如何理解T-SQL中Merge语句
写在前面的话:之前看过Merge语句,感觉没什么用,完全可以用其他的方式来替代,最近又看了看Merge语句,确实挺好用,可以少写很多代码,看起来也很紧凑,当然也有别的优点。
====正文开始=====
SQL Server 2008 引入了Merge关键字,主要是在一条语句里面可以执行insert、update、delete操作,以实现用一个源对象的数据对目标对象数据进行操作。注意这里的”源对象“和”目标对象“我用黑色标注了,源对象和目标对象实际上不仅仅可以是表Table,还可以是临时表、视图、表变量、CTE,同时”目标对象“还可以是Select语句,说这么多其实想表达Merge语句可以很灵活的使用,但是我们理解的话,可以把”源对象“和”目标对象“想象成Table就行了,毕竟临时表、视图、表变量、CTE也都可以想象成Table。
(注意:如果目标对象是视图的话,那么对目标对象的操作,如update,实际上是对生成视图的表进行操作的)。
好了,看完上面的文字,你可能已经看不下去了,之所以写上面的话,是为了显得严谨一些,接下来就用例子来讲解吧,这个例子不涉及业务逻辑,可以专注于理解Merge的用法,至于实际中什么时候用,只能自己悟了,好了,开始举例子。
例如有一个Student_Target表,如下表一,另外一个Student_Source表,如下表二:
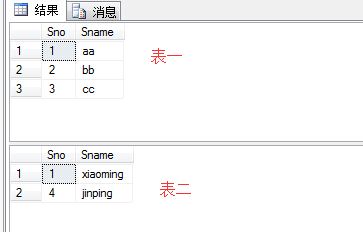
执行如下SQL语句:
MERGE INTO Student_Target AS st --这里是目标表,它将要被源表Merge
USING Student_Source AS ss --这里是源表
ON st.Sno = ss.Sno --这里是匹配条件
WHEN MATCHED --When和Then是配套的,当st.sno=ss.sno时,用ss.sname更新st.sname,我们看到这里update后面没有写明更新的表,这里更新的是目标表
THEN UPDATE SET st.Sname = ss.Sname
WHEN NOT MATCHED BY TARGET --目标表中不存在,而源表中存在数据,那么就执行insert操作,这里by target可以省略,但是建议加上
THEN INSERT VALUES ( ss.Sno,ss.Sname)
WHEN NOT MATCHED BY SOURCE --当目标表中存在,而源表中不存在数据,那么就执行delete操作,这里使用了by source
THEN DELETE
;
上面SQL语句的意思可以看后面的注释,这里再做一简要说明:对于表一,sno=1的一行和表二sno=1的匹配,所以表一中该行被更新;表一中sno=2,3在表二中不存在,因此delete,表二中sno=4但是在表一中不存在,因此insert,最后结果如下:

我们看到上面的结果和表二的内容是一样的,其实你再分析一下上面的SQL语句,逻辑就是把表二的内容弄进表一,表一中和表二中不一致的数据删除,似乎我们上面的Merge语句显得很多余。这里想再说明几点:
(1)我们When matched、When not matched by target、when not matched by source都写上了,其实是可选的,我们可以根据自己的需求只使用其中的部分。
(2)前面是Merge into Student_Target as st,其实可以增加top(n)来对特定数量的行进行操作。执行如下SQL:
MERGE TOP(2) INTO Student_Target AS st --这里是目标表,它将要被源表Merge
USING Student_Source AS ss --这里是源表
ON st.Sno = ss.Sno --这里是匹配条件
WHEN MATCHED --When和Then是配套的,当st.sno=ss.sno时,用ss.sname更新st.sname,我们看到这里update后面没有写明更新的表,这里更新的是目标表
THEN UPDATE SET st.Sname = ss.Sname
WHEN NOT MATCHED BY TARGET --目标表中不存在,而源表中存在数据,那么就执行insert操作,这里by target可以省略,但是建议加上
THEN INSERT VALUES ( ss.Sno,ss.Sname)
WHEN NOT MATCHED BY SOURCE --当目标表中存在,而源表中不存在数据,那么就执行delete操作,这里使用了by source
THEN DELETE
;
最后结果如下:
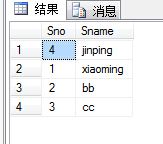
所以,增加了top(2),那么目标表可以被操作的行只能是2条,上面的update操作一条,insert操作一条,达到2条,因此后面的delete就不影响了。因此,对于top(n)应该能够正确的理解。
(3)前面when matched 其实还可以配合其他条件一起操作,例如when matched 可以修改为when matched and ss.sno=1或者when matched and st.sno=1;对于when not matched,只能够使用源列,也就是说,增加and ss.sno=1可以,但是增加and st.sno=1就会报错了。
(4)Merge最后一定要以分号结尾,表示这个Merge句子完整了。
前面的操作我们看到默认的都是对Target表的操作,有时候我们想对Target表操作后,还能够针对特定的条件,对Source表进行操作,这是就可以配合Output子句一起,来完成我们想要的操作。这里Output字句不单单是针对merge语句的,对于insert、update、delete等操作也可以用的,所以具体的可以再去单独研究研究output子句。
至此,本文也该告一段落,如何使用Merge语句应该也没有问题。可是心中仍然有一个结,正如上篇文章所写的:如何理解group by和聚合函数中对group by和聚合函数的认识一样,虽然用起来不成问题,但是总是希望能够找到一个天马行空的想法,能够换个角度去认识。比如为啥基本上都是when matched后面跟update,when not matched by target后面跟insert,when not matched by source 后面跟delete呢?为啥when not matched by target后面不能跟delete?为啥when not matched by source后面不能跟insert呢?当然可能还有其他疑问,目前可以跟join结合起来应该能够很好的解释清楚,可是现在还无法用很好的文字逻辑去表达清楚,回头想好怎么写了再写吧,请原谅我又”胡思乱想“了。
备注:上面的结已经解开了,可以看下一篇博文:如何理解T-SQL中Merge语句(二)