随机森林算法
目录
- 第一章 分类回归树
-
- 1.1 分类回归树概述
- 1.2 模型训练
-
- 1.2.1 递归分裂
- 1.2.2 寻找最佳分裂
- 第二章 随机森林
-
- 2.1 随机森林概述
- 2.2 模型组件
-
- 2.2.1 Bootstrap
- 2.2.2 Bagging
- 2.3 模型训练
- 2.4 Sklearn随机森林模型参数
-
- 2.4.1 随机森林参数说明
- 第三章 工程实践
-
- 3.1 数据收集
-
- 3.1.1 数据集介绍
- 3.1.2 数据集的下载地址
- 3.1.3 加载数据
- 3.2 数据探索
-
- 3.2.1 数据概述
- 3.3 特征工程
-
- 3.3.1 整数编码
- 3.4 数据准备
-
- 3.4.1 数据集划分
- 3.5 模型训练
- 3.6 模型评估
- 3.7 模型分析
- 参考文献
第一章 分类回归树
1.1 分类回归树概述
分类回归树(classification and regression tree, CART)是一种二叉树,该模型由Breiman等人在1984年提出,是应用最广泛的决策树学习方法。CART树从根节点开始,每次只对一个特征进行判断,然后进入左子节点或右子节点,直至到达叶子节点为止。
1.2 模型训练
1.2.1 递归分裂
训练一棵决策树是一个递归分裂过程。首先创建根节点,然后递归建立左子树和右子树。假设训练样本集为D,则训练流程如下:
(1) 用训练样本集D建立根节点,利用基尼指数判定规则,将样本分裂成D1和D2两个部分,同时为根节点设定判定规则;
(2) 用D1递归建立左子树;
(3) 用D2递归建立右子树;
(4) 如果不能分裂,则将当前节点标记为叶子节点,同时为它赋值。
1.2.2 寻找最佳分裂
训练时需要找到一个分裂规则把训练样本集分为两个子集,因此,需要确定评价标准,根据它寻找最佳分裂。对于分类问题,要确保分裂之后左右子树的样本尽可能纯,即样本类别单一。为此,需要定义不纯度指标,本文的不纯度指标为基尼指数。
假设数据集 D D D 有 k k k 个类别,其样本总数为 ∣ D ∣ |D| ∣D∣,每个类别的样本数目分别为 ∣ D 1 ∣ , ∣ D 2 ∣ , ⋯ , ∣ D k ∣ |D_1|,|D_2|,\cdots,|D_k| ∣D1∣,∣D2∣,⋯,∣Dk∣,则一个样本属于第 i i i 类的概率为:
p i = ∣ D i ∣ ∣ D ∣ p_i = \frac{|D_i|}{|D|} pi=∣D∣∣Di∣
则数据集 D D D 的基尼指数为:
G i n i ( D ) = ∑ i = 1 k p i ( 1 − p i ) Gini(D) = \sum_{i=1}^kp_i(1 - p_i) Gini(D)=i=1∑kpi(1−pi)
假设数据 D D D 被布尔特征 A A A 切分成 D 1 D_1 D1和 D 2 D_2 D2 两个子集,在特征 A A A 条件下 D D D 的基尼指数为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A) = \frac{|D_1|}{|D|}Gini(D_1) + \frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
其中,基尼指数越大,样本越纯。寻找最佳分裂时需要计算每个阈值对样本集进行分裂后的基尼指数,寻找最大的基尼指数对应分裂,这就是最佳分裂。
第二章 随机森林
2.1 随机森林概述
随机森林由Breiman等人提出,它由多棵决策树(CART)组成,这些决策树之间没有相互联系。一旦森林生成后,当有一个新的样本输入,森林中的每棵决策树分别进行以下判断,然后投票,得票最多的类为最终的分类结果。
2.2 模型组件
2.2.1 Bootstrap
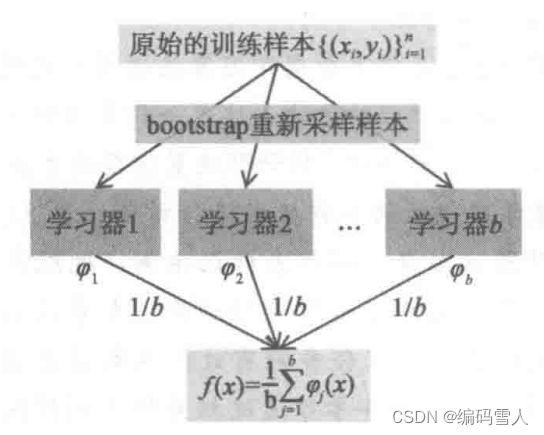
Bootstrap是一种数据抽样方法。抽样是指从一个样本数据集随机选择一些样本,形成新的数据集。这里有两个选择:有放回抽样和无放回抽样。对于前者,一个样本被抽中之后回放回去,在下次抽样时还有机会被抽中。对于后者,一个样本被抽中后就从样本集中除去,下次不参与抽样。Bootstrap使用的有放回抽样。
2.2.2 Bagging
集成学习是将多个弱学习算法通过一定的组合方式组合成一个强学习算法。目前有两类集成学习方法:Bagging和Boosting方法。
 |
 |
| 图a Bagging | 图b Boosting |
Bagging算法又称为袋装树,是一种并联数据集的集成算法。Bagging是对多个基学习器以相互独立的方式进行训练,在得出结果的时候,对于分类问题采用投票原则,选择最终的结果。
2.3 模型训练
随机森林在训练时依次训练每一棵决策树,每棵树的训练样本都是从原始训练集中采用Bootstrap抽样得到。在训练决策树的每个节点时所用的特征也是随机抽样得到的,即从特征向量中随机抽取部分特征参与训练。
正是因为有了这些随机性,随机森林才可以在一定程度上消除过拟合。如果不对样本、特征进行随机采样,每次都用完整的训练数据训练出来的多棵树是相同的。
训练每棵决策树时都有部分样本未参与训练。可以在训练时利用这些没有选中的样本做测试,统计它们的预测误差,这称为包外误差。利用包外误差作为泛化误差的估计。对于分类问题,包外误差被定义为被错分的包外样本与总包外样本数的比值。通过包外误差可以终止随机森林训练。
Algorithm 1 随机森林伪代码 1. For i=1:N 2. 利用Bootstrap自采样得到数据集 D i ; 3. 将 D i 放到根节点; 4. 随机选择部分特征; 5. 遍历上面筛选的特征,枚举阈值,计算不同特征和阈值下基尼指数; 6. 选择最大基尼指数对应的特征和阈值进行分裂; 7. 返回步骤2,直到满足终止条件; 8. End 9. 利用投票法选择类别 \begin{array}{ll} \hline \textbf{Algorithm 1 随机森林伪代码} \\ \hline 1. \enspace \text{For i=1:N}\\ 2. \enspace\enspace\enspace \text{利用Bootstrap自采样得到数据集} D_i ;\\ 3. \enspace\enspace\enspace\text{将} D_i \text{放到根节点};\\ 4. \enspace\enspace\enspace\text{随机选择部分特征};\\ 5. \enspace\enspace\enspace\text{遍历上面筛选的特征,枚举阈值,计算不同特征和阈值下基尼指数};\\ 6. \enspace\enspace\enspace\text{选择最大基尼指数对应的特征和阈值进行分裂};\\ 7. \enspace\enspace\enspace\text{返回步骤2,直到满足终止条件};\\ 8. \enspace \text{End}\\ 9. \enspace\text{利用投票法选择类别}\\ \hline \end{array} Algorithm 1 随机森林伪代码1.For i=1:N2.利用Bootstrap自采样得到数据集Di;3.将Di放到根节点;4.随机选择部分特征;5.遍历上面筛选的特征,枚举阈值,计算不同特征和阈值下基尼指数;6.选择最大基尼指数对应的特征和阈值进行分裂;7.返回步骤2,直到满足终止条件;8.End9.利用投票法选择类别
2.4 Sklearn随机森林模型参数
class sklearn.ensemble.RandomForestClassifier(
n_estimators=100, *,
criterion='gini',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='sqrt',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
max_samples=None,
monotonic_cst=None
)
2.4.1 随机森林参数说明
| 参数说明 | n_estimators:int, default=100 | 在森林中树的数目 |
| criterion:{“gini”, “entropy”, “log_loss”}, default=”gini” | 分支结点的划分标准,该参数是指定的 | |
| max_depth:int, default=None | 树的深度,如果为“None”,则节点将展开到所有叶子都是纯的,或者到所有叶子包含的样本少于 min_samples_split样本。 | |
| min_samples_split::int or float, default=2 | 拆分内部节点最小的样本数目 | |
| min_samples_leaf:int or float, default=1 | min_samples_leaf指定了在每个叶节点上所需的最小样本数。在构建随机森林时,每个决策树都会考虑min_samples_leaf参数。具体而言,当进行特征划分时,在任意深度上的分割点只有在左右分支中至少有min_samples_leaf个训练样本时才会被考虑。如果分割后的任一子节点中的样本数小于min_samples_leaf,则该分割不会发生,节点成为叶节点。在回归问题中,该参数有助于平滑模型。 | |
| min_weight_fraction_leaf:float, default=0.0 | min_weight_fraction_leaf指定在决策树构建过程中,叶子节点上允许的最小样本权重总和。样本权重是在训练数据中为每个样本指定的一个值,通常用于处理不平衡数据集或带有样本权重的问题。 | |
| max_features:{“sqrt”, “log2”, None}, int or float, default=”sqrt” | max_features用于控制每棵决策树的特征子集。它可以是字符串值 "sqrt"、"log2" 或 None,也可以是整数或浮点数,默认值为 "sqrt"。当 max_features 设定为 "sqrt" 时,每棵决策树的特征子集的大小将被设置为总特征数的平方根。当 max_features 设定为 "log2" 时,每棵决策树的特征子集的大小将被设置为总特征数的以 2 为底的对数。当 max_features 设定为 None 时,每棵决策树将使用所有特征进行训练。当max_features 是一个整数值,指定每棵决策树的特征子集的固定大小。 | |
| max_leaf_nodes:int, default=None | max_leaf_nodes用于控制决策树最大叶节点数量。它是一个整数,默认值为None。 | |
| min_impurity_decrease:float, default=0.0 | min_impurity_decrease控制决策树节点分裂的最小不纯度减少量。它是一个浮点数,默认值为0.0。决策树在每个节点处根据某个准则(如基尼不纯度或熵)进行特征选择和分裂。min_impurity_decrease定义了节点分裂所需的最小不纯度减少量。如果分裂后的不纯度减少量小于该阈值,则节点将被视为叶节点,不再进行分裂。 | |
| bootstrap:bool, default=True | 该参数保持默认 | |
| oob_score:bool or callable, default=False | oob_score控制是否使用袋外样本Out-of-Bag samples)来估计泛化得分的参数。默认为False。只有当bootstrap=True时,oob_score参数才可用。袋外样本是在随机森林训练过程中未被用于构建某个特定决策树的样本。由于每个决策树都是基于自助采样(bootstrap)得到的训练集构建的,因此每个决策树都有一部分样本未被使用。这些未被使用的样本可以被用来评估模型的泛化性能,而无需进行交叉验证或独立的验证集。 | |
| n_jobs:int, default=None | n_jobs控制并行计算。它是一个整数,默认值为None。 | |
| random_state:int or None, default=None | random_state控制bootstrapping采样的随机性,控制特征采样的随机性。 | |
| verbose:int, default=0 | verbose用于调整算法在训练过程中生成的输出信息。如果verbose为0,算法将不生成任何输出信息。如果verbose为1,算法会在训练过程中输出进度条,显示每个决策树的训练进度。如果verbose大于1,算法会输出更详细的信息,包括每个决策树的训练进度和其他相关信息。 |
第三章 工程实践
3.1 数据收集
3.1.1 数据集介绍
PhiUSIIL Phishing URL数据集是一个庞大的数据集,其中包含了134850合法网站和100945钓鱼网站。在构建数据集时,我们分析的大多数URL都是最新的URL。该数据集的特征都是从网页源码和URL中提取的。像CharContinuationRate, URLTitleMatchScore, URLCharProb和TLDLegitimateProb特征是从已有特征派生出来的特征。
3.1.2 数据集的下载地址
https://archive.ics.uci.edu/static/public/967/phiusiil+phishing+url+dataset.zip
3.1.3 加载数据
# 准备数据
try:
# 读取pkl文件
path = r"../../数据文件/PhiUSIILPhishingURL/PhiUSIIL_Phishing_URL_Dataset.pkl"
data = pd.read_pickle(path)
except FileNotFoundError:
# 读取csv文件并保存为pkl文件
path = r"../../数据文件/PhiUSIILPhishingURL/PhiUSIIL_Phishing_URL_Dataset.csv"
data = pd.read_csv(path)
data.to_pickle("../../数据文件/PhiUSIILPhishingURL/PhiUSIIL_Phishing_URL_Dataset.pkl", protocol=4)
【代码分析】
在大数据场景下,使用pd.read_excel()函数每次读取数据文件的速度会很慢。为了缓解该问题,可以采取以下步骤:
1)首先,使用pd.read_excel()函数将数据文件读取为一个DataFrame对象。这个函数是pandas库提供的用于读取Excel文件的函数,它会将Excel文件的内容加载到内存中,并创建一个DataFrame对象来表示数据。
2)接下来,可以使用dataframe.to_pickle(path, compression=‘infer’, protocol=5)函数将DataFrame对象保存为一个pkl文件。to_pickle()函数是pandas库提供的用于将对象序列化为pickle文件的函数。通过将DataFrame保存为pkl文件,可以以二进制格式将数据持久化到磁盘上,并在需要时快速加载。
| 参数说明 | path:保存 pickle 文件的路径(包括文件名和扩展名)。 |
| compression:可选参数,指定压缩格式。默认值为 'infer',表示自动推断压缩格式。其他可选值包括 'gzip'、'bz2'、'zip'、'xz',或者可以是一个压缩文件扩展名。 | |
| protocol:可选参数,指定 pickle 协议的版本。默认值为 5,表示使用最高版本的 pickle 协议。 |
3.2 数据探索
3.2.1 数据概述
步骤一: 通过查看数据的前几行,可以了解数据集中的特征以及它们的值是什么样的。这有助于我们对数据结构有一个直观的认识。
data = data.loc[:, "URL":"label"]
print(data.head(5))
运行结果如下:
URL URLLength ... NoOfExternalRef label
0 https://www.southbankmosaics.com 31 ... 124 1
1 https://www.uni-mainz.de 23 ... 217 1
2 https://www.voicefmradio.co.uk 29 ... 5 1
3 https://www.sfnmjournal.com 26 ... 31 1
4 https://www.rewildingargentina.org 33 ... 85 1

观察结果:通过运行结果可以发现,在数据集特征中含有类别特征。
步骤二: 查看数据集中的特征类型、缺失值等信息,有助于进一步了解数据的特征,并为后续的数据处理和分析做准备。
print(data.info())
运行结果如下:
RangeIndex: 235795 entries, 0 to 235794
Data columns (total 55 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 URL 235795 non-null object
1 URLLength 235795 non-null int64
2 Domain 235795 non-null object
3 DomainLength 235795 non-null int64
4 IsDomainIP 235795 non-null int64
5 TLD 235795 non-null object
6 URLSimilarityIndex 235795 non-null float64
7 CharContinuationRate 235795 non-null float64
8 TLDLegitimateProb 235795 non-null float64
9 URLCharProb 235795 non-null float64
10 TLDLength 235795 non-null int64
11 NoOfSubDomain 235795 non-null int64
12 HasObfuscation 235795 non-null int64
13 NoOfObfuscatedChar 235795 non-null int64
14 ObfuscationRatio 235795 non-null float64
15 NoOfLettersInURL 235795 non-null int64
16 LetterRatioInURL 235795 non-null float64
17 NoOfDegitsInURL 235795 non-null int64
18 DegitRatioInURL 235795 non-null float64
19 NoOfEqualsInURL 235795 non-null int64
20 NoOfQMarkInURL 235795 non-null int64
21 NoOfAmpersandInURL 235795 non-null int64
22 NoOfOtherSpecialCharsInURL 235795 non-null int64
23 SpacialCharRatioInURL 235795 non-null float64
24 IsHTTPS 235795 non-null int64
25 LineOfCode 235795 non-null int64
26 LargestLineLength 235795 non-null int64
27 HasTitle 235795 non-null int64
28 Title 235795 non-null object
29 DomainTitleMatchScore 235795 non-null float64
30 URLTitleMatchScore 235795 non-null float64
31 HasFavicon 235795 non-null int64
32 Robots 235795 non-null int64
33 IsResponsive 235795 non-null int64
34 NoOfURLRedirect 235795 non-null int64
35 NoOfSelfRedirect 235795 non-null int64
36 HasDescription 235795 non-null int64
37 NoOfPopup 235795 non-null int64
38 NoOfiFrame 235795 non-null int64
39 HasExternalFormSubmit 235795 non-null int64
40 HasSocialNet 235795 non-null int64
41 HasSubmitButton 235795 non-null int64
42 HasHiddenFields 235795 non-null int64
43 HasPasswordField 235795 non-null int64
44 Bank 235795 non-null int64
45 Pay 235795 non-null int64
46 Crypto 235795 non-null int64
47 HasCopyrightInfo 235795 non-null int64
48 NoOfImage 235795 non-null int64
49 NoOfCSS 235795 non-null int64
50 NoOfJS 235795 non-null int64
51 NoOfSelfRef 235795 non-null int64
52 NoOfEmptyRef 235795 non-null int64
53 NoOfExternalRef 235795 non-null int64
54 label 235795 non-null int64
dtypes: float64(10), int64(41), object(4)
memory usage: 98.9+ MB
None
观察结果: 通过运行结果可以发现,该数据集含有235795条数据,每个数据有54个特征。其中,实数类型特征有10个,整数类型特征有41个,类别型特征有4个分别为:URL、Domain、TLD和Title。
步骤三: 计算数据集中每个变量的描述性统计信息,如均值、中位数、标准差、最小值和最大值等。这些统计量可以提供关于数据的集中趋势、分散程度和数据分布等方面的信息。
print(data.describe())
运行结果:
URLLength DomainLength ... NoOfExternalRef label
count 235795.000000 235795.000000 ... 235795.000000 235795.000000
mean 34.573095 21.470396 ... 49.262516 0.571895
std 41.314153 9.150793 ... 161.027430 0.494805
min 13.000000 4.000000 ... 0.000000 0.000000
25% 23.000000 16.000000 ... 1.000000 0.000000
50% 27.000000 20.000000 ... 10.000000 1.000000
75% 34.000000 24.000000 ... 57.000000 1.000000
max 6097.000000 110.000000 ... 27516.000000 1.000000
分析结果: 例如,URLLength特征的最小值为34.573095,最大值为6097,数据标准差为41.314153,则该特征可能存在异常值,其他特征分析方法类似。
**步骤四:**查看类别数目,判断数据集是否属于不均衡数据集。
print(len(data.loc[data['label'] == 1]))
print(len(data.loc[data['label'] == 0]))
运行结果如下:
134850
100945
分析结果: 该数据集属于均衡数据集。
3.3 特征工程
3.3.1 整数编码
步骤一:选择特征数据并查看数据类型;
data = data.loc[:, "URL":"label"]
print(data.dtypes)
步骤二:选择分类特征(object)
cols = list(data.dtypes[data.dtypes == object].index) # 筛选类别特征
步骤三:对分类特征进行整数编码,注意对于缺失值,pd.Categorical()函数会编码为-1,LabelEncoder对象会编码为最大整数并且在大数据场景下拉低程序速度,因此在使用pd.Categorical()之前,应对缺失值进行处理。
for c in cols:
data[c] = pd.Categorical(data[c]).codes # 对类别特征进行编码
3.4 数据准备
3.4.1 数据集划分
在数据准备阶段,需要根据数据的大小或模型的复杂程度将数据集划分为训练集和测试集或训练集、验证集和测试集。
- 模型训练:将训练集输入到选定的算法中进行运算以获取算法最佳超参数,即得到模型。
(1)选定算法,比如分类算法,回归算法或者聚类算法;
(2)在训练集上训练模型,获取临时模型和训练集预测结果;
(3)在验证集上运行临时模型,获得验证集预测结果;
(4)参考训练集或验证集预测结果,改进模型;
(5)反复迭代 2)-4)步,直至满足停止条件。 - 模型测试: 将测试集输入模型中,得到预测结果,然后将预测结果与预期结果按模型质量评价指标进行比较,最后根据指标结果来衡量当前模型的质量。
注意:
一般而言,这三种数据集均是从同一份标注数据中随机选取的。三者的比例是训练集:验证集:测试集=8:1:1,也可以是训练集:验证集:测试集:7:1:2。如果数据量不大,模型相对简单时,可划分为训练集:测试集=8:2或者训练集:测试集=7:3。
train_data, test_data = train_test_split(data, train_size=0.7, random_state=200, shuffle=True)
3.5 模型训练
步骤一:建立分类模型;
rf = RandomForestClassifier(criterion='gini', verbose=2) # 创建模型
步骤二:利用随机搜索算法寻找最佳参数并保存最佳模型。
params = {
'n_estimators': list(range(10, 100)),
'max_features': list(range(0, train_data.shape[1] + 1))
}
rsv = RandomizedSearchCV(rf, param_distributions=params, cv=5) # 模型调参
rsv.fit(train_data.loc[:, "URL":"NoOfExternalRef"], train_data["label"])
opt_model = rsv.best_estimator_ # 最优模型
joblib.dump(opt_model, "ppu_model.joblib")
3.6 模型评估
步骤一:加载已经训练好的模型;
opt_model = joblib.load("./ppu_model.joblib")
步骤二:对新数据进行预测;
y_hat = opt_model.predict(test_data.loc[:, "URL":"NoOfExternalRef"])
步骤三:选择评价指标对模型进行评价。
score = f1_score(test_data["label"], y_hat)
print(score)
运行结果如下:
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 91 out of 91 | elapsed: 0.1s finished
F1分数为:1.0
3.7 模型分析
在模型训练和评价完成后,我们通常希望通过与其他模型进行比较来选择最优和最简单的模型作为基础模型。这个过程可以通过以下步骤来实现:
- 多模型比较:通过将已训练的模型与其他备选模型进行比较,可以评估它们在同一任务上的性能差异。这可以涉及使用相同的评价指标来比较模型在验证集或交叉验证上的性能。
- 评价函数的选择:在选择评价函数时,我们需要考虑不同评价函数的优点和缺点。每个评价函数都有其特定的关注点和应用场景。常见的评价函数包括准确率、精确率、召回率、F1分数、AUC-ROC曲线下面积等。根据任务需求,选择适当的评价函数来评估模型的性能。
- 多指标评估:由于每个评价函数都有其局限性,使用多个评价函数可以提供更全面的模型评估。通过综合多个评价指标的结果,我们可以得到更全面的模型性能分析。这可以帮助我们更好地理解模型在不同方面的表现。
综合考虑:在选择最优和最简单的模型时,我们需要综合考虑多个因素,包括模型性能、复杂度、解释性、计算效率和实际应用需求。最终选择的模型应该是在多个评价函数下表现较好,同时具有适当的复杂度和计算效率,并满足实际应用需求。
参考文献
[1] 安德烈 ⋅ \cdot ⋅布克夫. 机器学习精讲[M]. 北京: 人民邮电出版社, 2020:105-108.