Big Data大数据,谈的不仅仅是数据量,其实包含了数据量(Volume)、时效性(Velocity)、多样性(Variety)、可疑性(Veracity):
Volume:数据量大量数据的产生、处理、保存,谈的就是Big Data就字面上的意思,就是谈海量数据
Velocity:时效性这个词我有看到几个解释,但我认为用IBM的解释来说是比较恰当的,就是处理的时效,既然前头提到Big Data其中一个用途是做市场预测,那处理的时效如果太长就失去了预测的意义了,所以处理的时效对Big Data来说也是非常关键的,500万笔数据的深入分析,可能只能花5分钟的时间
Variety:多变性指的是数据的形态,包含文字、影音、网页、串流等等结构性、非结构性的数据
Veracity:可疑性指的是当数据的来源变得更多元时,这些数据本身的可靠度、质量是否足够,若数据本身就是有问题的,那分析后的结果也不会是正确的。
2:
Big Data技术综述
Big Data是近来的一个技术热点,但从名字就能判断它并不是什么新词。毕竟,大是一个相对概念。历史上,数据库、
数据仓库、数据集市等信息管理领域的技术,很大程度上也是为了解决大规模数据的问题。被誉为数据仓库之父的Bill Inmon早在20世纪90年代就经常将Big Data挂在嘴边了。
然而,Big Data作为一个专有名词成为热点,主要应归功于近年来互联网、
云计算、移动和物联网的迅猛发展。无所不在的移动设备、
RFID、无线传感器每分每秒都在产生数据,数以亿计用户的互联网服务时时刻刻在产生巨量的交互……要处理的数据量实在是太大、增长太快了,而业务需求和竞争压力对
数据处理的实时性、有效性又提出了更高要求,传统的常规技术手段根本无法应付。
10年前,Eric Brewer提出著名的CAP定理,指出:一个
分布式系统不可能满足一致性、可用性和分区容忍性这三个需求,最多只能同时满足两个。系统的关注点不同,采用的策略也不一样。只有真正理解了系统的需求,才有可能利用好CAP定理。
架构师一般有两个方向来利用CAP理论。
Key-Value存储,如Amazon Dynamo等,可以根据CAP理论灵活选择不同倾向的数据库产品。
领域模型+分布式缓存+存储,可根据CAP理论结合自己的项目定制灵活的分布式方案,但难度较高。
对大型网站,可用性与分区容忍性优先级要高于
数据一致性,一般会尽量朝着A、P的方向设计,然后通过其他手段保证对于一致性的商务需求。
架构设计师不要将精力浪费在如何设计能满足三者的完美
分布式系统,而应该懂得取舍。
不同的数据对一致性的要求是不同的。SNS网站可以容忍相对较长时间的不一致,而不影响交易和用户体验;而像支付宝这样的交易和账务数据则是非常敏感的,通常不能容忍超过秒级的不一致。
缓存在Web开发中运用越来越广泛,mem-cached是danga(运营LiveJournal的技术团队)开发的一套分布
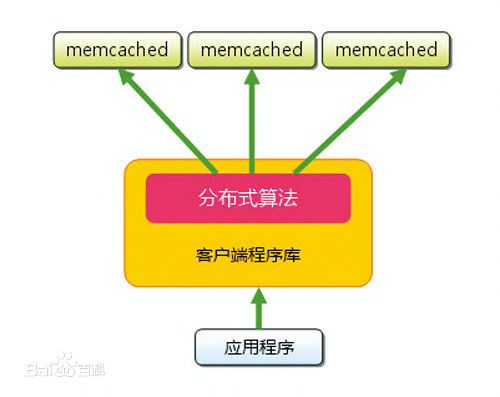
式内存对象缓存系统,用于在
动态系统中减少数据库负载,提升性能。
图1 memcached构成
memcached具有以下特点:
协议简单;基于
libevent的事件处理;内置内存存储方式;memcached不互相通信的分布式。
memcached处理的原子是每一个(Key,Value)对(以下简称KV对),Key会通过一个hash算法转化成hash-Key,便于查找、对比以及做到尽可能的散列。同时,memcached用的是一个二级散列,通过一张大hash表来维护。
memcached由两个核心组件组成:
服务端(ms)和
客户端(mc),在一个memcached的查询中,mc先通过计算Key的hash值来确定KV对所处在的ms位置。当ms确定后,mc就会发送一个查询请求给对应的ms,让它来查找确切的数据。因为这之间没有交互以及多播协议,所以memcached交互带给网络的影响是最小化的。
MemcacheDB是一个分布式、Key-Value形式的持久
存储系统。它不是一个缓存组件,而是一个基于对象存取的、可靠的、快速的持久
存储引擎。协议与memcached一致(不完整),所以很多memcached
客户端都可以跟它连接。MemcacheDB采用Berkeley DB作为持久存储组件,因此很多Berkeley DB的特性它都支持。
类似这样的产品也很多,如淘宝Tair就是Key-Value结构存储,在淘宝得到了广泛使用。后来Tair也做了一个持久化版本,思路基本与新浪MemcacheDB一致。
4: 分布式数据库篇
编辑
支付宝公司在国内最早使用
Greenplum数据库,将
数据仓库从原来的Oracle RAC平台迁移到Greenplum集群。
Greenplum强大的计算能力用来支持支付宝日益发展的业务需求。
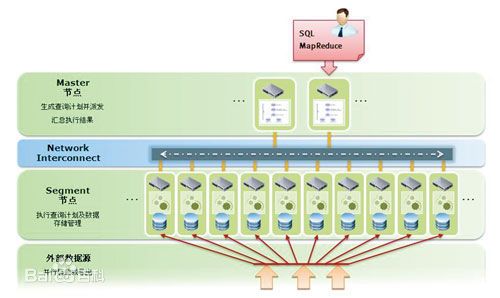
Greenplum数据引擎
软件专为新一代
数据仓库所需的大规模数据和复杂查询功能所设计,基于MPP(海量
并行处理)和Shared-Nothing(完全无共享)架构,基于
开源软件和x86商用硬件设计(性价比更高)。
谈到
分布式文件系统,不得不提的是Google的GFS。基于大量安装有
Linux操作系统的普通PC构成的
集群系统,整个集群系统由一台Master(通常有几台
备份)和若干台TrunkServer构成。GFS中文件
备份成固定大小的Trunk分别存储在不同的TrunkServer上,每个Trunk有多份(通常为3份)拷贝,也存储在不同的TrunkServer上。Master负责维护GFS中的 Metadata,即文件名及其Trunk信息。
客户端先从Master上得到文件的Metadata,根据要读取的数据在文件中的位置与相应的TrunkServer通信,获取文件数据。
在Google的论文发表后,就诞生了Hadoop。截至今日,Hadoop被很多中国最大互联网公司所追捧,百度的搜索日志分析,腾讯、淘宝和支付宝的数据仓库都可以看到Hadoop的身影
。
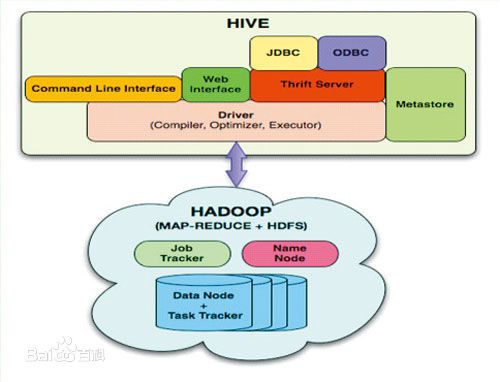
Hive是一个基于Hadoop的数据仓库平台,将转化为相应的MapReduce程序基于Hadoop执行。通过Hive,开发人员可以方便地进行ETL开发。
如图所示,引用一张Facebook工程师做的Hive和Hadoop的关系图。
Yonghong Data Mart的Data Grid的分布式文件存储系统(DFS) 是在Hadoop HDFS基础上进行的改造和扩展,将服务器集群内所有节点上存储的文件统一管理和存储。这些节点包括唯一的一个NamingNode,在 DFS 内部提供元数据服务;许多MapNode,提供存储块。存储在 DFS 中的文件被分成块,然后将这些块复制到多个计算机中(Map Node)。这与传统的 RAID 架构大不相同。块的大小和复制的块数量在创建文件时由客户机决定。Naming Node监控存在服务器集群内所有节点上的文件操作,例如文件创建、删除、移动、重命名等等。
数据集市(Data Mart) ,也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库。从范围上来说,数据是从企业范围的数据库、数据仓库,或者是更加专业的数据仓库中抽取出来的。数据中心的重点就在于它迎合了专业用户群体的特殊需求,在分析、内容、表现,以及易用方面。数据中心的用户希望数据是由他们熟悉的术语表现的。
国外知名的Garnter关于数据集市产品报告中,位于第一象限的敏捷商业智能产品有QlikView, Tableau和SpotView,都是全内存计算的数据集市产品,在大数据方面对传统商业智能产品巨头形成了挑战。国内BI产品起步较晚,知名的敏捷型商业智能产品有PowerBI, 永洪科技的Z-Suite,
SmartBI等,其中永洪科技的Z-Data Mart是一款热内存计算的数据集市产品。国内的德昂信息也是一家数据集市产品的系统集成商。
Yonghong Data Mart是永洪科技基于自有技术研发的一款数据存储、数据处理的软件。
Yonghong Data Mart底层技术:
1. 分布式计算
2. 分布式通信
3. 内存计算
4. 列存储
5. 库内计算
随着数据量增长,越来越多的人关注NoSQL,特别是2010年下半年,Facebook选择
HBase来做实时消息
存储系统,替换原来开发的Cassandra系统。这使得很多人开始关注
HBase。Facebook选择
HBase是基于短期小批量临时数据和长期增长的很少被访问到的数据这两个需求来考虑的。