Haystack - Facebook图片存储系统 论文阅读小结
Haystack是Facebook的海量图片存储系统,论文《Finding a needle in Haystack: Facebook’s photo storage》 发表于OSDI 2010上的一篇文章。这个学期准备认认真真的看一些经典的存储系统的文章,这周就是Haystack。
整体来说,Haystack给我最深的印象就是:简单、有效。不适用拗口的术语、复杂的理论,整个系统基于一个明确的目标:降低每个图片所需的元数据,进而使元数据可以完全访问内存,从而减少甚至避免获取图片元数据时的磁盘访问,提高对long tail(长尾)图片访问的速度。
存储场景
作为一个专用的存储系统,我们首先必须清晰的定义该存储系统的使用场景。Facebook图片存储的相应场景为:
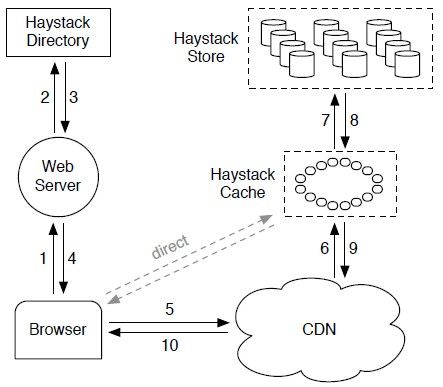
Haystack Sore:
负责图片的持久化存储,也是系统中唯一管理图片的文件系统层面元数据(Filesystem Metadata)的组件。所谓文件系统层面的元数据是指,这个元数据指导如何从物理磁盘上读取图片数据;对应的还有应用层面的元数据(Application Metadata),这个元数据指明如何构建浏览器访问图片的URL。
Haystack Directory:
负责维护图片逻辑地址到物理地址的映射,以及其他一些application metadata。Directory负责为图片生成URL,并返回给Web Server,Web Server将讲图片URL返回给浏览器,浏览器获取图片URL时,就会根据URL的地址向CDN或HayStack Cache请求图片数据了。URL的格式如下:
http://<CDN>/<Cache>/<Machine id>/<Logical volume, Photo>
Haystack Cache:
cache类似一个内部的CDN,它为Store提供popular picture的cache,并在上游的CDN节点出现故障时提供庇护,接受客户端的直接请求以重新读取内容。
这里有一个非常特别的点,给我的印象很深刻,就是关于Cache中缓存些什么数据的问题。如果CDN发生了read miss,请求到Caceh,又发生了read miss,则访问Store获取数据,按照一般的理解,这个数据应该被缓存在Cache中。但是在Haystack中,却比较特别,必须满足以下两点才会cache:
- the request comes directly from a user and not the CDN
- the photo is fetched from a write-enabled Store machine. (表明这个图片是最近写入的,因为较早写入的图片所在的物理机很可能已经写满,进入read-only状态)
这两个条件的设定,是Facebook根据对其图片分享应用的用户行为分析得到的:photos are most heavily accessed soon after they are uploaded and filesystems for our workload generally perform better when doing either reads or writes but not both。
Needle
至此,我们还没有提到如何实现对图片的元数据进行减小的方法。现在,就来简单谈谈,更多细节请参见论文:)
facebook将多个图片作为一个文件进行存储,这样就可以避免每个图片存储一个文件带来的大量文件元数据的问题。并将该文件称为一个superblock,superblock中的每个图片就称为Needle,一个Needle包含该图片的元数据,和其实际的数据内容,如下图所示:
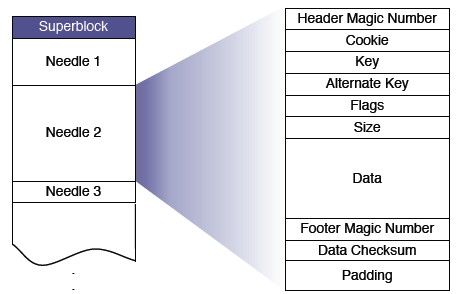
新图片写入的方式与LOG类似,采用追加的方式。如果一个图片被删除了,则只需对Flags标志位进行置位,并在compaction阶段进行真正的删除。
haystack将每个小文件(needle)在大文件(superblock)中的分布映射保存在内存中,这就减少了查找文件所需的磁盘访问次数。而且这些元信息是根据应用需求而定制的,每个图片需要10字节的元信息(4个尺寸的图片共40字节),而 XFS 需要536字节。
关于Index File、图片存储空间的compaction、一个图片的请求、上传、删除、修改过程这里就不再赘述了,文章的英文很好理解,可以去看看。很简单的实现思想,但结合了具体场景的trick,就变得非常有效。
嗯,我喜欢随后一句话。