nutch 1.8与solr 4.8环境搭建
环境:ubuntu 11.10
前提:
因为solr 4.8必须要jdk1.7或者以上才能正确编译 如果使用jdk1.6或者以下的话 使用jetty运行solr的时候 会出现
java.lang.UnsupportedClassVersionError Unsupported major.minor version 51.0 [duplicate]所以在进行以下操作时 确保你的jdk版本为1.7以上 如下
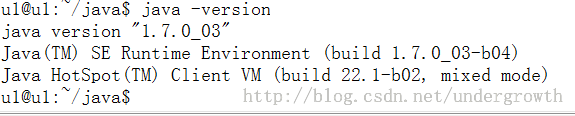
1.从这 http://mirror.bit.edu.cn/apache/nutch/1.8/ 下载 apache-nutch-1.8-bin.zip 下载nutch 1.8
从这 http://mirror.bit.edu.cn/apache/lucene/solr/4.8.0/ 下载 solr-4.8.0.tgz 下载solr 4.8
分为解压 如下
unzip apache-nutch-1.8-bin.zip
tar -zxvf solr-4.8.0.tgz

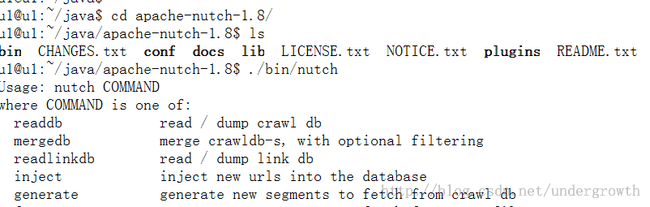
2.验证nutch与solr是否可以正常运行
nutch 出现如下情形表示nutch环境没有问题
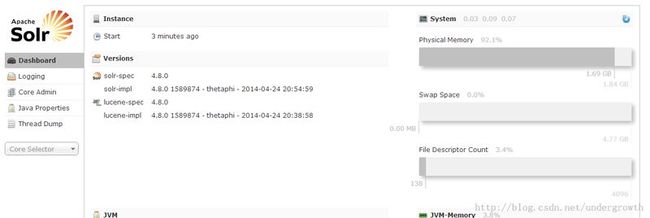
验证 solr 如下截图


在浏览器中输入 http://192.168.38.209:8983/solr/#/ 192.168.38.209为你ubuntu的ip地址
出现如下界面 表示solr的环境也没问题
因为solr是借助于jetty来运行的
3.整合nutch与solr
配置nutch来进行抓取网页
a: 配置代理名称 进入到nutch上面解压的conf目录下 例如
/home/u1/java/apache-nutch-1.8/conf修改 nutch-site.xml 文件 添加如下内容
property> <name>http.agent.name</name> <value>My Nutch Spider</value> </property>
上面的值 可以随便设置
b:设置你想抓取的网页 下面添加了两个准备抓取的网址 百度和新浪 如下


c:配置nutch的配置文件到solr中 官网上如此描述的

官网上的描述和solr 4.8中的目录稍微有一点不符合
具体操作如下


上面需要注意的是 就是第二步 因为从solr 4开始 需要nutch的配置文件为schema-solr4.xml 而不是原来的schema.xml 不然会报如下错误
collection1: org.apache.solr.common.SolrException:org.apache.solr.common.SolrException: Plugin init failure for [schema.xml] fieldType "text": Plugin init failure for [schema.xml] analyzer/filter: Error loading class 'solr.EnglishPorterFilterFactory'
然后重新启动 solr即可
d:最后一步了 使用nutch抓取网页后 索引存到solr中 进行后续的索引
使用如下命令即可 如下
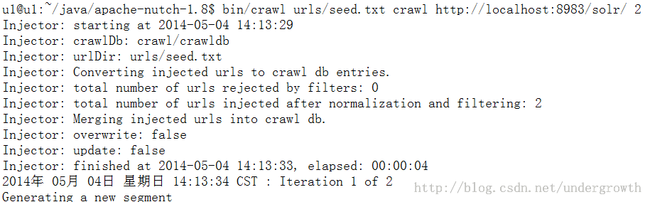
/bin/crawl 在进行抓取的时候 经过五个阶段 分别是 inject->generate->fetch->parse->updatedb
查看是否抓取到了数据 如下
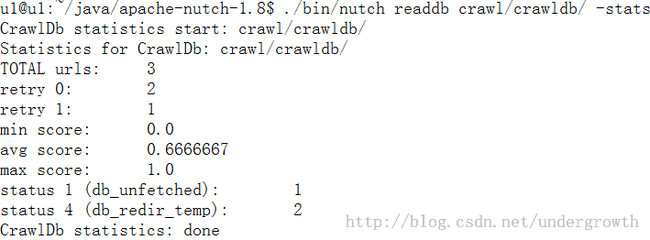
你会发现 怎么 retry 1 和 db_unfetched都是1呢 其实看到这么小的数字 我们也会意识到 应该是没有抓取到数据
可是 为什么呢 抓取数据的时候 没有报错 怎么没有数据呢 又是折腾了1个多小时 我突然意识到 我们实验室的电脑前段时间刚换的 需要账号才能上网 原来我的ubuntu没有上网 郁闷死了 连上网 删掉产生的文件crawl文件夹 重来

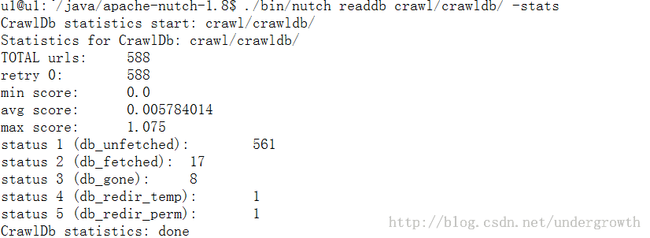
现在有数据了吧
再来在solr建的索引中看看是否可以查到数据了
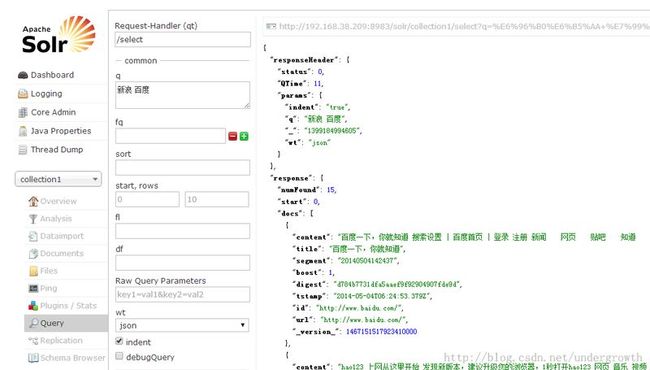
上面即是 nutch1.8与solr4.8的环境搭建 记录学习的脚步
参考: http://wiki.apache.org/nutch/NutchTutorial
参考: http://lucene.apache.org/solr/4_8_0/tutorial.html