k = (K) key; while (p != null) { int cmp = compare(k, p.key); if (cmp == 0) return p; else if (cmp < 0) p = p.left; else p = p.right; } return null; }
【HashTable】
和HashMap差不多,不过其方法是同步的,ConcurrentHashMap和它比较类似,只是后者的get方法不需要同步,所以效率想对更高效。
【HashSet】
本质上由hashMap来实现,只是对象不能重复:
public boolean add(E o) { return map.put(o, PRESENT)==null; }
【TreeSet】
本质上默认由TreeMap来实现,默认构造函数将使用TreeMap来实现。
public TreeSet() { this(new TreeMap<E,Object>()); }
TreeSet也是排序的,可以指定排序器,如果不指定则使用默认的自然序列排序器来排序。