Hadoop on Mac with IntelliJ IDEA - 3 解决MRUnit - No applicable class implementing Serialization问题
本文讲述在IntelliJ IDEA中使用MRUnit 1.0.0测试Mapper派生类时因MapDriver.withInput(final K1 key, final V1 val)的key参数被错误设置成空字符串""导致No applicable class implementing Serialization的解决过程。
环境:Mac OS X 10.9.5, IntelliJ IDEA 13.1.4, Hadoop 1.2.1, MRUnit 1.0.0
Hadoop放在虚拟机中,宿主机通过SSH连接,IDE和数据文件在宿主机。IDEA自身运行于JDK 1.8,IDEA工程及Hadoop使用JDK 1.6。
这是 个粗心的错误。
操作代码如下:
1 @SuppressWarnings("all") 2 public class MapDriverTest { 3 private Mapper mapper; 4 private MapDriver driver; 5 6 @Before 7 public void init() { 8 mapper = new TextMapper(); 9 driver = new MapDriver(mapper); 10 } 11 12 @Test 13 public void test() { 14 String content = "This is a simple test for TextMapper created by Michael"; 15 try { 16 driver.withInput("", new Text(content)) 17 .withOutput(new Text("this"), new IntWritable(1)) 18 .withOutput(new Text("is"), new IntWritable(1)) 19 .withOutput(new Text("a"), new IntWritable(1)) 20 .withOutput(new Text("simple"), new IntWritable(1)) 21 .withOutput(new Text("test"), new IntWritable(1)) 22 .withOutput(new Text("for"), new IntWritable(1)) 23 .withOutput(new Text("TextMapper"), new IntWritable(1)) 24 .withOutput(new Text("created"), new IntWritable(1)) 25 .withOutput(new Text("by"), new IntWritable(1)) 26 .withOutput(new Text("Michael"), new IntWritable(1)) 27 .runTest(); 28 } catch (IOException e) { 29 e.printStackTrace(); 30 } 31 } 32 }
相关类代码如下:
1 public class TextMapper extends Mapper<Object, Text, Text, IntWritable> { 2 final IntWritable count = new IntWritable(1); 3 final Text text = new Text(); 4 5 @Override 6 protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { 7 StringTokenizer tokenizer = new StringTokenizer(value.toString()); 8 while (tokenizer.hasMoreTokens()) { 9 text.set(tokenizer.nextToken()); 10 context.write(text, count); 11 } 12 } 13 }
执行结果如下:
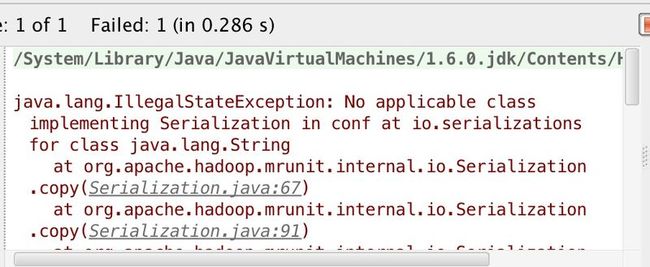
设置成""是完成参考别人代码写的,所以我不知如此设置的原因,原因是Hadoop有一套专用数据类型,分别映射了java基本类型,这里设置成""将被当成设置为String类型,在序列化时因不是Hadoop的数据类型,因而报错(更新于2014.10.06)。下面描述解决过程。
第一步,对比了参考代码,无拼写错误。
第二步,第一次使用MRUnit,Hadoop也刚学习,没人指导,纯抓瞎。只能先验证测试代码本身能否跑起来。注释掉MapDriverTest.test()中driver调用部分,并在init()及test()、TextMapper的map(args)中加入日志,看看代码执行到哪里报错。主体代码示意如下:
MapDriverTest
1 @Before 2 public void init() { 3 System.out.println("init BEGIN"); 4 mapper = new TextMapper(); 5 driver = new MapDriver(mapper); 6 System.out.println("init END"); 7 } 8 9 @Test 10 public void test() { 11 System.out.println("test BEGIN"); 12 String content = "This is a simple test for TextMapper created by Michael"; 13 /*try { 14 driver.withInput("", new Text(content))...*/ 15 System.out.println("test END"); 16 }
TextMapper
1 @Override 2 protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { 3 String keyString = key == null ? "null" : key.toString(); 4 String valueString = value == null ? "null" : value.toString(); 5 String invokeString = "map(key = " + keyString + 6 ", value = " + valueString + ") BEGIN"; 7 System.out.println(invokeString); 8 StringTokenizer tokenizer = new StringTokenizer(value.toString()); 9 while (tokenizer.hasMoreTokens()) { 10 System.out.println("while RUN"); 11 text.set(tokenizer.nextToken()); 12 context.write(text, count); 13 } 14 System.out.println("map END"); 15 }
按预期,还没调用driver.run()或runtTest(),则TextMapper的map方法日志不会输出。现在执行,输出如下
init BEGIN
init END
test BEGIN
test END
符合预期,测试代码运行正常。
第三步,恢复test方法至上一版本,特别处理driver.withInput的输入参数 ,为key及value传入相同的值,观察运行结果。新代码如下:
1 @Test 2 public void test() { 3 System.out.println("test BEGIN"); 4 String content = "This is a simple test for TextMapper created by Michael"; 5 try { 6 //driver.withInput("", new Text(content)) 7 driver.withInput(new Text(content), new Text(content)) // pass the same params to withInput, see how it acts. 8 .withOutput(new Text("This"), new IntWritable(1)) 9 .withOutput(new Text("is"), new IntWritable(1)) 10 .withOutput(new Text("a"), new IntWritable(1)) 11 .withOutput(new Text("simple"), new IntWritable(1)) 12 .withOutput(new Text("test"), new IntWritable(1)) 13 .withOutput(new Text("for"), new IntWritable(1)) 14 .withOutput(new Text("TextMapper"), new IntWritable(1)) 15 .withOutput(new Text("created"), new IntWritable(1)) 16 .withOutput(new Text("by"), new IntWritable(1)) 17 .withOutput(new Text("Michael"), new IntWritable(1)) 18 .runTest(); 19 } catch (IOException e) { 20 e.printStackTrace(); 21 } 22 System.out.println("test END"); 23 }
按资料说明,key参数表示每行的字节偏移量[1]。之前传入"",现在传入与value相同的值,不要位置数据了。走一个,看看啥情况。似乎成功了,看图。
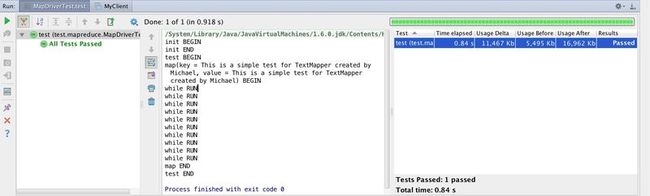
现在,可以认定是key传递""导致的错误了。
再做一次调整,传递key = new Text(),观察执行结果。
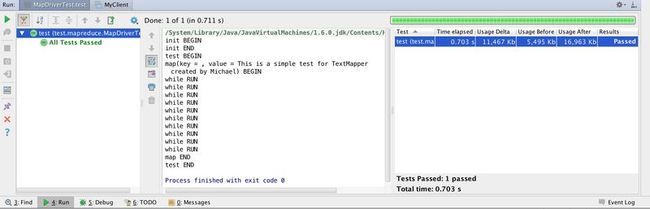
通过了。
什么,你要试试传递key = null。会报错的。另外,日志打印用的key == null ? "null" : key.toString()语句,意义不大,因为传递null会导致java.lang.NullPointerException。网上的资料好多是传递null的,我这边测试会报空指向异常。怀疑是RMUnit版本问题。
第一次使用RMUnit,遇到这个问题,即使目前不知原因,但还是勉强跑起来了,继续尝试。
参考
[1]Chuck Lam. Hadoop In Action. Manning Publications. 2010