淘宝主搜索离线集群完成hadoop2.0升级
搜索离线dump集群(hadoop&hbase)2013进行了几次重大升级:

2013-04
第一阶段,主要是升级hdfs为2.0版本,mapreduce仍旧是1.0;同时hbase也进行了一次重大升级(0.94.5版本),hive升级到0.9.0;
2013-09,2013-12
第二阶段,主要升级mapreduce到2.0版本即(YARN),hive升级到0.10.0,在13年年底的时候对hbase进行了一次小版本升级;
至此,dump离线集群完全进入2.0时代:

通过升级hdfs 2.0优化shortcircuit read,使用domain socket通信等等提升了效率,加快了任务运行速度,同时支持成熟的NAMENODE HA,Federation,解决了让大家担心的集群NN单点问题,集群容量和扩展性得到大大提升。
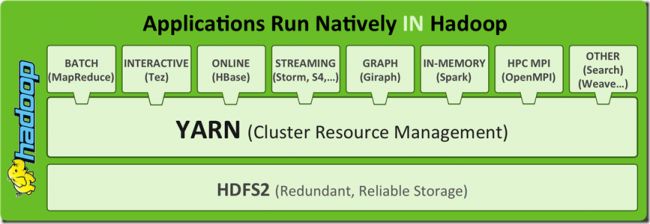
通过升级yarn对集群资源进行更有效的管理,摒弃了slots的物理划分,采用内存资源控制使集群资源被更有效的利用,从而提高整个集群的吞吐,同时支持丰富的计算框架,为后续DUMP应用架构优化调整提供了广阔的舞台。
当然集群的升级过程也遇到了很多问题和困难
第一阶段升级过程中遇到的主要问题:
1)hdfs升级为2.0后,需要同时升级下hive版本(hive-0.9.0-cdh4.1),之前使用老版本hive jar编译的任务需要使用新版本jar包重新编译
2)mr1任务要运行在hdfs 2.0上部分任务会运行失败,主要是2.0中将原来的class换成了interface,需要重新编译即可,少量代码需要添加下throws IOException,依赖的hadoop-core jar包也被拆分成了几个(common,hdfs,mr1等)
3)hdfs shell命令差异,主要是针对mkdir或者touchz等中间如果有不存在的路径不会自动创建
4)从云梯distcp数据由于hdfs版本不兼容,必须使用hftp的方式,且因hftp不支持密码访问,后来patch解决
5)升级hdfs 2.0后集群整体读I/O升高明显,从而导致特别是I/O需求高的build任务延时
原因是2.0对dfs.client.read.shortcircuit的调整,在检查是否有权限(dfs.block.local-path-access.user中配置的用户名)进行shortcircuit读取时如果没有权限会将本地的datanode作为deadnode处理,然后数据通过远程读取
又因为hbase中dfs.client.read.shortcircuit.buffer.size设置的值不合适导致多读了很多无谓的数据,导致整个集群I/O升高
解决方案:
设置dfs.client.read.shortcircuit.buffer.size=16K与hbase的block的大小相匹配
详细的分析过程见:
http://www.atatech.org/article/detail/2733/193
http://www.atatech.org/article/detail/7207/193
第二阶段升级遇到的主要问题:
1)升级到yarn后,Capacity Schedule进行了更新,job提交只需要指定叶子queue名字即可,指定全路径会报错
2)没有了map/reduce slots的概念,集群只需配置可用的内存大小,主要的参数:
集群:
yarn.nodemanager.resource.memory-mb: 一个nodemanager上可分配给container使用的物理内存大小 yarn.scheduler.minimum-allocation-mb: resource manage分配内存的最小粒度,暂设成1024,job提交需要内存必须为此参数的整数倍 yarn.scheduler.capacity.<queue>.maximum-am-resource-percent: am所占资源比例,可按queue设,暂设成0.3 yarn.scheduler.capacity.<queue>.user-limit-factor: 单个用户提交job限制,可按queue设,单用户如要抢占最大资源,需要设大
应用:
mapreduce.map.memory.mb,mapreduce.reduce.memory.mb: map,reduce的内存数,默认是1024,2048,如需设大,必须是1024的整数倍,可以简单理解为之前的slots数配置 mapreduce.map.java.opts,mapreduce.reduce.java.opts: java child进程的jvm heap大小,比上面的值小些 mapreduce.job.reduce.slowstart.completedmaps: 对于map数较多需要跑多轮,可以设大此值,延迟reduce启动避免占用资源
3)yarn中不在兼容commons-cli-2.0-SNAPSHOT.jar,之前通过将该jar文件copy到hadoop classpath中使用的应用需要部署到各自应用的相关目录下,并在提交任务的时候引用
4)一些使用0.19等老版本的hadoop-streaming.jar需要更换为新版本
5)container内存超配被kill掉,考虑到job内存的自然增长及一些使用共享内存的任务,所以设置yarn.nodemanager.vmem-pmem-ratio=false关闭物理内存检查
6)客户端向AM获取job status报错:IOException
原因是AM内存设置太小,频繁GC导致,通过调大yarn.app.mapreduce.am.resource.mb解决
7)c2c_merge任务在yarn上运行缓慢
经过排查分析是因使用的mmap文件在pagecache中频繁换进换出导致,根本原因还是18与32内核的差异,因为集群升级过程中也对内核进行了升级,通过修改应用代码
去除madvise设置的MADV_SEQUENTIA后问题解决,参考:
http://baike.corp.taobao.com/index.php/Kbuild在32内核上性能退化问题
8)IPV4和IPV6差异引起的长短机器名问题及job data local比例低的问题
在yarn resource manager下显示部分机器是长机器名,部分机器是短机器名
hbase集群下显示全是长机器名,原因是yarn与hbase获取机器名调用的方法不一样,得到的结果也不一样,导致resourcemanager在分配container时进行优先的host匹配是匹配不上,最后变成任意匹配导致
获取机器名差异的根本原因经过分析是java处理ipv6有bug和yarn脚本bug共同导致
http://bugs.sun.com/view_bug.do?bug_id=7166687
http://www.atatech.org/article/detail/10731/193
解决方案1是修改yarn脚本,并提交issue到社区: https://issues.apache.org/jira/browse/YARN-1226
解决方案2就是给集群配置上机架感知,且让一个机器一个rack的虚拟机架配置,通过rack匹配绕开任意匹配,在 http://www.atatech.org/article/detail/10731/193 中有详细分析
9)由于我们当时在方案1还未得出结论前临时采用方案2快速解决线上data local低的问题后发现有部分任务提交失败报错: Max block location exceeded for split
原因是:配置了一个节点一个机架后CombineFileInputFormat获取split的block localtion时会根据block分布在哪些rack上获取locations信息,由于机架数等同于机器数,获取到的localtions数会超过集群的默认配置:
mapreduce.job.max.split.locations = 10,而yarn上修改了代码会在超出这个配置值时抛出异常,所以任务提交失败
解决方案1:增大mapreduce.job.max.split.locations和集群节点数一致
解决方案2:patch修改JobSplitWriter中超过配置值抛异常为打印警告日志,与升级前一致
详情见: http://www.atatech.org/article/detail/11707/193
10)gcih不能正常工作
GCIH: http://baike.corp.taobao.com/index.php/GCIH
不能正常工作的原因有两个:
l 集群升级到yarn后,nm管理job临时目录和distribute file的方式与tt不同,导致GCIH会生成多个mmap文件gcih.dat
l 在修复上述问题的过程中,发现散列到不同磁盘上task,jvm classpath加载顺序不一致,导致GCIH不能正常工作
解决方案,升级GCIH
将gcih.dat生成到gcih.jar软连对应的源目录下,这样一个job只会有一个
调整gcih.jar的加载顺序,放到preload里
11)集群资源使用100%,job一直hang住
当集群root跑满100%而下面的子queue未满时(因为希望集群的资源共享竞争,queue的最大可用资源会进行适当的超配)
不会触发抢占reduce资源的过程
解决方案:
l 不同queue的大任务尽量避开运行
l 后续patch修改在root满时触发抢占
详细分析过程见:
http://www.atatech.org/article/detail/10924/193
12)load任务写hbase偶尔会卡住
原因是当集群中有节点挂掉或者网络等出现异常可能会导致hbaseclient在select时无线等待,而锁无法释放
解决方案:
在hbase client的代码里设置超时时间
具体原因分析见:
http://www.atatech.org/article/detail/9061/193
13)集群有节点出现问题,上面的任务一直失败,后续别的任务起来后还会将container分配到这个节点
原因是yarn和之前mr1黑名单机制发生了改变
mr1是全局的黑名单,一旦被加入黑名单后续任务不会再分配
yarn的黑名单是在AM上的,也就是任务级别的,被AM加入黑名单后可以保证当前任务不会被分配上去,但是其他任务的AM中是没有这个信息的,所以还是会分配任务上去
解决方案:等待NM将节点健康信息汇报给RM,RM将节点从集群摘除
如果一直无法汇报,可以通过yarn支持的外围用户脚本来做健康检查和汇报(需要在yarn配置中配置该脚本)
详细分析见:
http://www.atatech.org/article/detail/11266/193
hive相关:
1)out join被拆成多个job
问题发现:loader在做多表join的过程时原来的一个job被hive拆成了8个job,耗时由原来的3分钟变成30分钟
通过patch解决,参考:
http://mail-archives.apache.org/mod_mbox/hive-user/201305.mbox/[email protected]>
https://issues.apache.org/jira/browse/HIVE-4611
2)设置mapreduce.map.tasks不生效
分析是Hive的InputFormat的问题
如InputFormat设置为org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,需要设置mapreduce.input.fileinputformat.split.maxsize来控制map的个数
如InputFormat设置为org.apache.hadoop.hive.ql.io.HiveInputFormat,则此参数生效
解决,将hive配置中默认的InputFormat配置成org.apache.hadoop.hive.ql.io.HiveInputFormat
3)写redis的hive job拆成了两个job
hive默认设置中,当map输出文件太小,会新起一个job合并小文件
解决方案:set hive.merge.mapfiles=false;
仍然存在待解决的问题:
1)有部分job会导致单disk io到100%,拖慢这个任务
2)机器出现异常问题,task全部都在localizing,job一直pending,只能kill掉重新提交
3)job或者task被kill掉后,日志也被删除,history中看不到该job的信息,排查问题困难
集群HADOOP 2.0的升级,在更好的支持现有业务:主搜,商城,店铺内,PORA个性化,尼米兹平台,中文站(offer,company,minisearch),国际站(ae,sc,p4p,aep4p,scp4p)的基础上为后续离线dump平台:ADUMP的建设夯实了基础。
一个统一存储,模块插件化设计,减少各业务线之间数据冗余,避免重复开发,同时支持快速响应各条业务线新需求的全新平台ADUMP将在3月底左右上线,紧跟集群升级的节奏,离线DUMP也将马上进入2.0时代,敬请期待!