Spark安装过程
Precondition:jdk、Scala安装,/etc/profile文件部分内容如下:
JAVA_HOME=/home/Spark/husor/jdk CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME export CLASSPATH HADOOP_HOME=/home/Spark/husor/hadoop HBASE_HOME=/home/Spark/husor/hbase SCALA_HOME=/home/Spark/husor/scala SPARK_HOME=/home/Spark/husor/spark PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH export HADOOP_HOME export HBASE_HOME export SCALA_HOME export SPARK_HOME "/etc/profile" 99L, 2415C written [root@Master husor]# source /etc/profile [root@Master husor]# echo $SPARK_HOME /home/Spark/husor/spark [root@Master husor]# echo $SCALA_HOME /home/Spark/husor/scala [root@Master husor]# scala -version Scala code runner version 2.10.4 -- Copyright 2002-2013, LAMP/EPFL
1. expect安装
Expect是基于Tcl语言的一种脚本语言,其实无论是交互还是非交互的应用场合,Expect都可以大显身手,但是对于交互式的特定场合,还非Except莫属。
第1步:使用root用户登录
第2步:下载安装文件expect-5.43.0.tar.gz 和 tcl8.4.11-src.tar.gz
第3步:解压安装包
解压tcl8.4.11-src.tar.gz
tar –xvf tcl8.4.11-src.tar.gz
解压后将创建tcl8.4.11 文件夹
解压expect-5.43.0.tar.gz
tar –xvf expect-5.43.0.tar.gz
解压后将创建expect-5.43 文件夹
第4步:安装tcl
进入tcl8.4.11/unix 目录
a.执行sed -i "s/relid'/relid/" configure
b.执行./configure --prefix=/expect
c.执行make
d.执行make install
e.执行mkdir -p /tools/lib
f.执行cp tclConfig.sh /tools/lib/
g. 将/tools/bin目录export到环境变量
tclpath=/tools/bin
export tclpath
第5步:安装Expect
进入/soft/expect-5.43目录
执行./configure --prefix=/tools --with-tcl=/tools/lib --with-x=no
如果最后一行提示:
configure: error: Can't find Tcl private headers
需要添加一个头文件目录参数
--with-tclinclude=../tcl8.4.11/generic,即
./configure --prefix=/tools --with-tcl=/tools/lib --with-x=no --with-tclinclude=../tcl8.4.11/generic
../tcl8.4.11/generic 就是tcl解压安装后的路径,一定确保该路径存在
执行make
执行make install
编译完成后会生在/tools/bin内生成expect命令
执行/tools/bin/expect出现expect1.1>提示符说明expect安装成功.
第6步:创建一个符号链接
ln -s /tools/bin/expect /usr/bin/expect
查看符号连接
ls -l /usr/bin/expect
lrwxrwxrwx 1 root root 17 06-09 11:38 /usr/bin/expect -> /tools/bin/expect
这个符号链接将在编写expect脚本文件时用到,例如在expect文件头部会指定用于执行该脚本的shell
#!/usr/bin/expect
2. SSH免输入密码登陆
主机Master操作如下:
[Spark@Master ~]$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /home/Spark/.ssh/id_rsa.
Your public key has been saved in /home/Spark/.ssh/id_rsa.pub.
The key fingerprint is:
c9:d0:1f:92:43:42:85:f1:c5:23:76:f8:df:80:e5:66 Spark@Master
The key's randomart image is:
+--[ RSA 2048]----+
| .++oo. |
| .=+o+ . |
| ..*+.= |
| o =o.E |
| S .+ o |
| . . |
| |
| |
| |
+-----------------+
[Spark@Master ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3. 然后执行如下自动化传输公钥脚本SSH.sh,将主机Master上的公钥传输给各个从节点Slave1,Slave2......
(Note:将SSH.sh和NoPwdAccessSSH.exp脚本文件添加执行权限,如下:)
[Spark@Master test]$ chmod +x SSH.sh
[Spark@Master test]$ chmod +x NoPwdAccessSSH.exp
//执行自动化无密码访问脚本SSH.sh
[Spark@Master test]$ ./SSH.sh
spawn ssh-copy-id -i /home/Spark/.ssh/id_rsa.pub Spark@Master
The authenticity of host 'master (192.168.8.29)' can't be established.
RSA key fingerprint is f0:3f:04:51:36:b5:91:c7:fa:47:5a:49:bc:fd:fe:40.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'master,192.168.8.29' (RSA) to the list of known hosts.
Now try logging into the machine, with "ssh 'Spark@Master'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
No Password Access Master is Succeed!!!
spawn ssh-copy-id -i /home/Spark/.ssh/id_rsa.pub Spark@Slave1
Spark@slave1's password:
Now try logging into the machine, with "ssh 'Spark@Slave1'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
No Password Access Slave1 is Succeed!!!
spawn ssh-copy-id -i /home/Spark/.ssh/id_rsa.pub Spark@Slave2
Spark@slave2's password:
Now try logging into the machine, with "ssh 'Spark@Slave2'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
No Password Access Slave2 is Succeed!!!
[Spark@Master test]$ ssh Slave1
Last login: Wed Nov 19 02:35:28 2014 from 192.168.8.29
Welcome to your pre-built HUSOR STANDARD WEB DEVELOP VM.
PHP5.3 (/usr/local/php-cgi) service:php-fpm
PHP5.4 (/usr/local/php-54) service:php54-fpm
Tengine1.4.6, mysql-5.5.29, memcached 1.4.15, tokyocabinet-1.4.48, tokyotyrant-1.1.41, httpsqs-1.7, coreseek-4.1
WEBROOT: /data/webroot/www/
[Spark@Slave1 ~]$ exit
logout
Connection to Slave1 closed.
[Spark@Master test]$ ssh Slave2
Last login: Wed Nov 19 01:48:01 2014 from 192.168.8.1
Welcome to your pre-built HUSOR STANDARD WEB DEVELOP VM.
PHP5.3 (/usr/local/php-cgi) service:php-fpm
PHP5.4 (/usr/local/php-54) service:php54-fpm
Tengine1.4.6, mysql-5.5.29, memcached 1.4.15, tokyocabinet-1.4.48, tokyotyrant-1.1.41, httpsqs-1.7, coreseek-4.1
WEBROOT: /data/webroot/www/
[Spark@Slave2 ~]$
以上自动化执行脚本文件如下:
SSH.sh
#!/bin/bash
bin=`which $0`
bin=`dirname ${bin}`
bin=`cd "$bin"; pwd`
if [ ! -x "$bin/NoPwdAccessSSH.exp" ]; then
echo "Sorry, $bin/NoPwdAccessSSH.exp is not executable file,please chmod +x $bin/NoPwdAccessSSH.exp."
exit 1
fi
for hostInfo in $(cat $bin/SparkCluster);do
host_name=$(echo "$hostInfo"|cut -f1 -d":")
user_name=$(echo "$hostInfo"|cut -f2 -d":")
user_pwd=$(echo "$hostInfo"|cut -f3 -d":")
local_host=`ifconfig eth0 | grep "Mask" | cut -d: -f2 | awk '{print $1}'`
if [ $host_name = $local_host ]; then
continue;
else
expect $bin/NoPwdAccessSSH.exp $host_name $user_name $user_pwd //调用expect应答式脚本NoPwdAccessSSH.exp
fi
if [ $? -eq 0 ]
then
echo "No Password Access $host_name is Succeed!!!"
else
echo "No Password Access $host_name is failed!!!"
fi
done
NoPwdAccessSSH.exp
#!/usr/bin/expect -f
# auto ssh login
if { $argc<3} {
puts stderr "Usage: $argv0(hostname) $argv1(username) $argv2(userpwd).\n "
exit 1
}
set hostname [lindex $argv 0]
set username [lindex $argv 1]
set userpwd [lindex $argv 2]
spawn ssh-copy-id -i /home/Spark/.ssh/id_rsa.pub $username@$hostname
expect {
"*yes/no*" { send "yes\r";exp_continue }
"*password*" { send "$userpwd\r";exp_continue }
"*password*" { send "$userpwd\r"; }
}
其中的SparkCluster文件内容如下:
Master:Spark:111111
Slave1:Spark:111111
Slave2:Spark:111111
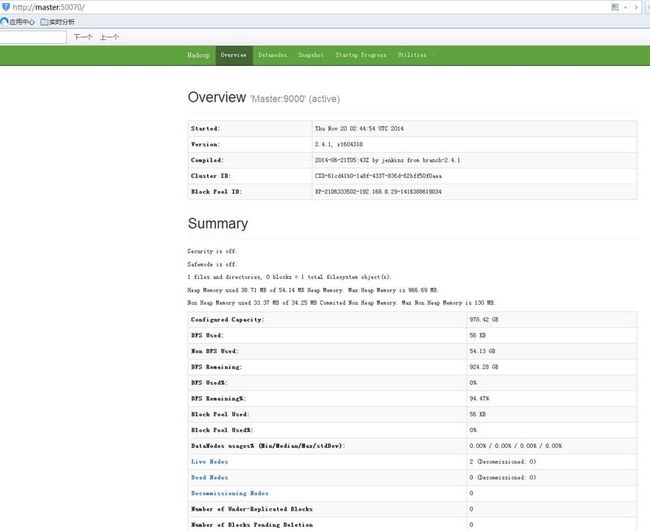
3. 安装hadoop2.4.1(呵呵,我博客上有的。。。。。。)
Note:
1> 将hadoop,jdk安装到统一新添用户Spark相应目录下:/home/Spark)(不然会引起一系列权限问题)
2> 将hadoop安装目录bin和sbin下添加执行权限(chmod 777 *)
3> 将主机Master上配置好的hadoop安装目录scp到所有从机Slave相同的新增用户Spark相同目录下:(/home/Spark) -> scp -r /home/Spark/* Spark@SlaveX:/home/Spark
4> 统一使用root用户修改/etc/hosts,添加相关hostname识别(192.168.8.29 Master 192.168.8.30 Slave1 192.168.8.31 Slave2)
所遇异常1:
Hadoop 2.2.0 - warning: You have loaded library /home/hadoop/2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard.
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_HOME=/home/Spark/husor/jdk
export HADOOP_HOME=/home/Spark/husor/hadoop
export HADOOP_CONF_DIR=/home/Spark/husor/hadoop/etc/hadoop
export SCALA_HOME=/home/Spark/husor/scala
export SPARK_MASTER_IP=Master
export SPARK_WORKER_MEMORY=512m
配置slaves文件
删除localhost,添加相关内容:
Slave1
Slave2
[Spark@Master spark]$ bin/spark-shell Spark assembly has been built with Hive, including Datanucleus jars on classpath 14/11/20 12:17:42 INFO spark.SecurityManager: Changing view acls to: Spark, 14/11/20 12:17:42 INFO spark.SecurityManager: Changing modify acls to: Spark, 14/11/20 12:17:42 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Spark, ); users with modify permissions: Set(Spark, ) 14/11/20 12:17:42 INFO spark.HttpServer: Starting HTTP Server 14/11/20 12:17:42 INFO server.Server: jetty-8.y.z-SNAPSHOT 14/11/20 12:17:42 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:34246 14/11/20 12:17:42 INFO util.Utils: Successfully started service 'HTTP class server' on port 34246. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 1.1.0 /_/ Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71) Type in expressions to have them evaluated. Type :help for more information. 14/11/20 12:17:52 INFO spark.SecurityManager: Changing view acls to: Spark, 14/11/20 12:17:52 INFO spark.SecurityManager: Changing modify acls to: Spark, 14/11/20 12:17:52 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Spark, ); users with modify permissions: Set(Spark, ) 14/11/20 12:17:53 INFO slf4j.Slf4jLogger: Slf4jLogger started 14/11/20 12:17:54 INFO Remoting: Starting remoting 14/11/20 12:17:54 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@Master:38507] 14/11/20 12:17:54 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriver@Master:38507] 14/11/20 12:17:54 INFO util.Utils: Successfully started service 'sparkDriver' on port 38507. 14/11/20 12:17:54 INFO spark.SparkEnv: Registering MapOutputTracker 14/11/20 12:17:54 INFO spark.SparkEnv: Registering BlockManagerMaster 14/11/20 12:17:54 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20141120121754-651a 14/11/20 12:17:54 INFO util.Utils: Successfully started service 'Connection manager for block manager' on port 48273. 14/11/20 12:17:54 INFO network.ConnectionManager: Bound socket to port 48273 with id = ConnectionManagerId(Master,48273) 14/11/20 12:17:54 INFO storage.MemoryStore: MemoryStore started with capacity 267.3 MB 14/11/20 12:17:54 INFO storage.BlockManagerMaster: Trying to register BlockManager 14/11/20 12:17:54 INFO storage.BlockManagerMasterActor: Registering block manager Master:48273 with 267.3 MB RAM 14/11/20 12:17:54 INFO storage.BlockManagerMaster: Registered BlockManager 14/11/20 12:17:54 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-7decc3d6-acce-4793-98c3-172c680de719 14/11/20 12:17:54 INFO spark.HttpServer: Starting HTTP Server 14/11/20 12:17:54 INFO server.Server: jetty-8.y.z-SNAPSHOT 14/11/20 12:17:54 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:46326 14/11/20 12:17:54 INFO util.Utils: Successfully started service 'HTTP file server' on port 46326. 14/11/20 12:17:55 INFO server.Server: jetty-8.y.z-SNAPSHOT 14/11/20 12:17:55 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040 14/11/20 12:17:55 INFO util.Utils: Successfully started service 'SparkUI' on port 4040. 14/11/20 12:17:55 INFO ui.SparkUI: Started SparkUI at http://Master:4040 14/11/20 12:17:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/11/20 12:17:59 INFO executor.Executor: Using REPL class URI: http://192.168.8.29:34246 14/11/20 12:17:59 INFO util.AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@Master:38507/user/HeartbeatReceiver 14/11/20 12:17:59 INFO repl.SparkILoop: Created spark context.. Spark context available as sc. scala>