Voldemort应用
互联网数据应用产品涉及到到大数据存储,譬如推荐系统,精准营销,个性化搜索这样的产品,后台离线计算的海量数据需要展示给用户。在电子商务应用中,譬如将User作为key,给用户挖掘的结果作为value;或者以商品id作为key,商品挖掘的知识作为value,这些数据可以通过KV存储,从而满足实际需求。个人根据阅读一些工业界papers,阅读一些企业的kv存储代码发现,很多公司实现的kv存储,借鉴了Voldemort的实现。Voldemort是linkedin公司实现的开源kv存储,理论基于amazon的dynamo。
1 理论
参考:Dynamo: Amazon’s Highly Available Key-value Store
Dynamo综合了一些著名的技术来实现可伸缩性和可用性:数据划分(data partitioned)和使用一致性哈希的复制(replicated),并通过对象版本(object versioning)提供一致性。在更新时,副本之间的一致性是由仲裁般(quorum-like)的技术和去中心化的副本同步协议来维持的。Dynamo采用了基于gossip的分布式故障检测及成员(membership)协议。Dynamo是一个只需要很少的人工管理,去中心化的系统。存储节点可以添加和删除,而不需要任何手动划分
或重新分配(redistribution)。
Voldemort

2 实验
2.1 Windows下安装voldemort,配置文件
Cluster.xml

Store.xml

2.2 启动单节点 cluster
bin\voldemort-server.bat config\single_node_cluster

2.3 客户端操作
bin\voldemort-shell.bat test tcp://localhost:6666

2.4 基于python的客户端操作
from voldemort import StoreClient, VoldemortException
s = StoreClient('test', [('localhost', 6666)])
value = s.get('hello')
print value
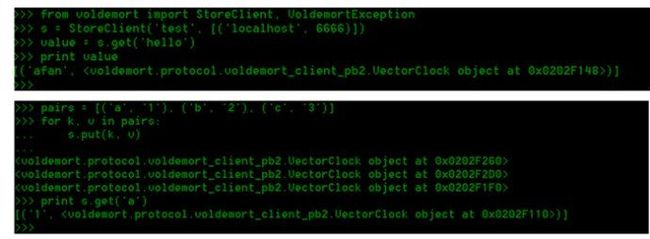
from voldemort import StoreClient, VoldemortException
s = StoreClient('test', [('localhost', 6666)])
value = s.get('b')
print value
3 hadoop离线批处理计算,数据存储到voldemort
3.1准备输入数据,将数据组织成kv
3.2 实现hadoop mapper
public class HadoopStoreMapper extends AbstractHadoopStoreBuilderMapper@Override
public Object makeKey(LongWritable key, Text value) {
return value.toString().split("\t")[0];
}
@Override
public Object makeValue(LongWritable key, Text value) {
return Integer.parseInt(value.toString().split("\t")[1]);
}
}
3.3 构建只读存储
HadoopStoreBuilder
从输入数据,创建hadoop Job,构建只读voldemort存储
$VOLDEMORT_HOME/bin/hadoop-build-readonly-store.sh --input \
--output wordcounts --tmpdir tmp-build --mapper com.lookery.HadoopStoreMapper \
--jar lib/wordcount-mapper.jar --cluster config/cluster.xml \
--storename wordcounts --storedefinitions config/stores.xml \
--chunksize 1073741824 --replication 2

