分层模式下的Lazy Load ——探索Domain Model系列(下)--转
 阅读本文并探索
阅读本文并探索
- 为什么Lazy Initialization只适用于ActiveRecord模式。
- 芝麻饼公司的Boss是否应该批准降低成本的议案。
- 为什么DomainObject会遭遇“巧妇难为无米之炊”的尴尬?
- 如何用依赖倒置原则解除DomainObject的尴尬处境。
- 如何使用泛型接口简化Value Holder(这个可是书上没有的哦)。
本文将探讨在分层模式下实现Lazy Load所遭遇的困难与迷思,并重点探索模式背后隐藏的思想和设计原则。文章的最后将对书上给出的三种Lazy Load作一个简单的分析和比较。
Lazy Load简介
对于Lazy Load,书上有一个相当精辟的定义。
An object that doesn't contain all of the data you need but knows how to get it.
一个对象,虽然它尚未包含所有你需要的数据,但是知道如何去获取这些数据。
一个对象,虽然它尚未包含所有你需要的数据,但是知道如何去获取这些数据。
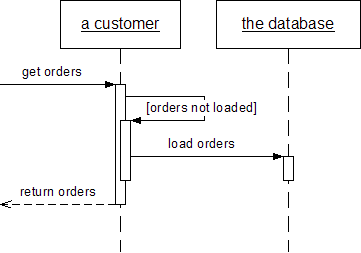
对于把数据从数据库装载到内存中的工作,一种方便的设计是,在你装载了想要的对象的同时,将相关联的对象也一并装载进来。这使得使用这些对象的其它开发者的工作变得更容易——否则他们不得不自己显式地装载他们需要的那些对象。
可是,如果你对此作一个逻辑上的推论,就会发现,装载一个对象的效果往往是同时装载了大量的相关联的对象——而当你实际上仅需要其中的几个对象时,这样作有时就会影响性能。
Lazy Load暂时中断装载其它关联对象的工作,只在对象中放置一个记号,这样就可只在需要使用关联对象的时候才装载它们。就像许多人所知道的,如果你因为懒惰而没有干某件工作,那么当这件工作变成了其它人的职责而你完全不需要再去作的时候,你就胜利了。(以上三段为原文翻译)
需要注意的是Lazy Load往往不能提高性能反而会降低性能(感谢 怪怪)。这是因为所谓的 ripple loading(为得到100条数据而执行100个select语句而不是执行一个select语句得到这100条数据)对性能伤害极大,以至于Fowler建议一开始的时候不要用Lazy Load,只有当系统确实因为装载了过多无用的数据而导致性能很差时,才有的放矢地使用Lazy Load提高性能。这也给我们的设计提出了一个要求: 可以以很小的代价在正常装载数据和Lazy Load之间切换。另,由于使用Lazy Load的时机并不是本文的重点,这里就不详谈了。
书中共给出了四种实现Lazy Load的方法,分别是lazy initialization, virtual proxy, value holder, 以及 gost。
让我们先来看看lazy initialization。
注:“书”指的是Martin Fowler写的《企业应用架构模式》一书。
Lazy Initialization
这是最简单的实现Lazy Load的方法。
lazy initialization的核心代码像这样:
class Department...
public Person getManager() {
if(manager == null) {
manager = new PersonMapper().findById(managerId);
}
return manager;
}
}
注:本文将沿用
上篇给出的数据库结构和数据。另外,本文与上篇联系十分紧密,强烈建议先看上篇,再看本篇。
为什么说lazy initialization只适用于ActiveRecord模式
这是因为Data Mapper模式使用了分层设计,DataSource层是DomainObject层的上层,DomainObject是不允许知道Mappers的(关于这一点在上篇中有详细论述),而上面的那个代码中使用了PersonMapper,这个是绝对不允许的。
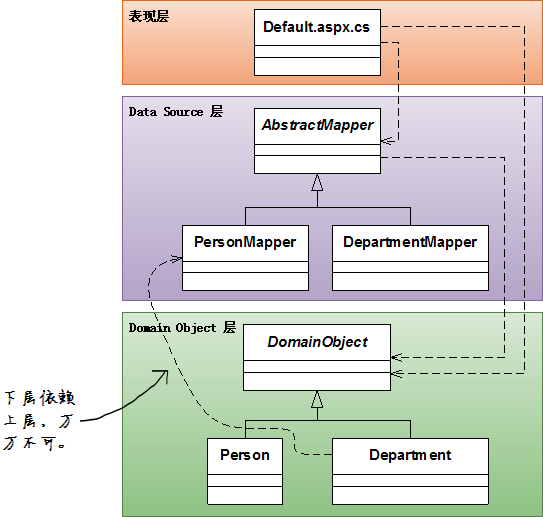
教条主义?
的确,我们写代码是为了完成工作,而不是为了遵守什么活见鬼的设计原则!设计原则往往只是提供一个 guideline ——大方向不能搞错,但是可以根据需要灵活处理。不过这一次不同,因为下层不能访问上层的原则是分层设计中最重要的一个而且是唯一一个绝对不能违反的原则。因为层之间的双向依赖对设计的伤害极大:
- 它使各层的职责不再清晰。
- 它令各层不再能够被独立地修改。
- 它使可读性变差。你将无法把层作为一个有清晰边界的系统来单独阅读,你的注意力必须在各层之间漂移。
- 它令单元测试更加困难。
总之,分层带来的全部好处都会被它消磨殆尽。
但是lazy initialization的简单性太诱惑了,特别是当你被其它三种lazy load搞得晕头转向的时候。我们不禁要问:可不可以只在实现Lazy Load的时候小小地违反一下原则呢?在回答这个问题之前,不妨先来听个小故事。
芝麻饼公司的故事
芝麻胡同 ®是国际知名的芝麻饼生产商。在一次经营会议上,该公司的总经理提出了一个降低成本的议案。
“根据公司现在的生产规程,每张芝麻饼上应放置100粒芝麻。如果我们将这一数量降低到97粒,顾客是察觉不到的——这是我们经过长期的科学实验发现的。如果从下个月开始实施,那么,年终就可节约成本3000万美元,而利润亦会有相应的提高。”
总经理指着幻灯片上那动人心魄的鲜红的向上箭头,眼中似乎也放出了异样的光彩。
如果你是董事长,是否应该同意这一议案呢?
粗看起来,这个议案似乎不错——即降低了成本,又没有损害产品质量(虽然实际上是损害了,但是顾客察觉不到可以约等于没有损害^_^)。但是,问题在于,没有人知道芝麻数量的 底线是多少。没准过了一段时间,又会有个什么销售经理提出一个“有效降低成本议案”:
“根据公司现在的生产规程,每张芝麻饼上应放置97粒芝麻。如果我们将这一数量降低到90粒,顾客是察觉不到的——这是我们经过长期的科学实验发现的。如果从下个月开始实施,那么,年终就可节约成本7000万美元......”
最后,芝麻饼恐怕就要变成烧饼了。
注:这个小故事改编自温伯格的《咨询的奥秘》。
是芝麻饼还是烧饼
同样,我们也不知道违反分层设计原则的底线到底是什么——既然实现Lazy Load可以违反原则,那么实现UnitOfWork的时候是不是也可以违反呢?最后依赖将失去控制,分层也名存实亡了。所以,我们决定 要在不违反分层设计原则的前提下实现Lazy Load。
巧妇难为无米之炊
再来看一下Lazy Load的定义:一个 对象,虽然它尚未包含所有你需要的数据,但是 知道如何去获取这些 数据。很明显,要实现Lazy Load,必须让domain object知道如何去获取数据,但是根据分层设计原则,domain object又不允许知道mappers,天哪,这岂不是正应了那句 巧妇难为无米之炊?
抽象,我们的老朋友
解决这个问题的方法是:从mappers里把domain object需要的功能服务 抽象出来,成为一个 窄接口,然后让domain object依赖这个窄接口。具体点说,Department类需要使用PersonMapper类的findById()函数,但是我们又不想让Department类知道PersonMapper类,这时就可把PersonMapper类的“根据id从数据库中装载并创建一个Person对象”的功能抽象出来,成为一个接口:
public interface IValueLoader
{
object load(long id);
}
然后Department类就可以只依赖这个接口,而不需要依赖PersonMapper了。
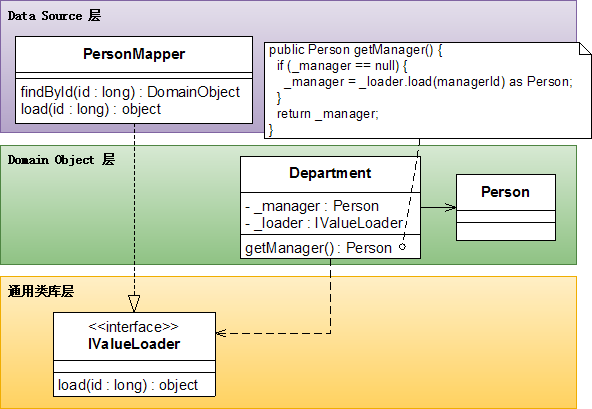
下面这张图包含了全部的源代码:
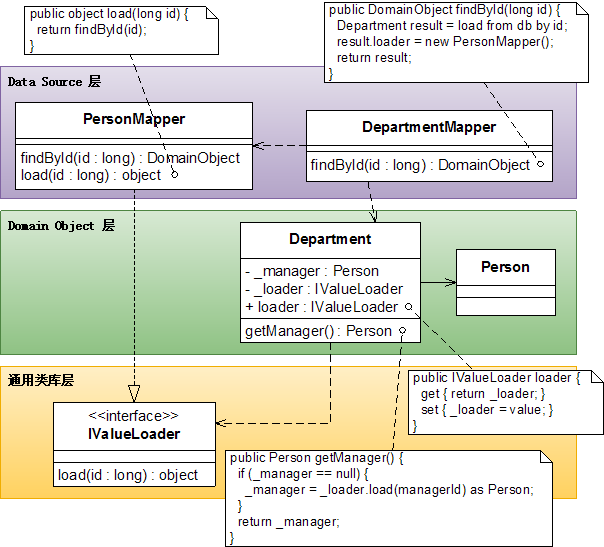
这样domain object既没有违反原则去依赖上层,又得到了想要的功能服务。虽然增加了一个接口之后程序变得稍稍有些复杂,但是对于一个复杂的大型系统来说,用增加一点复杂性来换取对依赖的可控性,还是很值得的。这个招数被Martin Fowler命名为 Separated Interface(476)模式。
Separated Interface Pattern (by 1-2-3)
在使用了分层设计的系统中,下层不应使用上层提供的功能服务。当下层必须使用上层提供的功能服务时,可以将这些功能服务抽象出来成为一个窄接口,然后让下层依赖这个窄接口。Separated Interface模式将上层和下层之间的双向依赖转变成上下两层对一个窄接口的单向依赖。
在使用了分层设计的系统中,下层不应使用上层提供的功能服务。当下层必须使用上层提供的功能服务时,可以将这些功能服务抽象出来成为一个窄接口,然后让下层依赖这个窄接口。Separated Interface模式将上层和下层之间的双向依赖转变成上下两层对一个窄接口的单向依赖。
在Separated Interface模式背后,隐藏着一个十分重要的设计原则,它非常著名,却因高深莫测的定义而难以被初学者理解,它就是 依赖倒置原则。
依赖倒置原则
 Dependency Inversion Principle
Dependency Inversion PrincipleDepend upon abstractions. Do not depend upon concret classes.
依赖倒置原则
要依赖抽象。不要依赖实现类。
这听起来和“要针对接口编程,不要针对实现编程”似乎差不多。的确,两个设计原则都告诉我们应该依赖抽象——这个OO与生俱来的能力与万变不离其宗的原则。不过仅仅说“要依赖抽象”也太过抽象了,感觉与老子的那句“玄之又玄,众眇之门”有得一拼。其实,依赖倒置原则的特别之处并不在原则本身,而在于它的 效果——将双向依赖转变成单向依赖。
另外,在这里我不想解释“倒置”或“反转”的意思,因为我发现这些词除了时髦好听、令人印象深刻外,对问题的理解并无太大帮助,反而容易分散人们的注意力。
模板方法模式和工厂方法模式也是依赖倒置原则的应用
我们都知道,继承关系本身就是一种由子类到超类的很强的依赖关系。在下图中,我们通过显式地画出这个依赖关系来强化这一概念。
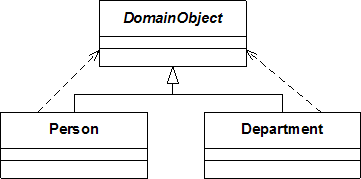
在下图中,因为DomainObject的whoAmI()函数引用了Person类和Department类,又增加了DomainObject对Person类和Department类的依赖。
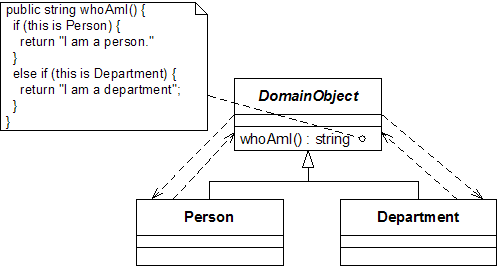
现在,依赖倒置原则就可以派上用场了。
首先,要搞明白谁在上层谁在下层。子类Person和Department由于继承了DomainObject,所以可以随意使用DomainObject中定义的函数,这是与生俱来的依赖关系,我们无法消除,所以Person和Department是DomainObject的上层,DomainObject处于下层。那么,下层类DomainOjbect对上层类的依赖就是不好的东西了,我们要消除它。
下一个问题就是,下层类使用了上层类那些功能服务?答案是“判断对象是Person还是Department”。
接着,我们就可以把这个功能服务抽象出来,成为DomainObject的抽象函数getType(),DomainObject直接依赖这个抽象函数;而Person和Department则要实现这个抽象函数。
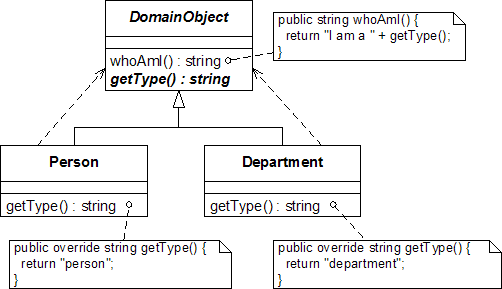
由此可见, 所谓“抽象出来的窄接口”不一定非得是interface,也可以是抽象函数,还可以是delegate(书上的Ghost模式就是一个很好的例子)。
重构,提炼类
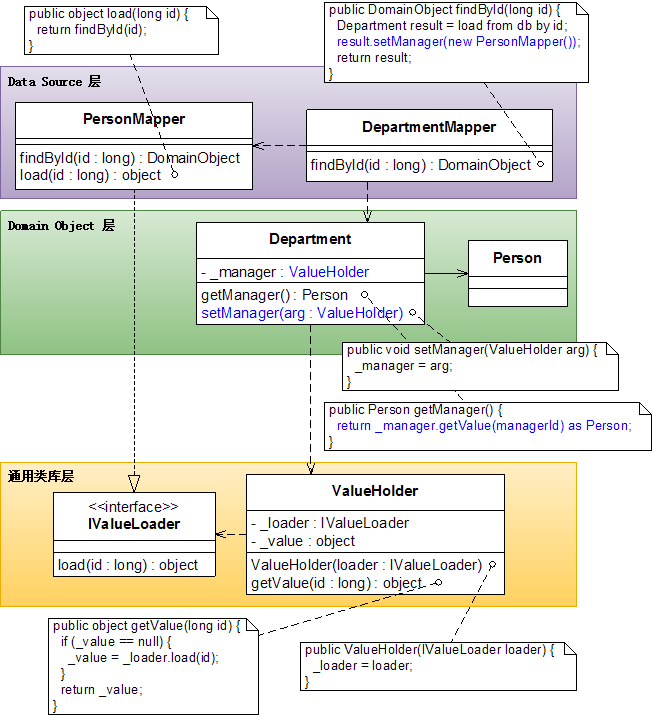
回到Department的定义中,可以看到一处潜在的重复代码(下面涂黄颜色的部分)。
public class Department...
{
public Person getManager() {
if (_manager == null) {
_manager = _loader.load(managerId) as Person;
}
return _manager;
}
}
以后只要每添加一个Lazy Load,就必须重复一遍这个代码,所以应该把它提炼出来。在作了一个Extract Class重构之后,这段代码被提炼到一个新的类ValueHolder中(被修改的部分涂了蓝色)。
使用泛型
现在我们的Lazy Load解决方案已经和书上的Value Holder模式基本差不多了,但是仍有一处坏味道如芒刺在背,让人浑身不自在,这就是Person#getManager()函数中的 向下转型(downcasting)操作(下面代码中涂了黄颜色的部分就是向下转型操作)。
public class Department...
{
public Person getManager()
{
return _manager.getValue(managerId) as Person;
}
}
向下转型三宗罪 (by 1-2-3)
向下转型,其罪有三:
一)破坏了抽象。接口就像魔术师手中的那块黑布,将实现细节隐藏在下边;而向下转型就像一个顽皮的孩子,非要掀开这块布看个究竟不可。
二)必须知道额外的信息。例如getValue()的返回值类型是Object,那么调用这个函数的人怎么能知道应该把这个Object转型成Person还是转型成Women?抑或必须转型成List?
三)必须等到运行期才能知道转型是否成功。你可能说我只要每次写了向下转型的代码之后立即就运行程序测试一下就可以了。我相信你足够勤奋,而且你的所有同事也都和你一样勤奋。但是,如果有一天写getValue()函数的那个人修改了函数真正返回的对象的类型呢?他未必会逐个通知所有调用了getValue()的人吧,再说他也未必就知道到底有多少人调用了这个函数。
向下转型,其罪有三:
一)破坏了抽象。接口就像魔术师手中的那块黑布,将实现细节隐藏在下边;而向下转型就像一个顽皮的孩子,非要掀开这块布看个究竟不可。
二)必须知道额外的信息。例如getValue()的返回值类型是Object,那么调用这个函数的人怎么能知道应该把这个Object转型成Person还是转型成Women?抑或必须转型成List?
三)必须等到运行期才能知道转型是否成功。你可能说我只要每次写了向下转型的代码之后立即就运行程序测试一下就可以了。我相信你足够勤奋,而且你的所有同事也都和你一样勤奋。但是,如果有一天写getValue()函数的那个人修改了函数真正返回的对象的类型呢?他未必会逐个通知所有调用了getValue()的人吧,再说他也未必就知道到底有多少人调用了这个函数。
在 .net framework2.0 中新增的泛型功能可以很好地解决这个问题,而且使用起来也很简单,只要把IValueLoader和ValueHolder中的“object”换成“T”就可以了。下面列出源代码,修改的部分涂了黄颜色。
public interface IValueLoader <T>
{
T load(long id);
}
public class ValueHolder <T>
{
private IValueLoader <T>
private T _value;
public ValueHolder(IValueLoader <T>
{
_loader = loader;
}
public T getValue(long id)
{
if (_value == null)
{
_value = _loader.load(id);
}
return _value;
}
}
而Department和PersonMapper也要做些修改。
public class Department...
{
private ValueHolder <Person>
public void setManager(ValueHolder <Person>
{
_manager = arg;
}
public Person getManager()
{
return _manager.getValue(managerId);
}
}
public class PersonMapper : ..., IValueLoader <Person>
{
public Person load(long id)
{
return findById(id);
}
}
一对多的情况
例如,想统计每个部门的员工数量,需要为Department增加如下代码。
public Class Department...
{
private ValueHolder<IList<Person>> _employees;
public void setEmployees(ValueHolder<IList<Person>> arg)
{
_employees = arg;
}
public IList<Person> getEmployees()
{
return _employees.getValue(id);
}
public int employeeCount
{
get { return getEmployees().Count; }
}
}
修改DepartmentMapper。
public class DepartmentMapper...
{
public DomainObject findById(long id)
{
Department result = load from db by id;
result.setManager(new ValueHolder<Person>(PersonMapper()));
result.setEmployees(new ValueHolder<IList<Person>>(new PersonMapper()));
return result;
}
}
让 PersonMapper 实现 IValueLoader<IList<Person>> 接口。
public class PersonMapper : ..., IValueLoader<Person>, IValueLoader<IList<Person>>
{
public IValueLoader<IList<Person>> load(long id)
{
return findByDepartmentId(id);
}
}
这样就搞定了。
说再见之前
这篇有些长,所以首先感谢您耐心的读到这里。上面那个例子与书上的Value Holder模式十分接近,只不过加上了泛型而已。在附录中,我对书上的三种Lazy Load模式作了一个非常简单的分析和比较,并为每种模式绘制了一幅UML类图,希望能对您有所助益。
附录 书上给出的三种Lazy Load浅析
Virtual Proxy
优点:
- 对domain object没有侵入性,透明度为100%。
- 在普通装载和Lazy Load之间切换只需要修改Mapper中的一行代码。
缺点:
- 在静态类型语言里,实现一个domain object的virtual proxy非常麻烦,所以此方法最好只用于需要返回domain object的集合的情况。
UML图:
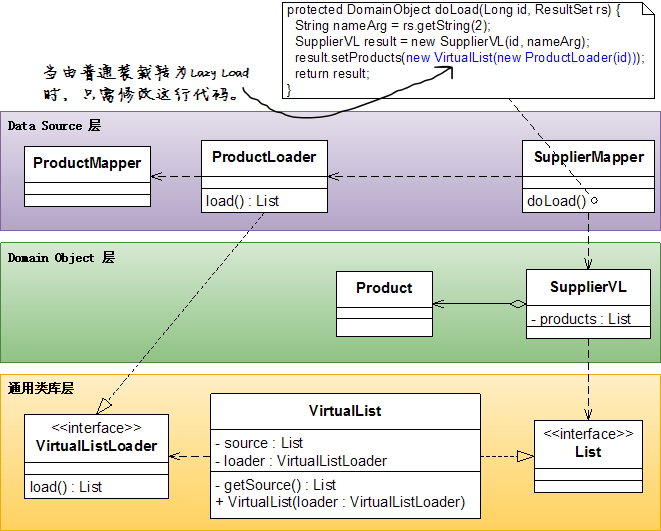
Value Holder
优点:
- 既可以返回单个domain object,也可以返回domain object的集合。
缺点:
- 对domain object有侵入性,当需要由普通装载转为Lazy Load时,必须修改domain object。
- 需要对ValueHolder返回的结果作向下转型操作。
UML图:
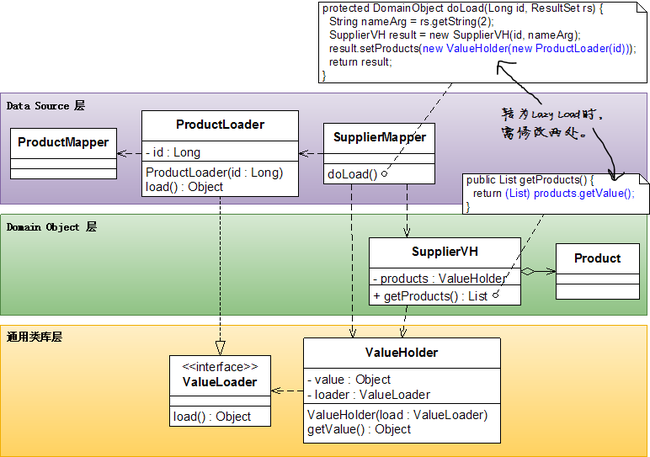
Ghost
优点:
- 既可以返回单个domain object,也可以返回domain object的集合。
- 当由普通装载转为Lazy Load时对DataSource层的改动非常小。但是前提是在项目一开始的时候就要预料到将来使用Ghost的可能性非常大而在一开始的时候就把DataSource层设计成支持Ghost的形式。
- 当由普通装载转为Lazy Load时对Domain Object层的改动非常小,前提是你的项目愿意并且能够支持AOP。
- 这是最Lazy的Lazy Load,你可以在一开始的时候让所有的domain object都是ghost。
缺点:
- 对Mappers有一定的侵入性。如果你的项目一开始的时候没有考虑要使用Ghost,并且设计得内聚度不是很高的话,可能需要进行一番重构才能比较容易支持Ghost。
- 在Mappers#AbstractFind()里调用CreateGhost()的确可以很方便地一下子把所有domain object都变成ghost,但是如果我们只想Lazy Load部分domain object,这招就不灵了。
- 对domain object的侵入性非常大,每个属性都要加一个Load()函数。当然如果你的项目愿意并且能够支持AOP就没什么问题。
UML图:
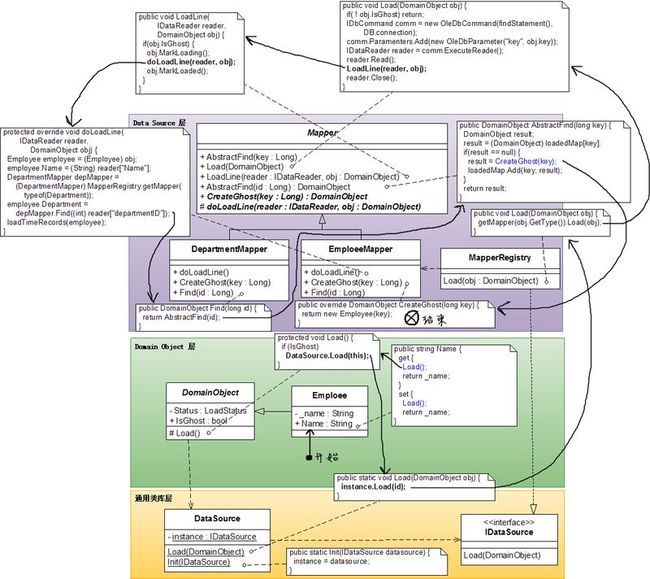
参考文献
[Fowler POEAA]
Fowler, Patterns of Enterprise Application Architecture. Addison-Wesley, 2003.
影印版: 企业应用架构模式(影印版)。中国电力出版社,2004。
[Fowler Refactoring]
Fowler, Refactoring: Improving the Design of Existing Code. Addison-Wesley, 1999.
影印版: 重构——改善既有代码的设计(影印版)。中国电力出版社,2003。
[Fowler UML]
Fowler et al, UML Distilled: A Brief Guide to the Standard Object Modeling Language(Sencond). Addison-Wesley, 2000.
中文版:徐家福 译, UML 精粹(第2版)标准对象建模语言简明指南。清华大学出版社,2002。
[Fowler IOC]
Fowler, Inversion of Control Containers and the Dependency Injection pattern. Web, 2004.
中文版:透明 译, IoC 容器和Dependency Injection 模式。PDF.
[Fowler RC]
Fowler, Reducing Coupling. PDF, 2001.
[Freeman et al]
Freeman et al, Head First Design Patterns. O’Reilly, 2004.
影印版: 深入浅出设计模式(英文影印版)。东南大学出版社,2005。
[王咏武 王咏刚]
王咏武 王咏刚, 道法自然:面向对象实践指南。电子工业出版社,2004。
工具箱
那个太极小图标来自《Head First Design Patterns》,用 FireWorks 6.0和 GIMP 2.2作了一些处理。UML图使用 Visio 2003+ Pavel Hruby's UML2.0 模板绘制。图片上使用了手写字体 方正静蕾简体。文字部分使用 Google 拼音输入法键入。