DeepSeek大模型技术架构全解析:从底层原理到顶层设计
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
文章目录
- DeepSeek大模型技术系列二
-
- DeepSeek大模型技术系列二》DeepSeek大模型技术架构全解析:从底层原理到顶层设计
-
- 更多技术内容
- 总结
DeepSeek大模型技术系列二
DeepSeek大模型技术系列二》DeepSeek大模型技术架构全解析:从底层原理到顶层设计
DeepSeek-V3 的基本架构,其特点是采用多头潜在注意力(MLA)(DeepSeek-AI, 2024c)实现高效推理,采用 DeepSeekMoE(Dai 等人,2024)进行经济高效的训练。然后,我们提出多 token 预测(MTP)训练目标,我们发现这可以提高模型在评估基准上的整体性能。对于未明确提及的其他细节,DeepSeek-V3 遵循 DeepSeek-V2(DeepSeek-AI, 2024c)的设置。
2.1 基本架构
DeepSeek-V3 的基本架构仍基于 Transformer(Vaswani 等人,2017)框架。为实现高效推理和经济高效的训练,DeepSeek-V3 还采用了经 DeepSeek-V2 充分验证的 MLA 和 DeepSeekMoE。与 DeepSeek-V2 不同的是,我们为 DeepSeekMoE 引入了无辅助损失的负载均衡策略(Wang 等人,2024a),以减轻为确保负载均衡而对模型性能造成的影响。图 2 展示了 DeepSeek-V3 的基本架构,我们将在本节简要回顾 MLA 和 DeepSeekMoE 的细节。
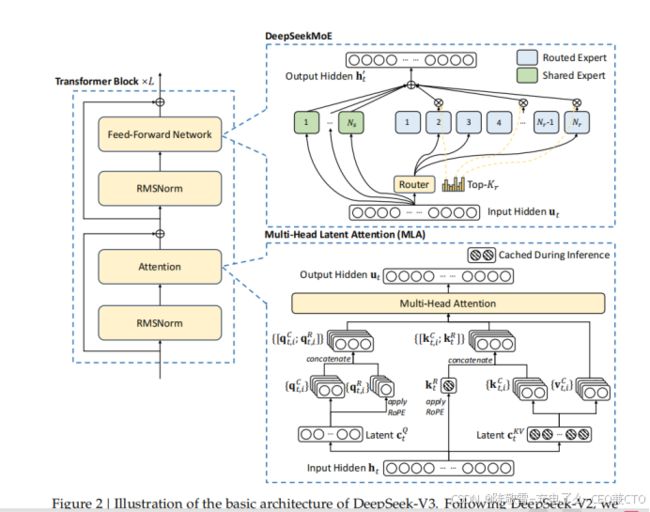
图 2 DeepSeek-V3 基本架构示意图。遵循 DeepSeek-V2,我们采用 MLA 和 DeepSeekMoE 实现高效推理和经济高效的训练
2.1.1 多头潜在注意力
对于注意力机制,DeepSeek-V3 采用 MLA 架构。设表示嵌入维度,表示注意力头数,表示每个头的维度,表示给定注意力层中第个 token 的注意力输入。MLA 的核心是对注意力键值进行低秩联合压缩,以减少推理时的键值(KV)缓存:
其中是键值的压缩潜在向量;表示 KV 压缩维度;表示下投影矩阵;、分别是键值的上投影矩阵;是用于生成携带旋转位置嵌入(RoPE)(Su 等人,2024)的解耦键的矩阵;RoPE 表示应用 RoPE 矩阵的操作;表示拼接。需要注意的是,对于 MLA,在生成过程中仅需缓存蓝色框中的向量(即和),这显著减少了 KV 缓存,同时保持与标准多头注意力(MHA)(Vaswani 等人,2017)相当的性能。
对于注意力查询,我们也进行低秩压缩,这可以减少训练期间的激活内存:
其中是查询的压缩潜在向量;表示查询压缩维度;、$W^{U Q
、分别是查询的下投影和上投影矩阵;是用于生成携带 RoPE 的解耦查询的矩阵。
最终,注意力查询()、键()和值()相结合,产生最终的注意力输出:
其中表示输出投影矩阵。
2.1.2 采用无辅助损失负载均衡的 DeepSeekMoE
DeepSeekMoE 基本架构:对于前馈网络(FFNs),DeepSeek-V3 采用 DeepSeekMoE 架构(Dai 等人,2024)。与传统的 MoE 架构(如 GShard(Lepikhin 等人,2021))相比,DeepSeekMoE 使用更细粒度的专家,并将部分专家设置为共享专家。设表示第个 token 的 FFN 输入,我们按如下方式计算 FFN 输出:
否则
其中和分别表示共享专家和路由专家的数量;和分别表示第个共享专家和第个路由专家;表示激活的路由专家数量;是第个专家的门控值;是 token 与专家的亲和度;是第个路由专家的质心向量;表示在为第个 token 和所有路由专家计算的亲和度分数中,包含个最高分数的集合。与 DeepSeek-V2 略有不同,DeepSeek-V3 使用 sigmoid 函数计算亲和度分数,并对所有选定的亲和度分数进行归一化以生成门控值。
无辅助损失负载均衡:对于 MoE 模型,专家负载不均衡会导致路由崩溃(Shazeer 等人,2017),并在专家并行的场景中降低计算效率。传统解决方案通常依赖辅助损失(Fedus 等人,2021;Lepikhin 等人,2021)来避免负载不均衡。然而,过大的辅助损失会损害模型性能(Wang 等人,2024a)。为了在负载均衡和模型性能之间实现更好的平衡,我们首创了无辅助损失的负载均衡策略(Wang 等人,2024a)来确保负载均衡。具体来说,我们为每个专家引入一个偏差项,并将其添加到相应的亲和度分数中,以确定前路由:
否则
注意,偏差项仅用于路由。与 FFN 输出相乘的门控值仍由原始亲和度分数导出。在训练过程中,我们持续监控每个训练步骤中整个批次的专家负载。在每个步骤结束时,如果相应专家负载过高,我们将偏差项减小;如果负载过低,则将其增大,其中是一个称为偏差更新速度的超参数。通过动态调整,DeepSeek-V3 在训练过程中保持专家负载平衡,并且比仅通过辅助损失鼓励负载均衡的模型表现更好。
互补的序列级辅助损失:虽然 DeepSeek-V3 主要依靠无辅助损失策略来实现负载平衡,但为了防止单个序列内出现极端不平衡,我们还采用了互补的序列级平衡损失:
其中平衡因子是一个超参数,对于 DeepSeek-V3,其取值极小;表示指示函数;表示序列中的 token 数量。序列级平衡损失鼓励每个序列上的专家负载保持平衡。
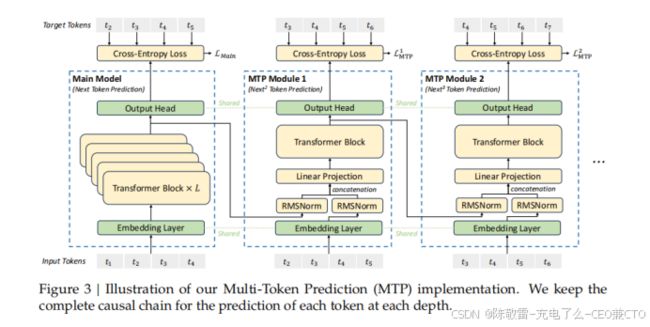
图 3 多 token 预测(MTP)实现示意图。我们在每个深度保持每个 token 预测的完整因果链
节点限制路由:与 DeepSeek-V2 使用的设备限制路由类似,DeepSeek-V3 也采用受限路由机制来限制训练期间的通信成本。简而言之,我们确保每个 token 最多被发送到个节点,这些节点根据分布在每个节点上的专家的最高个亲和度分数之和来选择。在这种约束下,我们的 MoE 训练框架几乎可以实现完全的计算 - 通信重叠。
无 token 丢弃:由于有效的负载均衡策略,DeepSeek-V3 在整个训练过程中保持良好的负载平衡。因此,DeepSeek-V3 在训练过程中不会丢弃任何 token。此外,我们还实施了特定的部署策略来确保推理负载平衡,所以 DeepSeek-V3 在推理过程中也不会丢弃 token。
2.2 多 token 预测
受 Gloeckle 等人(2024)的启发,我们为 DeepSeek-V3 研究并设置了多 token 预测(MTP)目标,将预测范围扩展到每个位置的多个未来 token。一方面,MTP 目标使训练信号更密集,可能提高数据效率。另一方面,MTP 可能使模型能够预先规划其表示,以便更好地预测未来 token。图 3 展示了我们的 MTP 实现。与 Gloeckle 等人(2024)使用独立输出头并行预测个额外 token 不同,我们顺序预测额外 token,并在每个预测深度保持完整的因果链。我们在本节介绍 MTP 实现的详细信息。
MTP 模块:具体来说,我们的 MTP 实现使用个顺序模块来预测个额外 token。第个 MTP 模块由一个共享嵌入层、一个共享输出头、一个 Transformer 块和一个投影矩阵组成。对于第个输入 token ,在第个预测深度,我们首先将第深度的第个 token 的表示与第个 token 的嵌入通过线性投影组合:
其中表示拼接。特别地,当时,指的是主模型给出的表示。需要注意的是,每个 MTP 模块的嵌入层与主模型共享。组合后的作为第深度的 Transformer 块的输入,以产生当前深度的输出表示:
其中表示输入序列长度,表示切片操作(包括左右边界)。最后,以为输入,共享输出头将计算第个额外预测 token 的概率分布,其中是词汇表大小:
输出头将表示线性映射到 logits,然后应用 Softmax 函数计算第个额外 token 的预测概率。此外,每个 MTP 模块的输出头也与主模型共享。我们保持预测因果链的原则与 EAGLE(Li 等人,2024b)类似,但 EAGLE 的主要目标是推测解码(Leviathan 等人,2023;Xia 等人,2023),而我们利用 MTP 来改进训练。
MTP 训练目标:对于每个预测深度,我们计算交叉熵损失:
其中表示输入序列长度,表示第个位置的真实 token,表示由第个 MTP 模块给出的的相应预测概率。最后,我们计算所有深度的 MTP 损失的平均值,并乘以加权因子,得到整体的 MTP 损失,作为 DeepSeek-V3 的额外训练目标:
MTP 在推理中的应用:我们的 MTP 策略主要旨在提高主模型的性能,因此在推理时,我们可以直接丢弃 MTP 模块,主模型可以独立正常运行。此外,我们还可以将这些 MTP 模块用于推测解码,以进一步提高生成速度。
更多技术内容
更多技术内容可参见
《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】书籍。
更多的技术交流和探讨也欢迎加我个人微信chenjinglei66。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:本书从自然语言处理基础开始,逐步深入各种NLP热点前沿技术,使用了Java和Python两门语言精心编排了大量代码实例,契合公司实际工作场景技能,侧重实战。
全书共分为19章,详细讲解中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注、文本相似度算法、语义相似度计算、词频-逆文档频率(TF-IDF)、条件随机场、新词发现与短语提取、搜索引擎Solr Cloud和Elasticsearch、Word2vec词向量模型、文本分类、文本聚类、关键词提取和文本摘要、自然语言模型(Language Model)、分布式深度学习实战等内容,同时配套完整实战项目,例如对话机器人实战、搜索引擎项目实战、推荐算法系统实战。
本书理论联系实践,深入浅出,知识点全面,通过阅读本书,读者不仅可以理解自然语言处理的知识,还能通过实战项目案例更好地将理论融入实际工作中。
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目。
【配套视频】
推荐系统/智能问答/人脸识别实战 视频教程【陈敬雷】
视频特色:把目前互联网热门、前沿的项目实战汇聚一堂,通过真实的项目实战课程,让你快速成为算法总监、架构师、技术负责人!包含了推荐系统、智能问答、人脸识别等前沿的精品课程,下面分别介绍各个实战项目:
1、推荐算法系统实战
听完此课,可以实现一个完整的推荐系统!下面我们就从推荐系统的整体架构以及各个子系统的实现给大家深度解密来自一线大型互联网公司重量级的实战产品项目!
2、智能问答/对话机器人实战
由浅入深的给大家详细讲解对话机器人项目的原理以及代码实现、并在公司服务器上演示如何实际操作和部署的全过程!
3、人脸识别实战
从人脸识别原理、人脸识别应用场景、人脸检测与对齐、人脸识别比对、人脸年龄识别、人脸性别识别几个方向,从理论到源码实战、再到服务器操作给大家深度讲解!
自然语言处理NLP原理与实战 视频教程【陈敬雷】
视频特色:《自然语言处理NLP原理与实战》包含了互联网公司前沿的热门算法的核心原理,以及源码级别的应用操作实战,直接讲解自然语言处理的核心精髓部分,自然语言处理从业者或者转行自然语言处理者必听视频!
人工智能《分布式机器学习实战》 视频教程【陈敬雷】
视频特色:视频核心内容有互联网公司大数据和人工智能、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)。
上一篇:DeepSeek大模型技术系列一》DeepSeek核心算法解析:如何打造比肩ChatGPT的国产大模型
下一篇:DeepSeek大模型技术系列三》DeepSeek大模型基础设施全解析:支撑万亿参数模型的幕后英雄