代码整洁之道读书笔记
引
写出可读的代码,重要程度不亚于写出可执行的代码
本书的逻辑模块:原则、模式、实践和启示。串联整个模块的是阅读和思考代码
此外,尽信书则不如无书,书中的东西固然有可取之处,但是有些东西也是针对当时的开发环境所提出的,那个时候和现在的并不完全一样,所以并不是说完全就要把作者提出的所有东西都奉为圭臬。
有些东西与Unity和C#关联性不强,如第15章整章内容“JUnit内幕”,或者11.5小节内容“纯Java AOP框架”就未在本笔记提及。
命名
这块其实和程序文档里要求的大致方向是相同的,总体来说就是为了能让他人看到代码之后能尽快准确理解某个东西的用途,避免揣摩,揣摩意味着浪费时间精力甚至因理解错误产生误用
- 把作用放在命名中,而非注释中(相应地,避免使用
a1这种无意义的) - 避免直接使用字面常量(使用
#define或者枚举值替代,为字面值赋予意义,如StatusEnum.Start) - 避免出现命名含有误导性质,如xxList可能和已有的数据结构List相混淆,特别是
xxList未必是数据结构的List,或者混淆0与o,I与l - 避免出现命名过于相似的名称,特别是没有明确约定的情况下,例如
accountInfo和accountData - 对4的补充:没有明确约定不要自造词,而是使用更容易读懂的
- 避免冗余:例如
nameString并不会比name好 - 名称应便于搜索,名称的长短应当与其作用域大小相对应
- 匈牙利语标记法和成员前缀
m_应当退出历史舞台,因为强类型语言和编辑器高亮的存在 - 接口不要I开头?(这个不太理解)
- 避免思维映射:在命名时不要让读者把编写者脑袋里的名称翻译成他们所熟知的另一个名称
- 类名应当是名词(eg.
AddressParser) - 方法名应当是动词短语(eg.
savePage,或加上get、set、is) - 每个概念对应一个词,例如不应同时使用
fetch、retrieve和get,类似地还有controller和manager - 禁止双关
- 使用专业领域、专业名词命名
- 添加有意义的语境,例如
state=>addrState,更好的做法是建一个Address类,但是只要短名称足够清楚则无需画蛇添足
函数
这一章围绕函数来说明代码的结构,贯穿始终的思想是抽象。相当于是在讲“抽象时机”、“抽象位置”和“抽象程度”的问题。也就是如何规划函数,设计完成一个功能要哪些函数,以及每个函数的意义。
代码是自底向上编写的,但是函数设计上完全可以自顶向下,捋顺一个函数的逻辑,一个函数要经过哪些步骤,这其中的每一个步骤都可以考虑是否需要抽象出来(以及抽象出几层)。代码抽象的最明面上的意义就是让“过程”具有可读性。
就原则上来讲:
- 对于一些较为晦涩的名值绑定完全可以抽象提出,把作用体现在函数名称上
- 函数要短小
- if/else/while代码块内语句一行为宜,函数的缩进等级(指嵌套)<2为宜
- 单一职责原则:一个函数做一件事
- 开放闭合原则
- 一个函数位于一个抽象层级
- 使用异常替代返回错误码(并且抽离
try-catch块,把内容形成新函数,不要让错误处理和正常流程混在一块) - 尽量避免使用goto
- DRY原则:Don’t Repeat Yourself
一开始写出来的东西总不可能完全符合规则,不断打磨修改是正常的
抽象层级问题
目的:能够自顶向下阅读代码
方式:不混用抽象层级,每个函数应位于一个抽象层级
抽象层级判定方法:"TO do something, we need …"句子。即“为了完成{函数的目标},我们需要进行{事件1}、{事件2}和{事件3}(甚至还可以添加条件:并且当这三件事情的结果是{某种结果}的时候需要做{事件4})”,通过这种自顶向下的捋顺之后,一个函数就可能长这样:
void func(){
var result1 = thing1();
var result2 = thing2();
var result3 = thing3();
if(result1 == true && ...){
thing4();
}
}
思想就是要完成一个大目标,考虑要分解成多少个子操作,然后对每个子操作也如法炮制,分解成更小的子操作
关于Switch
据说用在抽象工厂是勉强可以接收的,其它情况或多或少无法避免违反单一职责原则和开放闭合原则
关于参数
如果一个函数需要多个参数,其中某些则有可能封装成类的必要
越少越好,理想是0参数。参数与函数名处在不同的抽象层级,他要求你了解目前不特别重要的细节,此外多个参数也不便测试
bool参数
书上意思是传入的flag为true则做一件事,为false则做另一件事(违反了单一职责原则)
错误:Render(bool isSuite)
正确:RenderForSuite()+ RenderForSingleTest()
尽量避免输出参数
作者意思是尽量避免return东西,还得中断思考检测函数签名(虽然我觉得这并不费力)
string a = insert(a, index, content); // 不好
a.insert(index, content); // 好
无副作用
这不就是纯函数?
无副作用意味着只做承诺的那一件事,既不会额外改变其它未约定的东西,也不应该有任何先决条件(避免时序性耦合)
“必须先调用一个才能调用另一个”这种必须按照特定顺序调用的耦合关系叫做时序耦合。
不要把指令和询问同时出现
if(attributeExists("userName")){ // 这是询问
setAttribute("userName", "value"); // 这是指令(没有同时出现)
}
这也说明了为什么要使用异常替代返回错误码,因为一种典型的写法没把他俩分开
if(deletePage(page) == E_OK){
// do something
}
异常处理
抽离try-catch块,把内容形成新函数,不要让错误处理和正常流程混在一块。
错误码会在多处引用,形成“依赖磁铁”
- 注释并不能美化糟糕的代码(但是还是该用注释就用
- 无论何时,注释的正确性永远是他存在的基础,不正确的注释还不如不写
注释
对代码进行修改的时候不意味着配套的所有注释都一道更新,或者注释和他指向的代码分隔开了,也就是说存在“注释和描述的代码不一致”的可能性。所以对待注释要持怀疑态度:注释可能会撒谎
优质注释
- 版权信息
- 提供信息(如指出返回值表示什么东西)
- 解释意图(指向的操作要干什么事情)
- 阐释(对不好读懂的代码翻译为可读的)
- 警示(例如告知他人什么时候可以或者不可以调用)
- TODO(当然完成了要及时删除)
- 放大(对于某些不易注意到的东西方法其显著性)
- javadoc(C#有类似的XML注释,就是三个
/开头那个东西)
糟糕的注释
- 自言自语的注释
- 多余的注释(去掉之后还是能理解,例如给构造函数注释“构造函数”,或者给
GetCurMonth注释“返回当前月份”这样的 - 迫使读者读其它模块的注释
- 误导性注释
- 日志式注释(详细记录每一次更改)毕竟现在的git已经可以查历史了,完全没必要
- 署名(git也可以查到谁写的,不需要署名)
- 注释掉的代码(同理,git也能查到)
- 位置标记(类似于
///的这种为了引人注目的东西) - 大块的、信息量过多的注释(大块引用不如放外部链接)
- 需要解释的注释
- 不能和所指代码的那部分直接对应上(或者容易错误对应上)的注释
格式
谈及格式,团队内部的格式总是最应当优先遵守的,其次才是这种书中提到的。
- 函数定义之间空行,空白行会隔开不同概念的代码块,那么相似的应该放在一块。对于变量的定义,每个定义间全然没有必要隔开
void f1(){
// something
}
void f2(){
// something
}
- 变量声明放在函数头部
- 一行代码最好不要超120字符,尽量做到无需拖动滚动条
相关性(垂直)
概念相关的代码应当放在一起,相关性越强,彼此之间的距离就应该越短(我认为在C#可以使用
#region辅助)
相关的函数放一块:如果某个函数调用了另一个,这俩最好放一起,且被调用的在下面
相关性(水平)
使用空格把相关性较弱的东西隔开,如赋值操作符左右两侧
所幸已经有代码美化插件可以自动完成这些事情,但是作者声称多数代码格式化工具会模糊运算符优先级。例如(-b - Math.sqrt(c)) / (2*a),其中乘法没分隔而除法分隔了,因为(2*a)是一个有意义的整体。
作者还声称一个类头部有一堆东西要声明时说明类该拆分了(好吧,其实对于Unity程序员这并不是一个特别值得关心的事情)
其他
- 不要在短小的语句违反缩进规则
if(xxx)f(); //❌if这种最好还是不要写在一行
while(xxx)
; // 无函数体的while最好分号放次行,不过显然Unity有更优雅的解决方案
- 遵循团队共同的约定规则
对象与数据结构
数据抽象
抽象的意义在于隐藏底层数据细节(使用者无需了解数据实现就能操作数据本体)
// 具象点
public class Point{
public double x;
public double y;
}
// 抽象点
public interface Point{
double getX();
double getY();
void setCartesian(double x, double y);
double getR();
double getTheta();
void setPolar(double r, double theta);
}
反对称性
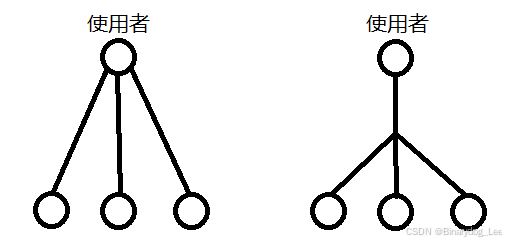
我觉得其实就是在讲上图这件事:面向过程(左图)面向对象(右图)
- 链接到使用者的某根线:使用者对数据结构进行的某种“使用”操作
- 底下的圆:某种数据结构
- 每有一根线连到使用者,就意味着多出一段与之对应的代码逻辑
然后现在要添加新类,对于左图,必须扯一根新线连到使用者(因为使用者去控制操作数据结构的这个过程)对于右图,使用者只需要知道调用数据结构的某个函数就行(数据结构自备了某种功能的实现)
显然:过程式代码难以添加新数据结构(特别是与某些调用的地方有耦合),面向对象容易添加新数据结构。但是对于添加新函数来说,面向对象就比面向过程要繁琐了(需要修改每一个类)
拓展:VISOTOR模式与双向分派
数据传送对象
数据传输对象(DTO,Data Transfer Object)是一种只有数据字段没有业务逻辑的数据类,用于在不同的系统组件或模块之间传递数据。允许开发者将数据以一种简单且可序列化的方式传递,而不必暴露整个数据模型或复杂的业务逻辑。
这也就是上文说的“如果一个函数需要多个参数,其中某些则有可能封装成类的必要”
总结
对象暴露行为而隐藏数据。
错误处理
原则
- 使用异常而非返回码或者错误标识(后者要求调用者调用之后立即检查错误,但是这个步骤易被忽略)
- 先写Try-Catch-Finally语句(好叭,Unity工程代码好像
LogError更多),而且Try语句块范围不要太大,并且异常应当携带充分的错误信息 - 特例模式
特例模式
特例模式(Special Case Pattern)是一种用于处理特殊情况或异常情况设计模式,将异常封装到特例对象中,异常不会在正常的流程中直接处理,而是将控制权转交给特例类来处理,而且对于异常的处理逻辑更为集中
public interface OrderStatus
{
void Handle();
}
public class NormalOrder : OrderStatus
{
public void Handle()
{
// 正常订单的处理逻辑
}
}
public class CancelledOrder : OrderStatus
{
public void Handle()
{
// 取消订单的处理逻辑
}
}
public class CompletedOrder : OrderStatus
{
public void Handle()
{
// 订单已完成的处理逻辑
}
}
public class OrderProcessor
{
public void ProcessOrder(OrderStatus status)
{
status.Handle();
}
}
// 在使用时
OrderProcessor processor = new OrderProcessor();
processor.ProcessOrder(new NormalOrder());
processor.ProcessOrder(new CancelledOrder());
processor.ProcessOrder(new CompletedOrder());
上述代码所示,本身正常流程是处理常规的订单,但是订单如果已完成或者被取消是特殊情况(不应被处理),此时就会在异常类内部得到处理。
- 别返回
null。因为一旦忘记检查容易出问题,所以不如不返回。当然,更不应该传递null值。(但是C#有可空类型奥,这个见仁见智了)
类
就变量声明顺序而言,从上到下:
- 公共静态常量
- 私有静态变量
- 私有实体变量
类的设计准则:短小。类名应当描述其权责,就权责而言,如果无法为某个类命以精确的名称,这个类大概就太长了。
避免不恰当的权责聚集情况存在
就类和模块的设计而言:
- 单一权责原则(SRP):类或模块应有且只有一条加以修改的理由(即它的权责,它所负责的功能)
- 内聚:如果一个类中的每个变量都被每个方法所使用,则该类具有最大的内聚性。内聚性肯定无法达到极高,但是要保持在一个合理的、较高的位置。
- 将大函数拆为许多小函数,往往也是将类拆分为多个小类的时机
- 保持内聚性就会得到许多短小的类
- 为了修改而组织(意思是组织代码必须考虑到便于后面的修改,因为改动的经常且必然的)
- 依赖倒置原则
- 通过扩展而非修改现有代码来增加新特性
我感觉还是在强调“边界”问题,利用边界把不同类的权责划分明确,尽量避免代码改动的影响扩散到别的地方
系统
“一开始就做对系统”纯属神话,主要关注的是做好当下的需求,并预留出拓展和重构的空间
将系统的构造与使用分开
软件系统应将启始过程和启始过程之后的运行时逻辑分离开,在启始过程中构建应用对象,也会存在互相缠结的依赖关系。
把构造集中放在某一部分,等运行到业务代码时,应该大部分构造好(业务代码不需关心如何构造)
上面大部分之外的,指的是一些情景可以通过工厂模式或者依赖注入
工厂模式和依赖注入的区别
网上说的各种各样,我是倾向于,DI和工厂模式都是IoC的一种实现方式。不过似乎依赖注入会更加灵活。
IoC 的核心是将对象的创建和管理从程序代码中转移到外部容器或框架,所以也要看怎么界定这个“外部”了。对于java程序员来说,用XML来配置更容易被认为是外部。不过Unity程序员似乎不兴这套,业务代码之外的,也就是框架范畴的代码也容易被认为是外部。
stackoverflow的讨论中,有人说工厂模式是一种Manually Injected Dependency(手动的依赖注入),似乎也有点道理。
控制反转
暂略,等以后看StrangeIoC得了。对,又挖一个坑
AOP
后面说了点AOP的内容,反正我感觉Unity不太用得上。也不能完全这么说,使用属性标记也算沾点AOP思想。
原则
没补充到的自己去看SOLID
Demeter法则(最少知识原则)
一个方法应该只调用以下几类对象的方法:
- 方法中的对象本身
- 作为方法的参数传递进来的对象
- 此方法创建或实例化的任何对象
- 此对象的任何组件
其意图是限制对象之间的耦合性,减少对象之间的依赖关系
这意味着,方法不应该调用任何由函数返回的对象的方法(好叭,说实话这样调用看着还是很方便的)
// ❌违反该法则的示例
final string outputStr = ctxt.getOptions().getScratchDir().getAbsolutePath();
以上述代码为例,outputStr所在的类需要了解好几个类的具体细节,并且他们之中任意一个有改动的时候,为outputStr赋值的这行代码都需要改动(增加了依赖性)。简言之就是这个调用链的任意一环发生了改变,这个链式调用都有可能要变;链上的类的内部结构还有可能被暴露开了;而且这样写需要对其它类有了解(理解也需要成本,万一理解错了更麻烦)。
一个反面的例子如下:
// ❌不遵循Demeter法则的例子
public class Customer {
private List<Order> orders;
// 获取客户的所有订单
public List<Order> getOrders() {
return orders;
}
}
public class Order {
private List<Product> products;
// 获取订单中的所有产品
public List<Product> getProducts() {
return products;
}
}
public class ProductService {
// ❌不遵循Demeter法则的方法
public boolean hasSpecificProductType(Customer customer, String productType) {
// 直接访问客户的订单列表,然后遍历订单列表,再遍历订单中的产品列表
for (Order order : customer.getOrders()) {
for (Product product : order.getProducts()) {
if (product.getProductType().equals(productType)) {
return true;
}
}
}
return false;
}
}
假设出于某种策略,获取到的Order实例要经过某个处理Order func(Order input)之后才能获取产品,那这个东西加进来就怪麻烦的。
通过重构ProductService和底层类提供的功能,进行了如下的改进:
public class ProductService {
// ⭕遵循Demeter法则的方法,通过客户类的方法来实现
public boolean hasSpecificProductType(Customer customer, String productType) {
return customer.hasProductType(productType);
}
}
public class Customer {
private List<Order> orders;
// 获取客户的所有订单
public List<Order> getOrders() {
return orders;
}
// 检查客户的所有订单中是否存在特定类型的产品
public boolean hasProductType(String productType) {
for (Order order : orders) {
if (order.hasProductType(productType)) {
return true;
}
}
return false;
}
}
public class Order {
private List<Product> products;
// 获取订单中的所有产品
public List<Product> getProducts() {
return products;
}
// 检查订单中是否存在特定类型的产品
public boolean hasProductType(String productType) {
for (Product product : products) {
if (product.getProductType().equals(productType)) {
return true;
}
}
return false;
}
}
基于此不难总结出改进思路:
减少用到的类的数据细节对外的暴露,相应地改为提供接口/功能(就像上面代码把检查是否有某种产品类型的功能写在了顾客类,而不是ProductService直接把顾客和订单拿来检查)
这也渗透这单一职责的思想,具体来说最开始ProductService既包括了与产品数据相关的查询和判断,也直接涉及了客户和订单的内部结构。
主要说的是对象不应该直接暴露数据的意思,如果是数据结构,直接访问数据是OK的,此时Demeter法则就不适用了
依赖倒置原则
依赖倒置的本质是“承诺”而非“指定”。即通过接口或者抽象类“承诺”有某种东西,但是不具体指定这个东西来自谁如何实现。
依赖倒置原则(Dependency Inversion Principle)
依赖源自于需求和关联,例如:
- 直接调用(如模块A调用模块B的方法)
- 继承关系(父类和子类,接口与实现)
- 参数传递
具体的原则是将高层模块与底层模块分离,通过抽象来实现解耦,即:高层模块(如业务逻辑)不依赖于底层模块(如数据库操作的具体实现),二者都应该依赖于抽象
即
A. High level modules should not depend upon low level modules. Both should depend upon abstractions.
B. Abstractions should not depend upon details. Details should depend upon abstraction.
A. 高层模块不应该依赖于低层模块,二者都应该依赖于抽象。
B. 抽象不应该依赖于具体实现细节,而具体实现细节应该依赖于抽象。
理解通过扩展而非修改现有代码来增加新特性
- 使用接口和抽象类(书上举的sql的那个例子)
- 使用设计模式(eg.策略模式、装饰器模式)
- 使用事件和委托
策略模式就是把算法封装在在单独的类中来实现
杂项
- 共性提取(雷同代码行封装函数)
- 尽可能少的类和方法(意思是不要一味地消除重复和遵循SRP而拆出太多的细小类和方法
- 边界处通常需要统一的接口
适配器模式
适配器(Adapter Class)是一种设计模式,用于将一个类的接口转换成客户端期望的另一个接口,使得系统中原本不兼容的接口协同工作。
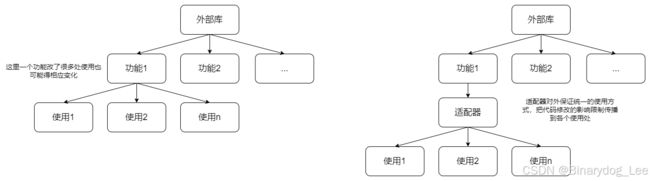
【分类】就处理对象而言可以分为
- 对象适配器
- 类适配器
【意义】这种代码使得很多东西被包装好(进而形成清晰的边界)客户端代码不需要越过边界去直接和外部代码接触。有边界意味着互相影响变少,最显著的表现是某一处改动不会扩散牵连到其他地方。
适配器类的实现形式通常需要声明一个接口或抽象类,适配器类去用“旧的或原先的或第三方的”代码实现接口或抽象类声明的“统一的”功能。
就其本质而言是包装类,就其作用而言则则称之为适配器类
边界
书里有一章讲边界,他想说的是写代码过程中,涉及第三方代码和自己代码的边界问题。但是这章讲的很模糊,甚至很多东西只是java的(eg. log4j),所以还是得从别处看看相关的原则介绍