eclipse安装hadoop插件
win7下安装hadoop完成后,接下来就是eclipse hadoop开发环境配置了。具体的操作如下:
一、在eclipse下安装开发hadoop程序的插件 安装这个插件很简单,haoop-0.20.2自带一个eclipse的插件,在hadoop目录下的 contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar,把这个文件copy到eclipse的eclipse\plugins
目录下,然后启动eclipse就算完成安装了。 这里说明一下,haoop-0.20.2自带的eclipse的插件只能安装在eclipse 3.3上才有反应,而在eclipse 3.7上运行hadoop程序是没有反应的,所以要针对eclipse 3.7重新编译插件。 另外简单的解决办法是下载第三方编译的eclipse插件,下载地址为: http://code.google.com/p/hadoop-eclipse-plugin/downloads/list 由于我用的是Hadoop-0.20.2,所以下载hadoop-0.20.3-dev-eclipse-plugin.jar. 然后将hadoop-0.20.3-dev-eclipse-plugin.jar重命名为hadoop-0.20.2-eclipse-plugin.jar,把它copy到eclipse的eclipse\plugins目录下,然后启动eclipse完成安装。
安装成功之后的标志如图:

1、在左边的 project explorer 上头会有一个 DFS locations的标志 2、在 windows -> preferences里面会多一个hadoop map/reduce的选项,选中这个选项,然后右边,把下载的hadoop根目录选中
如果能看到以上两点说明安装成功了。
二、插件安装后,配置连接参数 插件装完了,启动hadoop,然后就可以建一个hadoop连接了,就相当于eclipse里配置一个 weblogic的连接。 第一步,如图所示,打开Map/Reduce Locations 视图,在右上角有个大象的标志点击 
第二步,在点击大象后弹出的对话框进行进行参数的添加,如下图 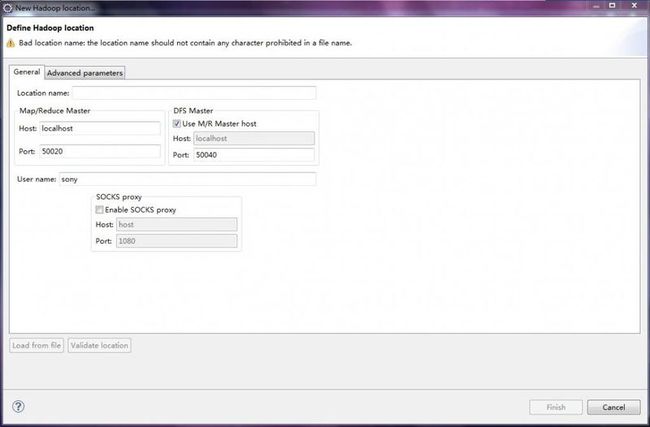
location name: 这个随便填写,我填写的是:localhost. Map/Reduce Master 这个框里 Host:就是jobtracker 所在的集群机器,这里写localhost Hort:就是jobtracker 的port,这里写的是9001 这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port DFS Master 这个框里 Host:就是namenode所在的集群机器,这里写localhost Port:就是namenode的port,这里写9000 这两个参数就是core-site.xml里面fs.default.name里面的ip和port (Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所
以是一样的,就勾选上) user name:这个是连接hadoop的用户名,因为我是用sony用户安装的hadoop,而且没建立其他的用户,所以就用sony。 下面的不用填写。 然后点击finish按钮,此时,这个视图中就有多了一条记录。
第三步,重启eclipse并重新编辑刚才建立的那个连接记录,如图现在我们编辑advance parameters tab页

(重启编辑advance parameters tab页原因:在新建连接的时候,这个advance paramters tab页面的一些属性会显示不出来,显示不出来也就没法设置,所以必须重启一下eclipse再进来编辑才能看到) 这里大部分的属性都已经自动填写上了,其实就是把core-defaulte.xml、hdfs-defaulte.xml、mapred-defaulte.xml里面的一些配置属性展示出来。因为在安装hadoop的时候,其site系列配置文件里有改动,所以这里也要弄成一样的设置。主要关注的有以下属性: fs.defualt.name:这个在General tab页已经设置了 mapred.job.tracker:这个在General tab页也设置了 dfs.replication:这个这里默认是3,因为我在hdfs-site.xml里面设置成了1,所以这里也要设置成1 hadoop.job.ugi:刚才说看不见的那个,就是这个属性,这里要填写:sony,Tardis,逗号前面的是连接的hadoop的用户,逗号后面就写死Tardis 然后点击finish,然后就连接上了,连接上的标志如图:
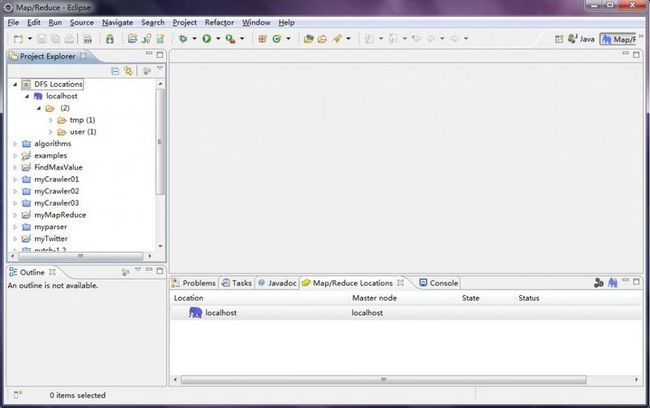
DFS Locations下面会有一只大象,下面会有一个文件夹,即 hdfs的根目录,这里就是展示的分布式文件系统的目录结构了。
到这里为止,Eclipse hadoop开发环境配置已经完全搭建完毕。最后,就可以在eclipse中像一般java程序那样开发hadoop程序了。哈哈,搞定!