设计模式 一、软件设计原则
一、理解设计原则
1、单一原则
1.1 如何理解单一职责原则(SRP)
单一职责原则(Single Responsibility Principle,简称SRP),他要求一个类或模块应该只负责一个特定的功能,这有助于降低类之间的耦合度,提高代码的可读性和可维护性。
单一职责原则的定义非常简单,一个类只负责完成一个职责或者功能,也就是说,不要设计大而全的类,要设计粒度小、功能单一的类,换个角度来讲,就是一个类包含了两个或者以上业务不相干的功能,那我们就说它职责不够单一,应该将它拆分成多个功能更加单一,粒度更细的类。
1.2 如何判断类的职责是否单一
大部分情况下,类里的方法是归为同一类功能,还是归为不相关的两类功能,并不是那么容易判定的,在真实的软件开发中,对于一个类是否自责单一的判定,是很难拿捏的。不同的应用场景、不同阶段的需求背景下,对同一个类的职责是否单一的判定,可能都是不一样的。所以我们可以先写一个粗粒度的类,满足业务需求,随着业务的发展,如果粗粒度的类越来越大,代码越来越多,这个时候我们就可以将这个粗粒度的类,拆分成几个更细粒度的类,这就是所谓的持续重构。
提供一些比较粗略的判断原则,去思考类是否职责单一:
1)类中的代码行数、函数或属性过多,会影响代码的可读性和可维护性,我们就需要考虑对类进行拆分。
2)类依赖的其他类过多,或者依赖类的其他类过多,不符合高内聚、低耦合的设计思想,我们就需要考虑对类进行拆分。
3)私有方法过多,我们就要考虑能否将私有方法独立到新类当中,设置为public方法,供更多的类使用,从而提高代码的复用性。
4)比较难给类起一个合适的名字,很难用一个业务名词概括,或者只能用一些笼统的 Manager、Context 之类的词语来命名,这就说明类的职责定义得可能不够清晰;
5)类中得大量方法都是集中操作类中得某几个属性,比如,在UserInfo例子中,如果一半方法都是在操作address信息,那就可以考虑将这几个属性和对应得方法拆分出来。
只供参考。
1.3 类得职责是否设计的越单一越好
单纯为了满足单一职责,把类拆分得很细致,并不是一定最好的,不管是应用设计原则,还是设计模式,最终得目的还是提高代码得可读性、可扩展性、复用性、可维护性等。我们在考虑应用一个设计原则是否合理得时候,也可以以此作为最终考量标准。
2、开闭原则
开闭原则是SOLID中最难理解、最难掌握,同时也是最有用得一条原则。
2.1 原理概述
开闭原则得英文全称是 Open Closed Principle,简写OCP。它得英文描述是:
software entities (modules, classes, functions, etc.) should be open for extension , but closed for modification。我们把它翻译成中文就是:软件实体(模块、类、方法等)应该“对扩展开放、对修改关闭”。
意思就是说:当我们需要添加一个新功能时,应该在已有代码得基础上扩展代码(新增模块、类、方法等),而非修改已有代码(修改模块、类、方法等)。
举一个简单的例子:下面是一个电商平台的订单折扣策略:
class Order {
private double totalAmount;
public Order(double totalAmount) {
this.totalAmount = totalAmount;
}
// 计算折扣后的金额
public double getDiscountedAmount(String discountType) {
double discountedAmount = totalAmount;
if (discountType.equals("FESTIVAL")) {
discountedAmount = totalAmount * 0.9; // 节日折扣,9折
} else if (discountType.equals("SEASONAL")) {
discountedAmount = totalAmount * 0.8; // 季节折扣,8折
}
return discountedAmount;
}
}上面代码中,Order类包含一个计算折扣金额的方法,他根据不同的折扣类型应用折扣。当我们需要添加新的折扣类型时,就不得不修改 getDiscountedAmount 方法的代码,这显然不合理,这就违反了开闭原则。
遵循开闭原则的代码:
// 抽象折扣策略接口
interface DiscountStrategy {
double getDiscountedAmount(double totalAmount);
}
// 节日折扣策略
class FestivalDiscountStrategy implements DiscountStrategy {
@Override
public double getDiscountedAmount(double totalAmount) {
return totalAmount * 0.9; // 9折
}
}
// 季节折扣策略
class SeasonalDiscountStrategy implements DiscountStrategy {
@Override
public double getDiscountedAmount(double totalAmount) {
return totalAmount * 0.8; // 8折
}
}
class Order {
private double totalAmount;
private DiscountStrategy discountStrategy;
public Order(double totalAmount, DiscountStrategy discountStrategy) {
this.totalAmount = totalAmount;
this.discountStrategy = discountStrategy;
}
public void setDiscountStrategy(DiscountStrategy discountStrategy) {
this.discountStrategy = discountStrategy;
}
// 计算折扣后的金额
public double getDiscountedAmount() {
return discountStrategy.getDiscountedAmount(totalAmount);
}
}在遵循开闭原则的代码中,我们定义了一个抽象的折扣策略接口 DiscountStrategy,然后为每种折扣类型创建了一个实现该接口的策略类。Order 类使用组合的方式,包含了一个DiscountStrategy 类型的成员变量,以便在运行时设置或更改折扣策略,(可以通过编码,配置、依赖注入等形式)。这样,当我们需要添加新的折扣类型时,只需要DiscountStrategy 接口即可,而无需修改现有的Order代码,这个例子遵循了开闭原则。
2.2 修改代码就意味着违背开闭原则么
开闭原则的核心思想是要尽量减少对现有代码的修改,以降低修改带来的风险和影响,在实际开发过程中,完全不修改代码是不现实的。当需求变更或者发现代码中的错误时,修改代码是正常的。然而,开闭原则鼓励我们通过设计更好的代码接口,使得在添加新功能或者扩展系统时,尽量减少对现有代码的修改。
2.3 如何做到 “对扩展开放、修改关闭”
开闭原则讲的就是代码的扩展性问题,是判断一段代码是否易扩展的“黄金标准”。如果某段代码在应对未来需求变化的时候,能够做到“对扩展开放、对修改关闭”,那就说明这段代码的扩展性比较好,事实上,学习设计模式很重要的一个目的就是i写出扩展性好的代码。
为了尽量写出扩展性好的代码,我们要时刻具备扩展意识、抽象意识、封装意识。这些潜意识可能比任何开发技巧都重要。
我们应该思考一些问题:
· 我们要写的这段代码未来可能有哪些需求变更、如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,不需要改动代码整体结构、做到最小代码改动的情况下,新的代码能够很灵活的插入到扩展点上,做到“对扩展开放、对修改关闭”
· 我们还要识别出代码可变部分和不可变部分,要将可变封装起来,隔离变化,提供抽象化的不可变接口,给上层系统使用。当具体的实现放上变化的时候,我们只需要基于相同的抽象接口,扩展一个新的实现,替换到老的实现即可,上游系统的代码几乎不需要修改。
经过以上思考,我们可以使用以下策略:
1.抽象与封装:通过定义接口或抽象类来封装变化的部分,将共性行为抽象出来。当需要添加新功能时,只需要实现接口或继承抽象类,而不需要修改现有代码。
2.组合/聚合:使用组合或聚合的方式,将多个不同功能模块组合在一起,形成一个更大的系统。当需要扩展功能时,只需要添加新的组件,而不需要修改现有的组件。
3.使用依赖注入。
4.使用设计模式:设计模式是针对某些特定问题的通用解决方案,很多设计模式都是为了支持“对扩展开放、修改关闭”的原则。例如,策略模式、工厂模式、装饰器模式等,都是为了实现这个原则。
5.使用事件和回调:通过事件驱动和回调函数,可以让系统在运行时根据需要动态的添加或修改功能,而无需修改现有代码。
6.使用插件机制:通过插件机制,可以允许第三方开发者为系统添加新功能,而无需修改系统的核心代码。这种机制常用于框架和大型软件系统中。
3、里氏替换原则
3.1 原理概述
里氏替换原则的英文翻译是:Liskov Substitution Principle,缩写为LSP。这个原则最早在1986年由Barbara Liskov提出,它是这么描述这条原则的:
Functions that use pointers of references to base classes must be able to use objects of derived classes without knowing it。(使用基类引用指针的函数必须能够在不知情的情况下使用派生类的对象。)
意思就是:子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
以下是一个简单的示例:
// 基类:鸟类
public class Bird {
public void fly() {
System.out.println("I can fly");
}
}
// 子类:企鹅类
public class Penguin extends Bird {
// 企鹅不能飞,所以覆盖了基类的fly方法,但这违反了里氏替换原则
public void fly() {
throw new UnsupportedOperationException("Penguins can't fly");
}
}上面的例子,重写了父类的方法,但是却抛出了异常,或者对父类的方法的传参做了限制,这样其实就违反了里氏替换原则。我们可以重新设计类结构,将能飞的行为抽象到一个接口中,让需要的飞行能力的鸟实现这个接口:
// 飞行行为接口
public interface Flyable {
void fly();
}
// 基类:鸟类
public class Bird {
}
// 子类:能飞的鸟类
public class FlyingBird extends Bird implements Flyable {
@Override
public void fly() {
System.out.println("I can fly");
}
}
// 子类:企鹅类,不实现Flyable接口
public class Penguin extends Bird {
} 通过这样的设计,我们遵循了里氏替换原则,同时也保证了代码的可维护性和复用性。
再来看一个基于数据库操作的案例,假设我们正在开发一个支持多种数据库的程序,包括mysql、PostgreSql和SQLite。我们可以这么设计:
首先,定义一个抽象的的Database基类,它包含一些通用的数据库操作方法,如:connect()、disconnect()和executeQuery()。这些方法的具体实现将在子类中完成。
public abstract class Database {
public abstract void connect();
public abstract void disconnect();
public abstract void executeQuery(String query);
}然后,为每种数据库类型创建一个子类,继承自Database基类,这些子类需要实现基类中定义的抽象方法,并可以添加特定于各自数据库的方法。
public class MySQLDatabase extends Database {
@Override
public void connect() {
// 实现MySQL的连接逻辑
}
@Override
public void disconnect() {
// 实现MySQL的断开连接逻辑
}
@Override
public void executeQuery(String query) {
// 实现MySQL的查询逻辑
}
// 其他针对MySQL的特定方法
}
public class PostgreSQLDatabase extends Database {
// 类似地,为PostgreSQL实现相应的方法
}
public class SQLiteDatabase extends Database {
// 类似地,为SQLite实现相应的方法
}这样设计的好处是,我们可以在不同的数据库类型之间灵活切换,而不需要修改大量代码,只要这些子类遵循里氏替换原则,我们就可以放心的使用基类的引用来操作不同类型的数据库,例如:
public class DatabaseClient {
private Database database;
public DatabaseClient(Database database) {
this.database = database;
}
public void performDatabaseOperations() {
database.connect();
database.executeQuery("SELECT * FROM users");
database.disconnect();
}
}
public class Main {
public static void main(String[] args) {
// 使用MySQL数据库
DatabaseClient client1 = new DatabaseClient(new MySQLDatabase());
client1.performDatabaseOperations();
// 切换到PostgreSQL数据库
DatabaseClient client2 = new DatabaseClient(new PostgreSQLDatabase());
client2.performDatabaseOperations();
// 切换到SQLite数据库
DatabaseClient client3 = new DatabaseClient(new SQLiteDatabase());
client3.performDatabaseOperations();
}
}里氏替换是一种设计原则,是用来指导继承关系中的子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
3.2 哪些代码明显违背了LSP?
违背里氏替换原则(LSP)的代码通常具有以下特征:
1)子类覆盖或修改了基类的方法
当子类覆盖或修改了基类的方法时,可能导致子类无法替换基类的实例而不引起问题。这违反了LSP,会导致代码变得脆弱和不宜维护。
2)子类违反了基类的约束条件
当子类违反了基类中的定义的约束条件(如输入、输出或异常等),也会违反LSP
3)子类与基类之间缺乏“is-a”关系
当子类与基类缺乏真正的“is-a”关系时,也可能导致违反LSP。例如,如果一个类继承自另一个类,仅仅因为它们具有部分相似性,而不是完全的“is-a"关系,那么这种继承关系可能不满足LSP.
为了避免违法LSP,我们需要在设计和实现过程中注意以下几点:
1、确保子类和基类之间存在真正的”is-a“关系
2、遵循其他设计原则,如单一职责原则、开闭原则和依赖导致原则。
4、接口隔离原则
4.1 原理概述
接口隔离原则的英文翻译是”Interface Segregation Principle“,缩写为ISP。Robert Martin 在 SOLID 原则中是这样定义它的:“Clients should not be forced to depend upon interfaces that they do not use。” 直译成中文的话就是:客户端不应该强迫依赖它不需要的接口。其中”客户端“,可以理解为接口的调用者或者使用者。
实际上,”接口“这个名词可以用在很多场合中。生活中我们可以用它来指插座接口等,在软件开发中,我们既可以把它看作一组抽象的约定,也可以具体指系统与系统之间的API接口,还可以特指面向对象编程语言中的接口等。
可以把”接口“理解为下面三种东西:
1)一组api接口集合
2)单个api接口或函数
3)OOP中接口的概念
接口隔离原则的解读与应用:
接口隔离原则是一种面向对象编程的设计原则,他要求我们将打的、臃肿的接口拆分成更小、更专注的接口,以确保类之间的解耦。这样,客户端只需要依赖它实际使用的接口,而不需要依赖那些无关的接口。
接口隔离原则有以下几个要点:
1)将一个大的、通用的接口拆分成多个专用的接口。这样可以降低类之间的耦合度,提高代码的可维护性和可读性。
2)为每个接口顶一个独立的职责。这样可以确保接口的粒度适度,同时也有助于遵循单一职责原则。
3)在定义接口时,要考虑到客户端的实际需求。客户端不应该被迫实现无关的接口方法。
接口隔离原则实例:
假设正在开发一个机器人程序,机器人具有多种功能,如行走、飞行和工作。我们可以为这些功能创建一个统一的接口:
public interface Robot {
void walk();
void fly();
void work();
}然而,这个接口并不符合接口隔离原则,因为他将多个功能聚合在了一个接口中。对于哪些只需要实现部分功能的客户端来说,这个接口导致不必要的依赖,为了遵循接口隔离原则,我们可以将这个接口拆分成多个更小、更专注的接口:
public interface Walkable {
void walk();
}
public interface Flyable {
void fly();
}
public interface Workable {
void work();
}现在,我们可以根据需要为不同类型的机器人实现不同的接口。例如,对于一个只能行走和工作的机器人,我们只需要实现 walkable 和 wokable 接口:
public class WalkingWorkerRobot implements Walkable, Workable {
@Override
public void walk() {
// 实现行走功能
}
@Override
public void work() {
// 实现工作功能
}
}通过接口隔离原则,我们确保了代码的可维护性和可读性,同时也降低了类之间的耦合度,在实际项目中,要根据需求和场景来判断何时应用接口隔离原则。
上面的例子,并不说每个接口只能定义一个方法,而是说我们需要权衡接口的粒度和实际需求。过渡拆分接口可能导致过多的单方法接口,这会增加代码的复杂性,降低可读性和可维护型。
一个接口包含多个方法是合理,只要这些方法服务于一个单一的职责,例如一个数据库操作接口可能包含 connect() 、disconnect()、executeQuery()等方法,这些方法都是数据库操作的一部分,因此可以放在同一个接口中。
4.2 案例分析
1)案例一
例如微服务用户系统提供了一组跟用户相关的API给其他系统使用,比如:注册、登录、获取用户信息等。具体代码如下:
public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public class UserServiceImpl implements UserService {
//...
}现在我们要实现后台管理系统要实现删除用户的功能,希望用户系统提供一个删除用户的接口。删除用户是一个非常慎重的操作,我们只希望通过后台管理系统来执行,所以这个接口只限于给后台管理系统使用。如果放在UserService中,那所有使用到UserService的系统,都可以调这个接口,不加限制的被其他业务系统调用,就有可能导致误删用户。
最好的解决方法是从架构设计的层面,通过接口鉴权的方式来限制接口的调用,不过,如果暂时没有鉴权的框架来支持,我们还可以从代码设计的层面,尽量避免接口被误用。参照接口隔离原则,调用者不应该强迫依赖它不需要的接口,将删除接口单独放到另一个接口 RestrictedUserService 中,然后将RestrictedUserService 只打包提供给后台管理系统来使用。
public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public interface RestrictedUserService {
boolean deleteUserByCellphone(String cellphone);
boolean deleteUserById(long id);
}
public class UserServiceImpl implements UserService, RestrictedUserService {
// ... 省略实现代码...
}在设计微服务或者类库接口的时候,如果部分接口只被部分调用者使用,那我们就需要将这部分接口隔离出来,单独给对应的调用者使用,而不是强迫其他调用者也依赖这部分不会被用到的接口。
2)案例二
public class Statistics {
private Long max;
private Long min;
private Long average;
private Long sum;
private Long percentile99;
private Long percentile999;
//... 省略 constructor/getter/setter 等方法...
}
public Statistics count(Collection dataSet) {
Statistics statistics = new Statistics();
//... 省略计算逻辑...
return statistics;
} 上面的代码中,count() 函数功能不够单一,包含很多不同的统计功能,比如,求最大值、最小值、平均值等等。按照接口隔离原则,我们应该把count()函数拆成几个更小粒度的函数,每个函数负责一个独立的统计功能。拆分之后的代码如下所示:
public Long max(Collection dataSet) { //... }
public Long min(Collection dataSet) { //... }
public Long average(Colletion dataSet) { //... }
// ... 省略其他统计函数... 在某种意义上讲,count() 函数也不能算是职责不够单一,毕竟他做的事情只跟统计相关。我们再讲单一职责原则的时候,也提到类似的问题。实际上,判定职责是否单一,除了很强的主观性,还需要结合具体的场景。
接口隔离原则跟单一职责原则有点类似,不过稍微还是有点区别。单一职责原则针对的模块、类、接口的设计。而接口隔离原则相对于单一职责原则,一方面它更侧重于接口的设计,另一方面它的思考的角度不同。他提供了一种判断接口是否职责单一的标准:通过调用者如何使用接口来间接地判定。如果调用者只使用部分接口或接口地部分功能,那接口地设计就不够职责单一。
5、依赖倒置原则
关于SOLID原则,单一职责、开闭、里氏替换、接口隔离还有最后一个 依赖倒置原则。
5.1 原理
依赖倒置原则(Dependency Inversion Principle,简称DIP)是面向对象设计地五大原则(SOLID)之一。这个原则强调要依赖于抽象而不是具体实现。遵循这个原则可以使系统地设计更加灵活、可扩展和可维护。
依赖倒置原则有两个关键点:
1、高层模块不应该依赖于底层模块,他们都应该依赖于抽象。
2、抽象不应该依赖于具体实现,具体实现应该依赖于抽象。
倒置(Inversion)在这里的确是指“反过来”的意思。在依赖倒置原则(Dependency Inversion Principle,DIP)中,我们需要改变依赖关系的方向,使得高层模块和低层模块都依赖于抽象,而不是高层模块直接依赖于底层模块。这样依赖,依赖关系就从直接依赖具体实现“反过来”依赖抽象了。
如果高层模块直接依赖于底层模块。这会导致系统的耦合度较高,底层模块的变化很容易影响到高层模块。当我们应用依赖倒置原则时,高层模块和低层模块的依赖发生了改变,他们都依赖于抽象(例如接口或者抽象类),而不是是高层模块直接依赖于底层模块。这样我们就实现了依赖关系的“倒置”。
这种倒置的依赖关系使得系统的耦合度降低,提高了系统的可维护性和可扩展性。因为当低层模块的具体实现发生变化时,只要不改变抽象,高层模块就不需要进行调整。所以这个原则叫做依赖倒置原则。
5.2 如何理解抽象
在倒置原则中的抽象,并不能仅仅理解为一个接口。抽象的目的是将关注点从具体实现转移到概念和行为,使得我们在设计和编写代码时能够更加关注问题的本质,通过使用抽象,我们可以创建更加灵活、可扩展和可维护的系统。
事实上抽象是一个很广泛的概念,它可以包括接口、抽象类记忆由大量接口,抽象类和实现组成的更高层次的模块。通过将系统分解为更小的、可复用的组件,我们可以实现更高层次的抽象。这些组件可以独立的进行替换和扩展,从而使整个系统更加灵活。
在依赖倒置有原则的背景下,我们可以从以下几个方面理解抽象:
1)接口
接口是java中实现抽象的一种常见的方式。接口定义了一组方法签名,表示实现该接口的类应具备哪些行为。接口本身并不包含具体实现。所以他强调了行为的抽象。
假设我们正在开发一个在线购物系统,其中有一个订单处理模块。订单处理模块需要于不同的支付服务提供商进行交互。如果我们直接依赖于支付服务提供商的具体实现,那么在更换支付服务提供商或添加的新的支付服务提供商时,就需要对订单处理模块斤西瓜大量修改,为了避免这种情况。我们应该依赖于接口而不是具体实现。
首先:定义一个支付服务接口:
public interface PaymentService {
boolean processPayment(Order order);
}然后,为每个支付服务提供商实现该接口:
public class PayPalPaymentService implements PaymentService {
@Override
public boolean processPayment(Order order) {
// 实现 PayPal 支付逻辑
}
}
public class StripePaymentService implements PaymentService {
@Override
public boolean processPayment(Order order) {
// 实现 Stripe 支付逻辑
}
}最后,我们只需要在订单处理模块中依赖PaymentService接口,而不是具体的实现:
public class OrderProcessor {
private PaymentService paymentService;
public OrderProcessor(PaymentService paymentService) {
this.paymentService = paymentService;
}
public void processOrder(Order order) {
// 其他订单处理逻辑...
boolean paymentResult = paymentService.processPayment(order);
// 根据 paymentResult 处理支付结果
}
}通过这种方式,当我们需要更换支付服务商或者添加新的支付服务提供商时,只需要提供一个新的实现类,而不需要修改OrderProcessor 类。我们可以在运行时通过构造函数注入不同的支付服务实现,使得系统更加灵活和可扩展。
这个例子展示了如何依赖接口而不是实现来编写代码,从而提高系统的灵活性和可维护性。
2)抽象类
抽象类的另一种实现抽象的方式。与接口类似,抽象类也可以定义抽象方法,表示子类应该具备哪些行为。不过抽象类还可以包含部分具体实现,这使得它们比接口更加灵活。
abstract class Shape {
abstract double getArea();
void displayArea() {
System.out.println("面积为: " + getArea());
}
}
class Circle extends Shape {
private final double radius;
Circle(double radius) {
this.radius = radius;
}
@Override
double getArea() {
return Math.PI * Math.pow(radius, 2);
}
}
class Square extends Shape {
private final double side;
Square(double side) {
this.side = side;
}
@Override
double getArea() {
return Math.pow(side, 2);
}
}在这个示例中,我们定义了一个抽象类 shape ,它具有一个抽象方法 getArea,用于计算形状的面积。同时,他还包含了一个具体方法 displayArea,用于打印面积。Circle 和 Square 类继承了Shape,分别实现了getArea方法,在其它类中跟我们可以依赖抽象Shape而非 Square 和 Circle。
3)高层模块
在某些情况下,我们可以通过将系统分解为更小的、可复用的组件来实现抽象。这些组件可以独立地进行替换和扩展,从而使整个系统更加灵活。这种抽象方法往往在软件架构和模块化设计中有所体现。
5.3 如何理解高层模块和底层模块
所谓高层模块和底层模块地划分,简单来说就是,在调用链上,调用者属于高层,被调用者属于底层。在平时地业务代码开发中,高层模块依赖底层模块使没有任何问题地。实际上这条原则主要还是用来指导框架层面地设计,跟前面讲到的控制反转类似。例如 tomcat 和 servlet容器的例子。
比如一个简单的例子,controller 要依赖 service的接口而不是实现。service实现要依赖dao层的接口而不是实现,调用者要依赖被调用者的接口而不是实现。
再比如,Tomcat 是运行 java Web应用程序的容器,我们编写的Web应用程序代码只需要部署在Tomcat容器下,便可以被tomcat容器调用执行。按照之前的划分原则,Tomcat就是高层模块,我们编写的Web应用代码就是底层模块。tomcat 和 应用程序代码之间并没有直接的依赖关系,两者都依赖同一个抽象,也就是sevlet规范。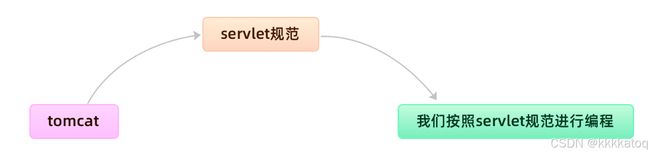
5.4 IOC容器
依赖倒置的目的是,底层模块可以随时替换,以提高代码的可扩展性。
控制反转是一种软件设计原则,它将传统的控制流程颠倒过来,将控制权交给一个中心化的容器或框架。
依赖注入是指不通过 new() 的方式在类内部创建依赖类对象,而是将依赖的类对象在外部创建好之后,通过构造函数、函数参数等方式传递(或注入)给类使用。
通过 控制翻转 和 依赖注入结合,我们只要保证依赖抽象而不是实现,就能很轻松的替换实现。如给容器注入一个mysql 的数据,则所有的依赖数据源的部分会自动使用mysql ,如果向替换数据源则仅仅需要给容器注入一个新的数据源就好了,不需要修改一行代码。
6、KISS原则
前面的五种原则,就是经典的 SOLID 原则。现在简单说一下 KISS原则。
6.1 理解 “KISS原则”
KISS原则(Keep Ii Simple,Stupid):KISS 原则强调保持代码简单,易于理解和维护。在编写代码时,应避免使用复杂的逻辑、算法和技术,尽量保持代码简洁明了。这样可以提高代码的可读性、可维护性和可测试性。但是这并不意味着要牺牲代码的性能和功能,而是要保证性能和功能的前提下,尽量简化代码实现。
6.2 代码简单和代码行数少
冒泡排序:
public class BubbleSort {
public static void main(String[] args) {
int[] arr = {4, 2, 7, 1, 8, 5};
bubbleSort(arr);
for (int i : arr) {
System.out.print(i + " ");
}
}
// 冒泡排序算法实现
public static void bubbleSort(int[] arr) {
int n = arr.length;
// 外层循环控制遍历次数
for (int i = 0; i < n - 1; i++) {
// 内层循环用于比较相邻的元素
for (int j = 0; j < n - 1 - i; j++) {
// 如果前一个元素大于后一个元素,则交换位置
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
}快速排序:
public class QuickSort {
public static void main(String[] args) {
int[] arr = {4, 2, 7, 1, 8, 5};
quickSort(arr, 0, arr.length - 1);
for (int i : arr) {
System.out.print(i + " ");
}
}
// 快速排序算法实现
public static void quickSort(int[] arr, int left, int right) {
if (left < right) {
// 划分数组
int pivotIndex = partition(arr, left, right);
// 分别对左右子数组进行快速排序
quickSort(arr, left, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, right);
}
}
// 将数组划分为两部分,并返回基准元素的索引
public static int partition(int[] arr, int left, int right) {
int pivot = arr[left]; // 选择基准元素
int i = left, j = right;
while (i < j) {
// 从右向左找到一个小于基准的元素
while (i < j && arr[j] >= pivot) {
j--;
}
// 从左向右找到一个大于基准的元素
while (i < j && arr[i] <= pivot) {
i++;
}
// 交换两个元素的位置
if (i < j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// 将基准元素和指针相遇位置的元素交换
arr[left] = arr[i];
arr[i] = pivot;
return i;
}
}我们可以看到,快速排序明显比冒泡排序复杂,多了很多行,但是我们不能说快速排序不符合kiss原则。
6.3 代码逻辑复杂就违背KISS原则么?
并非所有的复杂代码逻辑都违背了KISS原则,KISS原则强调的是保持代码简洁,易于理解和维护。有时候,为了实现某个功能,确实需要一定程度的复杂逻辑。关键在于如何尽可能地让代码简单和清晰。
遵循KISS原则地复杂代码应当具备以下特点:
1)模块化:将复杂地代码逻辑拆分成多个简单、独立地模块,每个模块负责一个特定地功能。这有助于降低代码地复杂度,提高代码地可读性和可维护性。
2)清晰地命名:为变量、方法、类等使用清晰、有意义地命名,以便于其他人阅读和理解代码
3)注释和文档:为复杂的代码逻辑编写清晰、详细的注释和文档,解释代码的作用和实现原理。这有助于其他人更容易地理解和维护代码
4)避免不必要地复杂度:尽量避免引入不必要地复杂性,如使用过于复杂地算法或数据结构。在实现功能地同时,要考虑代码地简洁性和可读性。
总之,遵循KISS原则并不意味着代码必须简单到极致。相反,他鼓励我们在实现功能地同时,尽量保持代码地简洁、易于理解和维护。
7、DRY 原则
DRY原则(Don't Repeat Yourself):DRY原则强调避免代码重复,尽量将相似的代码和逻辑提取到共享的方法、类或模块中。遵循DRY原则可以减少代码的冗余和重复,提高代码的复用性和可维护性。当需要修改某个功能时,只需要修改对应的共享代码,而无需在多处进行相同的修改,这有助于降低维护成本,提高开发效率。
设计原则不是1+1,有些代码在有些场景下就是符合某些原则的,在其他场景下就是不符合的,我们学习dry原则,不能狭隘的理解。不能说两端代码长得一样就是违反dry原则,同时有些看似不重复的代码也有可能维护dry原则。
7.1 实现方法
在java编程中,我们可以通过以下方法遵循DRY原则:
1)使用方法(functions):当你发现自己在多处重复相同的代码时,可以将其抽取为一个方法,并在需要的地方调用该方法。
public class DryExample {
public static void main(String[] args) {
printHello("张三");
printHello("李四");
}
public static void printHello(String name) {
System.out.println("你好," + name + "!");
}
} 在这个例子中,我们使用printHello方法避免了重复的 System.out.println 语句。
2)使用继承和接口:当多个具有相似的行为时,可以使用继承和接口来抽象共享的功能,从而减少重复代码。
public abstract class Animal {
public abstract void makeSound();
public void eat() {
System.out.println("动物在吃东西");
}
}
public class Dog extends Animal {
public void makeSound() {
System.out.println("汪汪");
}
}
public class Cat extends Animal {
public void makeSound() {
System.out.println("喵喵");
}
}在这个例子中,我们使用抽象类Animal 和 继承来避免在Dog 和 Cat类中重复eat方法的代码。
3)重用代码库和框架:使用成熟的代码库和框架可以避免从0开始编写一些通用功能。例如,使用java标准库、Apache Commons 或 Google Guava等库。
7.2 只要两段代码长得一样,那就是违反DRY原则么
不一定,DRY原则的核心思想时减少重复代码,以提高代码的可维护性、可读性和可重用性。然而不是所有看起来相似的代码都违反了DRY原则。在某些情况下,重复的代码片段可能具有完全不同的逻辑含义,因此将它们合并可能会导致误解。
在评估是否违反了DRY原则时,需要考虑到:
1)逻辑一致性,如果两段代码的逻辑和功能是一致的,那么将它们合并为一个方法或类是有意义的。如果它们实际上是在执行不同的任务,那么合并他们可能会导致难以理解的代码。
2)可维护性:如果将两段看似相同的代码合并可能导致难以维护的代码,例如增加了过多的条件判断,那么保留一些重复可能时更好的选择。
3)变更影响:考虑位的需求变更。如果两段看似相同的代码很可能在未来分别发生变化,那么将它们合并可能导致更多的维护负担。在这种情况下,保留一些重复代码可能时更实际的选择。
总之,判断是否违反了DRY 原则需要权衡多个因素。关键在于寻找适当的平衡点,以提高代码质量,同时确保可维护性和可读性。
7.3 什么样的代码违反了DRY原则?
1)功能重复
2)代码执行重复
小节:DRY原则(Don't Repeat Yourself),即不要重复自己的原则,是软件工程中非常重要的一条设计原则。它强调在软件开发中避免重复代码,减少代码的冗余性,提高代码的可维护性、可读性和可扩展性。DRY原则的核心思想是避免重复的代码,尽可能将重复的代码封装成可重用的模块、函数、类等,提高代码的复用性,降低代码的耦合性。
8、迪米特法则
8.1 理论原理
迪米特法则(Law of Demeter,Lod),又称最少知识原则(Least Knowledge Principle ,LKP)是一种面向对象编程设计原则。它的核心思想是:一个对象应该尽量少地了解其他对象,降低对象之间地耦合度,从而提高代码地可维护性和可扩展性。
英文定义:
Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
直译成中文:
每个模块(unit)只应该了解那些与它关系密切的模块(units: only units “closely” related to the current unit)的有限知识(knowledge)。或者说, 每个模块只和自己的朋友“说话”(talk),不和陌生人“说话”(talk)。
按我理解的意思应该是:两个类之间尽量不要直接依赖,如果必须依赖,最好只依赖必要的接口。
迪米特法则地主要指导原则如下:
1)类和类之间尽量不直接依赖
2)有依赖关系地类之间,尽量只依赖必要的接口。
8.2 类之间不直接依赖
不该有直接依赖关系地类之间,不要有依赖,这个原则强调的是降低类与类之间地耦合度,避免不必要地依赖。这通常意味着我们应该使用抽象(如接口或抽象类)来解耦具体实现。
假设有一个简短地报告生成系统,它需要从不同类型地数据源(如数据库、文件、API等)获取数据,并输出不同格式地报告(如CSV,JSON\XML等)。以下是不遵循这一原则地实现:
// 具体的数据库类
class Database {
public String fetchData() {
// 从数据库中获取数据
return "data from database";
}
}
// 具体的报告生成类
class ReportGenerator {
private Database database;
public ReportGenerator(Database database) {
this.database = database;
}
public String generateCSVReport() {
String data = database.fetchData();
// 将数据转换为CSV格式
return "CSV report: " + data;
}
}上述实现中,ReportGenerator 类直接依赖于具体的Database 类。这意味着如果我们想从其他类型地数据源(如文件)获取数据,或者使用不同的数据库实现,我们需要修改ReportGenerator 类。这违反了开闭原则(对扩展开放,对修改封闭),并增加了类与类之间的耦合。
为了遵循“不该有直接依赖关系地类之间,不要有依赖”原则,我们可以引入抽象来解耦具体实现。下面是一个修改后的实现:
// 数据源接口
interface DataSource {
String fetchData();
}
// 具体的数据库类
class Database implements DataSource {
@Override
public String fetchData() {
// 从数据库中获取数据
return "data from database";
}
}
// 具体的文件类
class FileDataSource implements DataSource {
@Override
public String fetchData() {
// 从文件中获取数据
return "data from file";
}
}
// 报告生成类
class ReportGenerator {
private DataSource dataSource;
public ReportGenerator(DataSource dataSource) {
this.dataSource = dataSource;
}
public String generateCSVReport() {
String data = dataSource.fetchData();
// 将数据转换为CSV格式
return "CSV report: " + data;
}
}在修改后的实现中,我们引入了DataSource 接口,并使ReportGenerator 类依赖于该接口,而不是具体的实现。这样,我们可以轻松的为报告生成器添加新的数据源类型,而无需修改现有代码。
通过引入抽象,我们遵循了“不该有直接依赖关系的类之间,不要有依赖”原则,降低了类与类之间的耦合。
8.3 只依赖必要的接口
有依赖关系的类之间,尽量只依赖必要的接口,这个原则强调的是,当一个类需要依赖另一个类时,应该尽可能地依赖于最小化地接口。这样可以降低类与类之间地耦合,提高系统的可扩展性和灵活性。
例如下面的例子:假如我们要开一个飞行比赛,我们可以写出如下地案例来满足迪默特法则:
// 飞行行为接口
public interface Flyable {
void fly();
}
// 基类:鸟类
public class Bird {
}
// 子类:能飞的鸟类
public class Sparrow extends Bird implements Flyable {
@Override
public void fly() {
System.out.println("sparrow can fly");
}
}
// 子类:飞机
public class Plane implements Flyable {
@Override
public void fly() {
System.out.println("plane can fly");
}
}
// 子类:企鹅类,不实现Flyable接口
public class Penguin extends Bird {
}
//
public class AirRace {
List list;
public void addFlyable(Flyable flyable){
list.add(flyable);
}
// ...
}
8.4 辩证思考与灵活应用
在实际工作中,确实需要在不同地设计原则之间进行权衡。迪米特法则,是一种有助于降低类之间耦合度地原则,但过渡地使用迪米特法则可能导致代码变得复杂和难以维护。因此在实际项目中,我们应该根据具体地场景和需求灵活地应用迪米特法则。以下是一些建议:
1. 避免过度封装:尽管迪米特法则强调类之间的低耦合,但是过度封装可能导致系统变得难以理解和维护。当一个类需要访问另一个类的属性或方法时,我们应该权衡封装的成本和收益,而不是盲目地遵循迪米特法则。