SQL JOIN --Merge Join
1概述
Merge join 合并连接。两个集合进行merge join,需要有一个等值的条件,然后需要两个已排序好的集合。
2 one-to-many与many-to-many
2.1 One-to-many
当参与merge join的两个集合中,其中一个集合在等值条件上是具有唯一性(如SELECT * FROM T1 INNER JOIN T2 ON T1.A=T2.B,如果T1在A列上具有唯一性),那么即为one-to-many。主要步骤为:首先从两个集合中各取出一条记录进行比较,如果符合join条件,那么取出该行;否则将值小记录从集合中移除,然后取值小集合的下一行,继续比较。
2.2 many-to many
当参与merge join的两个集合中,没有一个集合在等值条件上具有唯一性时,则采用many-to-many(SELECT * FROM T1 INNER JOIN T2 ON T1.A=T2.B,当列A与列B都不具有唯一性)。主要步骤为:在A和B中都存在A1,A2..An,B1,B2..Bn,那么正常情况下需要为A的每一条记录(A1,A2..An)都要将B中的B1,B2..Bn读取出来,这样浪费性能。所在数据库在处理时,将B中的匹配行储存在tempdb中,如果A中的下一行相等,则读取tempdb中的内容,否则删除tempdb中的数据。
2.3 one-to-many与many-to-many的比较
很显然,one-to-many的效率更高,因为它不需要临时表。那么如何让查询优化器知道我们其中某个集合具有唯一性呢。方法一是:建立聚集索引;二是如distinct、group by操作符。
3排序与索引
数据库几个大的操作之一就是大表的排序,所以使用merge join如果表数据量比较大,并且无索引,那么并不适合merge join。所以当数据量很大,就需要为其添加索引。
4示例
测试数据
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[GoodsType]')) DROP TABLE [dbo].[GoodsType] GO --商品类型表 CREATE TABLE dbo.[GoodsType] ( id int, good_type_name nvarchar(50) ); INSERT INTO dbo.GoodsType SELECT 1,'服装' UNION ALL SELECT 2,'数码' UNION ALL SELECT 3,'家电' IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Goods]')) DROP TABLE [dbo].[Goods] GO --商品类型表 CREATE TABLE dbo.[Goods] ( id int, good_name nvarchar(50), good_type int ); INSERT INTO dbo.Goods SELECT 1,'ADT恤',1 UNION ALL SELECT 2,'AD外套',1 UNION ALL SELECT 3,'T002电视',2 UNION ALL SELECT 4,'海尔洗衣机',2 UNION ALL SELECT 5,'HP222',3
4.1
未建任何索引,执行SQL
SET STATISTICS PROFILE ON SELECT * FROM Goods AS G INNER JOIN GoodsType AS GT ON G.good_type=GT.id OPTION(MERGE JOIN)
结果:
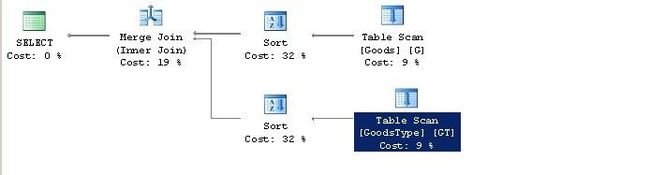

说明
1>未建立索引时,需要为两个集合进行排序;
2>虽然在连接条件上唯一,但是未建唯一聚集索引时,为多对多的连接;
4.2
建立非聚集索引,执行SQL
CREATE CLUSTERED INDEX GT ON GOODSTYPE(ID) CREATE CLUSTERED INDEX G ON GOODS(good_type) SET STATISTICS PROFILE ON SELECT * FROM Goods AS G INNER JOIN GoodsType AS GT ON G.good_type=GT.id OPTION(MERGE JOIN)
结果:


说明:
1>建立索引后,执行merge join无排序的开销
2>虽然两个集合都建立了索引,并且连接的关键字也无重复,但还是多对多的连接,因为优化器不知道它是唯一的。
4.3
为其中一个集合建立唯一聚集索引,执行SQL
DROP INDEX GT ON GOODSTYPE CREATE UNIQUE CLUSTERED INDEX GUT ON GOODSTYPE(ID) SET STATISTICS PROFILE ON SELECT * FROM Goods AS G INNER JOIN GoodsType AS GT ON G.good_type=GT.id OPTION(MERGE JOIN)
结果

说明:
1>为其中的一个集合建立唯一聚集索引时,此时的连接为一对一的连接(执行计划中无一对一连接的概念)
5总结
当不适合使用nested join时,可以考虑使用merge join。在使用merge join时,需要注意两个概念:一是排序,最好是索引排序,否则大数据量的实时排序会增加太多的成本;二是连接方式,是一对多还是多对多,如果关键字不重复,可以建立唯一聚集索引,即尽量使用一对多的连接。