前端工程师的编码遭遇战
导语:由于历史原因,淘宝网的页面编码一直都是gbk,F2E手册中也有明确规范,刚开始的一段时间,F2E们并未遭遇太麻烦的乱码问题,大家相安无事,但随着淘宝的合作方越来越多,合作方的API接口编码可谓五花八门,淘宝的系统和第三方的数据对接之后就暴露出各式各样的乱码问题。有必要再把这个问题缕缕清楚。
我想,可能是在做第一个淘宝网的页面时,工程师只顾写代码,而忘了看一看编辑器的默认编码设置,再后来就将错就错直到今天,如果稍微留神,可能就不会犯下这么一个低级错误。没错,“编码约定”在全站规范中占有及其重要的权重,不幸的是,而这个异常重要的问题却非常容易被忽略,毕竟它不仅仅是“统一页面编码约定”这么简单,甚至包含全站的安全策略(这是显而易见的)。而作为F2E面对各式乱码问题时,更要了解问题的本源,搞清楚能根治问题的方法,而不是依赖于浏览器的某种适应性暂时规避掉乱码,治标不治本。
从二进制码流到显示出字符
众所周知,字符的编码方式有两种惯例,一种是很古老的对ASCII码做某种语言子集的扩展,比如big5和gb2312,分别是繁体字扩展和简体字扩展,两者互不兼容,与之类似的编码还有ISO系列,各个拉丁文的子编码集合也不相互兼容,这种编码的好处是编码集合很小,坏处是不能同时使用多种语言,于是就有了另一种编码惯例:“万国码”,全球所有语言做成一个码表,即unicode码表,显然,这种编码的坏处是码表太庞大,好处是同时使用多种语言。所谓的utf-7、utf-8之类就是unicode的某种相对高效的实现,不管某个字符用utf编码为几个字节,他们都属于同一个unicode超集。我们常遇到的中文编码是gb2312、gbk、gb18030和utf-8,不严谨的讲,前三者大致相互兼容,但都和utf-8不兼容。如果一段文本以gbk(码表)进行编码的话,阅读软件只有按照gbk(码表)解码才能阅读。但机器码显示为最终的字符点阵,阅读软件(浏览器、文本编辑器等)还需要将解码后(通过查找码表将连续的二进制码转换为了字符)的字符码对应到相应的点阵,显然,如果用以显示文本的字体不包含某个字符的点阵,这个字符自然也无法显示出来。更多背景知识可以参照这个ppt。
由于浏览器比较好的兼容性,一般不会出现因为字体问题而出现乱码的情况,但在工程师写代码的时候偶有遇到,比如使用vim以gb2312编码编辑一个文件,当文件中出现“镕”字时,是无法保存这个文件的。这是因为gb2312码表中不存在这个字,但指定gb2312编码的网页是可以显示这个字的,这是因为浏览器通常会采用windows系统编码来解析gb系的页面,通常是gbk。
如果使用editplus或记事本,只需存为ANSI编码就可以,这些编辑器会根据码流去识别到底是gbk还是gb2312还是gb18030的编码,所以 window下很多文本编辑器都没有强行采用某种特定的编码,统一使用系统编码,通常情况下中文win系统中,可以认为ANSI就是gbk。如果使用linux系统,可以参照这里来正确处理你的编辑器的编码。
浏览器如何发送一个带有中文的URL
那么,浏览器打开一个网页,从敲入网址到最终呈现出UI整个过程中,是如何处理编码的呢?整个过程分两个阶段,1,发送URL请求,2,接收数据并呈现。HTTP标准对URL编码有着如是规定(RFC 1738):
“…Only alphanumerics [0-9a-zA-Z], the special characters “$-_.+!*’(),” [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL.”
“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*’(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这里不得不提到URL编码,尽管根据RFC的规定,含有中文的URL是非法的URL,但没有规定如何转码,阮一峰的这篇文章详细的介绍了在Firefox和IE中是如何对带有中文的URL进行编码发送HTTP请求的。确切的讲,URL是一种编码“方法”,编码结果依赖于所采用的“码表”,即汉字的内码表示形式。所以,相同汉字有N多种URL编码结果,“淘宝”的utf8编码为“%E6%B7%98%E5%AE%9D”,gbk编码为“%CC%D4%B1%A6”。
这里需要注意的是,一个gb系编码的html页面中的form提交,表单中的中文编码会进行URL编码,但是以gbk格式作转码,utf8页面的form提交,以utf8格式作转码。看这两个例子:
gbk页面的表单提交,utf-8页面的表单提交
这时就需要和后台程序做好约定,页面怎么进行编码,后台逻辑就需要对应的解码。比如淘宝的Search页面和百度搜索页一样,只接收gbk的URL编码。网上这方面的资料也比较多,这里不再赘述。
但如果通过JavaScript的encodeURI(encodeURIComponent亦是同理)做URL编码又会出现什么情况呢?JS只会以utf-8的形式做URL编码,同样参照上面两个例子,不管页面是gbk还是utf-8,JS中的URL编码始终是一样的。这在使用JS库模拟form提交时需要尤为注意,直接提交表单结果正常,用JS库或框架提供的方法模拟拼接查询串提交表单就出问题,也就是这个原因。所以,在用JS拼接查询URL的时候要小心,需要注意后台程序需要的编码是什么格式。
浏览器如何以正确的编码渲染页面
HTTP响应的数据起码有三个地方可以埋藏编码信息:
1,http头中的Content-Type
2,html页面中的meta标签中指定charset
3,页面正文数据(浏览器可以解析正文二进制码来判断编码)
浏览器可以从这三个地方获得HTTP响应报文的编码,此外还有两个因素,浏览器默认编码和操作系统语言类型。
淘宝首页是gbk的编码,HTTP响应头中指定了文档编码为GB2312,同时meta中的charset和页面正文都是gbk编码,浏览器渲染正确。
content-type中的编码设置

源码中的meta标签
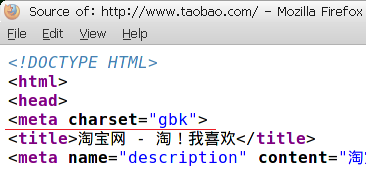
如果三者编码不一致,浏览器会首先读取http头中的content-type,若没有设定编码,再查找页面中meta标签中的charset设定,如果还没有就以浏览器默认编码来显示,如果默认编码没有指定,浏览器会通过解析正文内容来判断编码。所以,页面是gbk编码,即便meta属性中设置charset=utf-8,只要content-type中设定为gbk(或者GB2312、GB18030),该页面就正常显示,如果这时没有设定content-type的编码,浏览器就会以meta中的charset属性为准,页面出现乱码。
在PHP中可以这样设置content-type的编码:
header('Content-Type: text/html; charset=GBK');
正确的载入JS文件
html页面载入js文件的时候,需要指定js文件的编码才能正确引用,比如:
<script src="gbk.js" charset="gbk" ></script>
可以参照这个demo
JSONP里的中文处理
根据上面的例子,我们知道载入外部JS文件只要指定charset就可以,对JSONP来讲也是如此,但有一个更彻底的杜绝乱码的方法,将JS文件进行unicode编码,这是因为JS引擎的内码是unicode,所以只要是unicode的文本JS都可以识别。就像这样:

PHP中的json_encode函数可以直接将数组作unicode转码。通过JS也可以进行unicode编码,参照这个Demo。
通过JS获取URL
我们注意到,在使用Firefox打开的地址中包含中文时,将其拷贝粘贴到另外的地方却没有得到中文,而是编码后的URL。这是因为浏览器自作聪明的将URL解码为中文来显示的,当我们需要抓取URL的时候需要特别小心,这个Demo在Firefox和IE下打开,JS得到的URL是不一致的。
Firefox:

IE:

如果这个页面不和后台数据发生交互,直接通过document.location.href来取URL是ok的,一旦和后台发生交互,则需要非常小心,最常见出问题的场景是带入登录页的回调地址。比如通过这个地址进入淘宝首页:
http://www.taobao.com/?淘宝
在Firefox和IE下都是可以正常访问的,这时点击吊顶中的“登录”,进入登录页,可以看到在Firefox下的回调地址为:

而在IE下的回调地址为:

这时登录淘宝,页面跳转为淘宝首页,可以看到Firefox的地址栏中的URL是正确的,而在IE的地址栏中出现了乱码
Firefox下
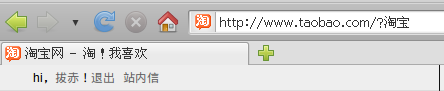
IE下
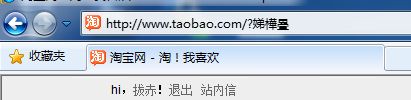
解决办法就是不要用JS去抓取URL写入回调,通过登录页面的Ref或其他方式来抓取。
gbk的页面如何通过JS得到gbk格式的URL编码
我们知道,gbk的页面提交表单是可以作基于gbk的URL编码的,基于这一点,我们可以封装一个函数,实现在gbk页面中使用JS得到gbk格式的URL编码。参照这个Demo,Demo中模拟提交一个表单,然后抓取表单提交的结果,进而得到gbk格式的URL编码。
这样,通过JS就可以控制我希望得到的URL编码了。但在utf-8的页面中是无法实现的。这一点需要尤为注意。