再读bert(Bidirectional Encoder Representations from Transformers)
再读 BERT,仿佛在数字丛林中邂逅一位古老而智慧的先知。初次相见时,惊叹于它以 Transformer 架构为罗盘,在预训练与微调的星河中精准导航,打破 NLP 领域长久以来的迷雾。而如今,书页间跃动的不再仅是 Attention 机制精妙的数学公式,更是一场关于语言本质的哲学思辨 —— 它让我看见,那些被编码的词向量,恰似人类思维的碎片,在双向语境的熔炉中不断重组、淬炼,将离散的文字升华为可被计算的意义。BERT 教会我们,语言从来不是孤立的字符堆砌,而是承载着文化、逻辑与情感的多维载体,每一次模型的迭代与优化,都是人类向理解语言本质更深处的一次虔诚叩问,在这过程中,我们既是技术的创造者,也是语言奥秘的永恒探索者。
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Github:https://github.com/google-research/bert?tab=readme-ov-file

1.引言与核心创新
-
背景:
现有预训练模型(如 ELMo、GPT)多基于单向语言模型,限制深层双向表征能力。
-
创新点:
(1)提出BERT,通过MLM和NSP预训练任务,实现真正的深层双向 Transformer 表征。
(2)证明预训练模型可通过简单微调(仅添加输出层)适配多任务,无需复杂架构设计。
2.模型架构与输入表征
-
模型结构:
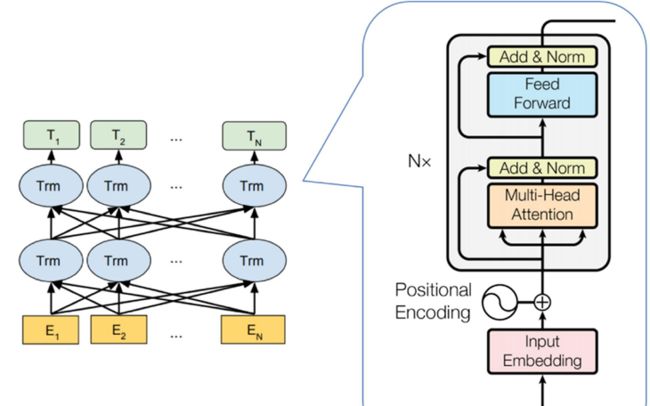
BERT(Bidirectional Encoder Representations from Transformers)由Google 提出并基于 Transformer 架构进行开发的预训练语言模型。如图所示, BERT 模型是由多个 Transformer 的编码器逐层叠加而成。 BERT 模型包括两种标准配置,其中 Base 版本包含 12 层 Transformer 编码器,而 Large版本包含 24 层 Transformer 编码器,其参数总数分别为 110M 和 340M。
BERT 模型的关键特点是能够全方位地捕捉上下文信息。与传统的单向模型(GPT-1 等自回归模型)相比, BERT 能够从两个方向考虑上下文,涵盖了某个词元之前和之后的信息。传统的模型往往只从一个固定的方向考虑上下文,这在处理复杂的语义关系和多变的句子结构时可能会遇到困难。例如,在问答系统中,单一方向可能导致模型不能完全理解问题的上下文,从而影响其回答的准确性。此外,在情感分析、关系抽取、语义角色标注、文本蕴涵和共指解析等任务中,单向方法可能无法充分捕获复杂的语义关系和上下文依赖,限制了其性能。为了应对这些挑战, BERT 通过预测遮蔽的词元来全面理解句子中的上下文,从而在许多 NLP 任务中实现了显著的性能增强。
-
Transformer 配置:
| 模型 |
层数 (L) |
隐层大小 (H) |
注意力头 (A) |
参数总量 |
| BERT BASE |
12 |
768 |
12 |
110M |
| BERT LARGE |
24 |
1024 |
16 |
340M |
-
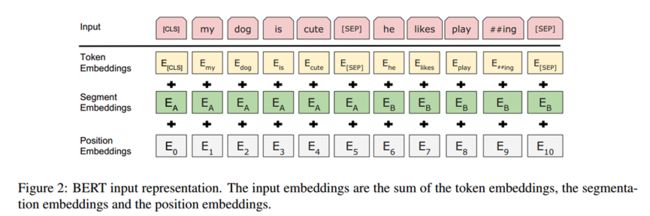
输入表征:
采用WordPiece 分词(30k 词汇表),添加特殊 token:
[CLS]:序列分类标识,对应隐层用于分类任务。
[SEP]:句子对分隔符,段嵌入(Sentence A/B)区分句子归属。
输入嵌入 = 词嵌入 + 段嵌入 + 位置嵌入。
3.训练任务设计
BERT 模型的训练过程通常分为预训练(Pre-training)与微调训练(Finetuning)等两部分。
3.1 预训练
在预训练阶段, BERT 模型在大量未标注的文本数据上进行训练,目标是学习文本之间的深层次关系和模式。具体来说,它使用了两种训练策略:
i)掩码语言模型 (Masked Language Model);
ii)预测下一句(Next Sentence Prediction)。
任务 1:掩码语言模型(MLM)
掩码策略:随机选择 15% tokens,其中:
80% 替换为[MASK](如my dog is [MASK]),
10% 替换为随机词(如my dog is apple),
10% 保留原词(如my dog is hairy)。
目标:通过双向注意力预测原词,缓解预训练与微调时[MASK]未出现的不匹配问题。
任务 2:下一句预测(NSP)
数据生成:50% 真实连续句对(标签 IsNext),50% 随机句对(标签 NotNext)。
目标:通过[CLS]隐层预测句对关系,提升句子级语义理解(如 QA、NLI 任务)。
3.2 微调
微调训练阶段是在预训练的 BERT 模型基础上,针对特定任务进行的训练。这一阶段使用具有标签的数据,如情感分析或命名实体识别数据。通过在预训练模型上加载特定任务的数据进行微调, BERT 能够在各种下游任务中达到令人满意的效果。
BERT 模型微调训练的目的是使其具备处理各种下游任务的能力,微调的任务包括:句子对分类任务、单句分类任务、问答任务和命名实体识别等。
微调训练中为了使 BERT 适应各种 NLP 任务,模型首先调整其输入和输出。例如,在基于句子对的分类任务中,假设要判断句子 A“这家餐厅的食物很美味。”和句子 B“菜品口味很棒,值得推荐。”之间的关系,模型的输入是这两个句子的组合,而输出可能是它们的关系分类,例如“相关”或“不相关”。而在命名实体识别任务中,如果输入句子为“任正非是华为的创始人”,输出则是每个词的实体类别,如“任正非”被标记为“PERSON”,“华为”被标记为“ORGANIZATION”。在针对不同的任务,如文本分类、实体识别或问答等,进行微调训练时,会在 BERT 模型上增添一个特定的输出层。这个输出层是根据特定任务的需求设计的。例如,如果是文本分类任务,输出层可能包含少量神经元,每个神经元对应一个类别。同时,通过反向传播对模型参数进行调整。微调的过程就像是对模型进行 “二次训练”。
4.实验结果与 SOTA 突破
-
GLUE 基准(11 任务)
| 任务 |
BERT LARGE 得分 |
前 SOTA |
提升幅度 |
| MNLI(自然语言推理) |
86.7% |
82.1%(GPT) |
+4.6% |
| QNLI(问答推理) |
92.7% |
87.4%(GPT) |
+5.3% |
| SST-2(情感分析) |
94.9% |
91.3%(GPT) |
+3.6% |
| 平均得分 |
82.1% |
75.1%(GPT) |
+7.0% |
-
SQuAD 问答任务
v1.1(有答案):单模型 F1 值 93.2,ensemble 达 93.9,超过人类表现(91.2%)。
v2.0(无答案):F1 值 83.1,较前 SOTA 提升 5.1%,首次接近人类表现(89.5%)。
- SWAG 常识推理:BERT LARGE 准确率 86.3%,远超 GPT(78.0%)和人类专家(85.0%)。
5.消融研究与关键发现
-
NSP 任务的重要性
移除 NSP 后,MNLI 准确率从 84.4% 降至 83.9%,QNLI 从 88.4% 降至 84.9%,证明句子级关系建模对 QA 和 NLI 至关重要。
-
双向性 vs 单向性
单向模型(LTR,类似 GPT)在 SQuAD F1 值仅 77.8%,远低于 BERT BASE 的 88.5%;添加 BiLSTM 后提升至 84.9%,仍显著落后。
-
模型规模的影响
增大参数(如从 110M 到 340M)持续提升性能,即使在小数据集任务(如 MRPC,3.5k 训练例)中,BERT LARGE 准确率 70.1%,较 BASE 的 66.4% 提升 3.7%。
6.对比现有方法
-
与 GPT 对比:
- GPT 为单向 Transformer(仅左到右),BERT 通过 MLM 实现双向,且预训练数据多 3 倍(33 亿词 vs GPT 的 8 亿词)。
- BERT 在 GLUE 平均得分比 GPT 高 7.0%,证明双向性和 NSP 的关键作用。
-
与 ELMo 对比:
- ELMo 通过拼接单向 LSTM 输出实现双向,为特征基方法;BERT 为微调基,参数效率更高,且深层双向表征更优。
7.关键问题
问题 1:BERT 如何实现深层双向语义表征?
答案:BERT 通过 ** 掩码语言模型(MLM)和下一句预测(NSP)** 任务实现双向表征。MLM 随机掩码 15% 的输入 tokens(80% 替换为 [MASK]、10% 随机词、10% 保留原词),迫使模型利用左右语境预测原词,避免单向模型的局限性;NSP 任务通过判断句对是否连续,学习句子级语义关系,增强模型对上下文依赖的建模能力。
问题 2:BERT 在预训练中如何处理 “掩码 token 未在微调时出现” 的不匹配问题?
答案:BERT 采用混合掩码策略:在 15% 被选中的 tokens 中,仅 80% 替换为 [MASK],10% 随机替换为其他词,10% 保留原词。这种策略减少了预训练与微调时的分布差异,使模型在微调时更适应未出现 [MASK] 的真实场景,同时通过随机替换和保留原词,增强模型对输入噪声的鲁棒性。
问题 3:模型规模对 BERT 性能有何影响?
答案:增大模型规模(如从 BERT BASE 的 110M 参数到 LARGE 的 340M 参数)显著提升性能,尤其在小数据集任务中优势明显。实验显示,更大的模型在 GLUE 基准的所有任务中均表现更优,MNLI 准确率从 84.6% 提升至 86.7%,MRPC(3.5k 训练例)准确率从 66.4% 提升至 70.1%。这表明,足够的预训练后,更大的模型能学习更丰富的语义表征,即使下游任务数据有限,也能通过微调有效迁移知识。