ChiMerge算法 (java)
韩家炜 数据挖掘概念与技术 第三版 习题3.12
取鸢尾花数据集iris.data作为待离散化的数据集合,使用ChiMerge算法,对四个数值属性进行离散化,对四个属性进行区间合并,最终合并区间个数剩下为6个即停:即max_interval=6。
一、样本数据
iris.data数据形式为:前面4列是属性,最后一列是数据类名,
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 6.6,2.9,4.6,1.3,Iris-versicolor 5.2,2.7,3.9,1.4,Iris-versicolor 6.0,3.0,4.8,1.8,Iris-virginica 6.9,3.1,5.4,2.1,Iris-virginica
........
此数据集一共3个类名:String[] classifies = {"Iris-setosa","Iris-versicolor","Iris-virginica"};
二、算法理论:
算法理论步骤参考: http://blog.csdn.net/zhaoyl03/article/details/8689440
第一步:初始化
初始化时,一个数据认为是一个区间,每个属性对该属性下的各个区间进行升序排序
第二步:合并区间:(直到剩下区间数目为6)
(1) 计算每一对相邻区间的卡方值
卡方公式是: 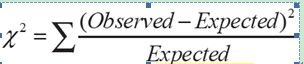
其中observed是expected是一个二行n列矩阵,二行是两个区间,n列是指数据一共有n个类。
这里iris.data数据中一共有三个类,所以是2行3列矩阵:e.g
observedmatrix:(下面表只有红色数字部分才为observedmatrix[2][3]的值。)
| 区间: | 类别Iris-setosa | 类别Iris-versicolor | 类别Iris-virginica | i行计算1的总个数 |
| {3.0} | 1 | 0 | 0 | 1 |
| {3.1,3.2,3.3} | 0 | 1 | 2 | 3 |
| j列计算1的总个数 | 1 | 1 | 2 | 4 (矩阵里1的总个数) |
| 区间: | 类别Iris-setosa | 类别Iris-versicolor | 类别Iris-virginica |
| {3.0} | 1*1/4=0.25 | 1/4=0.25 | 2*1/4=0.5 |
| {3.2,3.3} | 1*3/4=0.75 | 1/4=0.25 | 2*3/4 = 1.5 |

(2) 将上面卡方值最小的一对区间合并
第三步:输出结果:6个区间的最大最小值
三、算法理论数据结构化
将上面算法理论数据结构化:
1.属性:每个属性都有多个区间,所以定义属性是一个list,list的元素是什么类型呢? 是一个区间类型(所以写一个区间类:包括 区间最大最小值,区间包含的元素)。
2.区间:每个区间会包含很多元素,所以也需要一个list来存,list元素什么类型好? 再写一个数据Data类,包括(数据,数据对应的类别(在卡方运算里会用到类别))
所有数据都具备了结构了,整体结构这是最重要的。
List<Interval>[] attributelists = new ArrayList[attributenum]; for(int i=0;i<attributenum;i++) { attributelists[i] = new ArrayList<Interval>(); } class Interval { //每个区间都是有最小值最大值,以及该区间所包含的所有数据 public double maxvalue = 0.0; public double minvalue = 0.0; public List<Data> intervallist = new ArrayList<Data>(); //区间里的list每个元素都是Data类型 } class Data { //每个数据都包含它的值和类别 public double value = 0.0; public String classify = ""; }
四、Java 实现
public class ChiMergeTest {
public static int classificationnum = 3; //类个数 public static int attributenum = 4; public static List<Interval>[] attributelists = new ArrayList[attributenum]; //右边不能Arraylist<interval>!! public static String[] classifies = {"Iris-setosa","Iris-versicolor","Iris-virginica"}; public static void main(String[] args) throws Exception { String inputpath = "iris.data"; readFile(inputpath); //将输入数据的 结构化 chiMerge(); printresult(); }
对应上面算法步骤:
第一步:初始化
初始化时,一个数据认为是一个区间,每个属性对该属性下的各个区间进行升序排序
public static void readFile(String inputpath) throws Exception { BufferedReader br = new BufferedReader(new FileReader(inputpath)); String line = br.readLine(); for(int i=0;i<attributenum;i++) { attributelists[i] = new ArrayList<Interval>(); } while(line!= null&& line.length()>0) { String[] temp = line.split(","); //将数据分隔, for(int i=0; i<attributelists.length; i++) { //遍历属性名 Interval interval = new Interval(); Data onedata = new Data(); onedata.value = Double.parseDouble(temp[i]); onedata.classify = temp[4]; interval.minvalue = interval.maxvalue = onedata.value; interval.intervallist.add(onedata); //区间加入了一个数据 attributelists[i].add(interval); //第i个属性加入了一个区间 } line = br.readLine(); } br.close(); sort(); } public static void sort() { //初步建立属性list时,对区间进行排序 for(int i = 0; i<attributenum; i++){ List<Interval> attrlist = attributelists[i]; Collections.sort(attrlist,new IntervalComparator()); //排序 combineRepeatedData(attrlist); // CombineRepeatedDatawithHash(attrlist); //等同于上面方法,不同顺序会再被打算。麻烦。 }//for } public static void combineRepeatedData(List<Interval> attrlist) { for(int j=0; j<attrlist.size()-1 ;j++) { Interval inteFront = attrlist.get(j); Interval intevbehind = attrlist.get(j+1); List<Data> listFront = inteFront.intervallist; List<Data> listbehind = intevbehind.intervallist; Data dataFront = listFront.get(0); Data databehind = listbehind.get(0); while(databehind.value == dataFront.value &&(j<attrlist.size()-1) ) { //属性list已经排序,如果后面一个data值跟前面data相同,则合并到前面的。 attrlist.get(j).intervallist.addAll(listbehind); //用得不熟!! attrlist.remove(j+1);
if((j<attrlist.size()-1)) { inteFront = attrlist.get(j); intevbehind = attrlist.get(j+1); listFront = inteFront.intervallist; listbehind = intevbehind.intervallist; dataFront = listFront.get(0); databehind = listbehind.get(0); } } } }
class IntervalComparator implements Comparator { //升序了。对list引用类型写compartor排序方法很重要!! public int compare(Object arg0, Object arg1) { Interval i1 = (Interval)arg0; Interval i2 = (Interval)arg1; Data x1 = i1.intervallist.get(0); //一开始所有区间就一个元素而已 Data x2 = i2.intervallist.get(0); int result = 0; if(x2.value<x1.value) {result = 1; } if(x2.value>x1.value) {result = -1; } return result; } }
第二步:合并区间:(直到剩下区间数目为6)
public static void chiMerge() { for(int i=0; i<attributelists.length; i++){ List<Interval> attrlist =attributelists[i]; while(attrlist.size()>6){ //最终的终止条件是形成6个区间 double minchisquare = 10000000; //定义一个属性里最小的卡方值 。。 变量放在的位置很重要,是放在循环里面还是外面很重要,就因为这个找错误还挑不出来,白花了两个小时 int minchisquareindex =0; //记住两个区间最小卡方值的第一个区间在属性list的下标 //遍历一个属性的相邻的两个区间 for(int j=0; j<attrlist.size()-1;j++){ //遍历一个属性的每个两个区间比较 Interval interval1 = attrlist.get(j); //要比较两个区间 Interval interval2 = attrlist.get(j+1); Matrixs matrixs = buildObseredandExpectedMatrixs(attrlist,interval1, interval2); //返回了两个observed,expected矩阵 double chisquarevalue = calchi(matrixs); //计算两个区间的卡方值 if(chisquarevalue < minchisquare ){ //找最小的卡方值 minchisquare = chisquarevalue; minchisquareindex = j; //表示当前最小的卡方值的两个区间中第一个区间在该属性list的下标位置 } }//for mergetwoIntervals(attrlist,minchisquareindex); //合并第i个属性list里的最小两个区间。最终的合并! } //while } }
(1) 计算每一对相邻区间的卡方值
public static double calchi(Matrixs matrixs) { double[][] observedMatrix = new double[2][3]; double[][] expectedMatrix = new double[2][3]; observedMatrix = matrixs.observedMatrix; expectedMatrix = matrixs.expectedMatrix; //求卡方 int chisquarevalue =0; for(int r=0; r<2; r++) { for(int c=0;c<3;c++ ) { chisquarevalue += (observedMatrix[r][c]- expectedMatrix[r][c]) *(observedMatrix[r][c]- expectedMatrix[r][c]) /expectedMatrix[r][c] ; } } // System.out.println("卡方值:"+chisquarevalue); return chisquarevalue; } public static Matrixs buildObseredandExpectedMatrixs(List<Interval> attrlist,Interval interval1,Interval interval2) { //返回两个矩阵:obeserved和expected矩阵//建立observedMatrix double[][] observedMatrix = new double[2][3]; double[][] expectedMatrix = new double[2][3]; int[] linesum = new int[2] ; //矩阵两行的计算 int[] columnsum = new int[3]; //矩阵三列都计算 linesum[0] = interval1.intervallist.size(); linesum[1] = interval2.intervallist.size(); int allsum = linesum[0] + linesum[1]; columnsum[0]= columnsum[1] = columnsum[2] = 0; //初始化列 //取第一个区间 for(int k=0; k< interval1.intervallist.size() ; k++) { //遍历一个区间里所有元素 Data data = interval1.intervallist.get(k); if(data.classify.equals(classifies[0])) { //是类别1:Iris-setosa columnsum[0]++; observedMatrix[0][0]++; } else if(data.classify.equals(classifies[1])) { //是类别2:Iris-versicolor columnsum[1]++; observedMatrix[0][1]++; } else if(data.classify.equals(classifies[2])) { //是类3 columnsum[2]++; observedMatrix[0][2]++; } }//for //取第2个区间 for(int k=0; k< interval2.intervallist.size() ; k++) { //遍历一个区间里所有元素 Data data = interval2.intervallist.get(k); if(data.classify.equals(classifies[0])) { //是类别1:Iris-setosa columnsum[0]++; observedMatrix[1][0]++; } else if(data.classify.equals(classifies[1])) { //是类别2:Iris-versicolor columnsum[1]++; observedMatrix[1][1]++; } else if(data.classify.equals(classifies[2])) { //是类3 columnsum[2]++; observedMatrix[1][2]++; } }//for //建立expectedMatrix for(int r=0; r<2; r++) { for(int c=0;c<3;c++ ) { expectedMatrix[r][c]= linesum[r] * columnsum[c] /allsum; if(expectedMatrix[r][c]==0.0) expectedMatrix[r][c]=0.0001; //因为求卡方的时候,这个值会作分母,所以分母不能作0.分母变小,则卡方值就大,卡方值越大,越不相似,越不会被合并了 } } Matrixs matrixs = new Matrixs(); matrixs.expectedMatrix = expectedMatrix; matrixs.observedMatrix = observedMatrix; return matrixs; } } class Matrixs { public double[][] observedMatrix = new double[2][3]; public double[][] expectedMatrix = new double[2][3]; }
(2) 将上面卡方值最小的一对区间合并
public static void mergetwoIntervals(List<Interval> attrlist,int minchisquareindex) {
// List<Interval> attrlist =attributelists[0]; //将当前最小的卡方值对应的两个区间进行合并;删去已被合并的区间 List<Data> mergedlist = attrlist.get(minchisquareindex+1).intervallist; //被合并的区间里的数据list attrlist.get(minchisquareindex).intervallist.addAll(mergedlist); attrlist.get(minchisquareindex).maxvalue = attrlist.get(minchisquareindex+1).maxvalue; //该区间的最大值是第二个区间的最大值,因为区间已经排过序了 attrlist.remove(minchisquareindex+1); //该属性删去已被合并的区间 }
第三步:输出结果:6个区间的最大最小值
public static void printresult() { for(int i=0; i<attributenum; i++){ System.out.println("第"+(i+1)+"个属性:"); for(int j=0; j<attributelists[i].size(); j++) { //每个属性是list,遍历属性list每一个元素 Interval in = attributelists[i].get(j); System.out.println("( "+in.minvalue +" , " + in.maxvalue + " )" ); //每个interval类里的list每个元素都是一个Data类型 } } }
最终结果如下:
第1个属性: ( 4.3 , 4.8 ) ( 4.9 , 5.2 ) ( 5.3 , 5.3 ) ( 5.4 , 6.9 ) ( 7.0 , 7.0 ) ( 7.1 , 7.9 ) 第2个属性: ( 2.0 , 2.0 )( 2.2 , 2.2 ) ( 2.3 , 2.3 ) ( 2.4 , 3.5 ) ( 3.6 , 3.6 ) ( 3.7 , 4.4 ) 第3个属性: ( 1.0 , 1.9 ) ( 3.0 , 4.4 ) ( 4.5 , 4.5 ) ( 4.6 , 4.7 ) ( 4.8 , 5.1 ) ( 5.2 , 6.9 ) 第4个属性: ( 0.1 , 0.6 ) ( 1.0 , 1.5 ) ( 1.6 , 1.6 ) ( 1.7 , 1.7 ) ( 1.8 , 1.8 ) ( 1.9 , 2.5 )