[置顶] Rolling Hash(Rabin-Karp 算法)匹配字符串与anagram串
该算法常用的场景
字符串中查找子串,字符串中查找anagram形式的子串问题。
关于字符串查找与匹配
字符串可以理解为字符数组。而字符可以被转换为整数,他们具体的值依赖于他们的编码方式(ASCII/Unicode)。这意味着我们可以把字符串当成一个整形数组。找到一种方式将一组整形数字转化为一个数字,就能够使得我们借助一个预期的输入值来Hash字符串。
既然字符串被看成是数组而不是单个元素,比较两个字符串是否想到就没有比较两个数值来得简单直接。去检查A和B是否相等,我们不得不通过枚举所有的A和B的元素来确定对于所有的i来讲A[i]=B[i]。这意味着字符串比较的复杂度依赖于字符串的长度。比较两个长度为n的字符串,需要的复杂度为O(n)。另外,去hash一个字符串是通过枚举整个字符串的元素,所以hash一个长度为n的字符串也需要O(n)的时间复杂度。
做法
假设,一个模式串P(需要被匹配的串)长度为L,需要在其中查找匹配的串S长度为n。一种在S中查找P的方式为:
1、 hash P 得到 h(p) 。时间复杂度:O(L)
2、 从S的索引为0开始来枚举S里长度为L的子串,hash子串并计算出h(P)’。时间复杂度为O(nL)。
3、 如果一个子串的hash值与h(P)匹配,将该子串与P进行比较,如果不匹配则停止,如果匹配则继续进行步骤2。时间复杂度:O(L)
这个做法的时间复杂度为O(nL)。我们可以通过使用rollinghash来优化这种做法。在步骤2中,我们看到对于O(n)的子串,都花费了O(L)来hash他们(你可以想象成,找了一个长度为L的框,框住了S,每迭代一次向前移动一位,所以会移动n次,而对于每次每个框中的子串都需要迭代这个子串来算哈希值,所以复杂度为nL)。然而你可以看到这些子串中很多字符都是重复的。比如,看一个字符串“algorithms”中长度为5的子串,最开始的两个子串长度为“algor”和“lgori”。如果我们能利用这两个子串又有共同的子串“lgor”这个事实,将会为我们省去很多时间来处理每一个字符串。看起来我们应该使用rollinghash。
“数值”示例
让我们回到字符串上去,假如我们有P和S都被转化为了两个整形数组:
P=[9,0,2,1,0] (1)
S=[4,8,9,0,2,1,0,7] (2)
长度为5的S的子串被列举在下面:
S0=[4,8,9,0,2] (3)
S1=[8,9,0,2,1] (4)
S2=[9,0,2,1,0] (5)
…. (6)
我们想知道P是否能与S的某个子串匹配,可以使用上面的“做法”中的三个步骤。我们的Hash函数可以是:
![]()
或者换句话说,我们将长度为5的整形数组中的每个数值都映射到一个5位数的每一位上,然后用这个数值跟m做“mod”运算。h(P)=90210mod m,h(S0)=48902mod m,以及h(S1)=98021mod m。注意这个哈希函数,我们可以是用h(S0)来帮助计算h(S1)。我们从48902开始,去除第一位得到8902,乘以10得到89020,然后加上下一位数值得到:89021.更通用的公式是:
![]()
我们可以想象为这是在所有的S的子串上一个滑动的窗口。计算下一个子串的hash值其是值关系到两个元素,这两个元素正好是在这个滑动窗口的两端(一个进来一个出去)。这里与上面有很大的不同,这里我们除了第一次去计算长度为L的第一个子串之后,我们将不在依赖这长度为L的元素集合了,我们只依赖两个元素,这使得计算子串hash值的复杂度变成了O(1)的操作。
在这个数值的示例中,我们看到了简单的按位存放整数,并且设置了“底”为10,因此我们可以很轻易得分离出其中的每个数字。为了通用话,我们可以采用如下通用公式:
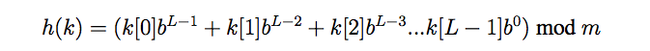
并且计算下一个子串的hash值就是:

回到字符串的问题上
既然字符串可以被转换为数字,我们可以在字符串上也像跟数值的示例一样用同样的方法来提高运行效率。算法实现如下:
1、 Hash P 得到h(P) 时间复杂度为O(L)
2、 Hash S中长度为L的第一个子串 时间复杂度为O(L)
3、 使用rolling hash 方法来计算S 所有的子串 O(n),并以计算出的hash值与h(P)进行比较 时间复杂度为O(n)
4、 如果一个子串的hash值与h(p)相等,那么将该子串与P进行比较,如果匹配则继续,否则则中断当前匹配 时间复杂度为O(L)
这加快了整个算法的效率,只要所有做比较的总时间为O(n),那么整个算法的时间复杂度为O(n)。我们进入一个问题,如果我们在我们的hashtable中假设产生了O(n)次“哈希碰撞”(指由于哈希函数的问题,导致多个key对应到同一个值),那么步骤4的总复杂度就为O(nL)。因此我们不得不确保我们的hashtable的大小为n(也就是必须保证每个子串都能唯一对应一个哈希key,这取决于hash函数的设计),这样我们就可以期待子串可以被一次命中,所以我们只需要走步骤4O(1)次。而我们步骤4的时间复杂度为O(L),在这种情况下,我们仍然可以保证整个问题的时间复杂度为O(n)
共同子串问题
刚才的算法被设计成:在一个字符串S中查找一个模式串P的匹配。然而,现在我们需要处理另一个问题:看看两个长度为n的长字符串S和T,看他们是否拥有长度为L的共同子串。这看起来是一个更难处理的问题,但我们还是能有采用rollinghash使得其复杂度为O(n)。我们采用一个相似的策略:
1、 hash S的第一个长度为L的子串 时间复杂度为:O(L)
2、 使用rolling hash 来计算S的所有O(n)个子串,然后把每个子串加入一个hash table中 时间复杂度为:O(n)
3、 hash T的第一个长度为L的子串 时间复杂度为:O(L)
4、 使用rolling hash方法来计算T的所有O(n)个子串,对每个子串,检查hashtable看是否能命中。
5、 如果T的一个子串命中了S的一个子串,那么就进行匹配,如果相等则继续,否则停止匹配。时间复杂度为:O(L)
然而,保持运行的次数为O(n),我们又再次需要注意限制“哈希碰撞”的次数,以减少我们进入步骤5来进行不必要的匹配。这次,如果我们的hashtable的大小为O(n),那么我们对于T的每个子串所期待的命中复杂度为O(1)(最坏的情况)。这样的结果会导致字符串进行O(n)次比较,总共的复杂度为O(nL)次,这使得字符串的比较在这里成为了瓶颈。我们可以扩大hashtable的大小,同时修改我们的hash函数使得我们的hashtable有O(n的平方)个槽(槽指hash表中真正用于存储数据的单元),来使得对于每个T的子串来讲,可能的碰撞降低到O(1/n)。这可以解决我们的问题,并且使得整个问题的复杂度仍然为O(n),但我们可能没有必要像这样来创建这么大的hashtable消耗不必要的资源。
取而代之的是,我们将利用字符串签名的优势来替代消耗更多存储资源的做法,我们将再为每个子串分配一个hash值,称之为h(k)’。注意,这个h(k)’的hash 函数最终将字符串映射到0到n的平方的范围而不是上面的0到n。现在当我们在hashtable中产生哈希碰撞时,在我们做最终“昂贵”的字符串比较之前,我们首先可以比较两个字符串的签名,如果签名不匹配,那么我们就可以跳过字符串比较。对于两个子串k1和k2,仅当h(k1)=h(k2)以及h(k1)’=h(k2)’时,我们才会做最终的字符串比较。对于一个好的h(k)’的哈希函数,这将大大减少字符串比对,使得比对的复杂度接近O(n),将共同子串问题的复杂度限制在O(n)。
关于rollinghash算法的JAVA简单实现
查找与给定字符串是anagram的子串,例如:
GetAnagram("abcdbcsdaqdbahs'', "scdcb'') ==>"cdbcs''。
因为这里不是查找相等的字符串,而是对应的anagram,所以比较的次数要比上面的第一个示例多,但也可以采用一定的机制来保证尽量少的哈希碰撞,从而减少比对的次数,大大降低复杂度。
大致实现如下:
package rollingHash;
/**
* User: yanghua
* Date: 5/11/13
* Time: 10:54 AM
* Copyright (c) 2013 yanghua. All rights reserved.
*/
import java.util.HashMap;
import java.util.Map;
/**
* rolling Hash(Rabin-Karp Algorithm)练习
* 功能:求给定串的anagram 子串
* 示例:GetAnagram("abcdbcsdaqdbahs","scdcb") --> cdbcs 【Google面试题】
*/
public class RollingHash {
//the simple hash calculate expression is : (a[0] + a[1] + a[2]+ .... + a[n]) * FACTOR
private static final int FACTOR = 41;
private static long hashValueOfPattern;
/**
* generate the pattern's hash
*
* @param patternStr the pattern string
*/
private static void generatePatternHash(String patternStr) {
if (null == patternStr || patternStr.isEmpty()) {
throw new IllegalArgumentException("the arg:patternStr can not be null or empty");
}
hashValueOfPattern = 0;
int sum = 0;
for (int i = 0; i < patternStr.length(); i++) {
char c = patternStr.charAt(i);
sum += (int) c;
}
hashValueOfPattern = sum * FACTOR;
}
/**
* find the matched anagram-str
*
* @param searchingStr the searching string
* @param patternStr the pattern for searching string
* @return matched count
*/
private static int findAnargamStr(String searchingStr, String patternStr) {
if (null == searchingStr || searchingStr.isEmpty()) {
throw new IllegalArgumentException("the arg:searchingStr can not be null or empty");
}
if (null == patternStr || patternStr.isEmpty()) {
throw new IllegalArgumentException("the arg:patternStr can not be null or empty");
}
if (searchingStr.length() < patternStr.length()) {
return 0;
}
int count = 0;
//generate hashmap and hashvalue
generatePatternHash(patternStr);
long tmpHashValue = 0;
int l = patternStr.length();
int n = searchingStr.length();
for (int i = 0; i < n; i++) {
char c = searchingStr.charAt(i);
//calculate the first sub-string (0:pattern.length()-1) which length equal to pattern
if (i < l) {
tmpHashValue += ((int) c) * FACTOR;
} else {
//new tmpHashValue: (a[in-index]-a[out-index]) * FACTOR
tmpHashValue += ((int) c - (int) searchingStr.charAt(i - l)) * FACTOR;
//if the hash-value matched, compare each character
//注:如果这里采用一个好的hash函数 或者 增大hash 槽 或者给字符串进行hash签名来避免过多的hash碰撞,
// 那么这里就可以大大简化对isAnagram的调用,从而使得整个问题的复杂度逼近O(n)
if (hashValueOfPattern == tmpHashValue)
if (isAnagram(searchingStr, i - l + 1, i, patternStr))
count++;
}
}
return count;
}
/**
* is the two string anagram (因为哈希碰撞的存在,该函数用于验证字符串是否确实相等)
*
* @param comparedStr compared string
* @param startIndex start index
* @param endIndex end index
* @param pattern pattern string
* @return true / false
*/
private static boolean isAnagram(String comparedStr, int startIndex, int endIndex, String pattern) {
if (null == comparedStr || comparedStr.isEmpty()) {
throw new IllegalArgumentException("the arg:comparedStr can not be null or empty");
}
if (null == pattern || pattern.isEmpty()) {
throw new IllegalArgumentException("the arg:pattern can not be null or empty");
}
if (startIndex > endIndex || endIndex - startIndex != pattern.length() - 1) {
throw new IllegalArgumentException("the arg:startIndex or endIndex is illegal");
}
boolean anagram = true;
int[] letterCountOfPattern = new int[256];
//not only number and letter , contain backspace and special symbol
for (int j = 0; j < 256; j++) {
letterCountOfPattern[j] = 0;
}
for (int k = 0; k < pattern.length(); k++) {
++letterCountOfPattern[pattern.charAt(k)];
}
for (int i = startIndex; i <= endIndex; i++) {
--letterCountOfPattern[comparedStr.charAt(i)];
}
for (int m = 0; m < 256; m++) {
if (letterCountOfPattern[m] != 0) {
anagram = false;
break;
}
}
return anagram;
}
public static void main(String[] args) {
String searchingStr = "abcdbcsdaqdbahs";
String patternStr = "scdcb";
int count=findAnargamStr(searchingStr,patternStr);
System.out.println(count);
}
}
代码在本人 GitHub上。